
Basic Concepts
- 프로그램 실행은 CPU 실행과 입출력의 반복
- CPU burst : 프로세스가 CPU 실행을 이어나가는 것
- I/O burst : 프로세스가 입출력을 하는 구간
- 프로세스는 CPU burst와 I/O burst를 반복하다가 마지막 CPU burst 이후에 종료 시스템콜로 마무리 됨
- 프로세스마다, 컴퓨터마다 차이가 있긴하지만 전반적으로 프로세스는 짧은 CPU burst(5millisecond 미만)를 많이 갖고 긴 CPU burst(10millisecond 이상)는 적게 가짐
CPU Scheduler
- Short-term scheduler
- ready queue에서 다음에 실행할 프로세스를 선택
- kernel 내에서 CPU scheduling이 일어나는 지점
- 현재 실행 중인 프로세스가 입출력을 요청하는 순간
- 다음에 실행할 프로세스 선택
- 현재 실행 중인 프로세스가 ready 상태로 돌아가는 상황
- 1번과 원인은 다르지만 다음에 실행할 프로세스를 선택
- 새로 ready 상태가 되는 프로세스가 생기는 때
- 새로 ready 상태가 된 프로세스가 현재 실행 중인 running 프로세스보다 실행하기에 적합한 경우
- 실행 중인 프로세스가 종료하는 경우
- 새로 실행할 프로세스를 선택
- 현재 실행 중인 프로세스가 입출력을 요청하는 순간
- non-preemptive scheduling, cooperative scheduling (비선점형 스케줄링) : OS가 1번과 4번의 경우에만 CPU scheduling을 하는 경우
- preemptive scheduling (선점형 스케줄링) : 1번~4번 모든 경우에서 scheduling이 이뤄지는 경우
- race condition이 발생할 수 있으며 interrupt 처리를 세심하게 해야 함
- 비선점형에 비해서 복잡하지만 응답성이 우수함
Dispatcher
- kernel 안에 있는 module 중 하나
- 단기 스케줄러가 선택한 프로세스에게 CPU 제어를 넘겨주는 역할
- 단기 스케줄러를 호출해서 새 프로세스를 선택하고 문맥 교환을 하는 것까지 아우름
- 문맥 교환 수행
- 사용자 모드 전환
- 사용자 프로그램의 적절한 위치로 분기 수행
- Dispatch latency
