[컴퓨터비전 STUDY / KOCW 한동대학교 황성수 교수님 강의 Review]
Introduction
Training stage
-
대량의 객체 이미지와 객체가 아닌 이미지를 수집한다.
(객체가 아닌 이미지가 훨씬 더 많아야 함) -
개체를 표현하기에 적합한 특징을 찾는다.
-
개체를 분류할 분류기(임계값)를 설계한다.
Test stage
-
입력 영상으로부터 feature을 추출해낸다.
-
trained classifier를 사용해서 물체를 감지한다.
Feature
OpenCV에 있는 Harr-like feature 알고리즘을 사용해서 얼굴을 검출할 수 있다.
-
해당 영역의 feature 값은 직사각형 내 영역의 픽셀 총합의 차이로 정의할 수 있다.
(밝은 부분과 어두운 부분 pixel들의 각각의 합을 구한 뒤, 빼 줌) -
원본 이미지 내의 모든 위치와 스케일에서 사용할 수 있다.
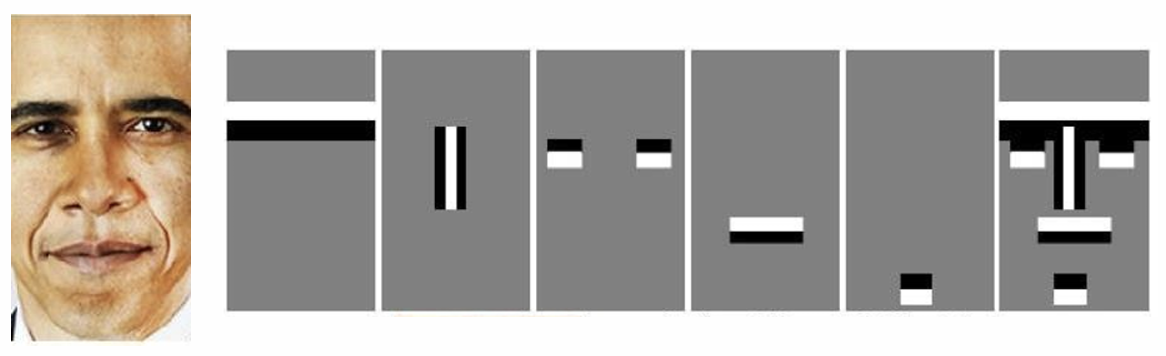
왼쪽에 있는 것처럼 다양한 Feature 특징이 있으며, 얼굴을 검출하기에 가장 적합한 Feature을 선택할 수 있다.

Training
크기와 위치를 변경하여 많은 features를 생성할 수 있다.
그것들 중에서 사람 얼굴을 검출하기에 가장 알맞은 features를 선택한다.
예를 들면, 두 눈은 검은색, 눈 사이 미간은 하얀색의 특징을 포함할 수 있다.

이러한 적당한 Feature를 찾아내기 위해 openCV에서는 Adaboost(Adaptive Boosting)을 사용한다.
Boosting : weak-learner 집합은 strong learner을 만들어 낸다.
Adaptive : 이미 훈련된 weak-learner의 정확도에 따라 각 샘플의 가중치가 조정된다.
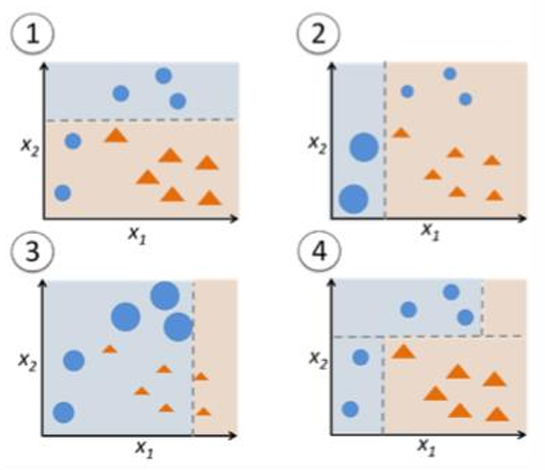
다음은 그림에 대한 설명이다.
