0. Abstract
기존 Transformer 기반 자율주행 모델은 attention의 계산량이 sequence 길이에 대해 quadratic 이라서, LiDAR point cloud, multi-view image, temporal sequence처럼 token 수가 많은 입력을 처리할 때 부담이 큽니다.
UniLION은 이를 해결하기 위해 Linear Group RNN 기반 3D backbone을 사용합니다. 이 구조는 LiDAR-only, Temporal LiDAR, LiDAR-Camera, LiDAR-Camera-Temporal 구성을 하나의 architecture로 처리할 수 있고, 별도의 multi-modal fusion module이나 temporal fusion module이 필요 없다고 주장합니다.
또한 UniLION은 3D object detection, tracking, occupancy prediction, BEV map segmentation, motion prediction, planning까지 하나의 unified BEV representation 위에서 수행합니다. 즉, 논문의 목표는 “자율주행용 3D foundation model에 가까운 통합 backbone”을 만드는 것입니다.
1. Introduction
기존 문제점
논문은 기존 자율주행 모델의 문제를 크게 두 가지로 봅니다.
-
첫째, multi-modal fusion과 temporal fusion이 너무 복잡하다는 점입니다.
기존 방법들은 LiDAR와 Camera를 결합하기 위해 point-wise alignment, voxel-wise alignment, BEV fusion, cross-attention 같은 별도 모듈을 설계합니다. temporal 정보도 BEV feature alignment나 query fusion 같은 별도 temporal module을 쓰는 경우가 많습니다. 그래서 전체 시스템이 복잡해집니다. -
둘째, perception → prediction → planning으로 이어지는 기존 end-to-end autonomous driving 구조는 sequential dependency 가 강합니다.
예를 들어 detection이나 prediction 결과가 planning에 영향을 주기 때문에, 앞단 task의 오류가 뒤 task로 전파될 수 있습니다. UniAD, VAD, FusionAD 같은 모델은 강력하지만 이런 복잡한 task dependency와 optimization 문제가 있다고 설명합니다.
논문 질문
논문이 던지는 질문은 다음과 같습니다.
서로 다른 modality와 temporal 정보를 하나의 3D backbone에서 처리하면서도, 별도 fusion module 없이 여러 task를 수행할 수 있을까?
Transformer는 long sequence 처리에 강하지만 attention 비용이 크기 때문에, 저자들은 Linear RNN 을 대안으로 사용합니다. Linear RNN은 sequence 길이에 대해 계산량이 선형적이므로, LiDAR voxel, camera voxel, temporal voxel을 그냥 길게 이어 붙여도 처리 가능하다는 것이 핵심 아이디어입니다.
Contribution
논문의 contribution은 다음 네 가지입니다.
1) Unified Heterogeneous Inputs
LiDAR, Camera, Temporal voxel을 하나의 3D backbone에 직접 입력합니다.
2) Unified Model
L, LT, LC, LCT 설정을 하나의 모델 구조로 처리합니다. L은 LiDAR-only, LT는 LiDAR + Temporal, LC는 LiDAR + Camera, LCT는 LiDAR + Camera + Temporal입니다.
3) Unified Output Representation
모든 정보를 compact한 BEV feature로 압축하고, 이 feature를 여러 task head가 공유합니다.
4) Superior Performance
detection, tracking, map segmentation, occupancy, motion prediction, planning에서 competitive 또는 SOTA 성능을 보였다고 주장합니다.
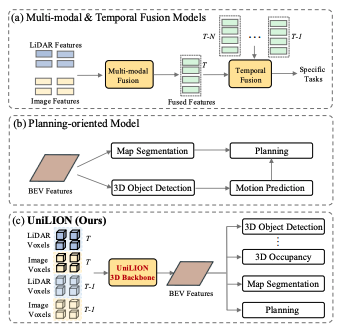
Fig 1
(a)는 멀티모달 융합 또는 시간적 융합을 구현하는 주류 방법들을 보여줍니다.
(b)는 end-to-end 자율주행 시스템을 구현하기 위한 전통적인 파이프라인을 나타냅니다.
(c)는 우리의 방법인 UniLION을 보여주며, UniLION은 여러 입력 모달리티와 시간적 시퀀스를 하나의 다목적 아키텍처로 우아하게 통합합니다.
UniLION은 명시적인 temporal fusion 모듈이나 multi-modal fusion 모듈 없이도 여러 특화된 변형 구조를 자연스럽게 지원할 수 있습니다. 여기에는 LiDAR-only, temporal LiDAR, multi-modal, multi-modal temporal fusion 구성이 포함됩니다.
또한 UniLION은 공유된 BEV feature representation을 통해 여러 downstream task를 서로 분리된 방식으로 동시에 수행할 수 있게 합니다. 이는 UniLION의 3D backbone이 가진 포괄적이고 우수한 feature extraction 능력을 활용하기 때문입니다.
2. Related Works
2.1 Linear RNN
RNN은 sequence를 선형 복잡도로 처리할 수 있다는 장점이 있습니다. 최근에는 Mamba, RWKV 같은 time-parallelizable linear RNN 계열 모델들이 등장했고, Transformer의 quadratic attention 문제를 완화하면서도 좋은 성능을 보여주고 있습니다. 논문은 특히 대규모 outdoor 3D scene에서는 linear RNN이 long-range modeling을 낮은 계산 비용으로 수행할 수 있다고 설명합니다.
