
🌈 이진 탐색 트리(BST: Binary Search Tree)
-
이진 탐색(binary search)과 연결리스트(linked list)를 결합한 자료구조이다.
-
이진 탐색의 효율적인 탐색 능력의 장점을 유지하면서 빈번한 자료 입력과 삭제가 가능하다.
✔ 이진 탐색
- 탐색 시간복잡도는 O(log n),
- 자료 입력, 삭제 불가능
✔ 연결리스트
- 탐색 시간복잡도는 O(n)
- 자료 입력, 삭제의 시간복잡도 O(1)
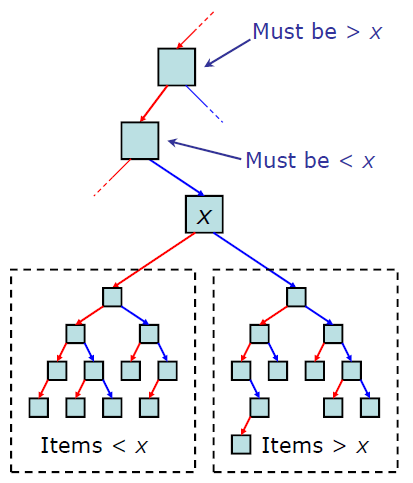
이진 탐색 트리의 4가지 조건
- 모든 노드는 유일한 키를 갖는다.
- 왼쪽 서브트리의 키들은 루트의 키보다 작다.
- 오른쪽 서브트리의 키들은 루트의 키보다 크다.
- 왼쪽과 오른쪽 서브트리도 이진탐색 트리이다.
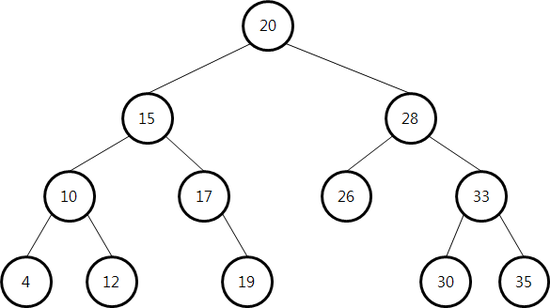
- 이진탐색트리를 순회할 때는 중위순회(inorder) 방식을 쓴다.(왼쪽 서브트리-노드-오른쪽 서브트리 순으로 순회)
- 위의 그림을 중위 순회하면, 4, 10, 12, 15, 17, 19, 20, 26, 28, 30, 33, 35 가 된다.
이진 탐색 트리의 구현
노드 생성
class Node:
def __init__(self, key, value, left, right):
self.key = key
self.value = value
self.left = left
self.right = right- 노드를 나타내는 Node 클래스를 생성한다.
- value만 있어도 구현에는 지장이 없으나, key-value pair 형태를 생성함으로써 데이터의 연산이 편리해질 수 있다.
- 이진 탐색 트리의 핵심 연산은 검색, 삽입, 삭제 이다.
트리 클래스의 생성자
class BST():
def __init__(self):
self.root = None- 트리의 root를 생성하고, 초기의 빈 값을 설정한다.
Search
- 루트를 기준으로 탐색을 시작하며 찾고자 하는 키의 값과 루트 값이 대소관계를 파악하여 자식 노드를 따라간다.
def search(self, key):
node = self.root # root를 기준으로 탐색
while True:
if node is None:
return -1
if key == node.key:
return node.value
elif key < node.key:
node = node.left
else:
node = node.right- 이진탐색트리의 탐색 연산에 소요되는 계산복잡성은 트리의 높이(루트노드-잎새노드에 이르는 엣지 수의 최대값)가 ℎ일 때 𝑂(ℎ)가 된다.
- 최악의 경우 잎새노드까지 탐색해야 하기 때문이다. 이 때 ℎ번 비교 연산을 수행한다.
Insert
- 삽입 시 가장 중요한 점은 이진 검색 트리의 조건을 유지해야한다는 것!
- 알고리즘은 다음과 같다.
- root 존재 여부 파악
- root가 없으면 생성.
- root가 있으면 root부터 탐색 시작.
- (root가 있다는 전제) 루트 - 현재 노드를 node라고 한다.
- 삽입하는 key와 현재 노드 node의 키를 비교한다.
- key == node : 추가하려는 키가 이미 있으니 삽입을 실패하고 종료
- key < node :
- 왼쪽 자식 노드가 없으면, 그 자리에 노드를 만들어서 삽입하고 종료.
- 왼쪽 자식 노드가 있으면, 현재 노드를 왼쪽 자식 노드로 옮겨서 다시 탐색한다.(재귀)
- key > node:
- 오른쪽 자식 노드가 없으면, 그 자리에 노드를 만들어서 삽입하고 종료한다.