1번에서는 weak-learner가 얼굴인 그림(원)과 얼굴이 아닌 그림(세모)을 비교적 잘 구분하고 있다. 하지만 좌측 하단에 있는 원들은 잘 구분해 내지 못한다.
따라서, 2번에서는 좌측 하단에 있는 원들만큼은 잘 구분해 내기 위해 해당 영역에 weight를 많이 부여한다.
3번에서는 우측 상단에 있는 원들을 잘 구분해 내기 위해 해당 영역에 weight를 많이 부여한다.
1, 2, 3을 조합해서 4에서 새로운 특징을 만들고 모든 그림을 잘 분류해 냄으로, 최종적인 strong-learner를 생성한다.
Harr-like features 알고리즘을 사용하여 다음과 같이 얼굴 표현을 할 수 있다.
(가장 적합한 feature을 찾음)
Cascade classifier
다수의 weak-learner를 사용하여 strong-learner를 생성한다.
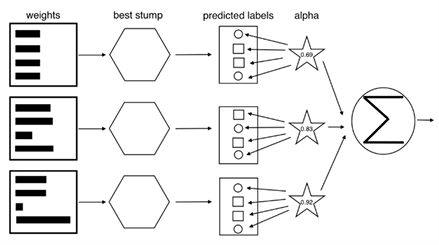
각각의 strong learner은 cascade로 연결된다.
▪ 각 strong-learner의 weak-learner 수 : 3>2>1
(수가 적은 것을 앞으로 빼, 알고리즘 속도를 향상시킴)
▪ 많은 non-face 영역이 쉽게 제거된다.
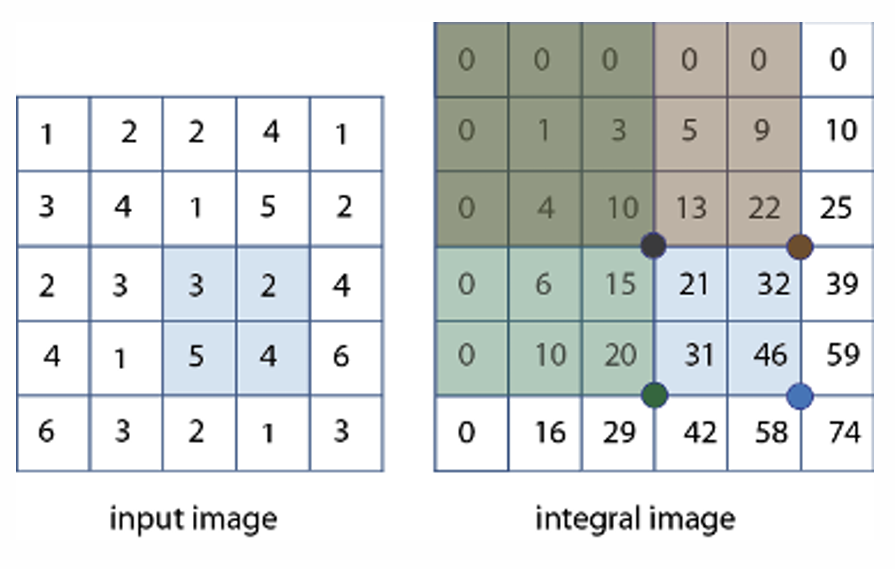
Integral image를 사용하여 Harr-like feature 알고리즘의 빠른 계산을 수행할 수 있다.
원래는 색칠된 영역의 우측 하단 값 46을 구하려면 Input image는 +연산을 15번 수행해야 하지만 Integral image는 +연산을 3번만 수행하면 된다.
따라서 빠르다는 장점으로 인해 Integral image를 face detection Algorithm에서 사용한다.
다음은 face_classifier를 사용하는 예시이다.