2.2 Multi-modal Temporal Fusion
기존 multi-modal fusion은 크게 두 가지입니다.
-
첫째는 LiDAR와 image feature를 BEV space로 변환한 뒤 feature-level fusion을 하는 방식입니다.
-
둘째는 LiDAR point나 voxel을 image plane에 projection해서 cross-modal interaction을 하는 방식입니다.
temporal fusion은 과거 point cloud를 현재 frame과 concat하거나, BEV feature / query feature 수준에서 fusion하는 방식이 많습니다.
UniLION은 이들과 다르게 fusion module을 따로 만들지 않고, LiDAR voxel, camera voxel, temporal voxel을 한 번에 backbone에 넣습니다.
2.3 3D Perception
논문은 3D detection, tracking, BEV map segmentation, occupancy prediction 관련 기존 연구를 정리합니다.
3D detection은 point-based 방식과 voxel-based 방식으로 나뉘고, tracking은 tracking-by-detection 방식과 end-to-end 방식으로 나뉩니다. BEV map segmentation은 BEV feature 위에서 segmentation mask를 예측하고, occupancy prediction은 3D volume feature를 이용해 voxel 단위 occupancy를 예측합니다.
2.4 Motion Prediction and Planning
Motion prediction은 주변 객체의 미래 trajectory를 예측하는 task이고, planning은 ego vehicle의 미래 trajectory를 생성하는 task입니다.
기존 방식은 modular architecture와 parallel architecture로 나뉩니다. Modular 방식은 perception → prediction → planning 순서로 연결되어 error propagation 위험이 있고, parallel 방식은 공유 BEV representation을 이용해 여러 task를 병렬적으로 처리합니다.
2.5 Multi-task Learning
자율주행에서는 detection, map segmentation, occupancy, tracking 등을 하나의 모델로 처리하려는 multi-task learning 연구가 많습니다. UniLION은 여기에 더해 motion prediction과 planning까지 포함하고, extra task-specific design 없이 dynamic multi-task loss 만으로 균형을 맞추려 합니다.
3. Methods
3.1 Overview
UniLION의 전체 구조는 다음과 같습니다.
LiDAR Encoder / Image Encoder → Unified 3D Backbone → BEV Backbone → Task-specific Heads
핵심은 Unified 3D Backbone 입니다. 이 backbone은 Linear Group RNN을 기반으로 하며, 수천 개 voxel을 하나의 group으로 묶어 long-range feature interaction을 수행합니다. 입력으로는 LiDAR voxel, camera voxel, temporal voxel이 모두 들어갈 수 있습니다.
논문의 중요한 관점은 다음과 같습니다.
Fusion을 따로 하지 말고, 모든 voxel을 같은 token sequence로 보고 backbone 안에서 자연스럽게 interaction하게 하자.
즉, Camera-LiDAR fusion, temporal fusion이 명시적 module이 아니라 backbone 내부의 representation learning으로 처리됩니다.
3.2 LiDAR and Image Encoders
LiDAR encoder는 point cloud를 dynamic voxelization 으로 voxel로 바꾸고, 두 개의 linear layer를 통해 LiDAR voxel feature 를 만듭니다. Image encoder는 ResNet-50이나 Swin-Tiny 같은 backbone으로 multi-view image feature 를 추출합니다.
Camera feature를 3D voxel로 올리기 위해, lightweight depth estimation branch를 사용합니다. 이 branch는 pixel-wise depth를 예측하고, confidence가 높은 Top-K depth candidates 를 선택합니다. 기본값은 K=4 입니다. 선택된 depth candidate와 camera matrix를 이용해 2D image feature를 3D coordinate system의 camera voxel로 변환합니다.
중복된 3D 위치에 여러 camera voxel이 생기면 feature를 element-wise summation으로 merge 합니다. 최종적으로 LiDAR voxel과 camera voxel을 voxel dimension 방향으로 concatenate해서 3D backbone에 넣습니다.
3.3 3D Sparse Window Partition
UniLION은 voxel들을 3D sparse window로 나눕니다. window shape은 다음과 같습니다.
여기서 는 각각 X, Y, Z 방향의 window 크기입니다.
그다음 voxel을 X-axis 기준, Y-axis 기준으로 각각 정렬합니다. 이후 동일한 shape의 window로 처리하는 대신, 동일한 group size G 를 가지는 group으로 나눕니다. Transformer 기반 방법은 attention 계산량 때문에 group size를 크게 잡기 어렵지만, UniLION은 Linear RNN을 사용하기 때문에 큰 group size로 long-range interaction이 가능합니다.
쉽게 말하면, voxel을 공간적으로 묶은 뒤 X방향 순서와 Y방향 순서로 길게 펼쳐서 RNN으로 정보 교환을 하는 구조입니다.
3.4 UniLION Block
UniLION Block은 논문의 핵심 모듈입니다. 구성 요소는 다음과 같습니다.
