
서버와 클라이언트는 다음과 같은 정보를 식별할 수 있어야 한다.
- 클라이언트가 메시지를 주고받고자 하는 대상을 식별해야 함
- 송수신하고자 하는 정보를 식별해야 함
1번은 도메인 네임을 통해,
2번은 URL과 URN을 통해 식별할 수 있다.
각각에 대해 먼저 살펴보자.
DNS(Domain Name System)
DNS 란 계층적이고 분산된 도메인 네임에 대한 관리체계이자 이를 관리하는 애플리케이션 계층 프로토콜이다.
도메인 네임과 네임 서버
네트워크 상의 어떤 호스트를 특정하기 위해 IP 주소를 사용한다고 했는데, 오로지 IP만 사용하기에는 번거로울 수 있다.
이는 호스트의 IP 주소는 언제든지 바뀔 수 있고, 기억하기 어렵다는데서 기인한다.
그래서 사용자는 일반적으로 상대 호스트를 특정하기 위해 도메인 네임 을 많이 사용한다.
예를 들어, www.example.com 과 같은 문자열이 도메인 네임이다.
도메인 네임과 IP 주소는 묶어서 관리하는데, 이를 관리하는 서버를 네임 서버(혹은 DNS 서버) 라고 부른다.
네임 서버(DNS 서버)는 호스트의 도메인 네임과 IP 주소를 모아 관리하는 공용 전화번호부와 같은 역할을 한다.
도메인 네임을 네임 서버에 질의하면, 해당 도메인 네임에 대한 IP 주소를 알아낼 수 있다.
물론, 반대도 가능하다.
도메인 네임을 쓰는 이유
- 도메인 네임은 IP에 비해 기억하기 쉽다.
- IP 주소가 바뀌더라도, 바뀐 IP 주소에 도메인 네임을 대응하면 되어 IP 주소만으로 호스트를 특정하는 것보다 간편하다.
도메인 네임 관리
도메인 네임은 점(.)을 기준으로 계층적으로 분류된다.
최상단에 루트 도메인이 있고, 그 다음 단계인최상위 도메인이 있으며, 계속 그 다음 단계의 도메인이 존재한다.
다음 그림을 보자.
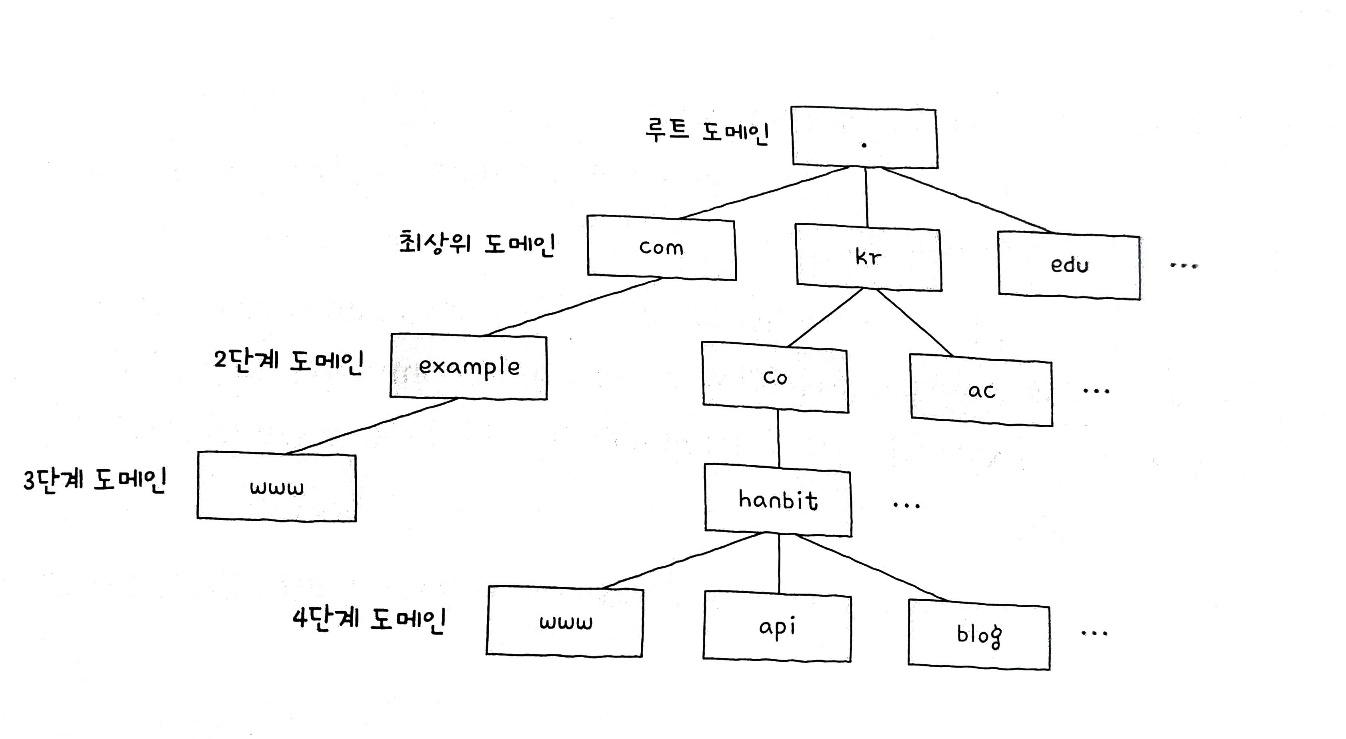
흔히 최상위 도메인을 도메인 네임의 마지막 부분이라고 생각하기 쉬운데, 사실 루트 도메인도 도메인 네임의 일부이다.
다만 일반적으로 루트 도메인을 생략해서 표기해서, 우리가 흔히 볼 수 있는 www.example.com 과 같은 주소의 마지막에는 점(.)이 생략되어 있다고 생각하면 된다.
www.example.com 에서 www 는 3단계 도메인이고, 도메인의 단계는 더 늘어날 수 있지만, 일반적으로는 3~5 단계 정도이다.
그리고 위 주소 처럼 도메인 네임을 모두 포함하는 도메인 네임을 전체 주소 도메인 네임(FQDN; Fully-Qualified Domain Name) 이라고 한다.
계층적 네임 서버
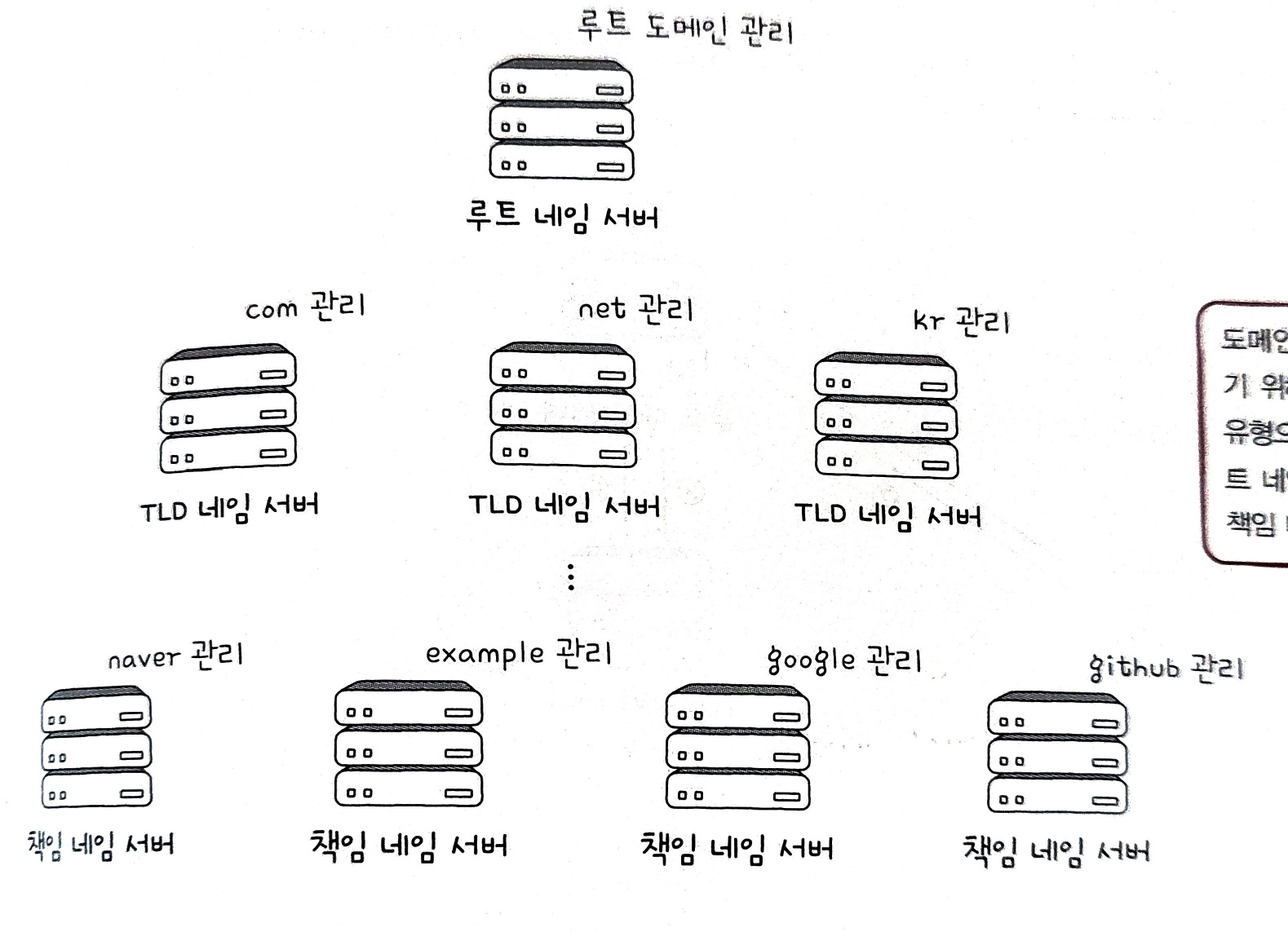
DNS가 계층적이고 분산된 도메인 네임에 대한 관리체계라고 했는데, 계층적인 도메인 네임을 효율적으로 관리하기 위해 네임 서버 또한 계층적인 형태를 이룬다.
IP 주소를 모르는 상태에서 도메인 네임에 대응되는 IP 주소를 알아내는 과정을 리졸빙(resolving) 한다라고 하고, 이 과정에서 아래와 같은 다양한 네임 서버들이 사용된다.
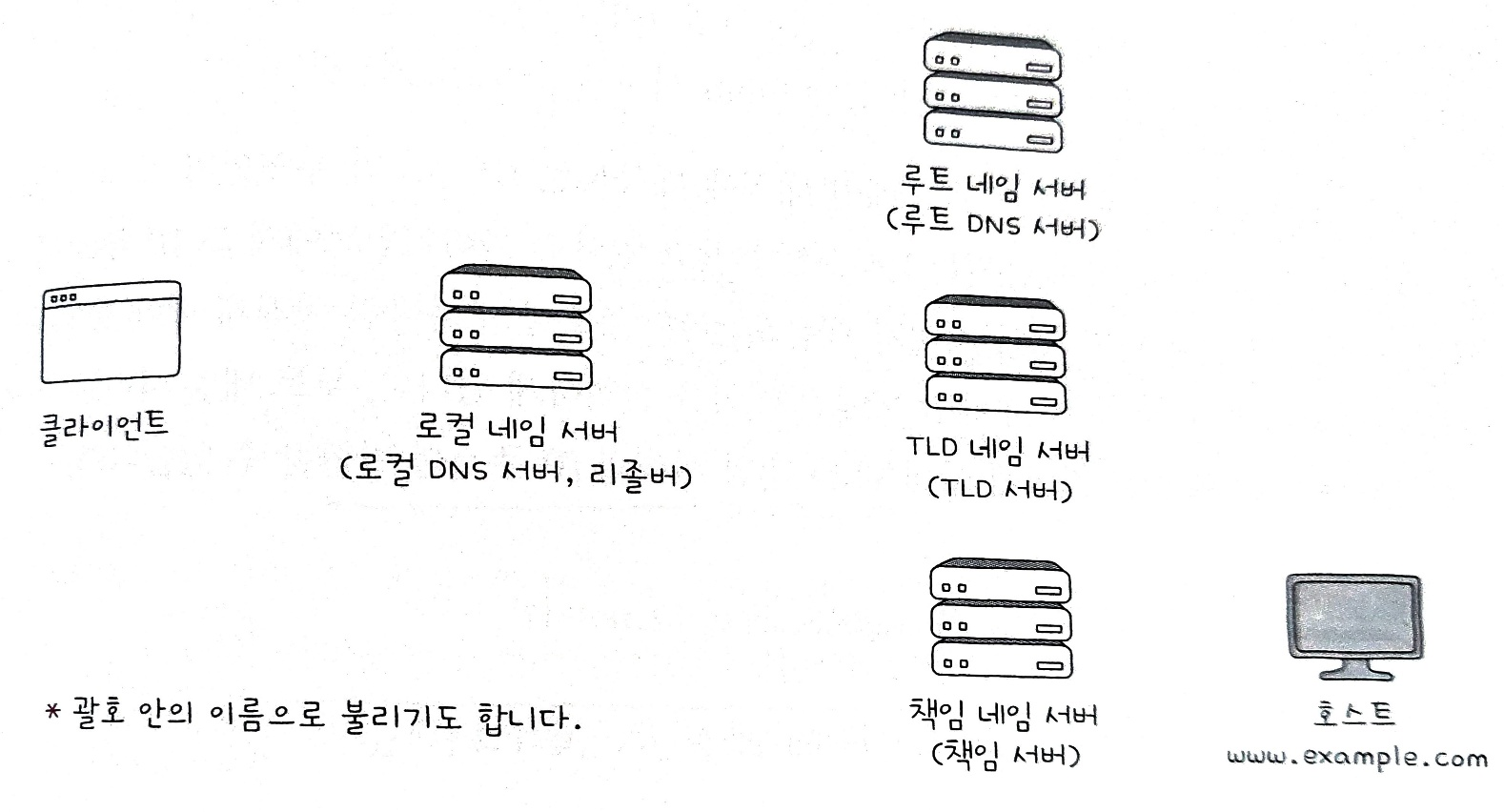
로컬 네임 서버, 루트 네임 서버, TLD(최상위 도메인) 네임 서버, 책임 네임 서버에 대해 알아보자.
로컬 네임 서버(local name server)
클라이언트와 맞닿아 있는 네임 서버로, 클라이언트가 도메인 네임을 통해 IP 주소를 알아내고자 할 때 가장 먼저 찾게되는 네임 서버이다.
로컬 네임 서버의 주소는 1. ISP에서 할당해주거나 2. 공개 DNS 서버를 이용하거나 로 결정된다.
일반적으로는 ISP에서 할당해 주는 경우가 많지만, 구글의 8.8.8.8 8.8.4.4 와 클라우드 플레어의 1.1.1.1 와 같은 공개 DNS 서버를 이용할 수도 있다.
만약 로컬 네임서버가 대응되는 IP 주소를 알고 있다면, 클라이언트에게 IP 주소를 알려준다.
만약 로컬 네임서버가 대응되는 IP 주소를 모를 경우에는 루트 네임 서버 에게 해당 도메인 네임을 질의하게 된다.
루트 네임 서버(root name server)
루트 네임 서버는 루트 도메인을 관장하는 네임 서버로, 질의에 대해 TLD 네임 서버의 IP 주소를 반환하는 역할을 한다.
단순히 다음 네임 서버의 위치(IP)를 반환하는 역할만 수행한다.
TLD(최상위 도메인) 네임 서버
TLD를 관리하는 네임 서버이다. TLD 네임 서버는 다음 그림과 같이 질의에 대해 TLD 하위 도메인 네임을 관리하는 네임 서버 주소를 반환한다.
단순히 다음 네임 서버의 위치(IP)를 반환하는 역할만 수행한다.
책임 네임 서버(authoritative name server)
자신이 관리하는 도메인 영역의 질의에 대해서는 다른 서버에게 떠넘기지 않고 곧바로 답할 수 있는 네임 서버이다.
일반적으로 로컬 네임 서버는 책임 네임 서버로부터 원하는 IP 주소를 얻어낸다.
결국 아래처럼 네임 서버들은 계층적인 구조를 띠고 있다.
재귀적 질의와 반복적 질의
재귀적 질의(recursive query)
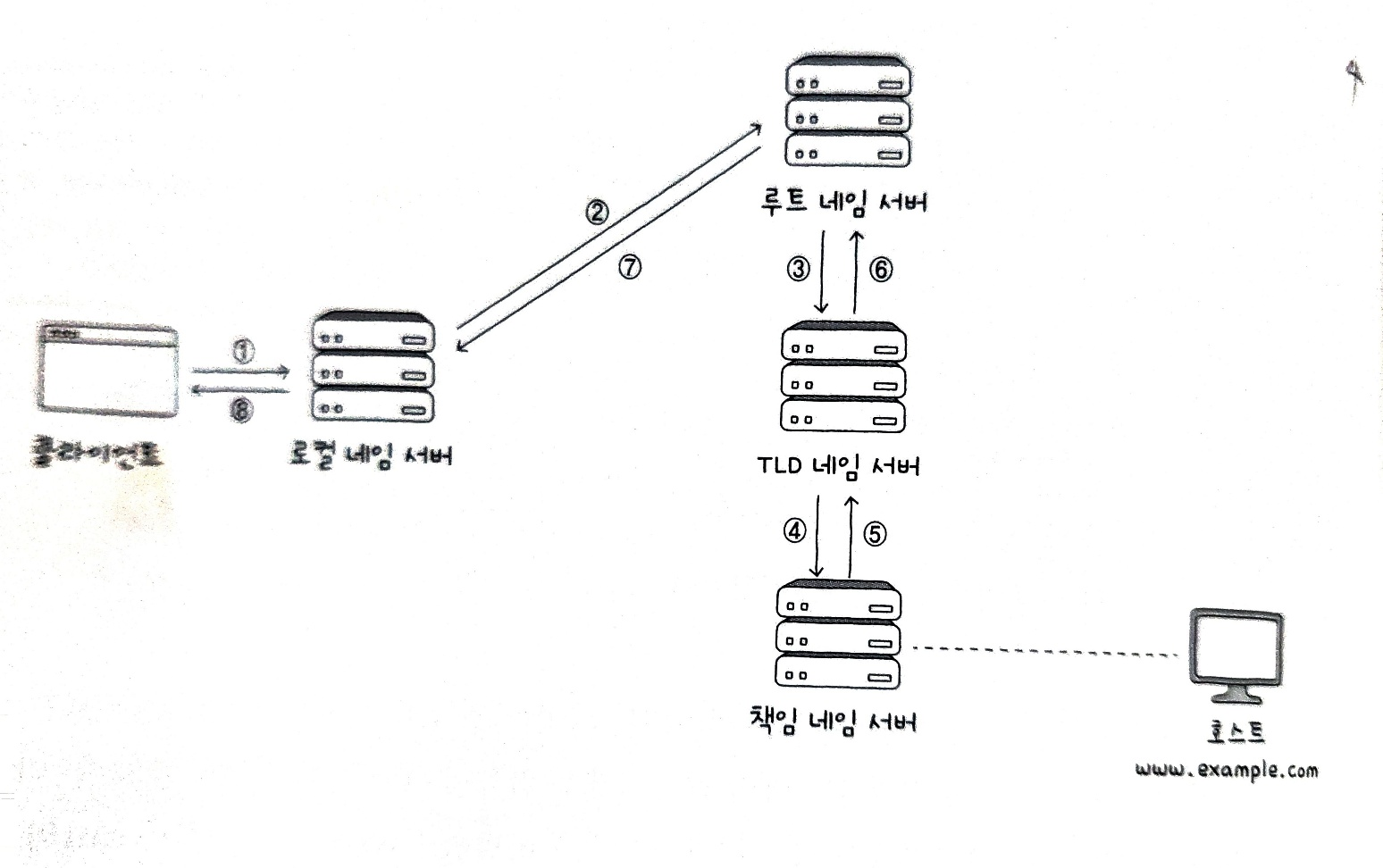
재귀적 질의 는 클라이언트가 로컬 네임 서버에게 도메인 네임을 질의하면, 로컬 네임 서버는 루트 네임 서버에게, 루트 네임 서버는 TLD 네임 서버에게, TLD 네임 서버가 다음 단계에 질의하는 과정을 반복하며 최종 응답을 역순으로 전달받는, 즉 재귀적으로 질의가 이루어지는 방식이다.
반복적 질의(iterative query)
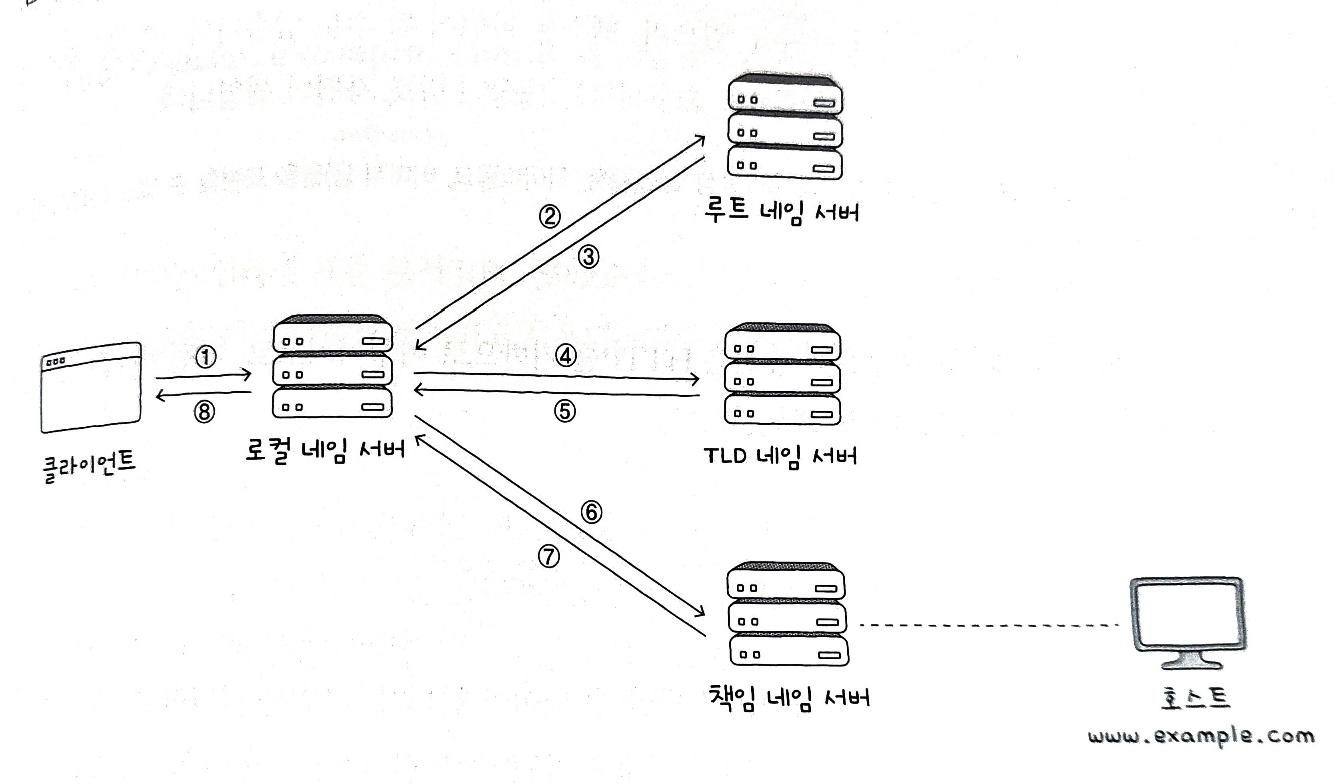
반복적 질의 는 로컬 네임 서버의 역할이 두드러진다.
반복적 질의란 클라이언트가 로컬 네임 서버에게 IP 주소를 알고 싶은 도메인 네임을 질의하면, 로컬 네임 서버는 루트 도메인에게 질의해서 다음으로 질의할 네임 서버의 주소를 응답 받고, 이렇게 다음으로 질의할 네임 서버의 주소를 응답받는 과정을 반복하다가 최종 응답 결과를 클라이언트에게 알려주는 방식이다.
DNS 캐시
위의 리졸빙 방식은 여러 단계를 거쳐야 해서 시간이 오래 걸리고 네트워크 상의 메시지 수가 지나치게 늘어날 수 있다는 단점이 있다.
이를 보완하기 위해, 네임 서버들이 기존에 응답받은 결과를 임시로 저장했다가 추후 같은 질의에 이를 활용할 수 있는데, 이를 DNS 캐시 라고 한다.
임시 저장된 값은 TTL(Time To Live) 라는 값이 만료되면 사라진다.
자원을 식별하는 URI
송수신하고자 하는 정보를 식별하기 위한 방식인 URI와, URI를 식별 정보 기준으로 분류한 개념인 URL, URN에 대해 살펴볼 것이다.
이 개념들을 이해하기 전, 자원(resource) 에 대한 이해가 필요하다.
자원 이란 네트워크상의 메시지를 통해 주고받는 대상을 의미한다.
이는 HTML 파일이 될 수도 있고, 이미지나 동영상, 혹은 텍스트 파일이 될 수도 있다.
네트워크 상에서 자원을 주고받으려면 자원을 식별할 수 있어야 한다.
자원을 식별할 수 있는 정보를 URI(Uniform Resource Identifier) 라고 부른다.
위치를 이용해 자원을 식별하는 방식을 URL(Uniform Resource Locator) 이라 하고,
이름을 이용해 자원을 식별하는 방식을 URN(Uniform Resource Name) 이라 한다.
URL(Uniform Resource Locator)
오늘날 더 많이 사용되는 방식은 URL 이다.
일반적인 URL 형식은 다음과 같다.
각각의 부분에 대해 살펴보자.
1. scheme
scheme 은 자원에 접근하는 방법을 의미한다. 일반적으로 사용할 프로토콜이 명시되는데, HTTP를 사용하여 자원에 접근할 때는 http:// 를 사용하고, HTTPS를 사용하여 자원에 접근할 때는 https:// 을 사용한다.
2. authority
authority 에는 호스트를 특정할 수 있는 정보, 이를 테면 IP 주소 혹은 도메인 네임이 명시된다. 콜론 뒤에 포트 번호를 덧붙일 수도 있다.
3. path
자원이 위치한 경로가 명시된다. 자원의 위치는 슬래시(/)를 기준으로 표현되고, 최상위 경로 또한 슬래시로 표현된다.
만약, 최상위 경로(/) 아래, home(/home) 아래, images(/home/images) 아래에 a.png 이라는 자원이 있다고 하면
a.png의 path는 /home/images/a.png 이 된다.
4. query
URL 구문만으로 자원의 위치를 식별할 수 있는 경우도 있지만, 더 많은 정보 가 필요할 때 사용할 수 있는 것이 쿼리 문자열(혹은 쿼리 파라미터) 이다.
쿼리 문자열은 물음표(?)로 시작되는 <키=값>의 형태로 앰퍼샌드(&)를 사용하여 여러 쿼리 문자열을 연결할 수 있다.
아래와 같이 말이다.
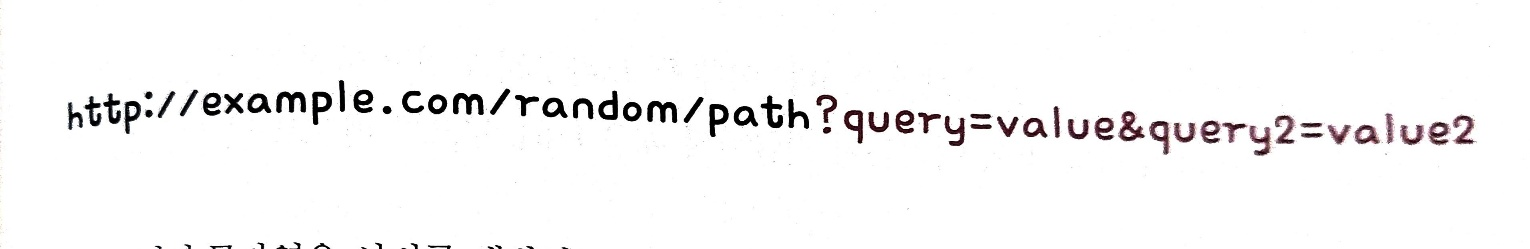
fragment
fragment는 자원의 한 조각을 가리키기 위한 정보 이다. 흔히 HTML 파일과 같은 자원에서 특정 부분을 가리키기 위해 사용된다.
만약 #section-1.1.2 라는 fragment가 있다면, HTML 파일의 특정부분으로 이동하여 보일 것이고,
fragment가 없다면, HTML의 첫 부분이 보일 것이다.
URN(Uniform Resource Name)
만약, 자원의 위치가 변한다면 URL은 유효해지지 않을 수 있다.
이것은 URL의 고질적인 문제 중 하나인데, URN은 이를 보완할 수 있다.
URN은 자원에 고유한 이름을 붙이는 이름 기반 식별자다. 따라서, 자원의 위치와 무관하게 자원을 식별할 수 있다는 장점이 있다.
다음 URN은 ISBN이 0451450523인 도서를 나타내는 URN 예시이다.
urn:isbn:0451450523
이와 같은 URN을 이용하면 위치나 프로토콜과 무관하게 자원을 식별할 수 있다.
다만 URN은 아직 URL 만큼 널리 채택된 방식은 아니기에 자원을 식별할 URI로는 URL이 더 많이 사용된다.
HTTP(Hypertext Transfer Protocol)
HTTP는 응용
HTTP에는 중요한 네 가지 특성이 있다.
- 요청과 응답을 기반으로 동작
- 미디어 독립적
- 상태를 유지하지 않음
- 지속 연결을 지원
이 특성들에 대해 살펴보자.
HTTP의 특성
요청-응답 기반 프로토콜
HTTP는 클라이언트-서버 구조 기반의 요청-응답 프로토콜 이다.
HTTP는 클라이언트와 서버가 서로 HTTP 요청 메시지와 HTTP 응답 메시지를 주고받는 구조로 동작한다.
같은 HTTP 메시지일지라도, HTTP 요청 메시지와 HTTP 응답 메시지는 형태가 다르다.
미디어 독립적 프로토콜
그렇다면 HTTP로는 어떤 자원을 주고받을 수 있을까?
HTTP는 자원의 특성을 제한하지 않는다.
다시 말해서, HTTP는 주고받을 자원의 특성과 무관하게 그저 자원을 주고받을 수단(인터페이스) 역할을 수행한다.
HTTP에서 메시지로 주고받는 자원의 종류를 미디어 타입 혹은 MIME 타입(Multipurpose Internet Mail Extensions Type) 이라고 부른다.
미디어 타입은 기본적으로 슬래시를 기준으로하는 타입/서브타입 형식으로 구성된다.
타입 은 데이터의 유형을 나타내고, 서브타입 은 주어진 타입에 대한 세부 유형을 나타낸다.
text/html text/plain image/png 가 그 예시다.
또한 미디어 탕비에는 부가적인 설명을 위해 선택적으로 매개변수가 포함될 수도 있다.
매개변수는 타입/서브타입;매개변수=값 의 형식으로 표현된다.
예를 들어 type/html;charset=UTF-8 은 미디어 타입이 HTML 문서 타입이며, HTML 문서 내에서 사용된 문자는 모두 UTF-8로 인코딩되었음을 의미한다.
스테이트리스 프로토콜
HTTP는 상태를 유지하지 않는 스테이트리스(stateless) 프로토콜이다.
이는 서버가 HTTP 요청을 보낸 클라이언트와 관련된 상태를 기억하지 않는다는 의미이다.
이러한 특성 때문에 클라이언트의 모든 HTTP 요청은 기본적으로 독립적인 요청으로 간주된다.
만약 HTTP가 상태를 유지하는 프로토콜이었다면 어땠을까?
서버가 모든 클라이언트의 상태 정보를 유지해야 하기 때문에, 서버에 부담이 갈 것이다.
또한, 서버가 여러 대로 구성될 경우, 모든 서버가 모든 클라이언트의 상태 정보를 공유해야 하는데 이는 매우 번거롭고 어려운 작업이다.
그리고 클라이언트는 자신의 상태를 기억하는 특정 서버하고만 상호 작용할 수 있게 되어, 특정 클라이언트가 특정 서버에 종속될 수 있다.
HTTP가 처음 만들어졌을 때부터 오늘날까지 이어지는 중요한 설계 목표는 확장성(scalability) 과 견고성(robustness) 이다.
스테이트리스한 특성은 언제든 쉽게 서버를 추가할 수 있게 해주어 높은 확장성을, 서버 중 하나에 문제가 생겨도 쉽게 다른 서버로 대체가 가능하다는 점 때문에 높은 견고성을 보장할 수 있다.
지속 연결 프로토콜
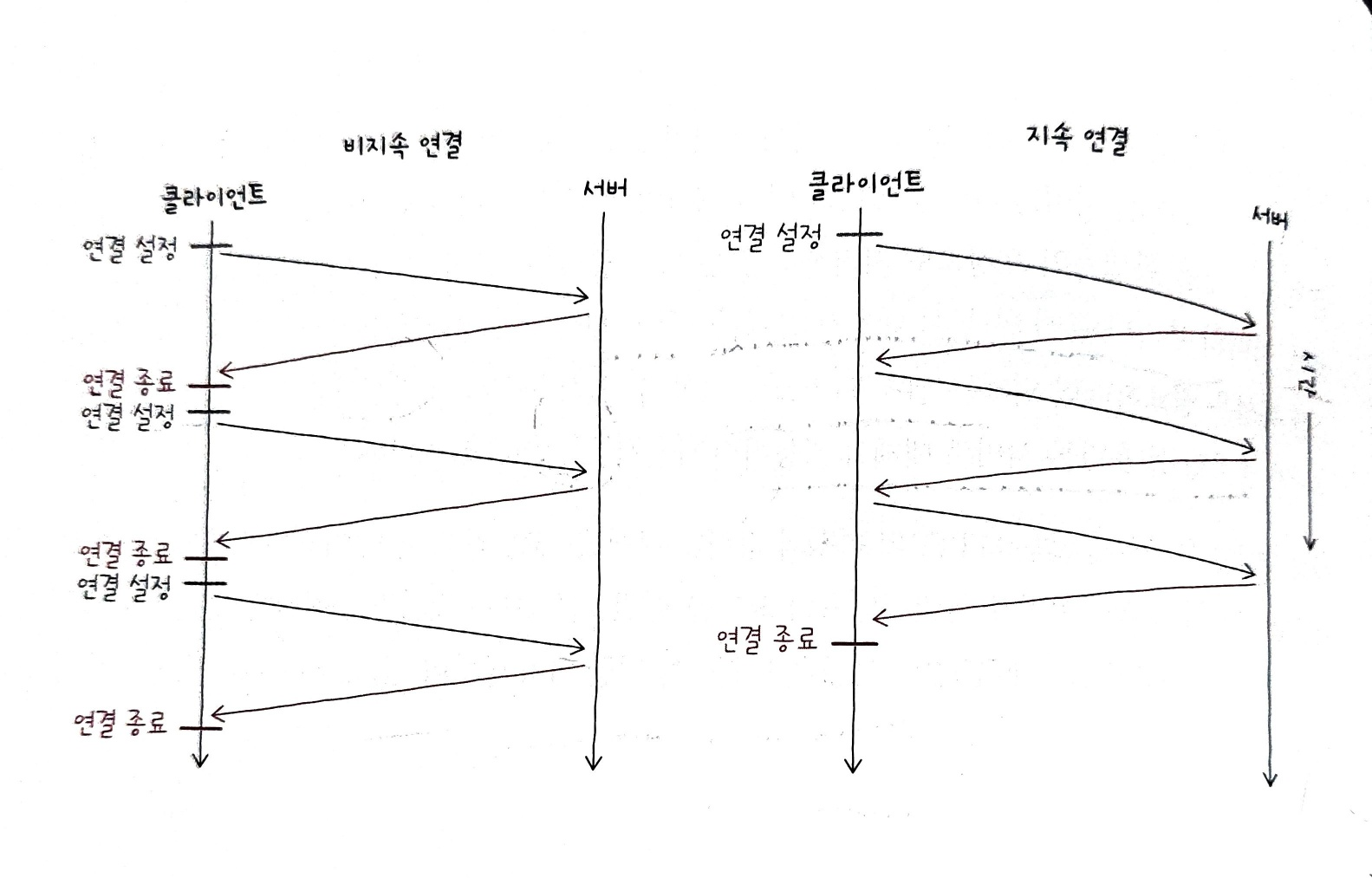
기본적으로 HTTP는 TCP 상에서 동작하는데, HTTP는 비연결형 프로토콜이지만, TCP는 연결형 프로토콜이다.
따라서 초기의 HTTP 버전은 쓰리 웨이 핸드셰이크를 통해 TCP 연결을 수립한 후, 요청에 대한 응답을 받으면 연결을 종료하는 방식으로 동작했다.
만약, 이후 추가적인 요청-응답이 필요하다면 다시 TCP 연결을 수립해야했다.
이러한 방식을 비지속 연결 이라고 한다.
하지만, 최근 대중적으로 사용되는 HTTP 버전(HTTP 1.1 이상)은 지속 연결 이라는 기술을 제공한다. 이는 킵 얼라이브(keep-alive) 라고도 부른다.
이는 하나의 TCP 연결상에서 여러 개의 요청-응답을 주고받을 수 있는 기술이다.
아래 그림을 통해 비지속 연결과 지속 연결의 차이점을 볼 수 있다.
HTTP 버전
https://developer.mozilla.org/ko/docs/Web/HTTP/Guides/Evolution_of_HTTP
HTTP 메시지 구조
대중적으로 사용되는 HTTP 1.1 버전의 메시지를 위주로 학습하겠다.
HTTP 메시지의 구조는 크게 다음과 같다.

