논문 링크: https://arxiv.org/abs/1602.04938
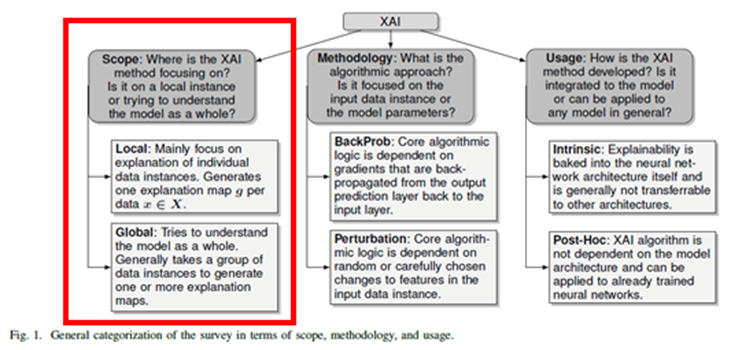
- LIME은 Local | Pertubation | Post-Hoc(agnostic)의 종류에 속한다.
- Post-Hoc은 Surrogate Model을 사용하는데 이는 Black box model을 f라고 할 때, 이를 흉내내는 모델 g를 만드는게 대리 분석의 목표이다.
- 이 때, 모델 g는 모델 f와 학습 방식이 같을 수도 있고, 다를 수도 있다. 모델 g를 결정하는 핵심 조건은 아래와 같다
- 모델 f보다 학습하기 쉽다.
- 설명 가능하다.
- 모델 f를 유사하게 흉내 낼 수 있으면 된다.
- 또한, 모델 g의 학습 과정은 다음 두 가지로 나뉜다.
- 학습 데이터 전부를 사용한다. (Global Surrogate Analysis)
- 데이터의 라벨 별로, 또는 데이터의 일부만 사용한다.(Local Surrogate Analysis)
→ 학습하는 과정이 끝나면 모델 g는 f를 조금이나마 흉내낼 수 있을 것이고 g는 설명가능하기 때문에 f가 어떻게 학습되었을지 간단하게나마 설명이 가능하다.
대리 분석법의 장점은 아래와 같다.
1. 모델 애그노스틱(model-agnostic technology, 모델에 대한 지식 없이도 학습할 수 있음)하다.
2. 적은 학습 데이터로도 설명 가능한 모델을 만들 수 있다.
3. 중간에 모델 f가 바뀌더라도 피처만 같다면 대리 분석을 수행할 수 있다.

Introduction
- 머신 러닝 기법들은 많은 성과를 거두고 있지만, 아무리 성능이 좋은 모델이라도 사용자가 납득할 수 있는 설명을 제시하지 못한다면 모델을 차용하기 어려울 것입니다.
- 특히 사람의 건강과 생명이 걸린 의료현장에서는, 의사가 납득할 수 있도록 설명가능하고 신뢰할 수 있는 모델만이 사용될 수 있습니다.
- 저자는 신뢰에 대해 두 가지 정의를 내린다.
- 개별 예측값에 대한 신뢰(Trusting a prediction)
- 모델에 대한 신뢰(Trusting a model)
- 본 논문에서는 이렇게 정의한 두 가지 신뢰 문제를 해결하기 위해 설명(Explanation)을 제시하는 알고리즘을 제안합니다.
- 개별 예측값에 대한 설명을 제시하는 LIME(Local Interpretable Model-agnostic Explanations)
- 모델에 대한 설명을 돕기 위해 대표적인 Instance 집합을 구성하는 SP-LIME(Submodular Pick - LIME)입니다.