- UniLION Layer
- 3D Spatial Feature Descriptor
- Voxel Merging
- Voxel Expanding
- Auto-regressive Voxel Generation
3.4.1 Voxel Merging and Voxel Expanding
3D point cloud는 sparse하고 irregular하기 때문에, 2D image처럼 단순 max pooling이나 average pooling을 적용하기 어렵습니다. 그래서 UniLION은 down-sampling을 위해 voxel merging, up-sampling을 위해 voxel expanding 을 사용합니다. voxel merging은 down-sampled index mapping을 계산해 voxel을 합치고, voxel expanding은 inverse index mapping으로 다시 up-sampling합니다.
3.4.2 UniLION Layer
UniLION Layer는 두 개의 Linear Group RNN operator로 구성됩니다. 하나는 X-axis window partition 기준으로 long-range feature interaction을 수행하고, 다른 하나는 Y-axis window partition 기준으로 feature interaction을 수행합니다. 두 방향을 모두 사용함으로써 더 충분한 feature interaction을 얻습니다.
즉, 한 방향으로만 scan하면 정보가 부족할 수 있으니, X 방향과 Y 방향 모두에서 sequence modeling을 수행하는 구조입니다.
3.4.3 3D Spatial Feature Descriptor
Linear RNN은 voxel을 1D sequence로 flatten해서 처리합니다. 이때 3D 공간에서 가까운 voxel들이 1D sequence에서는 멀리 떨어질 수 있습니다. 이 문제를 논문은 3D spatial information loss 라고 봅니다.
이를 보완하기 위해 3D Spatial Feature Descriptor를 추가합니다. 이 모듈은 다음으로 구성됩니다.
3D Sub-Manifold Convolution → LayerNorm → GELU
이 모듈은 local 3D position-aware information을 제공해서, Linear RNN이 놓칠 수 있는 local spatial structure를 보완합니다.
3.4.4 Auto-regressive Voxel Generation
Voxel merging 과정에서 정보 손실이 발생할 수 있기 때문에, UniLION은 foreground voxel 주변에 diffused voxel을 생성합니다. 생성된 voxel feature는 처음에 0으로 초기화하고, 이후 UniLION block의 auto-regressive 능력으로 feature를 채우게 합니다.
수식은 다음과 같습니다.
여기서 는 기존 voxel feature, 는 특정 offset 방향으로 diffusion된 voxel feature입니다. ⊕는 concatenation이고, Block은 UniLION block입니다.
3.5 Unified Feature Representation
기존 방법은 multi-modal fusion module, temporal fusion module을 따로 설계합니다. 반면 UniLION은 LiDAR voxel, camera voxel, temporal voxel을 모두 unified 3D backbone에 넣습니다. backbone의 long-range modeling 능력으로 modality 간 관계와 temporal 관계를 스스로 학습하게 합니다.
Multi-modal Feature Learning
LiDAR는 정확한 geometry 정보를 제공하고, camera는 semantic appearance 정보를 제공합니다. UniLION은 두 modality를 별도 fusion하지 않고, 같은 3D voxel coordinate system에 올린 뒤 backbone에 함께 입력합니다.
Temporal Feature Learning
현재 frame의 voxel을 , 이전 frame의 voxel을 라고 하면, 이전 frame voxel을 현재 frame 좌표계로 정렬한 뒤 concatenate합니다.
논문에서는 , 로 표현합니다. 여기서 , 는 각 frame의 voxel 개수이고, 는 channel dimension입니다. 정렬 후 동일한 3D 위치에 있는 voxel은 voxel merging으로 합치고, 최종적으로 unified 3D backbone에 넣습니다.
3.6 Dynamic Multi-task Loss
UniLION은 하나의 BEV feature로 여러 task를 동시에 학습합니다. 따라서 task별 loss scale을 맞추는 것이 중요합니다. 논문에서는 detection loss를 기준으로 각 task loss의 dynamic weight를 계산합니다.
각 task loss가 다음과 같이 주어졌다고 합니다.
task loss 에 대한 dynamic weight는 다음과 같습니다.
최종 loss는 다음과 같이 정의됩니다.
여기서 는 task별 loss weight입니다. 의도는 detection loss를 기준으로 map / occupancy loss scale을 맞추는 것입니다.
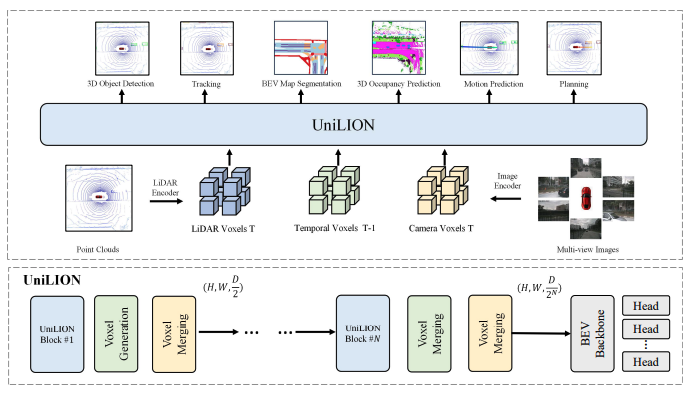
Fig 2
우리는 UniLION을 제안합니다. UniLION은 linear group RNN을 사용하는 UniLION backbone 안에서 잠재적인 temporal fusion과 multi-modal fusion을 모두 수행하는 통합 모델입니다. 이를 통해 perception, prediction, planning을 포함한 모든 자율주행 task에 사용될 수 있는 통합 BEV feature를 생성합니다.