HTTP 메시지는 시작 라인 필드 라인 메시지 본문 으로 이루어져 있다.
필드 라인 과 메시지 본문 사이에는 빈 줄바꿈이 있다.
시작 라인
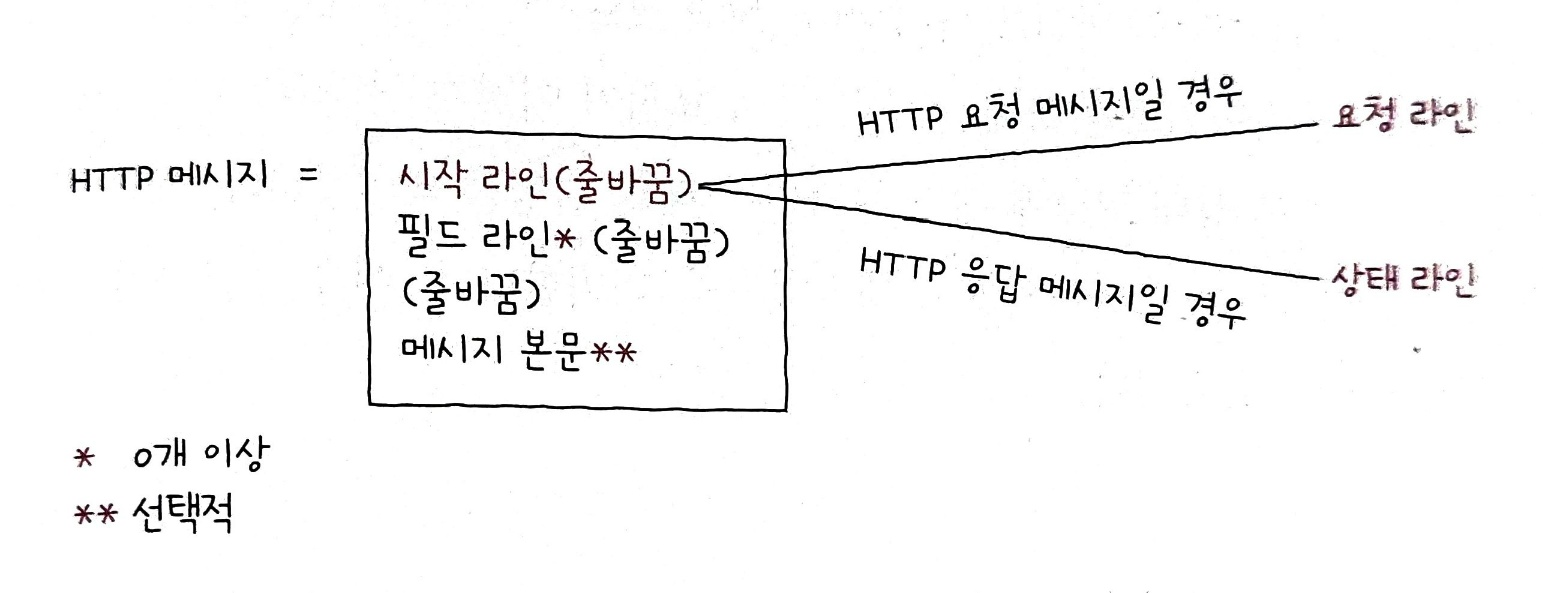
HTTP 메시지가 HTTP 요청 메시지일 경우, 시작 라인 은 요청 라인이 된다.
HTTP 메시지가 HTTP 응답 메시지일 경우, 시작 라인 은 상태 라인이 된다.
요청 라인(request-line)
요청 라인의 형식은 다음과 같다.