- dispatcher가 한 프로세스를 정지시키고 다른 프로세스의 수행을 시작시키는데 걸리는 시간
- dispatcher는 모든 프로세스가 문맥 교환을 해야 하는 시점에 호출되므로 최대한 빨리 수행되어야 함
Scheduling Criteria
- 각 CPU 스케줄링 알고리즘마다 특성이 있으며 성능 비교를 위한 기준들이 있음
- CPU Utilization
- CPU 이용률
- 가능한 CPU를 최대한 바쁘게 유지하고자 함
- Throughput
- 처리량 (단위 시간당 완료된 프로세스의 개수)
- Turnaround time
- 프로세스의 시작 시간부터 완료까지 걸리는 시간
- 프로그램이 메모리에 적재되기 위해 기다린 시간 + ready queue에서 머무르며 대기한 시간 + CPU에서 실행한 시간 + 입출력을 하는데 걸리는 시간
- Waiting time
- 프로세스가 ready queue에서 대기하면서 보낸 시간의 합
- Response time
- 프로세스의 실행을 시작한 후 첫 번째 응답(출력)이 나올 때까지 걸리는 시간
- CPU Utilization, Throughput은 극대화
- Turnaround time, Waiting time, Response time은 최소화 하는 것이 바람직
- Time-sharing 시스템이나 Interactive 시스템에서는 Response time이 중요
- 일괄처리 시스템이나 Batch 시스템에서는 Turnaround time이 중요
Scheduling Algorithms
- ready queue에 있는 프로세스 중 다음에 어느 프로세스에게 CPU를 할당할 것인지 결정
FCFS (First-Come, First-Served)
- CPU를 먼저 요청하는 프로세스가 우선적으로 CPU를 할당받는 방식
- CPU burst가 다 할 때까지 계속 CPU를 사용하는 비선점형 스케줄링
Example
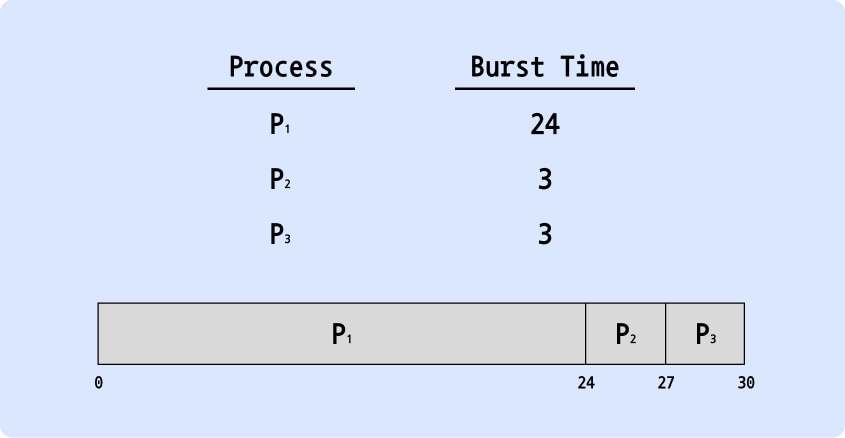
- 프로세스 P1, P2, P3가 순서대로 ready queue에 도착한 상태를 가정
- Waiting time
- P1 = 0
- P2 = 24
- P3 = 27
- average = 17
- 만약 아래와 같이 P2, P3, P1 순서대로 도착했을 경우

- Waiting time
- P1 = 6
- P2 = 0