UniLION은 주로 N개의 UniLION block으로 구성됩니다. 각 UniLION block은 feature를 강화하기 위한 voxel generation과, height dimension 방향으로 feature를 down-sampling하기 위한 voxel merging과 함께 사용됩니다.
여기서 는 3D feature map의 shape을 의미합니다.
, , 는 각각 3D feature map에서 X축 방향의 길이, Y축 방향의 너비, Z축 방향의 높이를 나타냅니다.
은 UniLION block의 개수입니다.
UniLION에서는 먼저 입력된 multi-modal voxel들을 동일한 크기의 여러 group으로 나눕니다.
그다음 이렇게 grouping된 feature들을 UniLION 3D backbone에 입력하여 feature representation을 강화합니다.
마지막으로, 강화된 feature들은 BEV backbone으로 전달되어 모든 task에 사용할 수 있는 통합 BEV feature를 생성합니다.
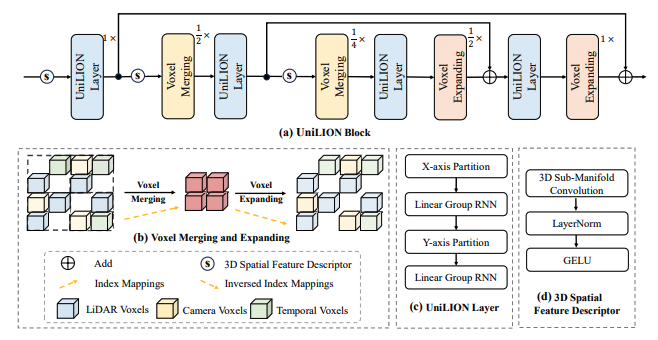
Fig 3
(a)는 UniLION block의 구조를 보여줍니다. UniLION block은 4개의 UniLION layer, 2개의 voxel merging 연산, 2개의 voxel expanding 연산, 그리고 3개의 3D spatial feature descriptor로 구성됩니다.
여기서 , , 는 각각 3D feature map의 해상도를 의미합니다. 즉, 원래 해상도는 , 절반 해상도는 , 1/4 해상도는 입니다.
(b)는 voxel down-sampling을 위한 voxel merging과 voxel up-sampling을 위한 voxel expanding을 설명하는 그림입니다. 논문에서는 입력된 LiDAR voxel, camera voxel, temporal voxel을 병합하기 위해 voxel merging을 사용하며, 이를 통해 multi-modal fusion과 temporal fusion을 수행합니다.
(c)는 UniLION layer의 구조를 나타냅니다.
(d)는 3D spatial feature descriptor의 세부 구조를 보여줍니다.
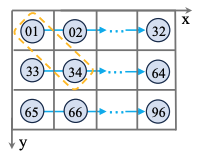
Fig 4
1D 시퀀스로 펼칠 때 발생하는 공간 정보 손실을 설명하는 그림입니다.
예를 들어, 공간 좌표상에서는 서로 인접한 두 voxel이 있습니다. 그림에서는 이 두 voxel이 각각 01번과 34번으로 표시되어 있습니다. 하지만 이 voxel들을 X축 순서에 따라 1D sequence로 flatten하면, 원래는 가까이 있던 두 voxel이 1D sequence 상에서는 서로 멀리 떨어지게 됩니다.
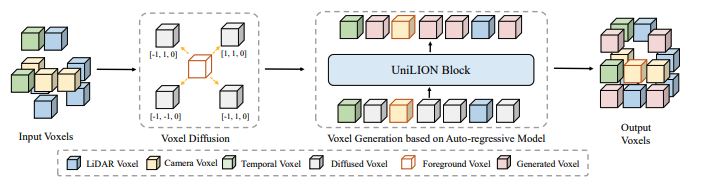
Fig 5
voxel generation을 설명하는 그림입니다.
먼저 LiDAR voxel, camera voxel, temporal voxel 중에서 foreground voxel을 선택합니다. 여기서 foreground voxel은 배경이 아니라 객체나 도로 구조물처럼 중요한 정보를 가진 voxel을 의미합니다.
그다음 선택된 foreground voxel들을 여러 방향으로 diffuse, 즉 주변 방향으로 확산시킵니다.
이후 확산되어 새롭게 만들어진 voxel들의 feature는 처음에는 0으로 초기화합니다. 그리고 뒤따르는 UniLION block의 auto-regressive 능력을 활용해, 이 확산된 voxel들의 feature를 생성합니다.
4. Experiments
4.1 Dataset and Evaluation Metrics
실험은 nuScenes 에서 수행합니다. nuScenes는 1000개 scene으로 구성되어 있고, train 750개, validation 150개, test 150개로 나뉩니다. LiDAR point cloud와 6개 surrounding camera image를 제공합니다.
평가 task와 metric은 다음과 같습니다.