메서드(method)
메서드 란 클라이언트가 서버의 자원(요청 대상)에 대해 수행할 작업의 종류를 나타낸다.
대표적으로 GET POST PUT DELETE 등이 있다.
요청 대상(request-target)
요청 대상은 HTTP 요청을 보낼 서버의 자원을 의미한다.
보통 이곳에는 (쿼리가 포함된) URL의 경로가 명시된다.
http://www.example.com/hello?q=world 로 요청을 보낼 경우, 요청 대상은 /hello?q=word가 된다.
HTTP 버전(HTTP-version)
이름 그대로 사용된 HTTP 버전을 의미한다.
HTTP/<버전> 과 같이 표기되며, HTTP 버전 1.1은 HTTP/1.1 로 표기된다.
상태 라인(status-line)
상태 라인의 형식은 다음과 같다.
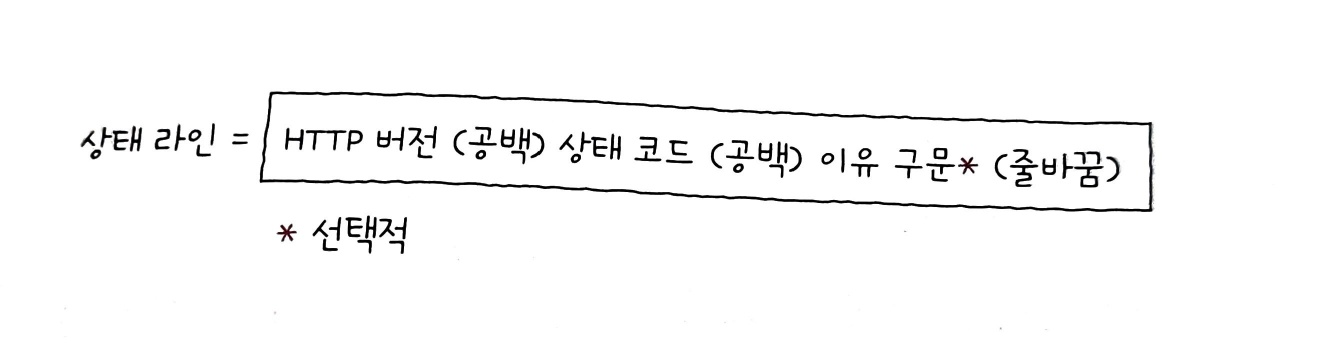
상태 코드(status code)
요청에 대한 결과를 나타내는 세 자리 정수이다.
클라이언트는 상태 코드를 통해 요청이 어떻게 처리되었는지 판단할 수 있다.
예를 들어, 200 은 요청이 성공적으로 받아들여지고 수행되었음 을, 404 는 요청한 자원이 존재하지 않음 을 의미한다.
HTTP/1.1 200 OK HTTP/1.1 404 Not Found 와 같이 표현된다.
필드 라인
필드 라인에는 0개 이상의 HTTP 헤더가 명시된다. 그래서 이를 헤더 라인 이라고도 부른다.
필드 라인에 명시되는 각 HTTP 헤더는 콜론(:)을 기준으로 헤더 이름 고 하나 이상의 헤더 값 으로 구성 된다.
다음 그림에서 첫 줄을 제외한 부분이 HTTP 헤더이다.