- 오른쪽 자식 노드가 있으면, 현재 노드를 오른쪽 자식 노드로 옮겨서 다시 탐색한다.(재귀)
- 3번 과정을 반복한다.
def add(self,key,value)->bool:
# 노드 추가하는 내부 함수
def add_node(node, key,value)->None:
# 탐색하고 적절한 자리에 삽입
if key == node.key: #이미 삽입하려는 키가 있으면 false 처리
return False
# 삽입하려는 키가 현재 탐색 노드의 키보다 작다면
elif key < node.key:
# 그 탐색 노드의 왼쪽 자식이 없다면 바로 그 자리에 삽입
if node.left is None:
node.left = Node(key,value,None,None)
else:
# 자식이 있으면 재귀함수 호출로 한번 더 들어감
add_node(node.left,key,value)
# 삽입하려는 키가 현재 탐색 노드의 키보다 크거나 같다면
else:
# 그 탐색 노드의 오른쪽 자식이 없다면 바로 그 자리에 삽입
if node.right is None:
node.right = Node(key,value,None,None)
else:
# 자식이 있으면 재귀함수 호출로 한번 더 들어감
add_node(node.right,key,value)
return True
# 루트가 있는 경우
if self.root is None:
self.root = Node(key,value,None,None)
return True
# 루트가 없는 경우
else: #리턴값은 내부함수 리턴 값
return add_node(self.root,key,value)
Delete
- 이진 탐색 트리 관련 알고리즘 중 가장 복잡하다.
- 삽입과 마찬가지로 탐색을 먼저 해야한다. 트리 안에서 삭제하고자하는 키 값의 위치를 알아야 삭제할 수 있기 때문이다.
- 탐색 후, 삭제시 발생할 수 있는 아래의 상황 3가지 경우를 고려해야 한다.
1) 삭제하려는 노드가 단말노드일 경우 (자식 노드가 없을 경우)
2) 삭제하려는 노드가 하나의 서브트리만 가지는 경우 (왼쪽 혹은 오른쪽 둘 중 하나만)
3) 삭제하려는 노드가 두 개의 서브트리를 모두 가지고 있는 경우
def remove(self, key)-> bool:
node = self.root # 스캔 중인 노드
parent = None # 스캔 중인 노드의 부모 노드
is_left_child = True # node는 parent의 왼쪽 자식 노드인지 오른쪽 자식 노드인지 확인
while True:
if node is None:
return False
if key == node.key:
break
else:
parent = node
if key < node.key:
node = node.left
is_left_child = True # 왼쪽 자식 노드로 내려가니까 플래그를 True로 설정
else:
node = node.right
is_left_child = False # 오른쪽 자식 노드로 내려가니까 플래그를 True로 설정
# 키를 찾은 뒤에 자식이 없는 노드이면 or 자식이 1개 있는 노드이면
if node.left is None: # 왼쪽 자식이 없으면
if node is self.root: #만약 삭제 노드가 root이면, 바로 오른쪽 자식으로 대체한다.
self.root = node.right
# 아래의 parent는 탐색 시 찾은 노드의 바로 위 부모가 됨.(탐색 로직에서 그렇게 적용)
# parent - node - node의 자식의 구도가 있으면 node라는 중간이 빠지기 때문에 parent의 자식과 node의 자식을 연결
# (node의 자식이 없으면 자연스레 None이 들어감)
elif is_left_child: #왼쪽 자식 노드가 있는 것이니까
parent.left = node.right # 부모의 왼쪽 참조가 오른쪽 자식을 가리킴
else: #오른쪽 자식 노드가 있는 것이니까
parent.right = node.right # 부모의 오른쪽 참조가 오른쪽 자식을 가리킴
elif node.right is None: # 오른쪽 자식이 없으면
if node is self.root:
self.root = node.left #만약 삭제 노드가 root이면, 바로 왼쪽 자식으로 대체한다.
elif is_left_child:
parent.left = node.left # 부모의 왼쪽 참조가 왼쪽 자식을 가리킴
else:
parent.right = node.left # 부모의 오른쪽 참조가 왼쪽 자식을 가리킴
else:
parent = node
left = node.left
is_left_child = True
while left.right is not None:
parent = left
left = left.right
is_left_child = False
node.key = left.key
node.value = left.value
if is_left_child:
parent.left = left.left
else:
parent.right = left.left
return True 모든 노드를 오름차순으로 출력
- 키의 오름차순으로 출력
- 중위 순회의 깊이 우선 검색으로 적용
def dump(self):
def print_subtree(node):
if node is not None:
print(f'{node.key} {node.value}')
print_subtree(node.left)
print_subtree(node.right)
print_subtree(self.root)🙆♂️ 정리
- 이진 탐색 트리의 개념과 연산의 원리를 이해하는 것은 어렵지 않지만 이를 구현하는 것이 아직은 어렵고, 알고리즘 문제나 실전에서 어떻게 적용시켜야할 지 아직 감이 오지 않는다.
- 반복 연습을 하고 다양한 문제를 접해보는 것이 최선일 것 같다! 특히 insert와 delete는 계속 복습하자.
📝 Reference

Backend Developer - "Growth itself contains the germ of happiness"