아직 많이 부족하지만 실전을 통해 체득한 노하우를 기록해보려고 합니다. 잘못된 내용이 있다면 지적도 부탁드립니다! 🤚
이번 포스팅의 목적
시계열 예측도 모델 훈련, 검증을 통해 성능이 가장 좋은 모형을 만드는 머신러닝 방법에 속합니다. 그런데 시계열 예측에 활용할 수 있는 알고리즘은 매우 다양합니다.
가장 기본적인 smoothing 기법부터 ARIMA, SARIMA, ARIMAX, VAR 등의 통계적 예측 방법이 있으며, Meta(과거 Facebook)에서 개발한 Prophet, LinkedIn에서 개발한 Greykite, 그리고 딥러닝 기반의 LSTM, ELM, Attenion 등 시도해볼 방법이 너무나 많습니다.
요새는 대부분 딥러닝을 활용하는 추세이지만, 반드시 딥러닝만이 좋은 모델이라고 장담하긴 어렵습니다. 모형 적합에 사용할 변수와 예측 기간 등 문제 정의와 실험 설계에 따라 때로는 통계 기반의 시계열 모델이 더 좋은 성능을 보일 때도 있기 때문입니다. 그래서 지금까지 프로젝트를 해보면서 느낀 것은 '하나의 방법으로만 실험하는 건 별 의미가 없다'입니다.
가령, 프로젝트 구성원과 열띤 논의를 통해 D+1 예측으로 문제를 정의했다가도, 향후 D+7 예측이 필요한 상황으로 바뀔 수 있습니다. 심지어 단기 예측이 아닌 중・장기 예측이 필요한 상황이 추가될 수도 있죠. 그뿐만 아니라 비즈니스 도메인을 이해하면서 새롭게 추가할 변수를 찾게 된다면 또다시 실험을 해봐야 합니다. 이렇듯 요구사항과 데이터는 언제든 바뀔 수 있기에 어떤 알고리즘이 적절한지는 매번 테스트를 해봐야 하는 게 현실인 것 같습니다.
이처럼 문제 정의가 바뀌면 실험 설계도 달라질 가능성이 크기 때문에, 변화에 발맞춰 새로운 모델 성능을 빠르게 확인할 수 있는 환경이 필요했습니다.
그래서 이번 글에서는 알고리즘별 시계열 예측 성능 측정 모듈 개발 과정의 일부를 간단히 공유해보려고 합니다.
본 포스팅에서 사용한 데이터
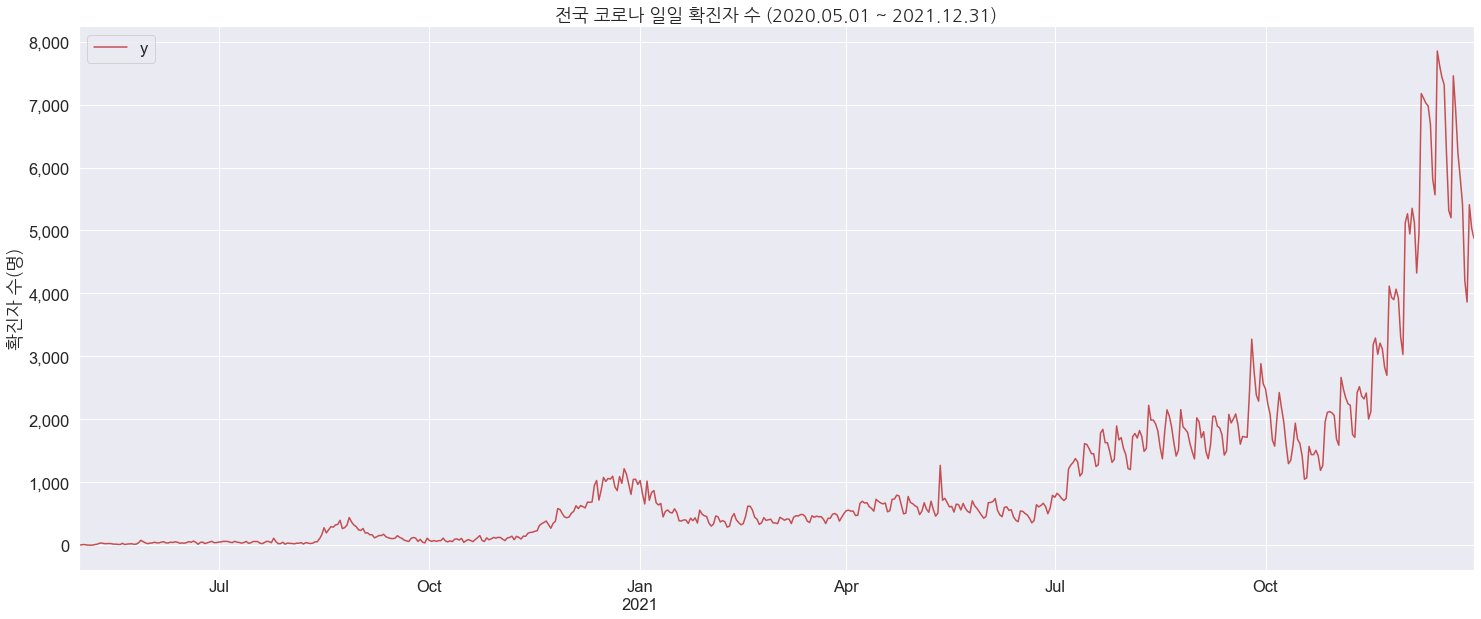
시계열 샘플 데이터는 Kaggle, UCI Machine Learning Repository 등에서 쉽게 얻을 수 있습니다. 근데 이번 글에서는 코로나 확진자 데이터를 사용했습니다. (이제 실외 마스크 해제가 가능해졌으니 하루빨리 종식되길 바라며..)
