데이터 수집
이전 포스팅에서 단순 3분봉 1000개로 백테스팅을 진행해보았는데, 고작 3일도 안되는 양이기 때문에 전략 검증에 있어서 신뢰도가 매우 낮다. 기본편에서 바이낸스 3분봉 데이터를 받아오는 API를 활용해서 3년 이상의 3분봉 데이터로 DB를 구축해보자.
DB에 데이터 넣기
from binance.spot import Spot
import datetime
import mplfinance as mpf
import pandas as pd
# MYSql 디비의 테이블에 데이터 넣기
# 디비 및 테이블 생성에 대해서는 해당 블로그에서 다루지 않음. 구글링 참조
import time
import pymysql
con = pymysql.connect(host='jikding.net', user='lazydok', password='13cjswo79', db='fin', charset='utf8')
# cur = con.cursor(pymysql.cursors.DictCursor)
cur = con.cursor()
client = Spot()
print(client.time())
client = Spot(key='', secret='') # 본인의 바이낸스 KEY 입력
def insert_chart(data, symbol, interval):
for i in range(len(data)):
data[i][0] = pd.to_datetime(data[i][0], unit='ms').strftime('%Y-%m-%d %H:%M:%S')
data[i][6] = pd.to_datetime(data[i][6], unit='ms').strftime('%Y-%m-%d %H:%M:%S')
# print(data[i])
# raise Exception
sql = """
REPLACE INTO CHART_{}_{}
VALUES (
%s,%s,%s,%s,%s,
%s,%s,%s,%s,%s,
%s,%s
)
""".format(symbol, interval.upper())
cur.executemany(sql, data)
con.commit()
UTC_PLUS_9 = 9 * 60 * 60 * 1000
start_time = int(time.mktime(datetime.datetime.strptime('2018-01-01 00:00:00', '%Y-%m-%d %H:%M:%S').timetuple()) * 1000)
start_time += UTC_PLUS_9
stop_time = int(time.mktime(datetime.datetime.strptime('2021-01-01 00:00:00', '%Y-%m-%d %H:%M:%S').timetuple()) * 1000)
stop_time += UTC_PLUS_9
end_time = 0
while end_time < stop_time:
print(pd.to_datetime(start_time, unit='ms'))
end_time = start_time + 1000 * 60 * 3 * 1000 - 1
data = client.klines(symbol='BTCUSDT', interval='3m', startTime=start_time, endTime=end_time, limit=1000)
insert_chart(data, 'BTCUSDT', '3m')
start_time = end_time
time.sleep(60/1200)데이터 불러오기
sql = "SELECT * FROM CHART_BTCUSDT_3M WHERE DATETIME BETWEEN '20210101' AND '20220312'" # 21년 ~ 22년 3월 까지 데이터
cur.execute(sql)
data = cur.fetchall()
df = pd.DataFrame(data, columns=
[
'datetime',
'open',
'high',
'low',
'close',
'volume',
'closeTime',
'QuoteAssetVolume',
'NumTrades',
'TakerBuyBaseAssetVolume',
'TakerBuyQuoteAssetVolume' ,
'Ignore'
]
)
# df['datetime'] = pd.to_datetime(df['datetime'], unit='ms')
df.set_index('datetime', inplace=True)
df = df[['open', 'high', 'low', 'close', 'volume']]
df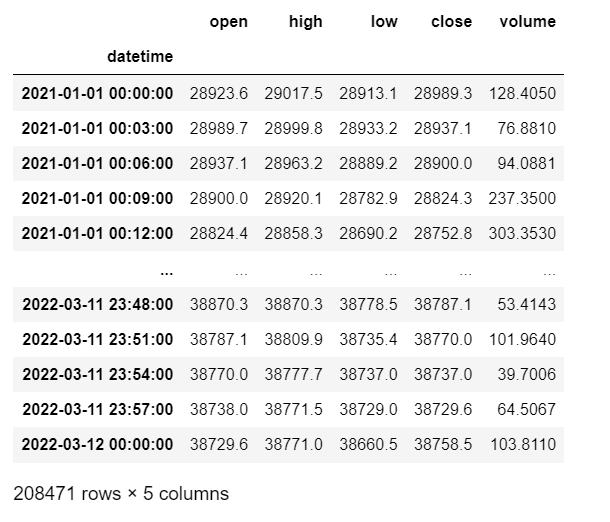
208471건의 데이터를 불러왔다.
Vectorized 백테스팅이란?