Task & Metric
3D Object Detection : mAP, NDS
3D Multi-object Tracking : AMOTA
BEV Map Segmentation : mIoU
3D Occupancy Prediction : RayIoU
Motion Prediction : minADE
Planning : L2 distance, collision rate
4.2 Implementation Details
논문은 네 가지 설정을 평가합니다.
설정 & 의미
L : LiDAR-only
LT : LiDAR + Temporal
LC : LiDAR + Camera
LCT : LiDAR + Camera + Temporal
모든 variant는 하나의 unified 3D backbone 구조를 사용합니다. voxel grid resolution은 이고, UniLION block 수는 입니다.
중요한 점은 inference 단계에서 하나의 LCT 모델이 temporal이나 camera input을 끄는 방식으로 L, LT, LC 형태로도 사용될 수 있다는 것입니다. 즉, sensor configuration이 달라도 별도 모델을 학습하지 않고 대응할 수 있다는 것이 논문의 장점입니다.
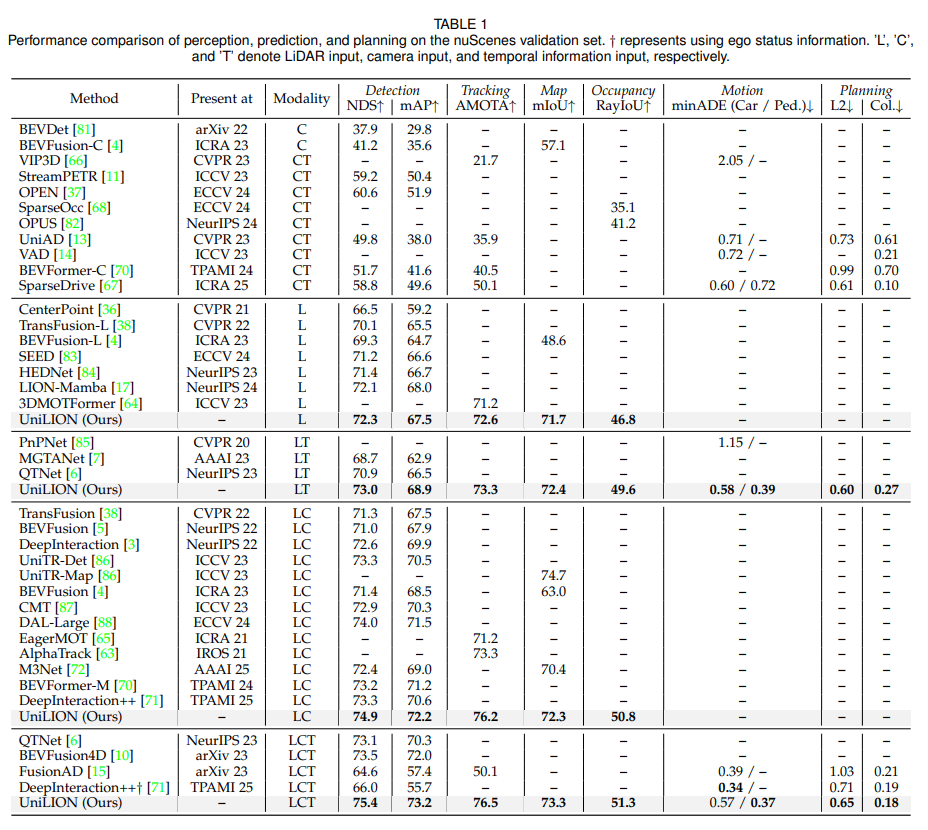
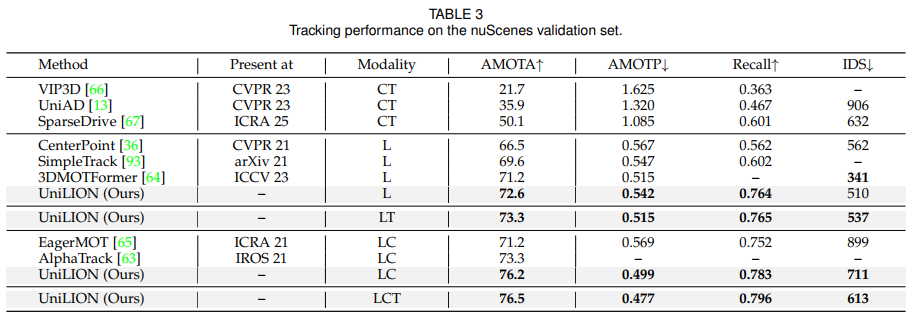
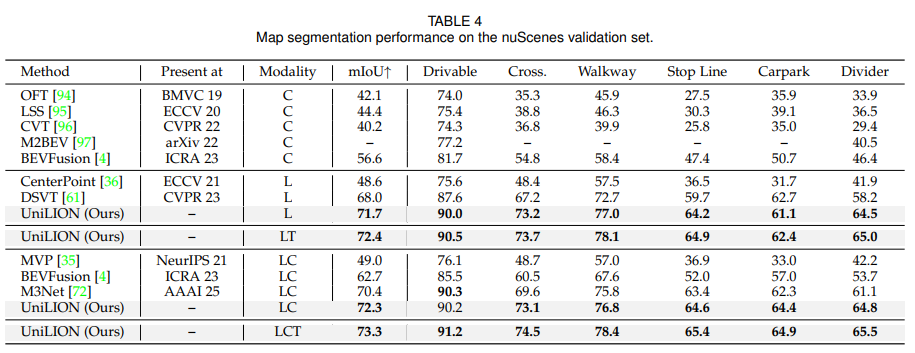
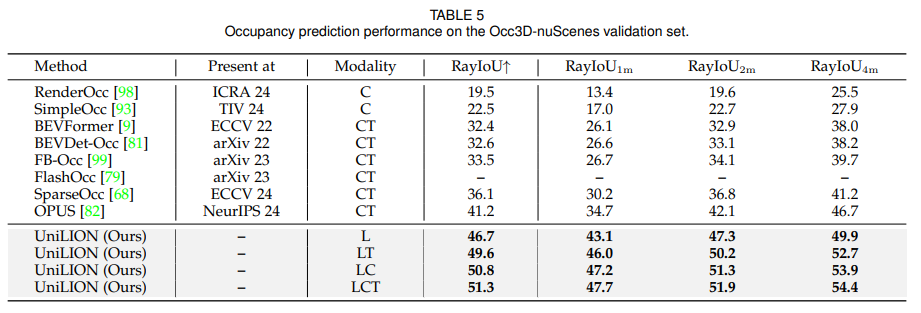
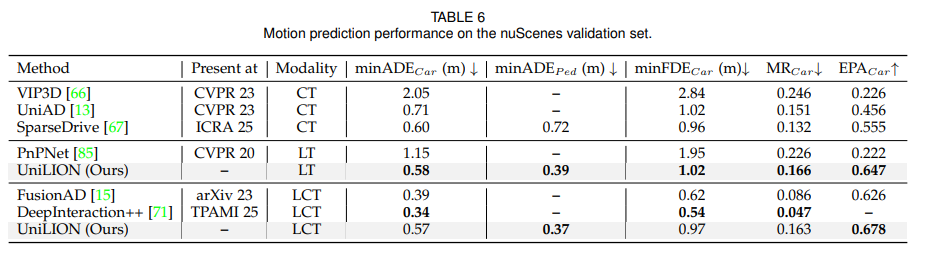
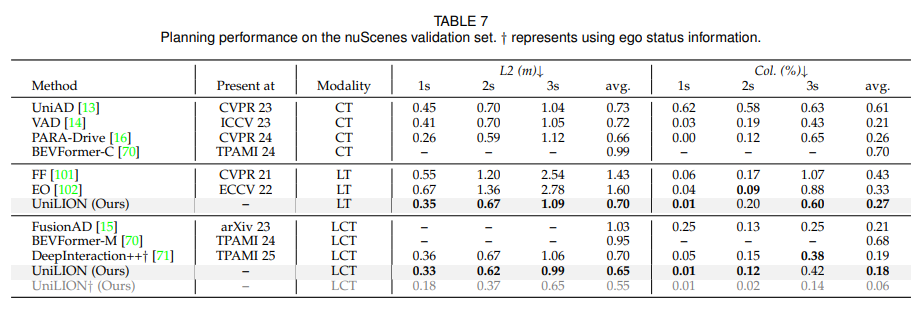
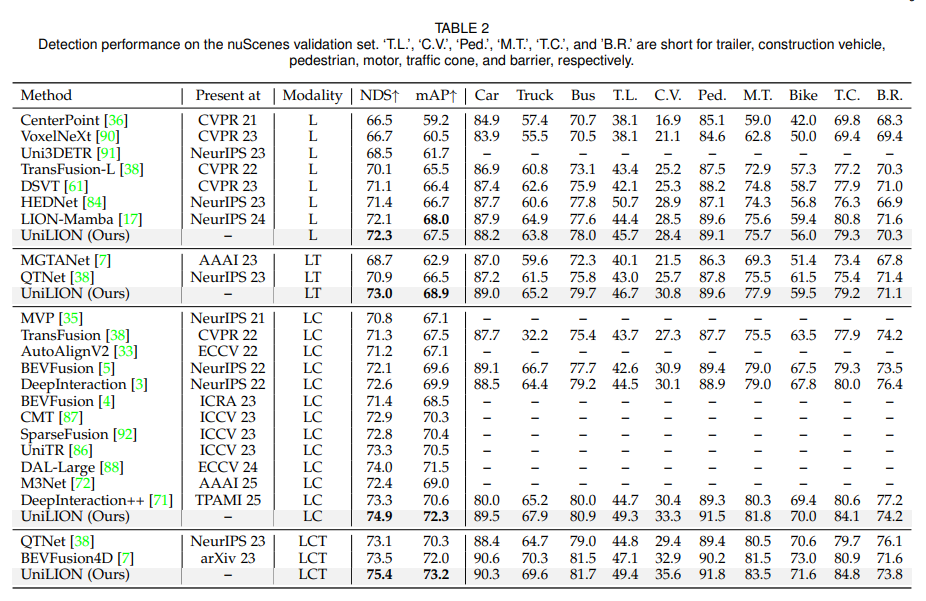
4.3 Comparisons with State-of-the-art Methods
UniLION은 nuScenes validation set에서 6개 task를 평가합니다. 논문은 LCT 설정이 가장 강력하다고 보고합니다. LCT 모델은 다음 성능을 달성합니다.