→ 이를 간단히 표현하자면, 어떤 두 모델 중 하나를 선택하고자 할 때, 전체적으로 더 합리적인 설명들을 제시하는 모델을 선택한다는 것
저자는 LIME을 비롯한 설명 모델 들이 갖추어야 할 세가지 요건들을 제시함
1. Interpretability
- 인간이 이해할 수 있는 방식으로 설명이 제시되어야 함.
- Random Forest처럼 수백, 수천 개의 트리 구성하거나 몇천 개 변수를 활용하는 회기 분석은 설명이 어려움
- e.g. Deicision Tree같은 경우 인간이 이해하기 쉽다
- Local Fidelity
- 최소한 국소적(Locally)으로는 합리적이어야 된다.
- 즉 Global Fidelity하지 않아도 내가 선택한 객체에 대해서는 합리적이어야 된다는 말.
- 다시 해석하면 전체적으로 중요한 Feature일지라도 개별 예측에서는 중요하지 않을 수 도 있다.
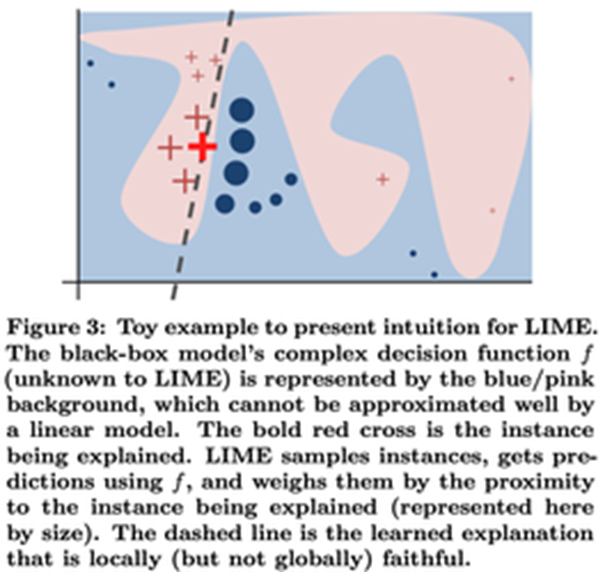
- 다시 해석하면 전체적으로 중요한 Feature일지라도 개별 예측에서는 중요하지 않을 수 도 있다.
- Model-agnostic
- Explainer(설명 모델)은 해석의 대상이 되는 모델의 종류와 관계없이 설명을 제시할 수 있어야 한다.
- Decision Tree, Logistic Regression 등등..
LIME의 목표는 분류기(Classifier)에서 Locally Faithful한 설명을 제시하는 것
3.1 Interpretable Data Representation

모델은 복잡할 수록 성능이 좋은편이지만 이 부분에서 성능과 복잡도 사이에 Trade-Off가 존재한다.
LIME은 이 Trade-Off관계를 활용하여 최적의 Explainer를 찾는다.

설명하고자 하는 모델 f의 input x에 대하여 가장 좋은 설명을 나타내는 L(~ ) 와 g의 복잡도의 합을 가장 적게 하는 g를 찾는 방식
여기에서도 마찬가지로 (L과 오메가는 서로 trade-off관계)



예시로 실제 동작 방식 이해
입력 데이터가 Text일 때 (NLP)

입력 데이터가 이미지 일 때 (image)

LIME은 어떤 원리로 이미지 분류 및 텍스트 분류에 대한 근거를 설명하는 것일까?
→ LIME은 입력 데이터에 대해 부분적으로 변화를 주는데 이 것을 Permutation 혹은 sample permutation 이라고 함.
→ 즉 어떤 이미지가 모델의 입력값으로 들어온다면 해석 가능하게끔 ‘인식 단위'를 쪼개고 이미지를 해석함
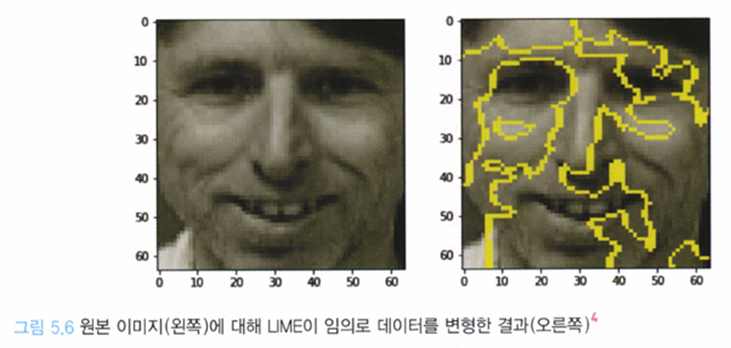
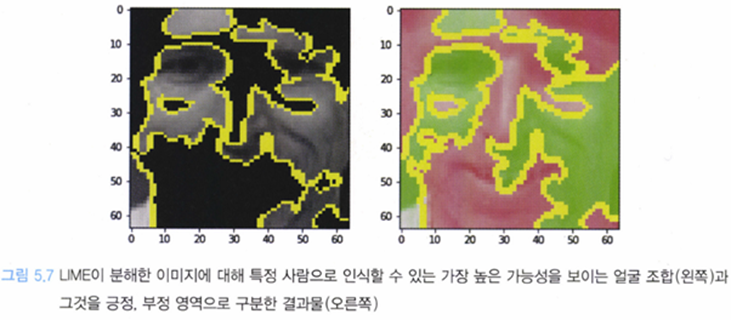
어떤 이미지가 입력 값으로 주어졌을 때 이미지 내 특정 관심 영역을 x라고 하고, 초점 중심으로 관심영역을 키워나갈 때 기준 x로부터 동일한 정보를 가지고 있다고 간주할 수 있을 때, 이를 파이x라고 하고 이를 슈퍼 픽셀이라고 한다.