Event Driven 방식의 장단점
위 20만건 이상의 데이터를 For문으로 하나하나 이벤트 발생여부를 검증하고 계산하는 방식은 가장 현실적이며 논리적으로도 단순하다. 실제 라이브에서 전략을 투입할때도 Event Driven방식으로 진행되니 당연한 접근이다. 하지만 전략을 테스트 해보기위해 수없이 많은 시도와 튜닝을 하기위해서는 속도가 중요하다.
이전 포스팅을 활용하여 백테스팅 해보자.
간단하게 MACD Signal 을 활용한 전략이다.
acc = {
'CASH': 1,
'F_BTC': {
'LONG': {'QTY': 0, 'MARGIN': 0, 'PRC': 0, 'DATETIME': None},
'SHORT': {'QTY': 0, 'MARGIN': 0, 'PRC': 0, 'DATETIME': None}
}
}
eval_amt_hist = []
td_hist = []
pre_prc = 0
s_t = time.time()
for i, (date, row) in zip(range(len(df)), df.iterrows()):
long = acc['F_BTC']['LONG']
short = acc['F_BTC']['SHORT']
if i == 0: # 최초
pre_macd_diff = 0
long['DATETIME'] = date
short['DATETIME'] = date
print(acc)
elif i + 1 == len(df): # 마지막
''
else: # 나머지
pre_macd_diff = df.iloc[i-1]['MACD_DIFF']
now_macd_diff = row['MACD_DIFF']
prc = df.iloc[i+1]['close'] # 매수, 매도시 가격은 이벤트 발생 다음 봉의 시가
if pre_macd_diff < 0 and now_macd_diff > 0:
# SHORT 청산
if short['QTY'] > 0:
acc['CASH'] += (short['PRC'] - prc) * short['QTY'] + short['MARGIN']
rt = short['PRC']/prc - 1
term = (date - short['DATETIME']).total_seconds()
td_hist.append({'RETURN': rt, 'TERM': term})
acc['F_BTC']['SHORT'] = {'QTY': 0, 'MARGIN': 0, 'PRC': 0, 'DATETIME': None}
short = acc['F_BTC']['SHORT']
# LONG 진입
cash = acc['CASH']
qty = cash / prc
long['QTY'] = qty
long['PRC'] = prc
long['MARGIN'] = cash
long['DATETIME'] = date
acc['CASH'] -= cash
elif pre_macd_diff > 0 and now_macd_diff < 0:
# LONG 청산
if long['QTY'] > 0:
acc['CASH'] += (prc - long['PRC']) * long['QTY'] + long['MARGIN']
rt = prc/long['PRC'] - 1
term = (date - long['DATETIME']).total_seconds()
td_hist.append({'RETURN': rt, 'TERM': term})
acc['F_BTC']['LONG'] = {'QTY': 0, 'MARGIN': 0, 'PRC': 0, 'DATETIME': None}
long = acc['F_BTC']['LONG']
#SHORT 진입
cash = acc['CASH']
qty = cash / prc
short['QTY'] = qty
short['PRC'] = prc
short['MARGIN'] = cash
short['DATETIME'] = date
acc['CASH'] -= cash
eval_amt = acc['CASH']
eval_amt += (row['close'] - long['PRC']) * long['QTY'] + long['MARGIN']
eval_amt += (short['PRC'] - row['close']) * short['QTY'] + short['MARGIN']
eval_amt_hist.append(eval_amt)
pre_macd_diff = row['MACD_DIFF']
print('종료, 실행 시간: {}'.format(time.time() - s_t))
df['return'] = eval_amt_hist
bt = df[['return']].copy()
bt['BM'] = df['close']/df['close'].iloc[0]
bt.plot(figsize=(20,10))종료, 실행 시간: 42.81160569190979
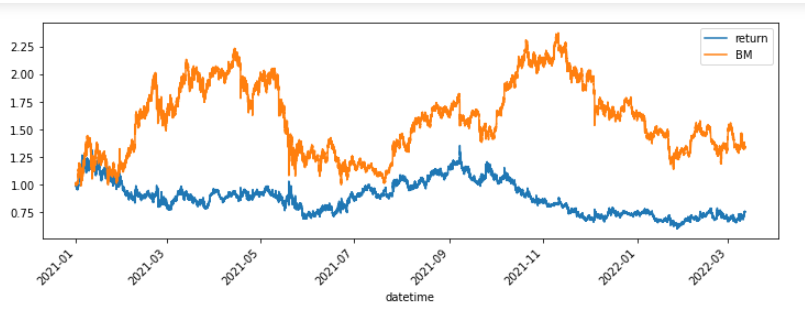
일단 전략 수익률이 형편없다. 조금 수정해서 다시 백테스팅 하려고 할때,
실행시간이 42.81초가 넘게 걸렸다. 살짝 전략에서 수치를 바꿔서 다시 돌리려면 또 1분가까이 시간이 걸릴것이다. 한종목 2년치를 돌리는데도 이렇게 시간이 많이 걸리는데 동시에 10종목이상의 포트폴리오 백테스팅을 하려면 상상도 못할 시간이 걸릴것이다. 수십만건 이상의 데이터를 For문으로 하나하나 연산하는 것은 컴퓨터입장에서 너무 비효율적인 연산이다.