이 부분은 다룰 내용이 꽤 있으니, 아래서 따로 정리하겠다.
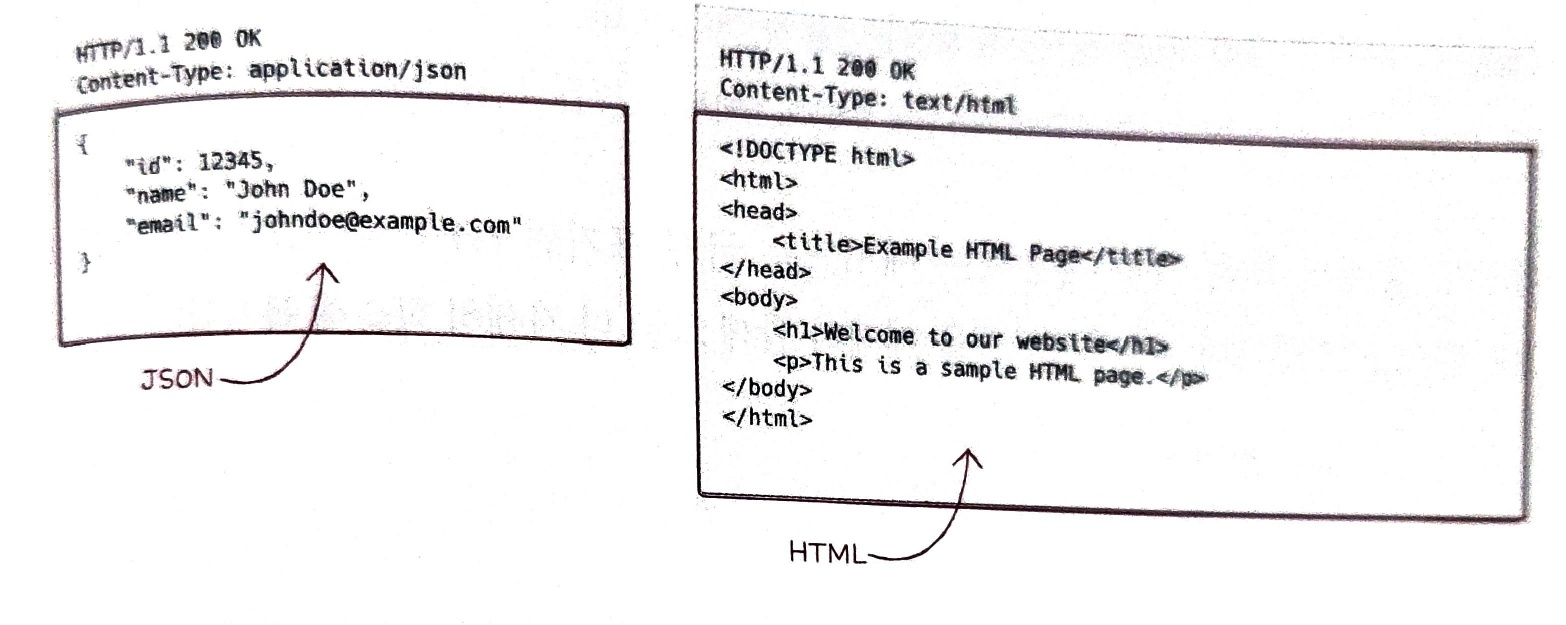
메시지 본문(message-body)
HTTP 요청 혹은 응답 메시지에서 본문이 필요할 경우 이는 메시지 본문 에 명시된다.
메시지 본문은 존재하지 않을 수도 있고, 다음과 같이 다양한 콘텐츠 타입이 사용될 수도 있다.
HTTP 메서드
HTTP 요청 메시지에서 사용될 수 있는 다양한 메서드를 학습해보자.
다음과 같은 종류가 있다.