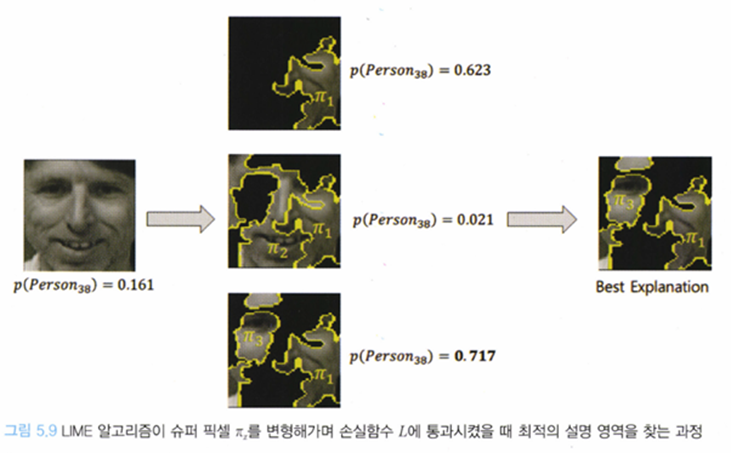
가장 확률이 높은 슈퍼픽셀의 조합을 찾아 output으로 내뱉는다.
→ 손실 함수가 최저가 되게 하는 슈퍼픽셀 조합을 찾는다.

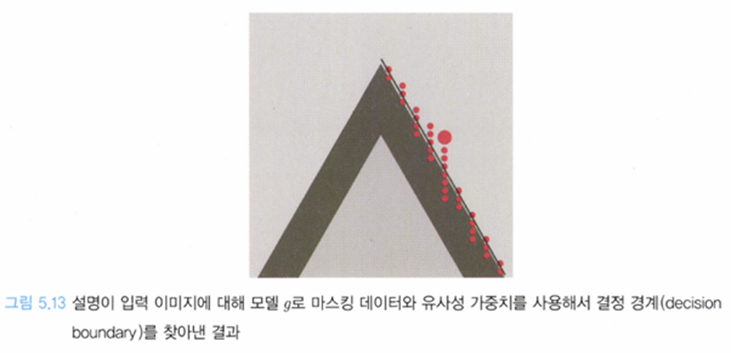
흰색 = 긍정 || 흑색 = 부정 || 빨간색 point는 input image
이때 g 모델은 f의 결정경계를 흉내낼 수 있어야 된다.
→ global하게는 아니더라도 빨간색 point에 대하여 local fidelity 해야된다는 소리

LIME은 이 주변 샘플들을 이용해 입력 이미지 x 근처(f의 분류 결과를 살핌으로써)를 조사해 결정경계를 구하는 것이다
→ 논문에서는 샘플링 후 K-Lasso를 통해 근사적으로 결정 경계를 구한다고 나와있음.