Vectorized 연산이란?
Python에서는 Pandas를 이용해서 쉽게 백터연산을 할 수 있다. 예를들어 5, 6, 7, 6, 5 이렇게 5개의 숫자에대해 각 1을 더하는 연산을 해보자.
Event Driven 방식의 경우 For 문을 돌며 각 숫자에 1씩을 더하는 5번의 연산을 하게된다. 하지만 백터 연산의 경우 5개 수에대해 한번에 1을 더하는 내부적 연산을 하게된다. 이런 연산이 몇십만건 몇백만건이 넘어가면 백터연산과 반복문 연산의 속도는 엄청나게 차이가 난다.
참고로 위 동일 데이터로 동일 전략 테스트를 하게 될경우 백터연산방식은 0.5초 정도 소요가된다. 즉 위 케이스에서는 속도가 100배 정도 빠르다.
백터연산의 단점
10, 11, 12, 11, 10 의 다섯개 수에대해 일괄적으로 1을 더하는 간단한 연산같은경우 반복문을 통하지 않고도 한번에 컴퓨터가 쉽게 병렬연산을 통해서 답을 낼 수 있다. 다만 반복문을 통해서 전 후 관계에 따른 별도 연산은 백터연산으로 구현하기가 매우 까다롭거나 불가능하다. 예를들어
11이 넘으면 매수 11 밑으로 떨어지면 매도라는 전략이 있다고하자. 백터연산으로 해당전략을 통해서 언제 매수, 매도햇는지. 그리고 저 조건에 따른 거래로 수익률이 얼마나 발생했는지 연산을 하려면 일괄연산으로는 당장 계산할 수 없어 보인다.
Vectorized Backtesting 구현
Log Return
반복문을 사용하지 않고 특정조건에 매수, 매도를 통한 수익률을 계산하기 위해서는 Log를 활용할 수 있다.
를 t시간의 Log 리턴(Log 수익률), 는 t시간대의 가격이라 할때 t-1에서 t 시간대까지의 리턴은
로 표현할 수 있다.
t = 1, 2, 3 즉, 3개의 시간대동안 로그리턴은 아래와 같다.
위 식을 통해 t가 0부터 3까지 수익률은 단순 로그리턴 합에 대해 exp를 취해주면 된다. 즉 t 부터 T 까지의 수익률은 t 부터 T까지의 로그리턴의 합만 구하고 해당 값에 exp만 취하면 된다.
전략 백테스팅
로그리턴 및 포지션을 먼저 백터연산으로 구해보자.