논문은 특히 UniLION이 ego status information 없이 planning task에서 낮은 collision rate를 얻었다고 강조합니다.
LiDAR-only에서도 꽤 강한 성능을 보입니다. L 설정에서 72.3% NDS, 67.5% mAP, 72.6% AMOTA, 71.7% mIoU, 46.8% RayIoU를 달성합니다. Temporal을 추가한 LT에서는 detection, tracking, map, occupancy 성능이 모두 향상됩니다.
4.4 Ablation Studies
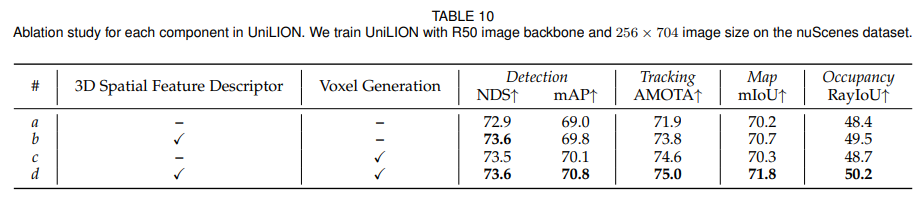
4.4.1 Component Ablation
논문은 3D Spatial Feature Descriptor와 Voxel Generation의 효과를 검증합니다. baseline 대비 두 모듈을 모두 넣었을 때 성능은 다음과 같이 향상됩니다.
즉, local spatial information을 보완하는 모듈과 foreground voxel을 확장하는 전략이 모두 성능 향상에 기여합니다.
4.4.2 Dynamic Loss Ablation
Dynamic loss를 적용하면 detection, tracking, map segmentation 성능은 향상되지만, occupancy는 약간 하락합니다. 논문은 dynamic loss가 전체 task balance를 맞추는 방향으로 작동하기 때문에 특정 task 최적화에는 손해가 있을 수 있다고 해석합니다.

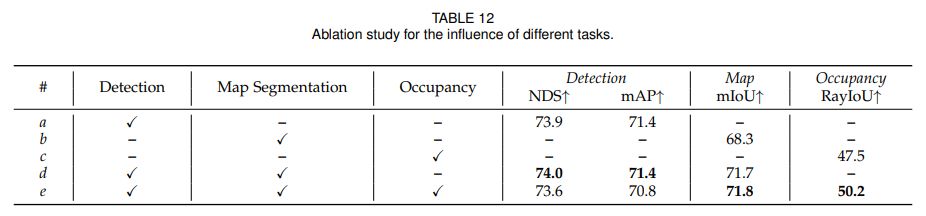
4.4.3 Multi-task Learning
Detection만 학습하거나 map segmentation만 학습하는 경우보다, detection과 map segmentation을 함께 학습하면 map segmentation 성능이 크게 좋아집니다. occupancy까지 함께 넣으면 detection은 약간 떨어지지만 occupancy는 좋아집니다. 논문은 이를 통해 UniLION의 shared BEV feature가 multi-task 학습에 효과적이라고 주장합니다.
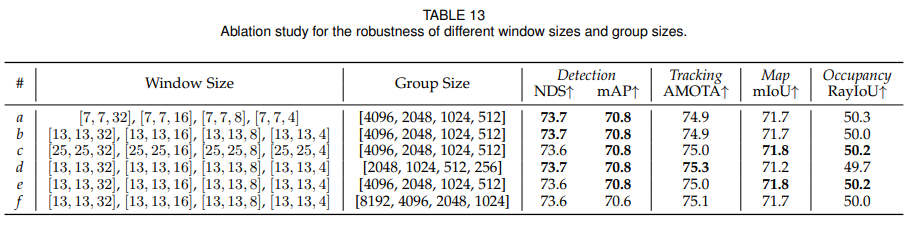
4.4.4 Robustness to Input Modality
흥미로운 실험은 LCT로 학습한 모델에서 inference 시 camera나 temporal input을 꺼보는 실험입니다. LCT로 학습한 뒤 temporal만 끄고 LC처럼 써도 성능이 거의 유지됩니다. camera와 temporal을 모두 꺼서 LiDAR-only처럼 써도 70.6 NDS를 달성해, TransFusion-L과 BEVFusion-L보다 높은 detection score를 보였다고 합니다.
즉, 논문이 주장하는 unified model adaptability를 보여주는 핵심 ablation입니다.