- P3 = 3
- average = 3
- 평균 대기 시간이 크게 짧아짐
- Waiting time
- Convoy effect
- 하나의 긴 프로세스를 다른 프로세스들이 기다리는 현상
- FCFS에서 하나의 CPU-bound 프로세스와 여러 개의 I/O-bound 프로세스들 간에 이런 현상이 나타날 수 있음
SJF (Shortes Job First)
- ready queue 내에 있는 프로세스들 중 CPU burst가 가장 짧은 프로세스를 선택
- 프로세스 전체 길이가 아닌 다음 CPU burst만 고려
- 프로세스 집합에 대해 평균 대기 시간을 최소화한다는 점에서 최적의 스케줄링 방식
- 문제는 다음 CPU burst 길이를 OS가 정확하게 알 수 없음
→ 정확한 값은 알 수 없지만 실제 값에 가깝게 예측하는 것이 가장 중요한 포인트
Example

- Waiting time
- P1 = 3
- P2 = 16
- P3 = 9
- P4 = 0
- average = 7
- 다른 스케줄링 알고리즘을 사용해도 평균 대기 시간이 7보다 짧을 수는 없음
- Next CPU burst를 예측하는 방법
- 이전 CPU burst 길이를 바탕으로 예측
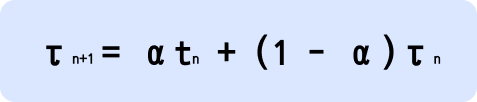
- t : 직전 n번째 CPU burst의 실제 값
- τ : 다음번 CPU burst 예측 값
- α : 0과 1사이 값으로 보통 0.5를 사용
- 다음번 CPU burst 예측 값은 이전 CPU burst 예측 값과 이전 CPU burst 실제 값에 영향을 받음
- 이전 CPU burst 길이를 바탕으로 예측
Shortest-remaining-time-first
- SJF의 선점형 버전
- 기본적으로는 짧은 CPU burst 순으로 스케줄링
- 현재 실행 중인 프로세스의 남은 CPU burst보다 짧은 CPU burst를 갖는 프로세스가 ready queue에 들어오면 실행 중인 프로세스를 교체함
- 프로세스가 ready queue에 도착하는 시간도 중요
Example

- Waiting time
- P1 = (0-0) + (10-1) = 9
- P2 = (1-1) = 0
- P3 = (17-2) = 15
- P4 = (5-3) = 2
- average = 6
Priority Scheduling