원래는 주가 데이터를 사용해 보려고 했으나.. 제 주식을 떠올리니 눈물 젖은 글을 쓸 것 같아 꾹 참았습니다. (크흑..)
이런 걸 만들었습니다
결론부터 보여드리자면, 예측 시작 시점, 예측 기간, 시계열 예측 모델을 원하는 형태로 지정하여 교차검증(Cross Validation)을 수행하는 함수를 개발했습니다. Cutoff에 따라 훈련 & 검증 데이터셋을 나누어 교차 검증을 수행하되, 원하는 모델을 언제든 추가하여 실행할 수 있도록 확장성을 고려하여 모듈을 개발했습니다.
>>> from time_series_forecast import forecast_cross_validation
>>> df_fcst = forecast_cross_validation(
df=df, # 예측에 사용할 pandas dataframe
freq="D", # 예측 주기 (D: Daily, W: Weekly, M: Monthly)
cutoffs=["2022-04-01"], # 예측 시작 시점
step=3, # 예측 기간 (2022-04-01 ~ 2022-04-03 예측)
model="arima" # 예측에 사용할 알고리즘 선택 (arima, prophet, lstm, ...)
)
>>> print(df_fcst)
model cutoff date y yhat yhat_lower yhat_upper yhat_naive
0 ARIMA 2022-04-01 2022-04-01 2224 2105.13 1944.76 2265.51 2224
1 ARIMA 2022-04-01 2022-04-02 1760 1765.64 1564.36 1966.92 2224
2 ARIMA 2022-04-01 2022-04-03 1715 1880.29 1654.24 2106.33 2224
>>> from time_series_forecast_evaluation import get_performace_metric
>>> df_perf = get_performace_metric(df=df_fcst) # 예측 성능 지표 계산
>>> print(df_perf)
{'mae': 906.85, 'mape': 20.81, 'mase': 6.22, 'coverage': 19.04, 'winkler': 6688.22}이처럼 cutoff, step, model을 다양하게 조합하여 성능을 비교할 수 있으며, 실행 결과를 아래의 사진처럼 만들 수 있습니다.
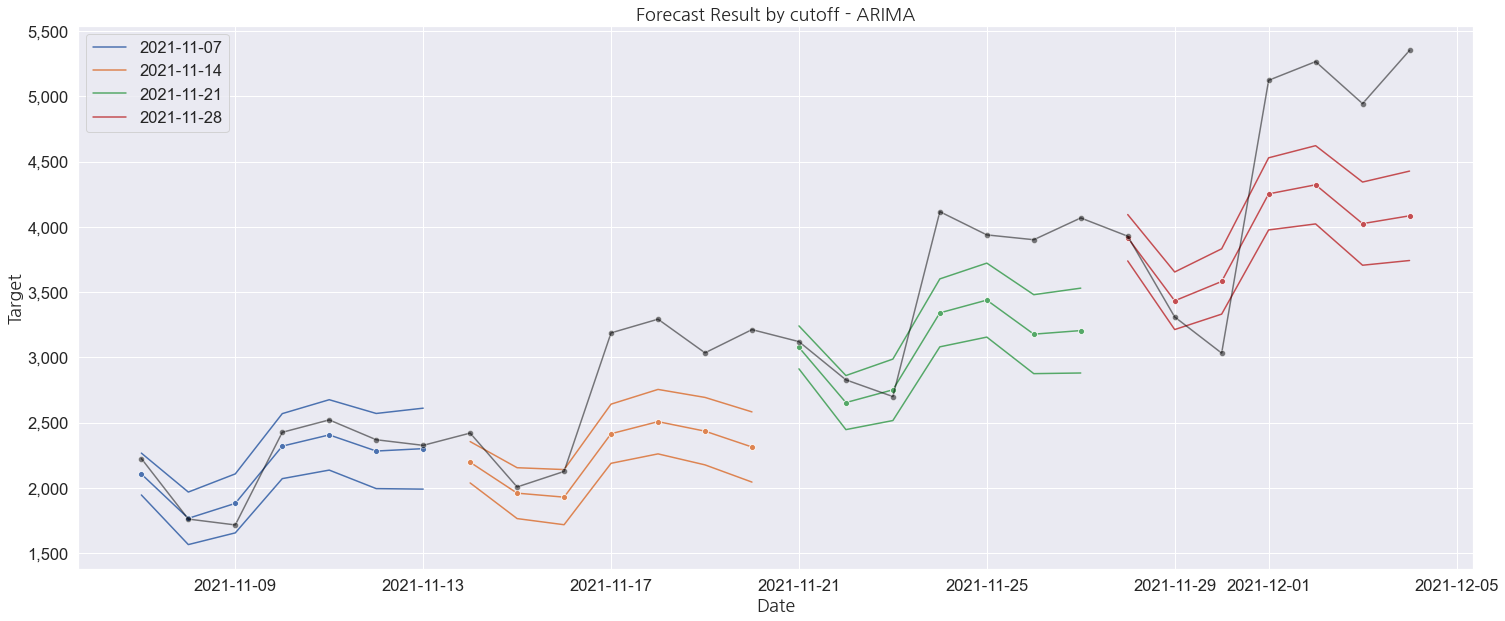
Cutoff는 무엇인가
시계열 데이터에서 특정 시점 전까지를 Train dataset으로 모델링하기 위해 사용하는 표현
시계열 예측에서 교차 검증은 흔히 알려진 Cross Validtion과 약간 차이가 있습니다. 너무 당연한 말이긴 하지만, 시계열은 시간의 순서를 유지해야 하므로 Row를 뒤섞어(suffling) 데이터셋을 나눌 수 없습니다.