# Log Retrun
rs = df['close'].apply(np.log).diff(1)
# 포지션 구하기(MACD가 Signal을 상향 돌파시 롱, 하향 돌파시 숏
pos = df['MACD_DIFF'].apply(np.sign) # +1 if long, -1 if short
# MACD OSC 및 롱 숏 포지션 표현하기
fig, ax = plt.subplots(2,1)
df['MACD_DIFF'].iloc[-1000:].plot(ax=ax[0], title='MACD OSC')
pos.iloc[-1000:].plot(ax=ax[1], title='Position', figsize=(20, 10))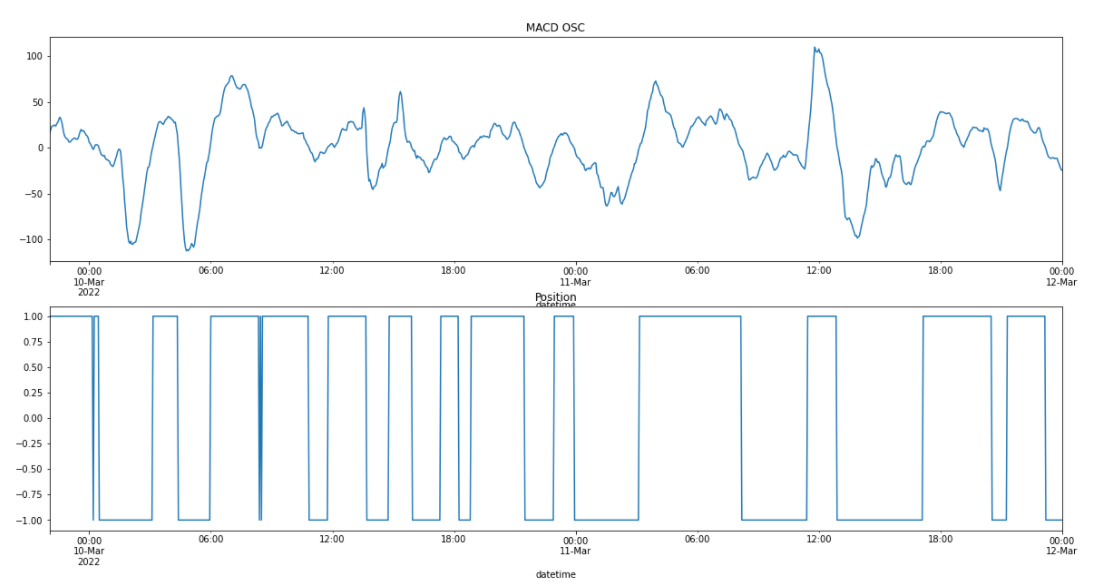
로그리턴 및 포지션을 통해서 백테스팅 수익률 그래프를 그려보자.
my_rs = pos.shift(1)*rs # 다음봉 종가 가격으로 샀다고 가정
bt = pd.DataFrame()
bt['return'] = my_rs.cumsum().apply(np.exp)
bt['BM'] = df['close']/df['close'].iloc[0]
bt.plot(figsize=(20,10))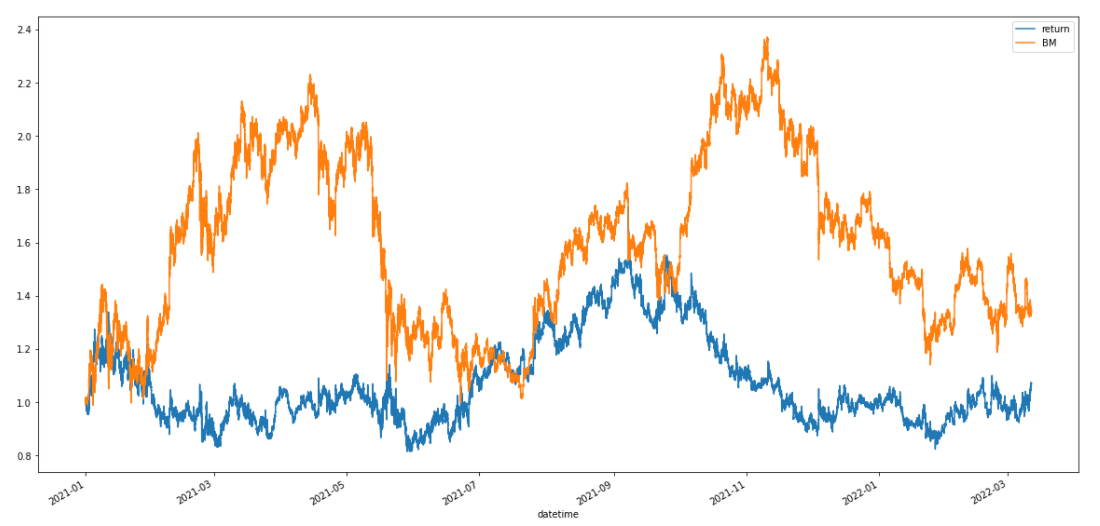
백테스팅 Summary
mdd = ((bt['return'] - bt['return'].cummax()) / bt['return'].cummax()).min()
bm_mdd = ((bt['BM'] - bt['BM'].cummax()) / bt['BM'].cummax()).min()
years = (bt.index[-1] - bt.index[0]).total_seconds()/60/60/24/365
cagr = (bt['return'][-1])**(1/years) - 1
bm_cagr = (bt['BM'][-1] / bt['BM'][0])**(1/years) - 1
sharpe_ratio = (bt['return'][-1] - 1)/bt['return'].std()
test = pd.DataFrame()
test['close_diff_log'] = rs
test['position_chaged'] = pos.shift(1).diff(1).abs()
test['position_chaged'][test['position_chaged'] == 0] = np.nan
test['grp'] = test.index.astype(int)
test['grp'] = test['position_chaged'] * test['grp']
test['grp'] = test['grp'].fillna(method='ffill')