GET - 가져다 주세요
GET 메서드는 특정 자원을 조회할 때 사용된다.
가장 흔히 사용되는 메서드 중 하나이며, 웹 브라우저에서도 빈번히 사용된다.
GET 메서드에 요청 메시지 본문을 포함시키는 것은 바람직하지 않으며, 쿼리 문자열이 사용되는 경우가 많다.
HEAD - 헤더만 가져다 주세요
HEAD 메서드는 사실상 GET 메서드와 동일한 역할을 한다.
유일한 차이점은 응답 메시지에 메시지 본문이 포함되지 않는다는 것이다.
즉, 서버는 요청에 대한 응답으로 응답 메시지의 헤더만을 반환한다.
POST - 처리해 주세요
POST 메서드는 서버로 하여금 특정 작업을 처리하도록 요청하는 메서드이다.
처리할 대상은 흔히 메시지 본문으로 명시된다.
만약 성공적으로 POST 요청이 처리되어 새로운 자원이 생성되면, 서버는 응답 메시지의 Location 헤더를 통해 새로 생성된 자원의 위치를 클라이언트에게 알려줄 수 있다.
PUT - 덮어써 주세요
PUT 메서드는 쉽게 말해서 '덮어쓰기' 를 요청하는 메서드이다.
요청 자원이 없다면 메시지 본문으로 새롭게 생성하거나,
이미 자원이 존재한다면 메시지 본문으로 자원을 완전히 대체하는 메서드이다.
PATCH - 일부 수정해주세요
PATCH 메서드는 PUT 메서드와 비교하며 이해하는 것이 좋다.
PUT 메서드가 덮어쓰기, 완전한 대체에 가깝다면,
PATCH 메서드는 부분적 수정이다.
만약, 기존 데이터와 요청 데이터가 일치하는 정보가 있다면, 그 부분은 그대로 유지하고 일치하지 않는 부분만 덮어쓴다고 생각하면 된다.
DELETE - 삭제해 주세요
DELETE 메서드는 특정 자원을 삭제하고 싶을 때 사용하는 메서드다.
HTTP 상태 코드
상태 코드는 요청에 대한 결과를 나타내는 세 자리 정수이다.
상태 코드는 굉장히 다양하지만, 백의 자리 수를 기준으로 유형을 구분할 수 있다.

자주 사용되는 200번대 상태 코드부터 500 번대 상태 코드까지 자세히 알아보자.
200번대 : 성공 상태 코드
200번대 상태 코드는 요청이 성공했음 을 의미한다.
주로 사용되는 상태 코드는 200(OK) 201(Created) 202(Accepted), 204(No Content) 이다.