그래서 예측 시작점을 따로 선택하고, 해당 시점 전까지를 훈련 데이터로 사용하여 그 이후를 step 만큼 예측하여 성능을 확인합니다.
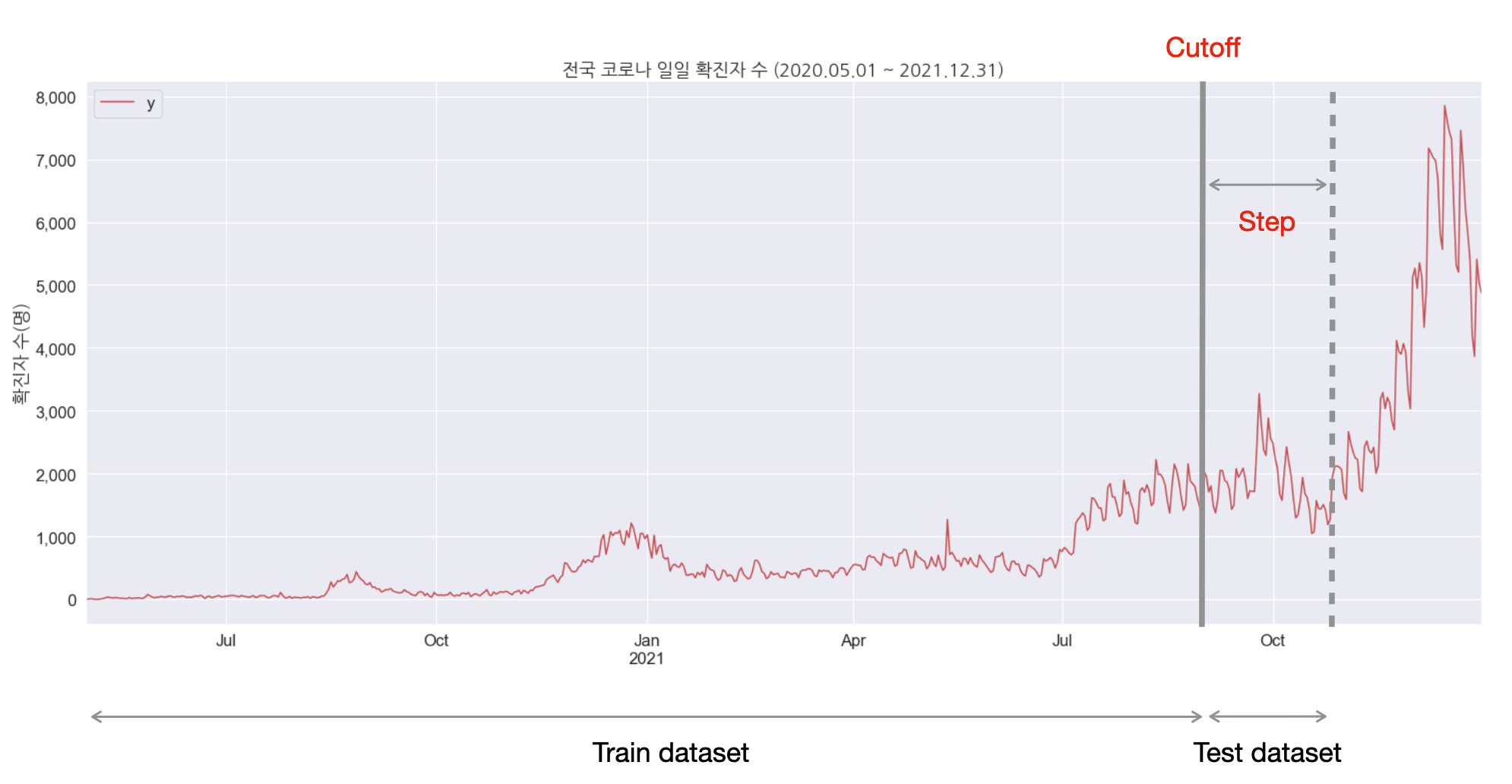
Cutoff를 아래와 같이 10개를 설정한다면 10개의 훈련 데이터 셋이 생기고, 각각 예측한 결과로 시간의 흐름에 따른 성능을 비교할 수 있습니다.

모듈 구조 (Functions in Module)
위에서 예시로 보여드린 모듈(time_series_forecast)의 구조는 대략 아래와 같습니다.
forecast_cross_validation(): 교차검증을 수행하는 main 함수 (forecast()호출)forecast(): cutoff에 따라 train, test dataset 분리 후 예측 실행 (fit_*()호출)fit_arima(): ARIMA 예측 모델fit_prophet(): Prophet 예측 모델fit_lstm(): LSTM 예측 모델fit_...(): 그 외 시계열 모델- ...
forecast_cross_validation()에서 모든 작업을 통제합니다. cutoff와 사용할 모델을 지정하면 그에 맞게 예측을 수행하는 구조입니다. 이렇게 메인 함수는 어느 정도 추상화를 해놓고, 시계열 예측에 사용할 모델을 튜닝하거나 추가하여 확장성이 용이하도록 설계했습니다.
