kafka를 kubernetes에 올리는 법을 리서치하던 도중 여러 가지 고민이 있었다... 필자가 마지막으로 kafka를 사용했던 시기는 22년으로 그때는 zookeeper를 사용해서 간략하게 kafka를 on-premise로 monolithic으로 구축했었다. 그것도 학부에서...
1. KRaft mode가 지금은 어느 정도 안정됐는지를 몰라!! KRaft mode 자체를 처음 듣는다!! 그리고 나중에 Hadoop을 도입하게 되면 zookeeper를 공통으로 써야하지 않을까?
2. kubernetes에 kafka를 올리려면 strimzi를 많이 쓴다고들 하는데, 나는 production 환경을 고려해서 개발해야한다.
여러 곳에 문의를 했었고, 특히 strimzi github의 discussion에 쳐들어가서 질문했다!
결론은 다음과 같다. 어차피 KRaft가 이제 많이 쓰일꺼고, 이왕 시작한거 최신으로 짱짱하게 구축해보자. 그리고 이전에 prometheus나 loki를 구축해볼 때, helm으로 설치했었는데 처음에 설치할 땐 세상 편한데... 유지보수나 고도화하려니까 무슨 기능이 너무 많아서 어디를 손대야할지를 모르겠었다.. 그래서 helm없이 strimzi를 github에서 받아와서 사용할 예정이다.
정리하자면 다음과 같다.
- Strimzi 설치(helm 사용하지 않음)
- KRaft mode
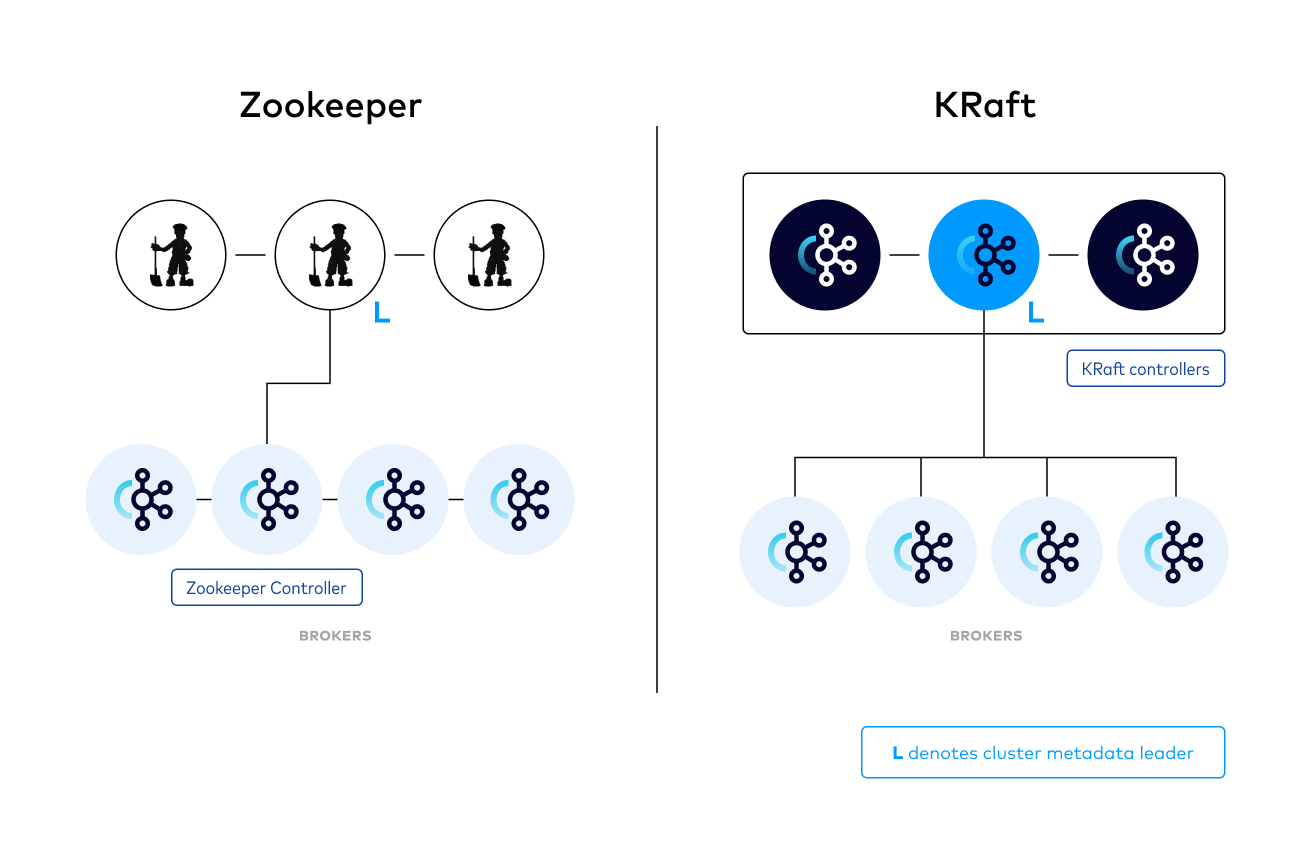
- 최신 Strimzi 설치
kubectl create namespace kafka
kubectl apply -f 'https://strimzi.io/install/latest?namespace=kafka' -n kafka- KRaft 모드용 Kafka 클러스터를 설정해줘야한다.
이때 Zookeeper 구성이 필요없다.
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-kraft-cluster
namespace: kafka
spec:
kafka:
version: 3.1.0
replicas: 3
listeners:
- name: internal
port: 9092
type: internal
tls: false
- name: external
port: 9094
type: loadbalancer
tls: false
configuration:
bootstrap:
host: external-bootstrap.my-kraft-cluster-kafka.svc
port: 9094
config:
process.roles: "controller,broker"
controller.quorum.voters: "0@my-kraft-cluster-kafka-0:9093,1@my-kraft-cluster-kafka-1:9093,2@my-kraft-cluster-kafka-2:9093"
node.id: ${STRIMZI_BROKER_ID}
storage:
type: persistent-claim
size: 100Gi
class: nfs-storage
deleteClaim: false
kafkaExporter: {}
entityOperator:
topicOperator: {}
userOperator: {}- 'process.roles'와 'controller.quorum.voters' 설정을 통해 KRaft metadata 모드를 활성화해준다.
- NFS StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage
provisioner: kubernetes.io/nfs
parameters:
server: {nfs_ip}
path: "/data/kafka"
readOnly: "false"
mountOptions:
- hard
- nfsvers=4.1- 배포
kubectl apply -f nfs-storageclass.yaml
kubectl apply -f kafka-kraft.yaml -n kafka
유연한 사고의 데이터 엔지니어입니다