- 각 프로세스마다 우선순위를 나타내는 정수를 부여하고, 이는 보통 PCB에 저장
- 일반적으로 숫자가 작을수록 우선순위가 높음
- 우선순위가 가장 높은 프로세스가 다음번 CPU를 사용하게 됨
- 비선점형
- 우선순위에 따라 스케줄링이 되면 자발적으로 CPU를 반납할 때까지 실행을 이어나감
- 선점형
- 현재 실행 중인 프로세스보다 높은 우선순위의 프로세스가 ready queue에 들어오면 실행 프로세스가 변경됨
- Problem : Starvation
- 순수한 우선순위 스케줄링은 starvation 문제가 발생할 수 있음
- 매번 높은 우선순위 프로세스들이 ready queue에 진입해서 낮은 우선순위의 프로세스가 오랜 시간 동안 서비스를 받지 못함
- Solution : Aging
- ready queue에 머무르는 시간에 비례해서 프로세스의 우선순위를 높여주는 방식
Example

- Waiting time
- P1 = 6
- P2 = 0
- P3 = 16
- P4 = 18
- P5 = 1
- average = 8.2
Round Robin (RR)
- 프로세스가 ready queue에 도착한 순서대로 실행시킴
- 실행 시작 이후 미리 정한 time quantum q만큼 실행한 이후 CPU를 빼앗음
- time quantum : 한 번 실행을 이어나갈 수 있는 최대 시간
- ready queue에 n개의 프로세스가 있을 때 최대 대기 시간은 (n-1) * q로, 대기 시간에 상한선이 있음
- timer interrupt를 사용해 구현 가능
- time quantum과 성능
- 너무 크면 FCFS와 마찬가지가 됨
- 너무 작으면 context switch overhead가 너무 커짐
Example
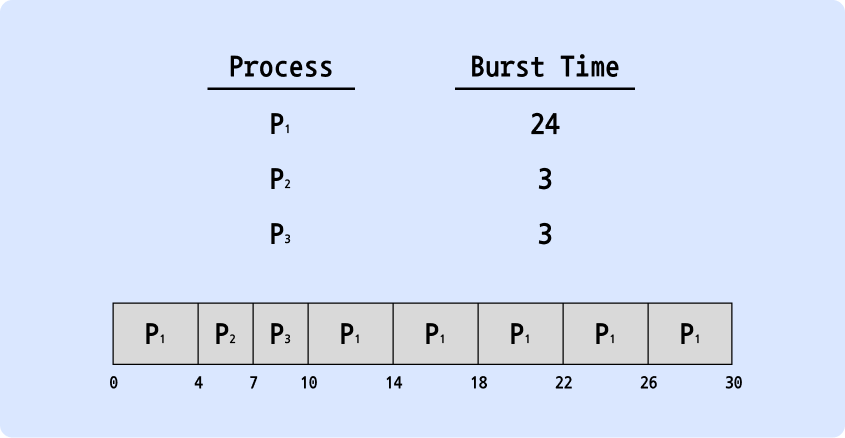
- time quantum = 4
- P1은 time quantum만큼 실행 후 선점됨 (CPU를 뺏김)
- 보통 SJF에 비해 turnaround time은 길지만 response time은 짧음
- 평균 turnaround time은 time quantum의 크기가 증가하더라도 반드시 개선되는 것은 아니지만, time quantum이 짧을수록 평균 turnaround time은 증가함
Multilevel Queue