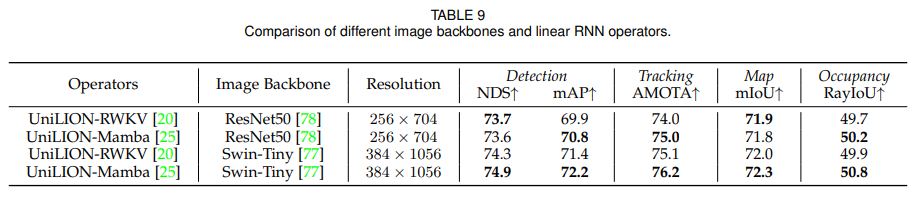
4.4.5 Different Image Backbones and Linear RNN Operators
Swin-Tiny backbone 을 쓰는 기본 모델보다 ResNet-50 + 낮은 image resolution을 쓰는 lightweight 모델은 성능이 낮지만 여전히 괜찮은 결과를 냅니다. 또한 Linear RNN operator로 Mamba뿐 아니라 RWKV도 실험했는데, RWKV는 Mamba보다 약간 낮지만 여전히 좋은 성능을 보입니다. 이는 UniLION framework가 특정 Linear RNN operator에 완전히 종속되지 않는다는 근거로 제시됩니다.
4.4.6 Sensor Misalignment Robustness
LiDAR-camera calibration이 틀어지는 상황을 시뮬레이션합니다. Low / Middle / High misalignment는 각각 camera extrinsic matrix를 vertical 방향으로 1.5°, 3.0°, 5.0° 회전시키고, 0.15m, 0.30m, 0.50m translation을 주는 방식입니다. High misalignment에서도 multi-modal UniLION이 LiDAR-only보다 성능이 높게 유지되어 sensor misalignment에 강하다고 주장합니다.
4.4.7 Top-K Depth Candidates
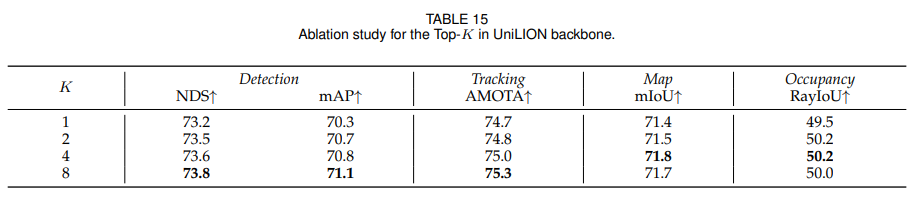
Camera voxel을 만들 때 depth candidate 수 K를 바꿔 실험합니다. K가 커질수록 detection 성능은 대체로 좋아지지만, 계산량과 성능의 trade-off를 고려해 기본값을 K=4로 설정합니다.
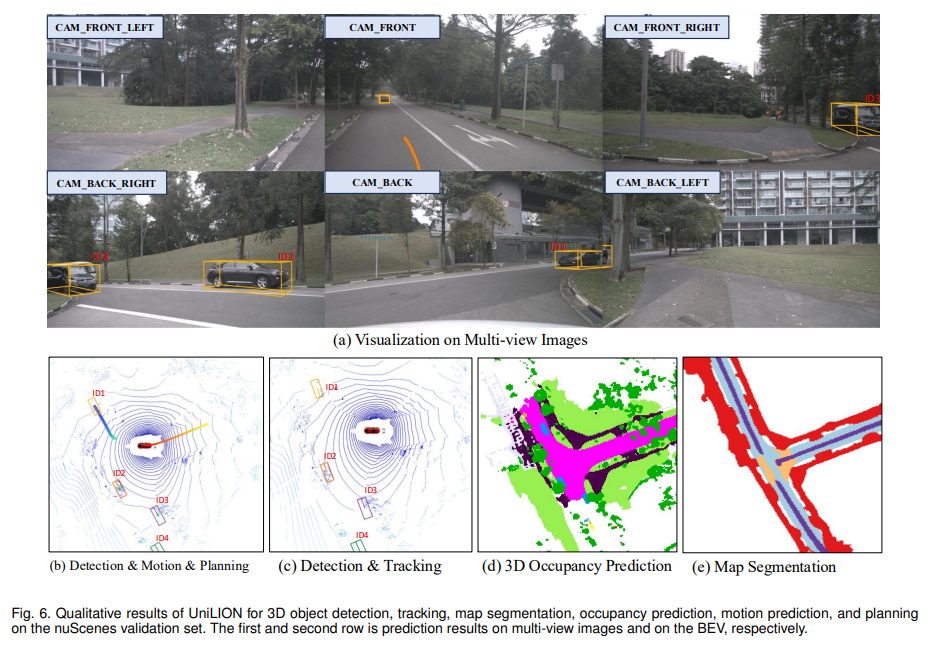
4.5 Analysis of Visualization
시각화 분석에서는 detection, tracking, occupancy, map segmentation, motion prediction, planning 결과를 qualitative하게 보여줍니다.
논문은 UniLION이 distant object를 잘 검출하고, frame 간 object ID를 안정적으로 유지하며, occupancy와 map element를 정확히 예측한다고 설명합니다. Motion prediction에서는 moving object와 static object를 구분하고, planning에서는 collision을 피하는 합리적 trajectory를 생성한다고 주장합니다.
5. Conclusion
UniLION은 Linear RNN 기반 unified 3D backbone 으로, LiDAR, Camera, Temporal 정보를 별도 fusion module 없이 처리합니다. 이 backbone은 다양한 정보를 compact한 BEV representation으로 압축하고, 이를 여러 autonomous driving task가 공유합니다. 결과적으로 detection, tracking, occupancy prediction, BEV map segmentation, motion prediction, planning에서 competitive 또는 SOTA 수준의 성능을 보였다고 주장합니다.