그림 5.12처럼 주변 이미지를 샘플링 하게 되면 긍정과 부정으로 분류되는 얘들이 나오게 된다.
• 긍정 : 해당 샘플 이미지는 예측에 도움이 되는 부분(슈퍼픽셀 파이x)를 갖고 있다.
• 부정 : 해당 샘플 이미지는 예측에 도움이 되지 않는 부분(슈퍼픽셀 파이x)을 가지고 있다.
이렇게 긍정과 부정을 나누게 된다면 locally fidelity한 결정 경계를 찾을 수 있게 된다.
LIME의 장점:
1. LIME은 분류에 사용한 블랙박스 모델 f가 무엇이든 적용할 수 있다(model-agnostic)
2. LIME은 딥 러닝이나 GPU 등을 사용하지 않고도 적용할 수 있는, 가벼운 XAI 기법이다.
3. LIME은 행렬로 표현 가능한 데이터(텍스트, 이미지)에 작동하는 XAI 기법이다. 서브모듈러를 찾고, 이를 이용해 설명하기 때문에 결과를 직관적으로 만들 수 있다.
단점 :
1. 슈퍼 픽셀을 구하는 알고리즘과 모델 g의 결정 경계를 확정 짓는 방식이 비결정적(non-deterministic)이다.
- LIME은 슈퍼 픽셀 알고리즘에 따라 마스킹 데이터가 달라지며, 모델 g는 샘플링 위치에 따라 랜덤한 결과를 보일 수 있다.
- 이러한 비결정 문제는 ‘샘플링’을 사용하는 대부분의 문제에서 발생할 수 있다.
- LIME은 데이터 하나에 대한 설명이기 때문에 모델 전체에 대한 일관성을 보전하지 못한다.
- 서브모듈러 픽(Submodular pick) 알고리즘을 사용한 SP-LIME으로 데이터세트 전체를 활용해 서브모듈러를 선정할 수 있게끔 보완하였다.
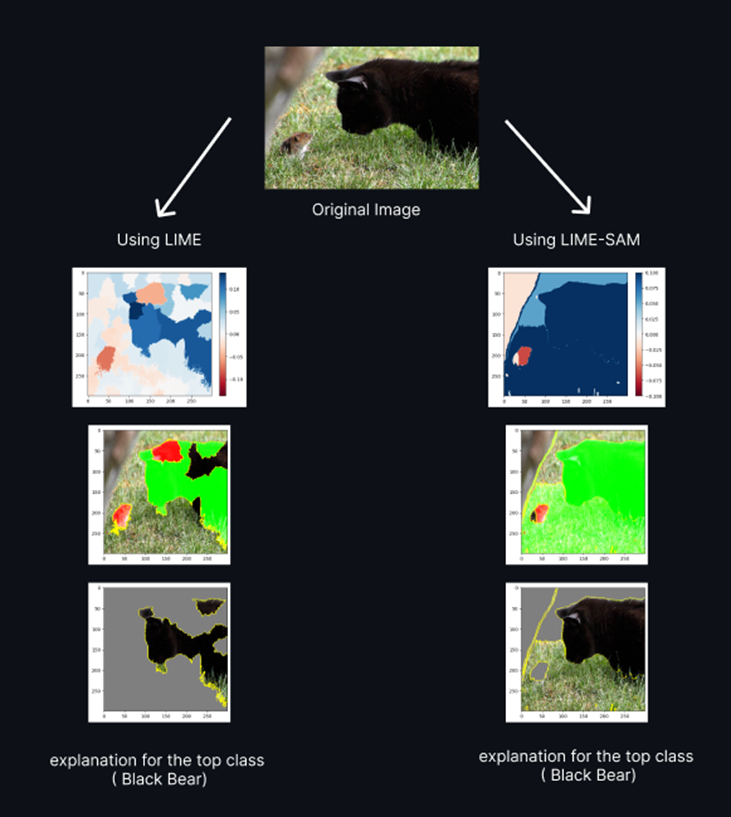
- LIME-SAM
• 중요한 건 아니고, 기존 super pixel을 이용하는 LIME의 특성상 정확한 Segmentation이 되지 않는 경우도 존재하였다.
• 이번에 SAM의 발견으로 인하여 좀 더 정교한 LIME을 사용할 수 있게 되었다.