- 시스템 안에 프로세스들이 성격상 서로 다른 몇 개의 그룹으로 분류할 수 있는 경우
- ready queue 자체도 몇 개의 queue로 나눠서 운영할 수 있음
- 예를 들어 interactive한 foreground 프로세스들과 batch 작업을 하는 background 프로세스들로 구분하여 별도의 queue에 머물게 할 수 있음
- <각 queue마다 별도의 스케줄링 알고리즘이 있어서 같은 queue에 머무르는 프로세스들 간에는 지정된 스케줄링 알고리즘이 적용되도록 함
- queue 사이에는 고정 우선순위의 선점형 스케줄링이 주로 사용됨
- 예를 들어 foreground queue의 프로세스가 우선적으로 스케줄링되고, background queue의 프로세스는 foreground 프로세스가 없는 경우에만 서비스
→ starvation 가능성 있음 - 전체 CPU 시간을 queue 간의 적절한 비율로 배분되도록 하는 것이 중요
- 예를 들어 foreground queue의 프로세스가 우선적으로 스케줄링되고, background queue의 프로세스는 foreground 프로세스가 없는 경우에만 서비스
Multilevel Feedback Queue
- 전반적인 운영은 Multilevel queue와 동일하되, 프로세스가 queue 간의 이동을 하는 것이 허용됨
- 입출력 중심 프로세스나 대화형 프로세스들은 주로 높은 우선순위 큐에 머물게 되고, CPU 중심 프로세스(CPU를 많이 사용하는 프로세스)들은 낮은 우선순위 큐에 주로 머물게 됨
- 낮은 우선순위 큐에서 너무 오래 대기하는 프로세스는 높은 우선순위 큐로 이동할 수 있도록 해서 aging 효과를 냄
- parameter
- 전체 큐의 개수
- 각 큐의 스케줄링 알고리즘
- 언제 높은 우선순위 큐로 올릴 것인지
- 언제 낮은 우선순위 큐로 내릴 것인지
- 프로세스가 ready queue에 진입할 때 최초로 어느 queue에 들어갈 것인지
Example
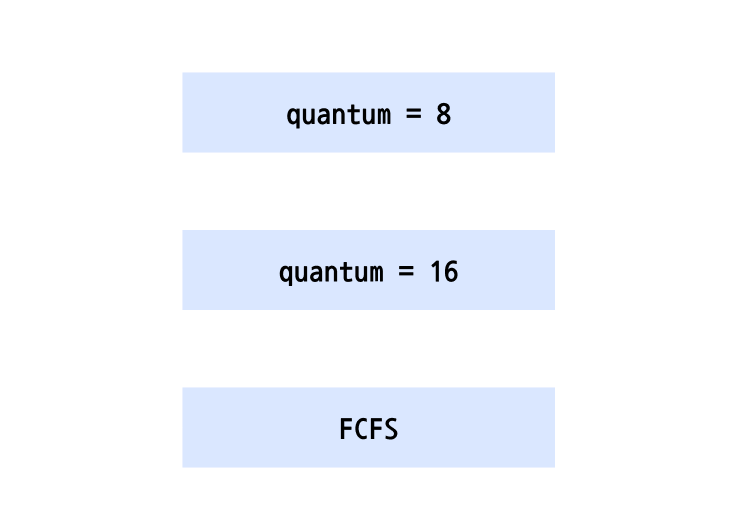
- Q0 : 가장 높은 우선순위로, time quantum = 8인 RR 스케줄링
- Q1 : 두 번째 우선순위로, time quantum = 16인 RR 스케줄링
- Q2 : 가장 낮은 우선순위로, FCFS 방식으로 동작