단변량 시계열 예측 모듈 만들어보기 (hands-on 💻)
데이터에 따라 다르겠지만 대부분의 경우 단변량 예측은 다변량 예측에 비해 성능이 떨어지기 마련입니다. 다만, 이번 글에서는 모듈의 구조와 성능 비교까지의 흐름을 공유하는 게 목적이기 때문에 이해하기 쉬운 단변량 예측으로 설명한 점을 참고해 주세요.
이제 모듈을 간단한 버전으로 만들어보겠습니다. 여기서는 auto_arima와 prophet 두 가지만 사용했습니다.
1) 모델 반환 함수
먼저 알고리즘별로 모델을 반환하는 함수를 만들어 줍니다.
1.1) ARIMA
ARIMA는 과거 관측값과 오차항만으로 적합한 모형을 도출하는데, 주로 단기 예측에서 많이 사용합니다. 최적의 모형을 추정하려면 정상성을 확인하는 단위근 검정, 계절성 차수를 결정하기 위한 AICc 최소화, 최대 가능도 추정(MLE) 등의 복잡한 과정을 거쳐야 합니다. 그래서 보통 단변량 & 단기 예측을 할 때 이러한 단계를 통해 모형을 도출하는 auto_arima()를 많이 사용합니다.
from pmdarima.arima import auto_arima, ARIMA
def fit_arima(
df: pd.DataFrame,
params: dict = None
) -> ARIMA:
"""
ARIMA에 데이터를 fitting한 객체를 반환한다.
"""
if params is None:
ar = auto_arima(y=df["y"])
else:
ar = auto_arima(y=df["y"], **params)
print(ar.summary())
ar.fit(df["y"])
return ar1.2) Prophet
Prophet은 Meta(과거 Facebook)에서 개발한 시계열예측 라이브러리로, 학습 속도가 빠르고 계절성이 있는 데이터에 좋은 예측 성능을 보이며 seasonality, growth 등의 파라미터 튜닝이 가능한 모형입니다. ARIMA와 다르게 차분을 통해 정상성을 만족하는 형태로 변환할 필요가 없고, 결측치를 채워주지 않아도 예측이 가능하도록 설계된 라이브러리입니다.
특히, 휴일(Holiday)의 영향을 고려하는 것이 특징입니다. 특정 날짜를 이벤트로 인식하도록 feature를 추가로 넣어주면 해당 날짜 전후에 따른 영향을 학습하여 미래에 있을 같은 이벤트에 전후로도 그 영향을 반영해 주기 때문에 이것 역시 많이 사용합니다.
from prophet import Prophet
def fit_prophet(
df: pd.DataFrame,
params: dict = None
) -> Prophet:
"""
Prophet에 데이터를 fitting한 객체를 반환한다.
"""
if params is None:
m = Prophet()
add_seasonality = None
else:
if "add_seasonality" in params:
add_seasonality = params["add_seasonality"]
params_ = params.copy()
params_.pop("add_seasonality")
m = Prophet(**params_)
else:
m = Prophet(**params)
add_seasonality = None
if add_seasonality is not None:
if type(add_seasonality) == list:
for add in add_seasonality:
m.add_seasonality(**add)
elif type(add_seasonality) == dict:
m.add_seasonality(**add_seasonality)
else:
raise TypeError("TypeError: 'add_seasonality' is allowed dictionary or list type.")
m.add_country_holidays(country_name="KR")
m.fit(df)
return m
2) 예측 실행 함수
위에서 정의한 함수를 사용하여 예측 실행 함수를 만듭니다. 이 부분이 모델별 예측을 수행하는 함수이므로 새로운 시계열 예측 알고리즘을 추가할 때마다 여기에도 추가해 주는 방식으로 사용할 수 있습니다.
아래와 같은 아키텍쳐 보다는 예측 실행을 최종 담당하는 추상화된 클래스가 있고,
알고리즘별 예측 클래스를 상속받아 실행하는 형태로 개발한다면 더욱 좋습니다.
def forecast(
df: pd.DataFrame,
model: str,
cutoff: str,
steps: int,
freq: str = "D",
params: dict = None
) -> pd.DataFrame:
"""
시계열 예측 모델을 호출하여 cutoff로부터 steps 만큼 예측한 결과를 반환한다.
"""
series = pd.date_range(start=cutoff, periods=steps, freq=freq)
df_future = pd.DataFrame(series)
df_future.columns = ["date"]
if model == "prophet":
df = df.rename(columns={"date": "ds"})
df_future = df_future.rename(columns={"date": "ds"})
m = fit_prophet(df=df, params=params)
df_fcst = m.predict(df_future)
df_fcst = df_fcst.rename(columns={"ds": "date"})
elif model == "arima":
df = df.set_index("date").resample(rule=freq).ffill()
m = fit_arima(df=df, params=params)
pred, pi = m.predict(n_periods=steps, return_conf_int=True, alpha=.2)
df_fcst = pd.DataFrame(pi, index=df_future["date"], columns=["yhat_lower", "yhat_upper"])
df_fcst["yhat"] = pd.Series(pred, index=df_future["date"])
df_fcst = df_fcst.reset_index()
# 필요시 모델별 예측 조건 추가 가능
# elif model == "lstm": ...
# elif model == "lstm-stl": ...
# elif model == "prophet-stl": ...
else:
raise ValueError(
"Not found model. 'model' should be one of 'arima', 'prophet'."