201(Created)
POST 요청을 통해 서버에 새로운 자원을 성공한 경우, 상태 코드 201로 요청이 성공했으며 새로운 자원이 만들어졌음을 알린다.
202(Accepted)
요청을 잘 받았으나, 아직 요청한 작업을 끝내지 않았음을 의미한다.
작업 시간이 긴 대용량 파일 업로드 작업이나 배치 작업과 같이 요청 결과를 곧바로 응답하기 어려운 상황에 사용된다.
204(No Content)
요청 메시지에 대해 성공적으로 작업을 완료했더라도 마땅히 메시지 본문으로 표기할 것이 없을 경우 상태코드 204로 응답할 수 있다.
200은 응답 본문이 있지만 204는 그렇지 않음을 기억하자.
300번대 : 리다이렉션 코드
리다이렉트 란 클라이언트가 요청한 자원이 다른 곳에 있을 때, 클라이언트의 요청을 다른 곳으로 이동시키는 것을 의미한다.
클라이언트가 요청한 자원이 다른 URL에 있을 경우, 서버는 응답 메시지의 Location 헤더를 통해 요청한 자원이 위치한 URL을 안내해줄 수 있다.
이를 수신한 클라이언트는 Location 헤더에 명시된 URL로 즉시 재요청을 보내어 새로운 URL에 대한 응답을 받게 된다.
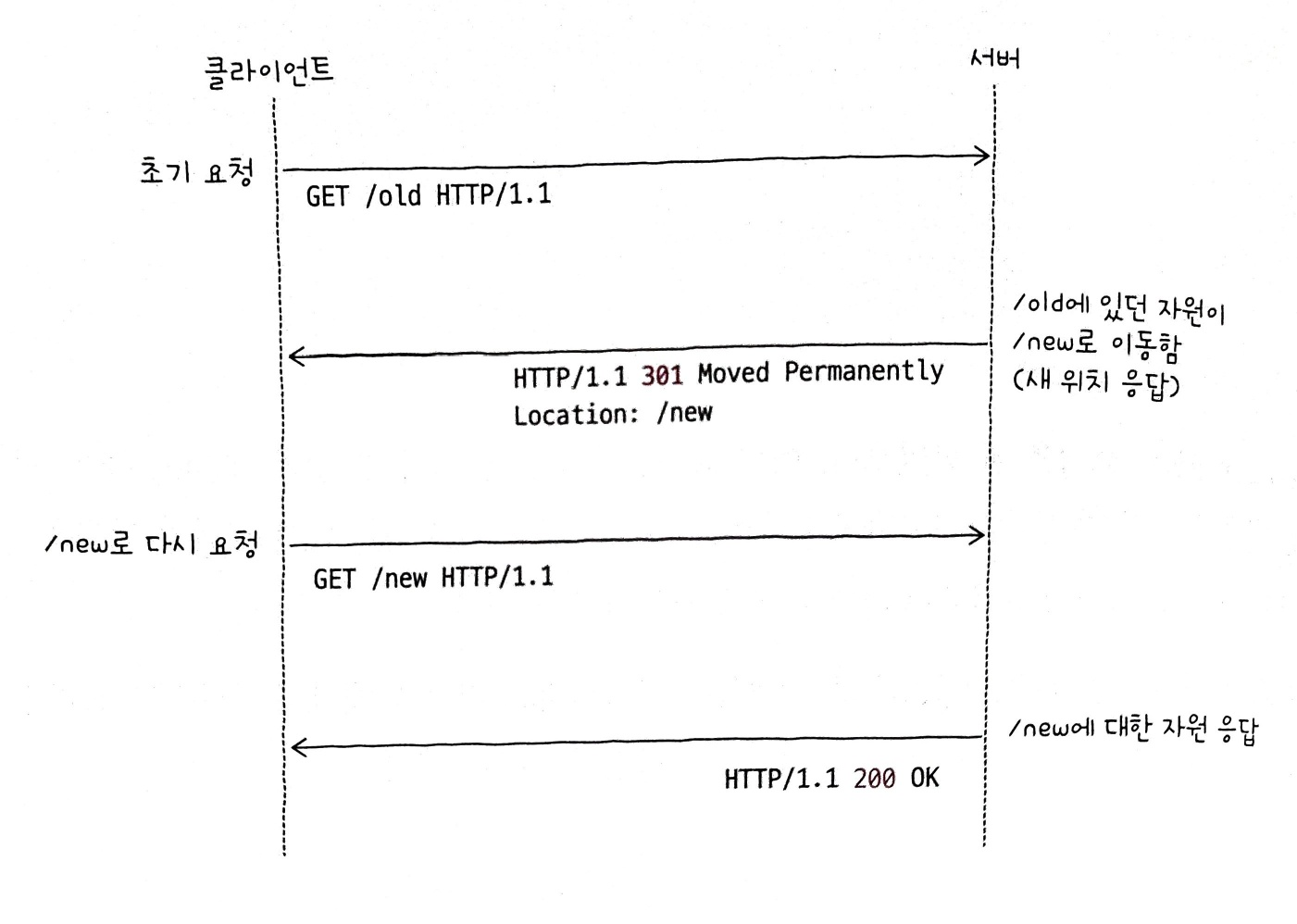
리다이렉션의 유형은 크게 영구적인 리다이렉션 과 일시적인 리다이렉션 으로 구분된다.
영구적인 리다이렉션(permanent redirection)
영구적인 리다이렉션(permanent redirection) 은 자원이 완전히 새로운 곳으로 이동하여 경로가 영구적으로 재지정되는 것을 의미한다.
서버가 도메인을 이전하는 등 웹 사이트의 큰 개편이 있을 때 이런 영구적인 리다이렉션을 접할 수 있다.
영구적인 리다이렉션과 관련한 상태 코드로는 301과 308이 있다.

상태 코드 301과 308의 차이점은 클라이언트의 재요청 메서드 변경 여부 에 있다.
클라이언트가 처음에 POST 메서드로 요청을 보낸 뒤, Location 헤더에 명시된 경로로 재요청을 보내야 한다는 상황에서, 두 번째 요청 메서드는 다음 그림처럼 GET 요청으로 바뀔 수도 있다.
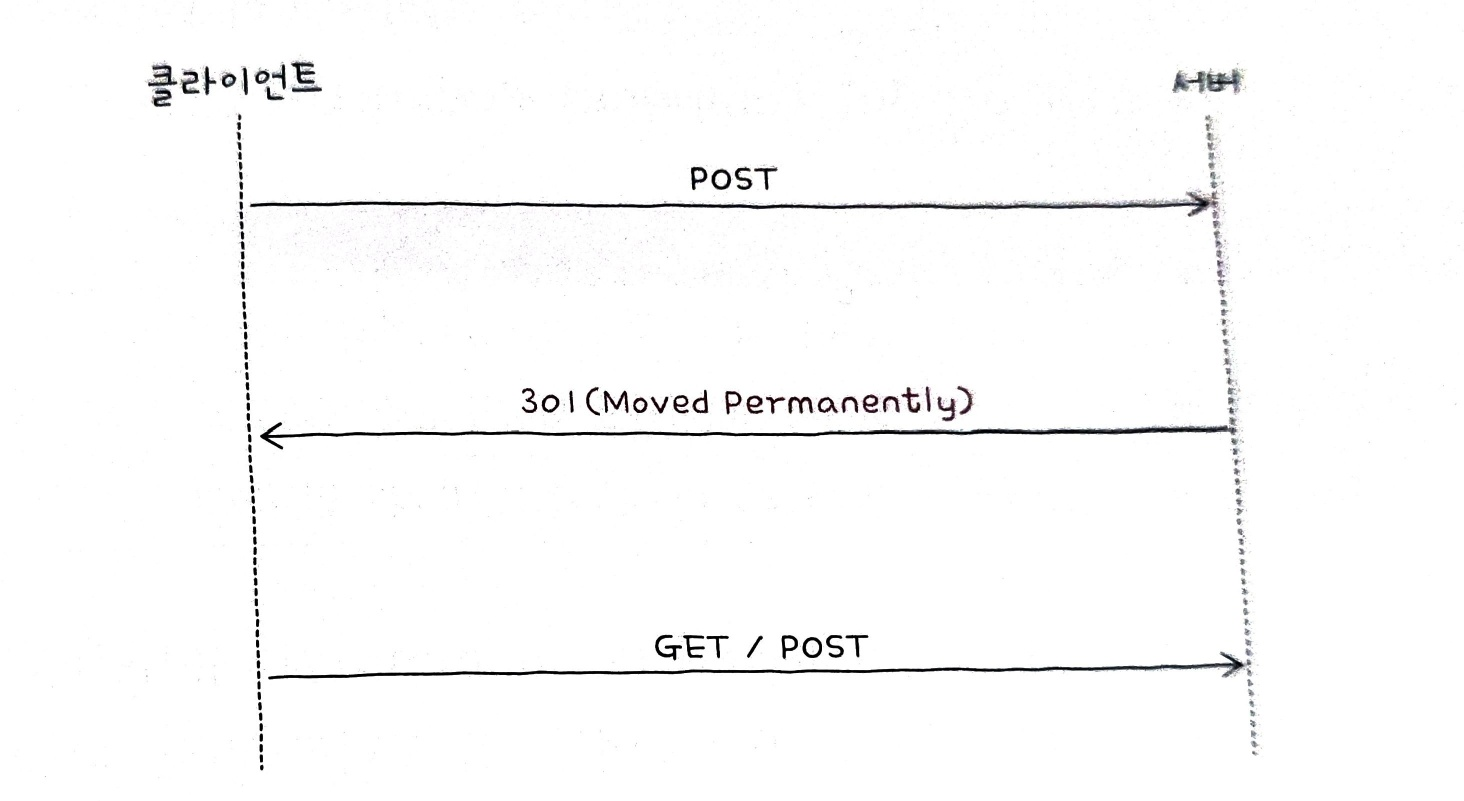
만약 클라이언트가 첫 번째 요청으로 POST 메서드를 보내고 상태 코드 308을 받았다면,
두 번째 요청에서도 POST 메서드를 유지하게 된다.
일시적인 리다이렉션(temporary redirection)
자원의 위치가 임시로 변경되었거나 임시로 사용할 URL이 필요한 경우에 주로 사용된다.
일시적인 리다이렉션과 관련한 상태 코드는 302, 303, 307이 있다.

302와 307은 앞에서 살펴본 것과 똑같이 동작한다.
303(See Other) 은, 첫 번째 요청의 메서드가 무엇이든지 간에, 두 번째 요청 메서드를 GET으로 하도록 강제한다.
400번대: 클라이언트 상태 에러 코드
400 번대 상태 코드는 클라이언트에 의한 에러가 있음 을 알려주는 상태 코드다.
서버가 처리할 수 없는 형태로 요청을 보냈거나, 존재하지 않는 자원에 대해 요청을 보내는 경우가 이에 해당한다.
400번대 상태 코드의 대표 유형은 다음과 같다.