is_win = np.exp(test.groupby('grp')['close_diff_log'].sum()).apply(lambda v: 1 if v > 1 else 0)
num_tds = len(is_win)
win_rate = is_win.sum() / num_tds
win_rate
summary = {
'MDD': round(mdd * 100, 2),
'CAGR': round(cagr * 100, 2),
'ALPHA': round((cagr-bm_cagr) * 100, 2),
'SHARPE_RATIO': round(sharpe_ratio, 2),
'-CAGR/MDD': round(cagr/-mdd*100,2),
'WIN_RATE': round(win_rate*100, 2),
'TOT_TRADE_CNT': num_tds
}
s_df = pd.DataFrame.from_dict(summary, orient='index').rename(columns={0:'Summary'})
s_df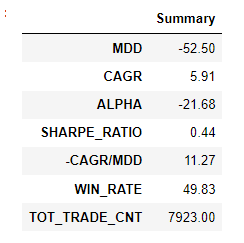
해당 테스트는 Event Driven 방식처럼 정교한 전략을 테스트 할 수 없고, 수익률 자체도 정확하지 않다. 다만, 아이디어를 통한 전략 생성 및 튜닝은 백터방식으로 여러번 돌려서 좋은전략을 만든 다음 event driven 방식의 백테스팅으로 상세 검증을 해야한다.
슬리피지 적용
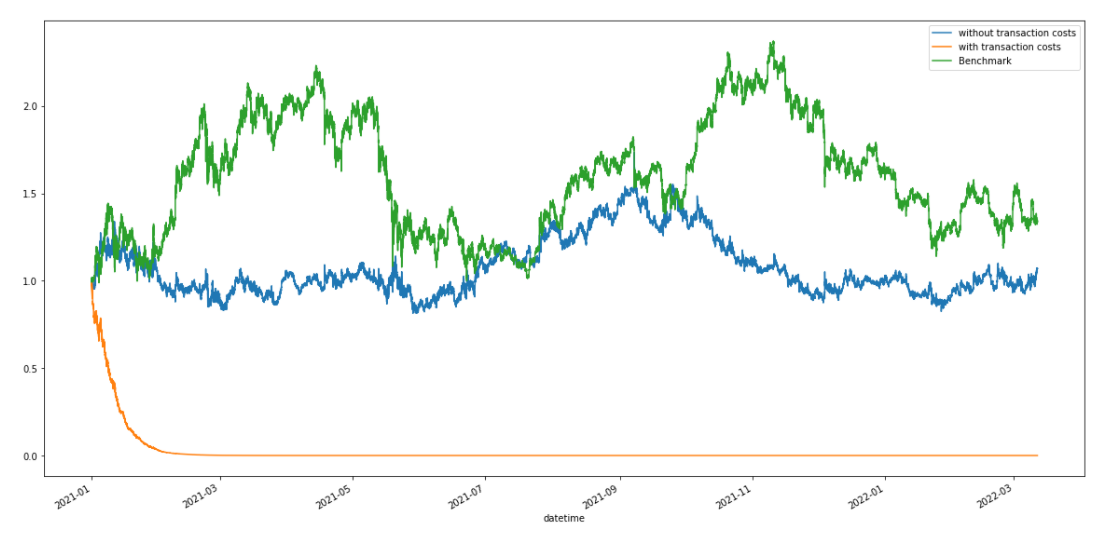
# 벡터연산 수수료 다시 구하기.
rs = df['close'].apply(np.log).diff(1)
pos = df['MACD_DIFF'].apply(np.sign) # +1 if long, -1 if short
tc = 0.003 # assume transaction cost of 0.3%
tc_rs = pos.diff(1).abs() * tc
my_rs1 = pos.shift(1)*rs # don't include costs
my_rs2 = pos.shift(1)*rs - tc_rs
bt = pd.DataFrame()
bt['return'] = my_rs2.cumsum().apply(np.exp)
bt['BM'] = df['close']/df['close'].iloc[0]
my_rs1.cumsum().apply(np.exp).plot(figsize=(20, 10))
bt['return'].plot()
bt['BM'].plot()
plt.legend(['without transaction costs', 'with transaction costs', 'Benchmark'])