)
return df_fcst3) 교차검증 실행 함수
이제 여러 cutoff를 통해 예측한 결과와 실제값을 비교해 볼 수 있는 메인 함수를 만들면 큰 그림은 어느 정도 완성입니다. 이것을 사용하여 모델별 예측값과 실제값이 담긴 결과를 생성하고, 해당 결과로부터 성능 지표(performance metrics)를 만들기만 하면 본 포스팅의 목적을 달성하게 됩니다.
def add_date(date: str, delta: int) -> str:
return (datetime.strptime(date, "%Y-%m-%d") + timedelta(days=delta)).strftime("%Y-%m-%d")
def forecast_cross_validation(
df: pd.DataFrame,
model: str,
cutoffs: list,
steps: int,
freq: str = "D",
params: dict = None
) -> pd.DataFrame:
"""
forecast()를 사용하여 cutoff로부터 steps 만큼 예측하고, 실제값(y)과 예측값(yhat)을 비교할 수 있는 dataframe을 반환한다.
"""
df_fcst_all = pd.DataFrame()
for cutoff in cutoffs:
print(f"\n ---------------------- cutoff: {cutoff} ---------------------- ")
date_end = add_date(date=cutoff, delta=steps - 1)
df_train = df[df["date"] < cutoff].reset_index(drop=True)
df_test = df[df["date"].between(cutoff, date_end)].reset_index(drop=True)
if len(df_test) == 0:
print("There is no test dataset for this cutoff.")
continue
else:
print(f"train dataset rows: {df_train.shape[0]}")
print(f"test dataset rows: {df_test.shape[0]}\n")
df_fcst = forecast(
df=df_train,
model=model,
cutoff=cutoff,
steps=steps,
freq=freq,
params=params
)
df_fcst = df_fcst.merge(df_test, on="date", how="left")
df_fcst["cutoff"] = cutoff
df_fcst["yhat_naive"] = df_train["y"].iloc[-1]
df_fcst_all = pd.concat([df_fcst_all, df_fcst], ignore_index=True)
df_fcst_all.insert(0, "model", model)
df_fcst_all = df_fcst_all[["model", "cutoff", "date", "y", "yhat", "yhat_lower", "yhat_upper", "yhat_naive"]]
return df_fcst_all3.1) 사용 예시
위에서 보여드린 샘플 데이터를 활용하여 2021.12.01부터 3일간의 multi step 예측 결과를 확인해 볼 수 있습니다.
# auto_arima에 하이퍼파라미터를 직접 전달하여 예측
df_fcst = forecast_cross_validation(
df=df,
cutoffs=["2021-12-01"],
steps=3,
freq="D",
model="arima",
params={
"seasonal": False,
"stepwise": True,
"trace": True,
"start_p": 5,
"max_p": 15,
"max_q": 5,
"max_order": 20,
"m": 0
}
)
+----+---------+------------+------------+------+---------+--------------+--------------+--------------+
| | model | cutoff | date | y | yhat | yhat_lower | yhat_upper | yhat_naive |
|----+---------+------------+------------+------+---------+--------------+--------------+--------------|
| 0 | arima | 2021-12-01 | 2021-12-01 | 5123 | 3928.96 | 3759.58 | 4098.33 | 3032 |
| 1 | arima | 2021-12-01 | 2021-12-02 | 5266 | 4004.15 | 3784.21 | 4224.08 | 3032 |
| 2 | arima | 2021-12-01 | 2021-12-03 | 4944 | 3774.39 | 3528.63 | 4020.15 | 3032 |
+----+---------+------------+------------+------+---------+--------------+--------------+--------------+이때 cutoff를 여러 개로 지정하여 예측을 실행하는 것이 이 함수의 주요 역할입니다.
# prophet에 하이퍼파라미터를 직접 전달하여 예측
forecast_cross_validation(
df=df,
cutoffs=["2021-12-01", "2021-12-04"], # cutoff를 여러 개로 설정하는 것이 포인트!
steps=3,
freq="D",
model="prophet",
params={"yearly_seasonality": True, "weekly_seasonality": True, "daily_seasonality": False}
)
+----+---------+------------+------------+------+---------+--------------+--------------+--------------+
| | model | cutoff | date | y | yhat | yhat_lower | yhat_upper | yhat_naive |
|----+---------+------------+------------+------+---------+--------------+--------------+--------------|
| 0 | prophet | 2021-12-01 | 2021-12-01 | 5123 | 3318.81 | 3046.54 | 3571.58 | 3032 |
| 1 | prophet | 2021-12-01 | 2021-12-02 | 5266 | 3324.61 | 3086.13 | 3578.71 | 3032 |
| 2 | prophet | 2021-12-01 | 2021-12-03 | 4944 | 3330.05 | 3059.28 | 3570.91 | 3032 |
| 3 | prophet | 2021-12-04 | 2021-12-04 | 5352 | 3673.2 | 3392.92 | 3975.52 | 4944 |
| 4 | prophet | 2021-12-04 | 2021-12-05 | 5128 | 3639.85 | 3346.52 | 3920.09 | 4944 |
| 5 | prophet | 2021-12-04 | 2021-12-06 | 4325 | 3568.89 | 3299.8 | 3860.35 | 4944 |
+----+---------+------------+------------+------+---------+--------------+--------------+--------------+4) 성능 지표 계산 함수
시계열 예측 성능을 비교하는 몇 가지 metric이 있는데, 이것을 계산하는 함수까지 만들면 끝입니다!
