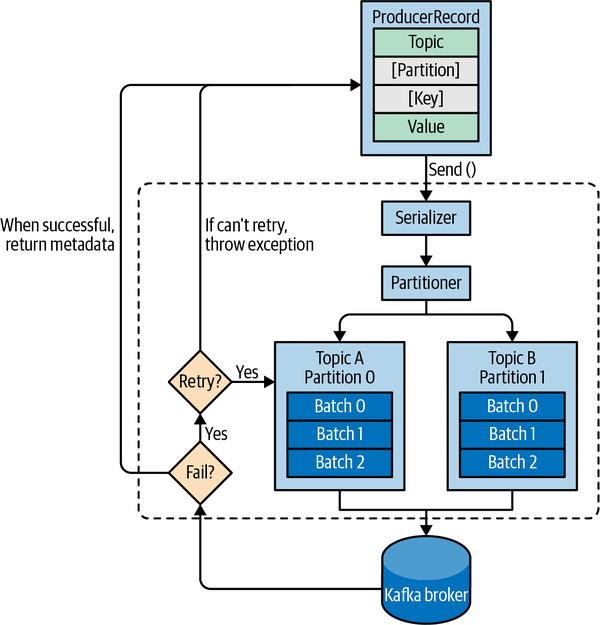
Producer API는 매우 간단하지만 실제 아키텍쳐는 복잡하다. 위 사진처럼 데이터를 전송한다.
ProducerRecord
필수 항목
- topic
- value
선택 항목
- key
- partition
- timestamp
- header 모음
ProducerRecord 동작 순서
- 네트워크를 통해 전송할 수 있도록 "key-value object를 byte array로 serialize".
- 파티션으로 데이터 전송.
2.1. 명시적으로 파티션을 지정하지 않은 경우, 데이터는 partitioner에게 전송됨. Partitioner는 일반적으로 ProducerRecord key를 기반으로 파티션 선택.
2.2. 파티션이 선택된 경우, record가 어떤 topic의 어떤 partition으로 이동할지 producer가 알 수 있음.
이때, 별도의 쓰레드가 배치를 브로커로 전송하는 작업 담당. - 브로커가 메세지를 받았으면 response를 줌.
3.1. 메세지가 Kafka에 성공적으로 쓰였으면, topic, partition, partition 내 record의 offset이 포함된 RecordMetadata 객체를 반환함.
3.2. Producer가 오류를 수신하면 포기하고 오류를 반환하기 전 메시지 전송을 몇 번 더 시도할 수 있음.
Producer 생성시 필수 요소들
bootstrap.servers
host:port쌍으로 Producer가 Kafka cluster에 초기 연결을 설정하는데 사용할 list.- 모든 브로커를 포함할 필요는 없지만, 한 브로커가 다운되더라도 Producer가 클러스터에 계속 연결할 수 있게 최소 두 개 이상의 브로커를 포함하는 게 좋음.
key.serializer
- record의 키를 serialize하는데 사용할 클래스의 이름.
value.serializer
- Kafka에 생성할 record의 value를 serialize하는데 사용할 클래스의 이름.
메세지를 보내는 세가지 방법
- Fire-and-forget
- 서버에 메시지를 보내고 성공적으로 도착했는지 신경 쓰지 않음.
- Kafka 자체가 HA고, 자동 재시도를 해서 대부분은 성공적으로 도착함.
- 하지만 재시도할 수 없는 오류나 timeout은 message가 손실되며 application은 이에 대한 정보나 예외를 받지 못함
- Synchronous send
- 기술적으로 Kafka producer는 항상 비동기임.
- message를 보내고 send() 메소드가 Future 객체를 반환함.
- 하지만 Future에서 get()을 사용해서 send()의 성공 유무를 기다림.
- Asynchronous send
- send() 메소드를 callback함수와 함께 호출. 이 콜백 함수는 Kafka 브로커로부터 응답을 받을 때 트리거됨.
Kafka에 메시지 보내기
예시)
ProducerRecord<String, String> record =
new ProducerRecord<>("CustomerCountry", "Precision Products",
"France"); (1)
try {
producer.send(record); (2)
} catch (Exception e) {
e.printStackTrace(); (3)
}
유연한 사고의 데이터 엔지니어입니다