
저번시간에는 write에 대해서 서술하였는데 이번에는 streamlit의 꽃이라고 불릴 수 있는 DataFrame에 대해서 서술해보였다.
Data Elements
정보와 상호작용이 가능한 데이터 중심의 인터페이스
st.dataframe
pandas DataFrame을 스크롤 가능한 테이블 형식으로 표시st.data_editor
사용자가 UI에서 직접 데이터를 편집할 수 있는 편집 가능한 데이터 테이블을 제공st.column_config
테이블에서 열의 표시 속성을 커스터마이즈하고 설정지원st.table
정적인 테이블을 렌더링하여 데이터를 표시st.metric
숫자형 지표(예: KPI)를 간단히 표시하고, 변화량(delta)을 표시st.json:
JSON 객체를 축소 및 확장이 가능한 포맷으로 표시
위와 같이 6개의 기능을 제공한다.
st.dataframe
import streamlit as st
st.dataframe(
data=None,
width=None,
height=None, *,
use_container_width=False,
hide_index=None,
column_order=None,
column_config=None,
key=None,
on_select="ignore",
selection_mode="multi-row"
)
1. data
data의 경우 말 그대로 내가 UI로 표시하고자 하는 Data를 의미한다.
처음 설명할 때, pandas의 DataFrame을 이라고 언급하였지만 다른 포멧(pandas.Series, pandas.Styler) 등
다양한 포멧도 변환 가능하니 유용하게 사용가능하다.(해당 부분은 공식문서 참조)
pandas.Styler를 이용해 특정 컬럼 색칠하기 같은 부가적인 기능도 가능하다.
2. width
UI의 넓이 조절
3. height
UI 높이 조절
4. use_container_width
use_container_width의 경우에는 이제 나중에 설명할 부분이지만 st.columns과 같이 칸을 쪼개는 경우가 있는데 해당 칸에 자동으로 맞출지 안맞출지를 선택한다(본인은 잘 사용하지 않는다)
5. hide_index
기본적으로 pandas의 dataframe처럼 맨 좌측에 index를 제공하는데 표시여부
6. column_order
특정 row의 순서를 지정할 수 있게 해주는 것
예를들어 원본 데이터 상 1, 2 이렇게 되어잇지만 순서를 바꾸어서 노출하고 싶을 때 사용하면 편리하다.
(사용해 본 적은 없다)
7. column_config
특정 컬럼의 type같은 것을 설정할 때 사용하는 것
import random
import pandas as pd
import streamlit as st
df = pd.DataFrame(
{
"name": ["Roadmap", "Extras", "Issues"],
"url": ["https://roadmap.streamlit.app", "https://extras.streamlit.app", "https://issues.streamlit.app"],
"stars": [random.randint(0, 1000) for _ in range(3)],
"views_history": [[random.randint(0, 5000) for _ in range(30)] for _ in range(3)],
}
)
st.dataframe(
df,
column_config={
"name": "App name",
"stars": st.column_config.NumberColumn(
"Github Stars",
help="Number of stars on GitHub",
format="%d ⭐",
),
"url": st.column_config.LinkColumn("App URL"),
"views_history": st.column_config.LineChartColumn(
"Views (past 30 days)", y_min=0, y_max=5000
),
},
hide_index=True,
)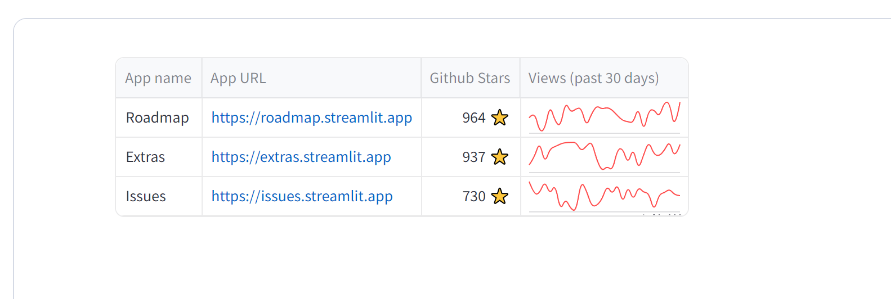
이런식으로 특정 컬럼에 config를 설정할 수 있다.
(공식 홈페이지 내용이다..)
위에서 보이는 코드와 같이 매우 매우 귀찮고 한다고 해도 특별히 예쁘지 않기에 필자는 잘 하지 않는다..