아래는 시계열 예측에서 성능 지표로 많이 사용하는 것을 나열한 것인데, 여기에선 MAE, MAPE 두 가지만 사용하여 만들어보겠습니다.
- R-Squared
- Mean Absolute Error (MAE) ✅
- Mean Absolute Percentage Error (MAPE) ✅
- Mean Squared Error (MSE)
- Root Mean Squared Error(RMSE)
- Normalized Root Mean Squared Error (NRMSE)
- Winkler scores
def get_performance_metrics(df_fcst: pd.DataFrame) -> dict:
"""
시계열 예측 결과가 담긴 DataFrame으로부터 performance metrics을 계산하여 반환한다.
"""
true = df_fcst["y"]
pred = df_fcst["yhat"]
mae = (true - pred).abs().mean()
mape = (true - pred).abs().div(true).mean() * 100
n_cover = (((true - df_fcst["yhat_lower"]) > 0) & ((true - df_fcst["yhat_upper"]) < 0)).sum()
coverage = (n_cover / (true > 0).sum()) * 100
return {"mae": mae, "mape": mape, "coverage": coverage}5) 모델별 성능 지표 비교하기
이 정도면 대충 준비는 끝났습니다. 2021년 11월의 매주 일요일을 Cutoff로 놓고 D+3을 예측하여 성능을 비교해 보겠습니다.
# cutoff 리스트 생성
cutoffs = ['2021-11-07', '2021-11-14', '2021-11-21', '2021-11-28']
# Prophet 예측
df_fcst_prophet = forecast_cross_validation(
df=df,
cutoffs=cutoffs,
steps=3,
freq="D",
model="prophet",
params={"yearly_seasonality": True, "weekly_seasonality": True, "daily_seasonality": False}
)
# ARIMA 예측
df_fcst_arima = forecast_cross_validation(
df=df,
cutoffs=cutoffs,
steps=3,
freq="D",
model="arima",
params={
"seasonal": False,
"stepwise": True,
"trace": True,
"start_p": 5,
"max_p": 15,
"max_q": 5,
"max_order": 20,
"m": 0
}
)
# 예측 결과 합치기
df_fcst = pd.concat([df_fcst_prophet, df_fcst_arima], ignore_index=True)
# 각 cutoff의 모델별 예측 성능 지표 생성
df_perf = pd.DataFrame()
for model in df_fcst["model"].unique():
for cutoff in cutoffs:
df_fcst_tmp = df_fcst[(df_fcst["cutoff"]==cutoff) & (df_fcst["model"]==model)].reset_index(drop=True)
metric_dict = get_performance_metrics(df_fcst_tmp)
metric_dict["model"] = model
metric_dict["cutoff"] = cutoff