- Scheduling
- 새 프로세스가 Q0에서 시작해서 도착한 순서대로 8millisecond의 CPU 시간을 부여받음
- 만일 프로세스가 8millisecond를 모두 사용하지 않고 입출력을 한다면 이 프로세스는 다음에 ready queue에 진입할 때도 Q0에서 시작
- 8millisecond를 모두 사용했다면 다음에 한 단계 낮은 우선순위 큐인 Q1으로 이동
- Q1의 프로세스는 Q0의 프로세스가 하나도 없는 경우에만 CPU를 받을 수 있음
- Q1에서도 16millisecond를 다 사용하는 프로세스가 있다면 Q2로 이동
Priority Inversion
- 우선순위 역전 현상
- 우선순위 스케줄링 하에서 프로세스 간의 semaphore나 lock과 같은 자원을 사용하면서 벌어지는 문제
Example
- 선점형 우선순위 스케줄링을 하는 시스템에 우선순위가 높은 순서대로 H, M, L의 세 프로세스가 있음
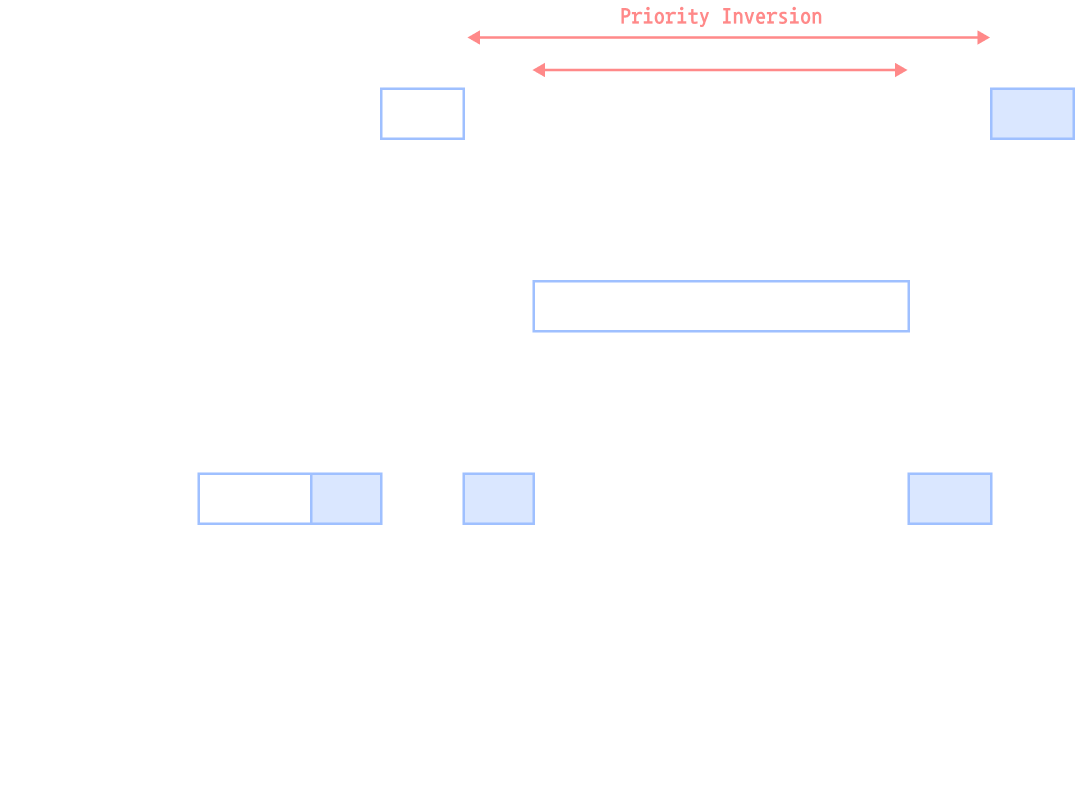
- semaphore를 소유한 L이 우선순위가 낮은 관계로 M에게 실행에서 밀림
→ 최종적으로 높은 우선순위인 H의 실행이 지연되는 것이 문제 - 높은 우선순위의 프로세스가 H가 낮은 우선순위의 프로세스 L이 먼저 가지고 있던 semaphore를 나중에 요청함으로써 우선순위가 높음에도 실행하지 못하고 L이 먼저 실행되는 현상 발생
Priority Inheritance (Donation) Protocol
- 우선순위 상속 기법
- 우선순위 역전 현상 해결법
- 낮은 우선순위의 프로세스가 이미 소유한 semaphore 같은 자원을 높은 우선순위의 프로세스가 요구하는 경우 semaphore를 소유한 프로세스의 우선순위를 임시로 높여주는 방식
- 자원을 해제하면 우선순위를 환원
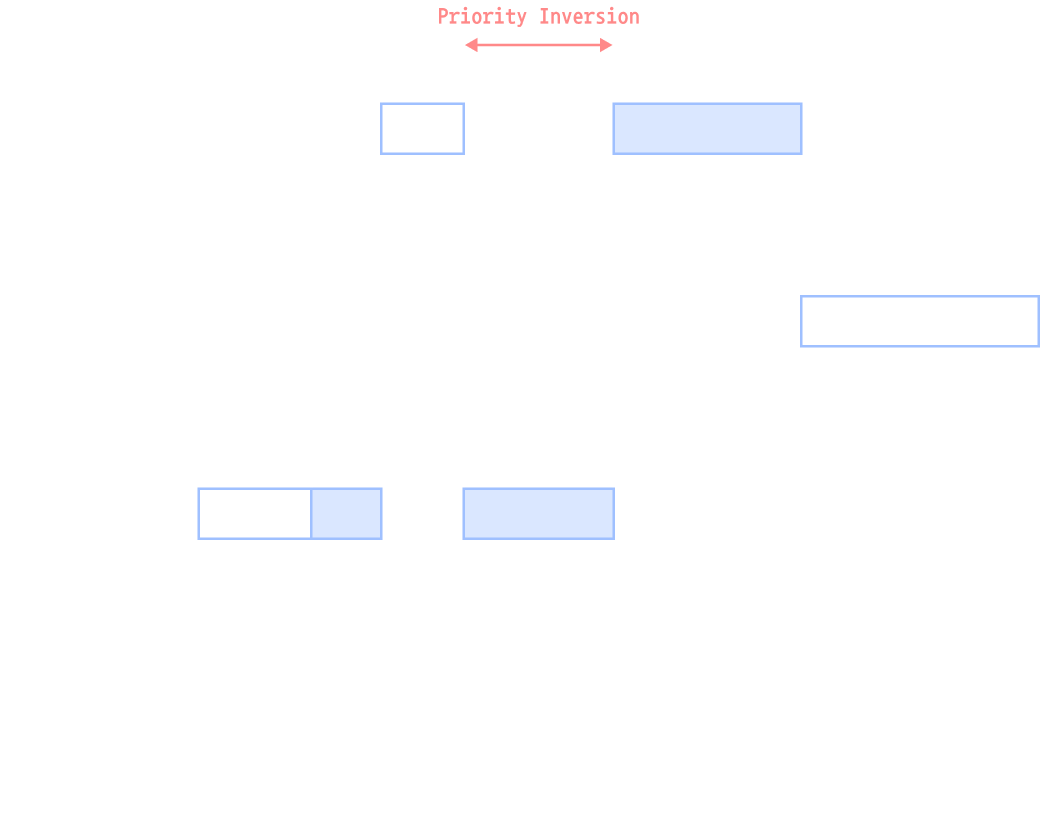
- 프로세스 H가 semaphore S에 대해 wait 연산을 시도하면 프로세스 L의 우선순위를 임시로 H의 우선순위만큼 높여줌
→ L이 최대한 빨리 S를 release하게 함
→ 우선순위 역전 구간이 줄어듦
참고 자료 : Operating System Concepts Essentials
*이미지 자료는 교재 자료를 직접 다시 만든 것으로 무단 불펌 금지입니다
끗~~