400(Bad Request)
클라이언트의 요청이 잘못되었음을 알려주는 상태 코드다.
클라이언트의 요청 메시지의 내용이나 형식 자체에 문제가 있어, 서버가 요청 메시지를 올바르게 처리할 수 없는 경우가 이에 해당한다.
401(Unauthorized)
웹상에서 정보를 검색할 때, 모든 자원에 접근이 가능한 것은 아니다.
특정 자원에 접근하기 위해 인증이 필요할 때가 있는데, 요청에 대한 인증이 필요할 경우 서버는 401 상태 코드를 응답할 수 있다.
서버는 반드시 WWW-Authenticate 라는 헤더를 통해 인증 방법을 알려주어야 하는데, 이는 아래서 살펴보겠다.
403(Forbidden)
클라이언트의 권한이 충분하지 않다면 상태코드 403을 응답한다.
즉, 자원에 접근할 권한이 없음 을 의미한다.
404(Not Found)
접근하고자 하는 자원이 존재하지 않음을 알리는 상태 코드이다.
존재하더라도 공개하지 않는 자원에 대해 404를 응답하는 경우가 있다.
405(Method Not Allowed)
일부 메서드는 구현되어 있지 않을 수 있는데, 구현되지 않은 메서드로 요청을 보낸다면 405를 통해 해당 메서드의 미지원을 알린다.
500번대: 서버 에러 상태 코드

500번대 상태 코드 원인은 서버다.
클라이언트가 올바르게 요청을 보냈을 지라도 발생할 수 있는 서버 에러에 대한 상태 코드이다.
500(Internal Server Error)
서버의 예기치 못한 상황으로 인해 요청을 처리할 수 없음 이라는 의미이다.
다소 포괄적이기 때문에, 서버 내 에러를 통칭하기도 한다.
502(Bad Gateway)
클라이언트와 서버 사이에 위치한 중간 서버의 통신 오류를 나타내는 상태 코드다.
클라이언트와 서버 사이에 위치한 중간 서버가 유효하지 않거나 잘못된 응답을 받는다면 502를 응답한다.
503(Service Unavailable)
현재 서비스를 일시적으로 이용할 수 없음 을 의미한다.
서버가 과부하 상태에 있거나 일시적인 점검 상태일 때 볼 수 있다.
HTTP 헤더와 HTTP 기반 기술
HTTP 메시지의 두 번째 줄인 필드 라인에 대해 배워보자.
HTTP 헤더
HTTP 헤더는 필드 이름(헤더 이름):필드 값(헤더 값) 의 형식으로 이루어져 있다.
HTTP 요청시 자주 사용되는 헤더, HTTP 응답 시 주로 사용되는 헤더, HTTP 요청과 응답 모두에서 자주 활용되는 헤더 순으로 살펴보자.
요청 시 활용되는 HTTP 헤더
Host User-Agent Referer Authorization 에 대해 알아보자.
Host

Host는 요청을 보낼 대상 호스트를 나타내는 헤더이다.
주로 도메인 네임 으로 명시되며, 포트 번호가 포함될 수 있다.
User-Agent

유저 에이전트 란 웹 브라우저와 같이 HTTP 요청을 시작하는 클라이언트 측의 프로그램을 의미한다.
서버 입장에서는 이 헤더를 통해 클라이언트의 접속 환경을 유추할 수 있다.
Referer
클라이언트가 요청을 보낼 때 머무르고 있던 URL이 명시된다.
영문법적으로는 Referrer이 맞지만, 초기 개발 당시 오타로 인해 Referer 이라는 표기가 오늘날까지 사용되고 있다고 한다.
클라이언트의 유입 경로를 확인하는데 용이하다.
GET /page2.html HTTP/1.1
Host: www.example.com
Referer: https://www.google.com/search?q=example위 예시에서 서버는 사용자가 구글에서 검색 후 들어왔다는 것을 알 수 있다.
Authorization
클라이언트의 인증 정보를 담는 헤더이다.
다음 처럼 인증 타입(type) 과 인증을 위한 정보(credentials) 가 차례로 명시된다.
Authorization : <type> <credentials>
인증 타입 종류는 다양하지만, 가장 기본적인 HTTP 인증 타입은 Basic이라는 타입이다.
Basic 타입 인증은 username:password 와 같이 사용자 아이디와 비밀번호를 콜론을 이용해 합친 뒤, 이를 Base64 인코딩한 값을 인증 정보로 삼는 방식이다.
Authorization: Basic dXNlcm5hbWU6cGFzc3dvcmQ=위 예시에서
Basic = 인증 타입 이고,
dXNlcm5hbWU6cGFzc3dvcmQ= 은 username:password를 Base64 인코딩한 값이다.
응답 시 활용되는 HTTP 헤더
HTTP 응답 시 활용되는 대표적인 헤더인 Server Allow Retry-After Location WWW-Authenticate 헤더에 대해 알아보자.
Server
Server 헤더는 요청을 처리하는 서버 측의 소프트 웨어와 관련된 정보를 명시한다.
예를 들어 다음 예시 헤더는 Unix 운영체제에서 동작하는 아파치 HTTP 서버 를 의미한다.
Server : Apache/2.4.1 (Unix)
Allow
Allow 헤더는 클라이언트에게 허용된 HTTP 메서드 목록을 알려주기 위해 사용된다.
앞선 절에서 배웠던 405(Method Not Allowed) 상태 코드를 응답하는 메시지에서 Allow 헤더가 함께 사용된다.
다음 예시를 살펴보면 이해가 쉽다.
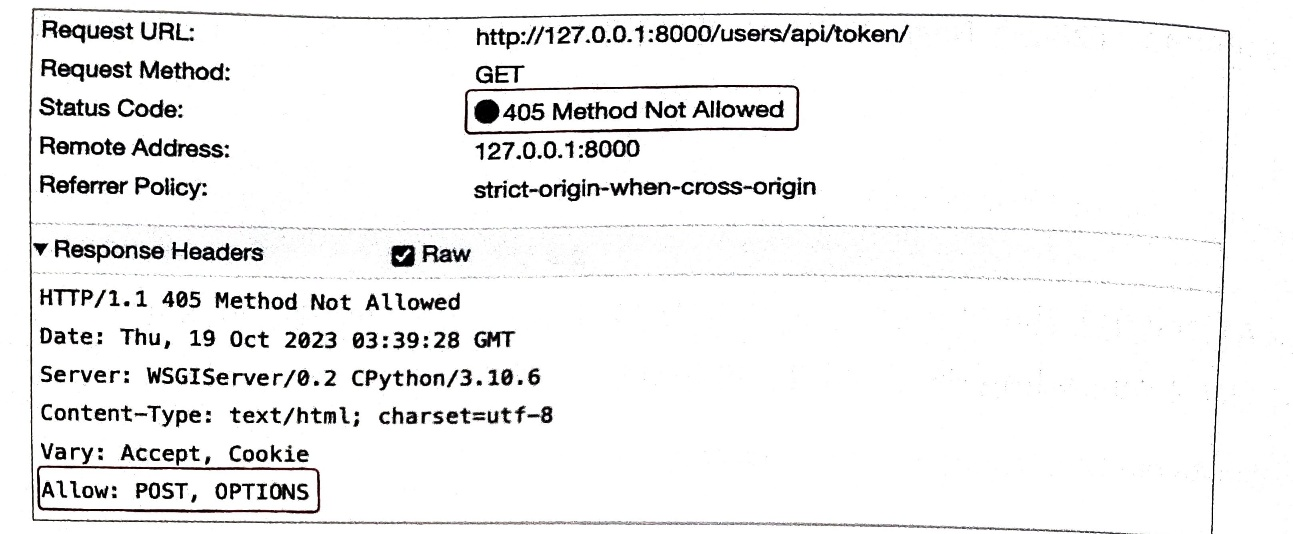
서버에서 GET 요청을 받았는데, POST 와 OPTIONS 메서드만 사용가능하다고 클라이언트에게 알려주는 사진이다.
Retry-After
앞선 절에서 배웠던 503(Service Unavailable) 상태 코드는 현재는 요청을 처리할 수 없으나 추후 가능할 수도 있음 을 의미했다.
이 응답과 함께 사용될 수 있는 헤더가 Retry-After 헤더이다.
다음 예시는 각각 2024년 8월 23일 금요일 09시 이후에 사용 가능하다 라는 사실
120 초 이후에 사용 가능하다 라는 사실을 나타내는 헤더이다.
각각 다른 예시이고, 동시에 여러 헤더를 사용한 예시가 아님에 유의하자.