df_perf_tmp = pd.Series(metric_dict).to_frame().T
df_perf = pd.concat([df_perf, df_perf_tmp], ignore_index=True)
# 각 cutoff의 naive 예측 성능 생성
for cutoff in cutoffs:
df_fcst_tmp = df_fcst[df_fcst["cutoff"]==cutoff].reset_index(drop=True)
metric_dict = get_performance_metrics(df_fcst_tmp.drop("yhat", axis=1).rename(columns={"yhat_naive": "yhat"}))
df_perf_tmp = pd.Series(metric_dict).to_frame().T
df_perf_tmp["cutoff"] = cutoff
df_perf_tmp["model"] = "naive"
df_perf = pd.concat([df_perf, df_perf_tmp], ignore_index=True)
df_perf = df_perf[["model", "cutoff", "mae", "mape", "coverage"]]
# Performance metrics 시각화
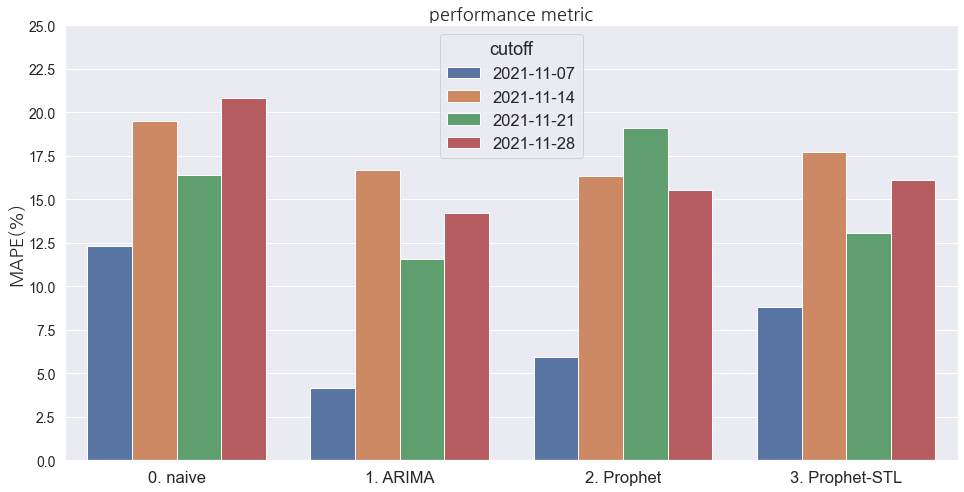
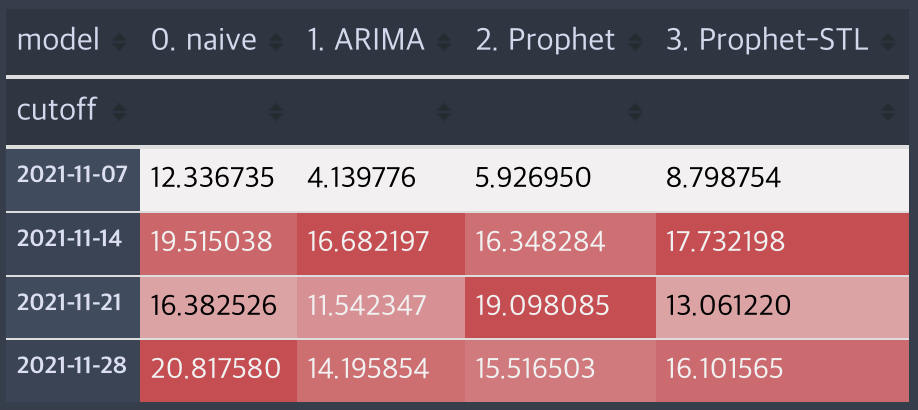
plt.figure(figsize=(16, 8))
sns.barplot(data=df_perf, x="model", y="mape", hue="cutoff")
_ = plt.yticks(np.linspace(0, 25, 11), fontsize=14)
_ = plt.yticks(fontsize=14);대체로 ARIMA가 상대적으로 좋은 성능을 나타내는 것으로 보입니다. 이런 식으로 시간의 흐름에 따른 예측 성능을 지속 확인할 수 있다면, 현시점의 오차를 파악하는데 조금이라도 도움이 될 수 있을 것 같습니다. 또, 최소한 Naive 예측 결과 보다 좋은지를 확인하는 게 모델 선택의 기준점이 되기도 합니다. (해당 샘플 코드는 하나의 방법일 뿐, 절대적인 방법은 아닙니다!)
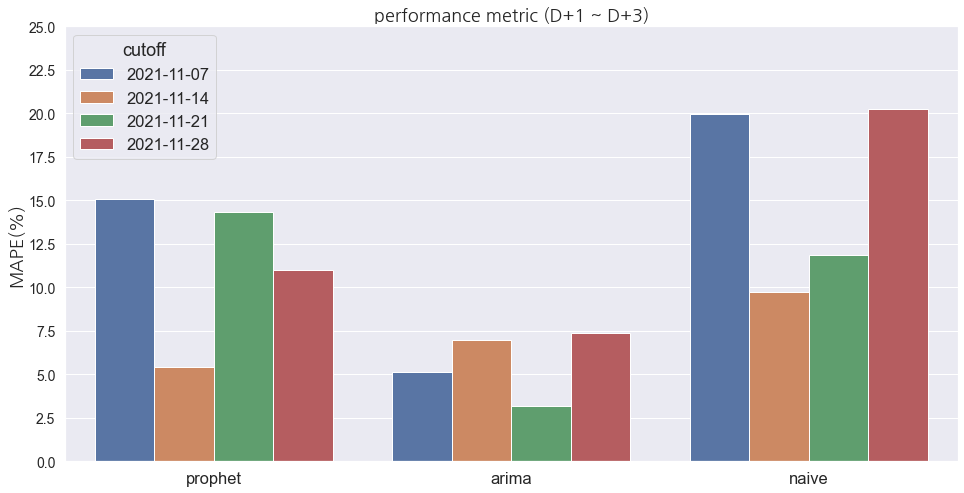
어떻게 활용하면 좋을까요 🤔
열심히 만들었는데 목적에 맞게 잘 활용하는 것도 중요하겠죠. 이 모듈의 큰 목적은 '시간의 흐름에 따라 모델의 성능이 어떻게 변화하는가'를 보는 것입니다.
만약 전반적으로 모든 모델의 성능이 큰 변동없이 비슷한 수준을 보이면서, 만족할만한 예측력이라면 그 중에서 best 모델을 선택하는 기준을 충분히 잡을 수 있을 것입니다.
혹은 예측하려는 Target의 변동성이 애초에 커서 전반적으로 모델 성능이 출렁인다면 모델 튜닝이 필요하거나, 현재의 데이터셋만으로 설명이 불가능한 또 다른 변수를 찾아야 한다는 신호를 감지할 수 있는 용도로 사용할 수도 있습니다. (제가 실제로 이렇게 사용하고 있습니다!)
추가해보면 좋을 것들
이 글에 적진 않았지만 따로 추가하면 더 좋을 것 같은 기능도 나열해 봤습니다.
- 다른 예측 모델을 추가해보면서 비교하면 더욱 좋습니다. (LSTM, LGBM, …)
- 모델별 하이퍼파라미터별 성능 비교 모듈이 있으면 좋습니다.
- Cutoff별 예측 실행을 병렬로 처리할 수 있으면 좋습니다.
- Cutoff를 일, 주, 월별로 반환하는 함수를 만들어서 사용하면 좋습니다.
- 데이터셋으로 사용하는 DataFrame에 반드시 있어야 할 컬럼명을 검증하는 Validator 함수가 있으면 좋습니다.
- 데이터셋 결측치를 Interpolation 해주는 함수를 만들어 놓으면 좋습니다.