- OPENCV provides various classifiers (eye, upper body, etc.)
in “…\opencv\sources\data\haarcascades” 처럼 다양한 영역을 검출하기 위한 xml 파일이 이미 사전학습되어 있다. 우리는 이것을 불러와서 사용하는 것뿐이다.
openCV function인 CascadeClassifier은 다음과 같다.

-
Image : 개체가 감지되는 이미지를 포함하는 CV_8U 유형의 행렬 (Input)
-
Objects : 각 직사각형이 있는 직사각형의 벡터는 검출된 개체를 포함하며, 직사각형은 부분적으로 원래 이미지 외부에 있을 수 있다. (얼굴 영역)
-
numDetections : 해당 개체에 대한 detection 번호 벡터이다. 또한 이것은 어떤 개체의 탐지 번호는 개체를 구성하기 위해 서로 결합된 인접한 양으로 분류된 직사각형의 개수이다. (얼굴 영역 중복 검출)
-
scaleFactor : 각 영상 스케일에서 영상 크기가 감소하는 정도를 지정하는 매개 변수이다. (다양한 크기의 얼굴 검출)
-
minNeighbors : 각 후보 직사각형을 유지해야 하는 이웃 수를 지정하는 매개 변수이다. (예를 들어, 얼굴 검출이 3번 이상 되어야 확정하는 방식)
-
flags : old cascade에 대해 cvHaarDetectObjects 함수에서와 동일한 의미의 매개 변수이다. 이 매개 변수는 new cascade에 사용되지 않는다.
-
minSize : 최소 임계값이며, 가능한 최소 개체 크기를 의미한다. 이것보다 작은 개체는 무시된다.
-
maxSize : 최대 임계값이며, 가능한 최대 개체 크기를 의미한다. 이것보다 큰 개체는 무시된다. 추가로, maxSize == minSize인 경우 모델은 단일 척도로 평가된다.
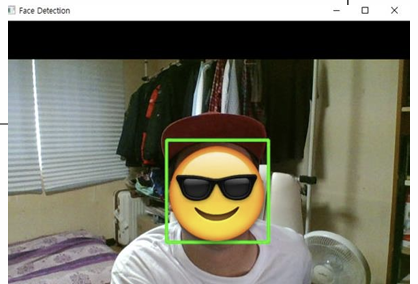
다음은 Face Detection을 수행하는 예시 코드이다.
CascadeClassifier face_classifier;
Mat frame, grayframe;
vector<Rect> faces;
int i;
// openthewebcam
VideoCapturecap(0); // 웹캠을 연다.
// checkifwesucceeded
if (!cap.isOpened()) {
cout<< "Couldnotopencamera" << endl;
return-1;
}
// facedetectionconfiguration
// 얼굴 검출을 위한 분류기를 생성함
face_classifier.load("haarcascade_frontalface_alt.xml");
while(true) {
// get a new frame from webcam
cap>> frame;
// convert captured frame to gray scale
cvtColor(frame, grayframe, COLOR_BGR2GRAY); // gray scale로 변환
// grayscale 프레임에서 얼굴을 감지함
// 결과를 faces에 저장, 감지 스케일 비율 (1.1), 최소 요소 수 3, 최소 객체 크기 (size(30, 30))
face_classifier.detectMultiScale(
grayframe,
faces,
1.1, // increase search scale by 10% each pass
3, // merge groups of three detections
0, // not used for a new cascade
Size(30, 30) //min size
);
// draw the results 결과 출력
for (i = 0; i < faces.size(); i++) {
Point lb(faces[i].x + faces[i].width, faces[i].y + faces[i].height);
Point tr(faces[i].x, faces[i].y);
rectangle(frame, lb, tr, Scalar(0, 255, 0), 3, 4, 0);
}
// print the output
imshow("Face Detection", frame);
if (waitKey(33) == 27) break;
}결과는 다음과 같다.