8. key
매우 중요하다..! 소규모의 프로젝트나 dataframe을 하나만 사용할 때는 필요없는 기능이지만
규모가 크거나 다양한 dataframe을 보여줄때는 필요한 기능이다.
겹치는 dataframe의 경우 streamlit에서 구분을 위해 key를 지정하라는 오류 메세지가 나오는데 이 때, 이것을 설정해두면 된다.
9. on_select
ignore
rerun
두 가지 기능을 지원하는데 'ignore' 의 경우, 평소의 data형태를 보여준다.
하지만 rerun으로 바꾸는 경우 하단 처럼 맨 좌측에 선택할 수 있는 체크박스가 나오는데
해당 체크박스를 클릭하면 어떤 row와 colum을 선택햇는지 결과 값이 나온다.
{'selection': {'rows': [0], 'columns': []}}해당값을 바탕으로 특정 row를 선택햇을 때마다 어떤 반응이 나오게 할지 동적UI를 구성할 수 있다.
TIP
만약 첫번재 row를 선택하면 버튼에 나오는 동적 UI를 구성하는 코드는 다음과 같다.
import streamlit as st import pandas as pd data = { 'a': [1, 2, 3], 'b': [4, 5, 6], 'c': [7, 8, 9] } df = pd.DataFrame(data) result = st.dataframe(df, on_select='rerun') rows = result['selection']['rows'] for i in rows: st.button(label=f'button_{i}')
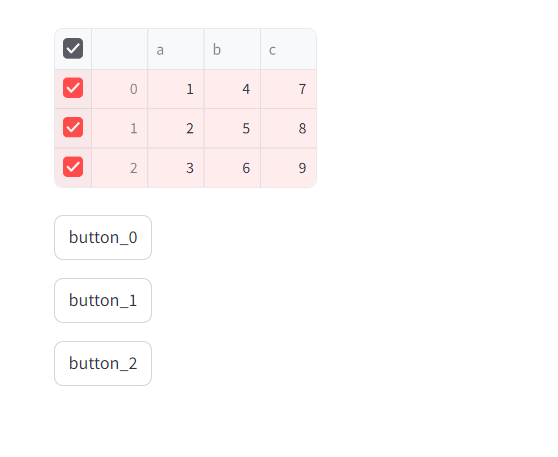
10. selection_mode
여러 행 선택, 단일 행 선택, 여러 열 선택, 단일 열 선택 등 사용자 선택을 제한 할 수 있게 하는 기능
기본적으로 on_select가 rerun일 경우에만 사용 가능하다.
st.data_editor
st.dataframe 경우, 사용자가 값을 수정하기는 불가능하지만 특정 row는 선택해서 특정 동작을 유도 할 수 있게하지만
data_editor의 경우, 사용자가 직접 data를 건드려 수정하게 할 수 있게 해주는 함수이다.
이 차이점을 제외하고는 나머지는 똑같기에 서술하지는 않겟다.
st.column_config
st.column_config의 경우, st.dataframe, st.data_editor에서 특정 컬럼의 config를 지정할 때 사용하는 함수이다.
st.table
정적인 값을 단순하게 표시하고 싶다 할 때 사용하는 함수
더 밋밋하고 엑셀같기에 필자는 선호하지 않는다.
st.metric
특정한 값을 사용자에게 임팩트있게 보여주고나 변화량이 중요한 값(ex. 온도)을 보여줄 때 유용하게 쓰일수 있는 값
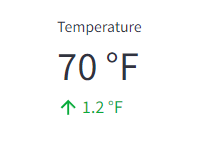
단점으로는 단일로는 잘 안쓰며 꼭 st.columns를 사용해서 보여줘야 있어보이기에 코드짤 때 조금 짜증나는 부분이다..
import streamlit as st
col1, col2, col3 = st.columns(3)
col1.metric("Temperature", "70 °F", "1.2 °F")
col2.metric("Wind", "9 mph", "-8%")
col3.metric("Humidity", "86%", "4%")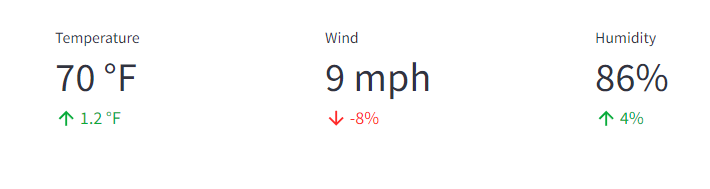
st.json
json data를 보여줄 때 효과적이다. 하지만 해당 기능 st.write에서도 충분히 구현되는 기능이기에 필자는 사용해본적이 없었다.