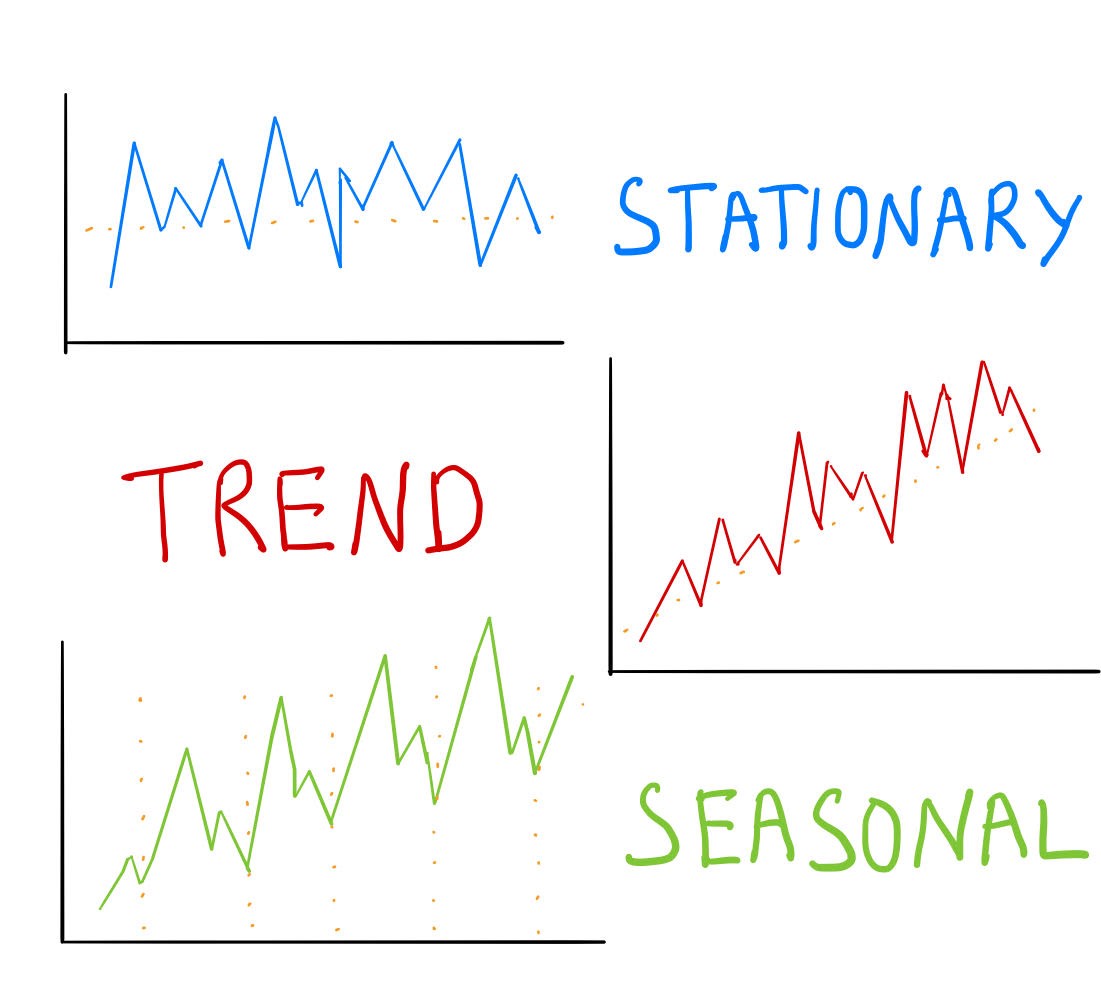
- STL을 통해 시계열을 분해하여 Trend, Seasonality, Residual를 반환하는 함수가 있으면 좋습니다. 예측 시 특정 요소를 제거하여 시도해볼 수 있습니다.
마무리 ⌛️
(와 드디어 다 썼다!)
시계열 모델 성능 비교를 위해 이해하기 쉬운 단변량 예측에 초점을 두고 모듈 개발의 컨셉을 공유해 봤습니다.
사실 코사인이나 사인 그래프 마냥 아름다운 계절성과 트렌드를 보이는 시계열 데이터가 아닌 이상, 단변량으로 정확도 높은 예측을 해내는 것은 상당히 어려운 일입니다. 결국 다양한 변수를 추가해 보면서 성능을 끌어올리는 작업은 필연적이기 때문에 이 글에서 제안한 코드 보다는 훨씬 복잡한 수준이 될 것입니다. 또, 모델을 추가할수록 더 모듈 내 기능을 잘 분리해야 하죠. 그래서 더더욱 모델별 비교를 위한 환경을 잘 준비해야 하지 않을까 싶습니다.
시계열 예측을 처음 시작한 지 얼마 안 되었을 때, 모델별로 모듈을 각각 만들고 있었습니다. 그러다가 문득 '이거 이러다가 더 많은 모델을 실험하면 점점 비교가 어려워지겠다'라는 생각이 자연스럽게 들었고, 이것을 해결하기 위해 본 포스팅에서 작성한 흐름대로 모듈을 개발했습니다.
시계열 데이터는 시간이 지남에 따라 얼마든지 '좋은' 모델이 달라질 수 있습니다. 과거의 패턴을 특정 시점에만 학습을 시키고, 해당 모델로만 계속 예측을 하다 보면 분명히 불확실성이 높은 예측 구간이 발생하기 마련입니다. 그러므로 현재 만들고 있는 시계열 모델들을 언제든 비교할 수 있는 환경을 미리 만들어 놓는 것도 좋을 것 같습니다.
이 글을 보신 분들 중 시계열 예측을 처음 시작하시거나, 혹은 저처럼 어려움을 겪었던 분들에게 도움이 되었으면 좋겠네요!



내용이 알차네요. 감사합니다!