Location
Location은 이전 절에 언급했던 대로, 클라이언트에게 자원의 위치를 알려주기 위해 사용되는 헤더이다.
주로 리다이렉션이 발생했거나 새로운 자원이 생성되었을 때 사용된다.
HTTP/1.1 301 Moved Permanently
Location: https://www.example.com/new-page위 예시를 살펴보자.
301(Moved Permanently) 를 통해 재요청 메서드가 변경될 수 있는 영구적인 리다이렉션을 명시하고 있다.
이 때, 브라우저는 Location 에 명시된 주소로 자동으로 이동하고 새로운 자원을 받아오게 된다.
그러니까 실제 사용자 경험 관점에서 대부분의 경우 리다이렉션이 발생한 줄 모른다고 한다.(알아서 Location 주소의 자원을 받아오므로)
HTTP/1.1 201 Created
Location: https://www.example.com/resources/123다음처럼 새 리소스를 생성하고, 해당 리소스가 어느 URL로 접근 가능한지에 대해 명시할 때도 사용할 수 있다.
WWW-Authenticate
상태코드 401(Unauthorized)는 요청한 자원에 대한 유효한 인증이 없을 때 응답하는 코드다.
상태코드 401과 함께 사용되는 헤더가 WWW-Authenticate 이다.
이 헤더는 자원에 접근하기 위한 인증 방식을 설명하는 헤더이다.
이를테면 다음과같이 Basic 인증을 요구할 수 있다.
WWW-Authenticate: Basic
다만 실제로는 이보다 조금 더 많은 정보를 알려주는 경우가 많다.
예를 들어 다음과 같이 보안 영역(realm)을 함께 알려주건, 인증에 사용될 문자집합도 알려줄 수 있다.
WWW-Authenticate: Basic realm="Access to engineering site", charset="UTF-8"
realm 이란 보안이 적용될 영역을 의미한다. 같은 서버가 제공하는 자원일지라도, Engineering site 라는 영역에 속한 자원에 접근 가능한 사용자는 Financial site 라는 영역에 속한 자원에 접근이 불가할 수 있다.
요청과 응답 모두에서 활용되는 HTTP 헤더
Date
메시지가 생성된 날짜와 시각에 관련된 정보를 담은 헤더이다.
Date: Tue, 15 Nov 1994 08:12:31 GMT
Connection
클라이언트의 요청과 응답 간의 연결 방식을 설정하는 헤더이다.
Connection: keep-alive 헤더를 통해 상대방에게 지속 연결을 희망함을 알릴 수도,
Connection: close 헤더를 통해 서버나 클라이언트가 연결을 종료하고 싶음을 알릴 수도 있다.
만약 요청1->요청2->요청3 이 연달아 발생하는 상황이라고 해보자.
그럼 요청1 과 요청2 에는 keep-alive 를 명시해서 TCP 연결을 재사용해 핸드셰이크 비용을 줄일 수 있음이 명확하다.
그렇다면 요청3 은 close 를 해야할까 keep-alive 를 해야할까?
요청3 이 끝난 이후, 사용자의 행동을 알 수 있다면 명확해지겠지만, 사용자가 어떤 행동을 취할지 모르는 상황이라고 가정했을 때, 결정하기가 쉽지 않을 것이다.
그래서 keep-alive 를 사용하되, timeout 을 짧게 설정해서 잠시동안 TCP 연결을 재사용할 수 있는 환경을 만들어주기도 한다고 한다.
Content-length
본문의 바이트 단위 크기(길이) 를 나타낸다.
Content-length: 100
일반적으로 자동으로 본문 길이를 계산해서 보내주기 때문에 따로 명시할 필요는 없다.
서버가 요청 본문의 끝을 정확히 알 수 있도록 해서 내부적으로 서버가 언제 데이터 수신을 멈춰야 할지 알 수 있다고 한다.
그런데, 스트리밍 서비스나 압축된 데이터처럼 데이터가 동적으로 생성되거나 크기가 너무 클 경우에는 크기를 미리 알 수 없을 수 있다고 한다.
이럴 때는 Transfer-Encoding: chunked 를 사용해 데이터를 청크 단위로 나누어 보내고, 서버는 각 청크의 크기를 표시하되 마지막 청크를 보낼 때 0 으로 표시하여 데이터 전송이 끝났음을 알려준다고 한다.
Content-Type, Content-Language, Content-Encoding
이 헤더들은 전송하려는 메시지 본문의 표현 방식을 설정하는 헤더이다.
이런 점에서 이 헤더들은 표현 헤더 의 일종이라고도 부른다.
Content-Type 헤더는 메시지 본문에서 사용된 미디어 타입을 담고 있다.
예를 들어 다음 헤더는 메시지 본문이 HTML 문서 형식이며, 문자 인코딩으로 UTF-8을 사용한다는 정보를 알려준다.
Content-Type: text/html; charset=UTF-8
Content-Language 헤더는 메시지 본문에 사용된 자연어를 명시한다.
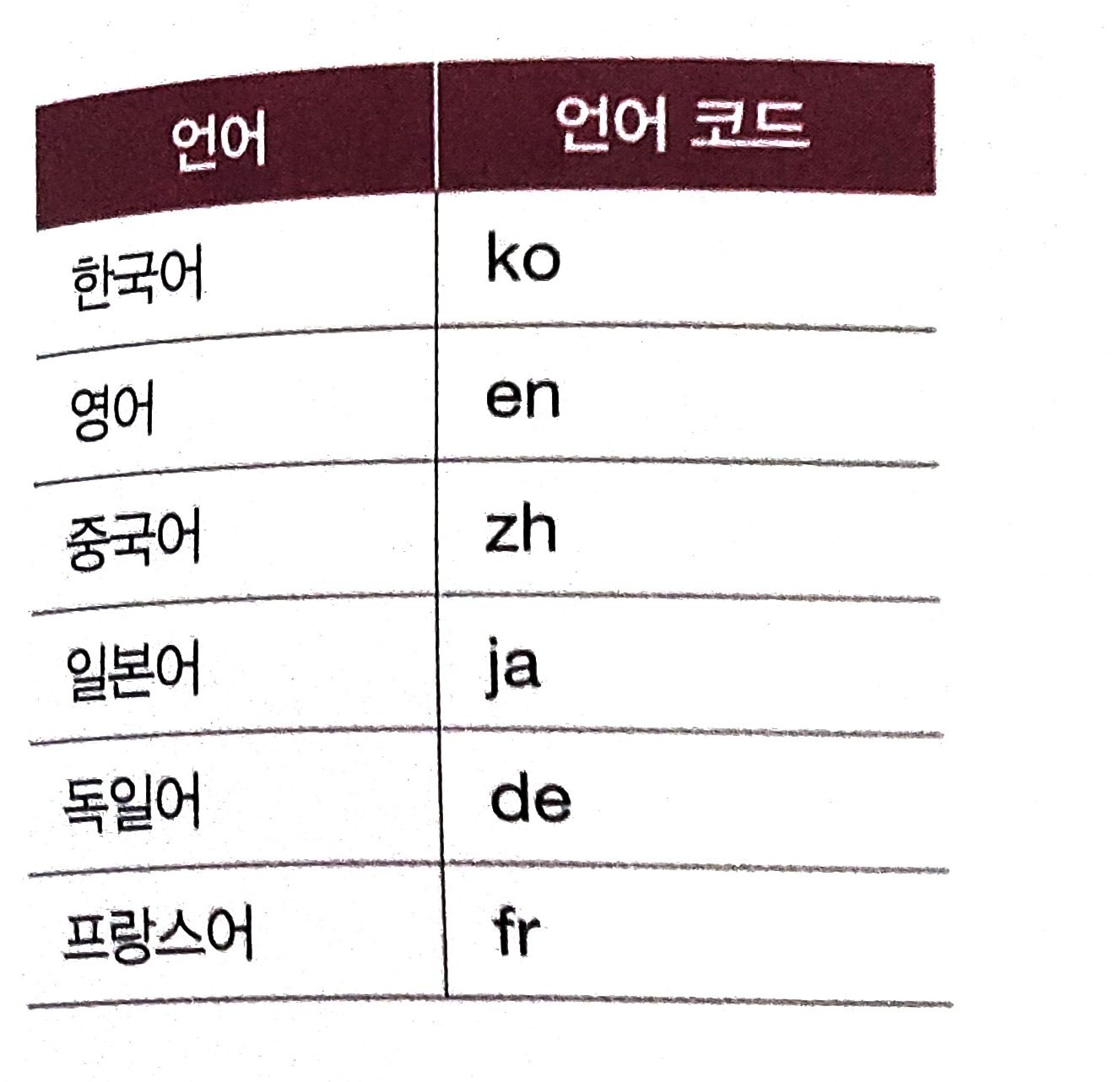
해당 헤더 값은 언어 태그로 명시되며, 언어 태그는 하이픈(-)으로 구분된 다음과 같은 구조를 따른다.

일반적으로는 첫 번째 서브 태그(en, ko)나 두 번째 서브 태그(en-US, ko-KR)까지만 사용된다.
주로 사용되는 언어 코드와 국가 코드는 다음과 같다.

Content-Encoding 헤더에는 메시지 본문을 압축하거나 변환한 방식이 명시된다.
HTTP를 통해 송수신되는 데이터는 전송 속도를 개선하기 위해 종종 압축이나 변환이 되고는 하는데, 이때 사용된 방식이 명시된다.
명시될 수 있는 대표적인 값은 gzip compress deflate br 등이 있다.
캐시
캐시란 불필요한 대역폭 낭비와 응답 지연을 방지하기 위해 정보의 사본을 임시로 저장하는 기술이다.
사본을 임시로 저장해두면 동일한 요청에 대해 캐시된 데이터를 활용할 수 있기에 불필요한 대역폭 낭비를 줄이고 빠르게 데이터에 접근할 수 있다.
만약, 클라이언트가 이미지를 조회하기 위해 서버를 향해 GET 요청을 보내고, 같은 이미지를 두 번 세 번 요청하는 상황에 캐시를 이용하면 좋다.
웹 브라우저에 저장된 캐시를 개인 전용 캐시(private cache),
클라이언트와 서버 사이에 저장된 캐시를 공용 캐시(public cache) 라고 부른다.
개인 전용 캐시에 초점을 맞춰 살펴볼 것이다.
캐시가 사본을 저장한다고 했는데, 그렇다면 캐시된 데이터가 최신 상태를 유지하고 있는지를 어떻게 알 수 있을까?
최신 원본 데이터와 얼마나 유사한지를 캐시 신선도(cache freshness)라고 표현하기도 하는데, 이 캐시 신선도를 유지하는 가장 기본적인 방법은 캐시된 데이터에 유효 기간을 설정하는 방법 이다.
캐시 데이터에 유효 기간을 설정하고, 기간이 만료되었다면 원본 데이터를 다시 요청하는 방식으로 캐시 신선도를 유지할 수 있다.
캐시할 데이터에 유효 기간을 부여하는 방법으로 응답 메시지의 Expires 헤더(날짜) 와 Cache-Control 헤더의 Max-Age 값 (초)을 사용할 수 있다.
아래 두 그림을 보면 이해가 쉽다.


캐시된 자원이 만료되었더라도, 캐시된 자원이 여전히 최신 정보라면 클라이언트는 굳이 서버로부터 같은 자원을 응답받을 필요가 없다.
따라서 캐시의 유효 기간이 만료되었다면 클라이언트는 캐시된 자원이 여전히 신선한지를 재검사해야 할 필요가 있다.
이 재검사 방법에는 날짜를 기반으로 서버에게 물어보는 방법 과 엔티티 태그를 기반으로 서버에게 물어보는 방법 이 있다.
날짜 기반 재검사 방법
클라이언트는 If-Modified-Since 헤더를 통해 서버에게 특정 시점 이후로 원본 데이터에 변경 이 있는지 물어볼 수 있다.
이 시점 이후로 원본에 변경이 있었다면, 그때만 새 자원으로 응답하도록 서버에게 요청하는 헤더이다.
다음 예시를 통해 이해해보자.
해당 요청 메시지는 2024년 8월 23일 금요일 09:00:00 이후에 www.example.com/index.html 의 자원이 변경되었니? 변경이 되었을 경우에만 새 자원으로 응답해 줘 라는 요청 메시지와 같다.

자, 이제 서버 입장에서 해당 헤더를 받았다고 가정하고 생각해보자.
서버의 자원은 크게 셋 중 하나의 상황을 따르게 된다.
- 요청받은 자원이 변경되었음
- 요청받은 자원이 변경되지 않았음
- 요청받은 자원이 삭제되었음
요청받은 자원이 변경된 상황

서버는 상태 코드 200(OK)와 함께 새로운 자원을 반환한다.
요청받은 자원이 변경되지 않은 상황

서버는 상태 코드 304(Not Modified)를 통해 클라이언트에게 자원이 변경되지 않았음을 알린다.
서버는 자원의 변경 여부 뿐만 아니라, 마지막 변경 시점도 알려줄 수 있는데, 이를 위한 헤더로 Last Modified 가 있다.
이 헤더는 특정 자원이 마지막으로 수정된 시점을 나타낸다.
요청 받은 자원이 삭제된 상황

서버는 상태코드 404(Not Found)를 통해 요청한 자원이 존재하지 않음을 알린다.
엔티티 태그 기반 재검사 방법
엔티티 태그(Etag)는 자원의 버전 을 식별하기 위한 정보이다.
여기서 버전 이란 유의미한 변경 사항 을 의미한다.
즉, 자원이 변경될 때마다 자원의 버전을 식별하는 Etag 값이 변경된다.
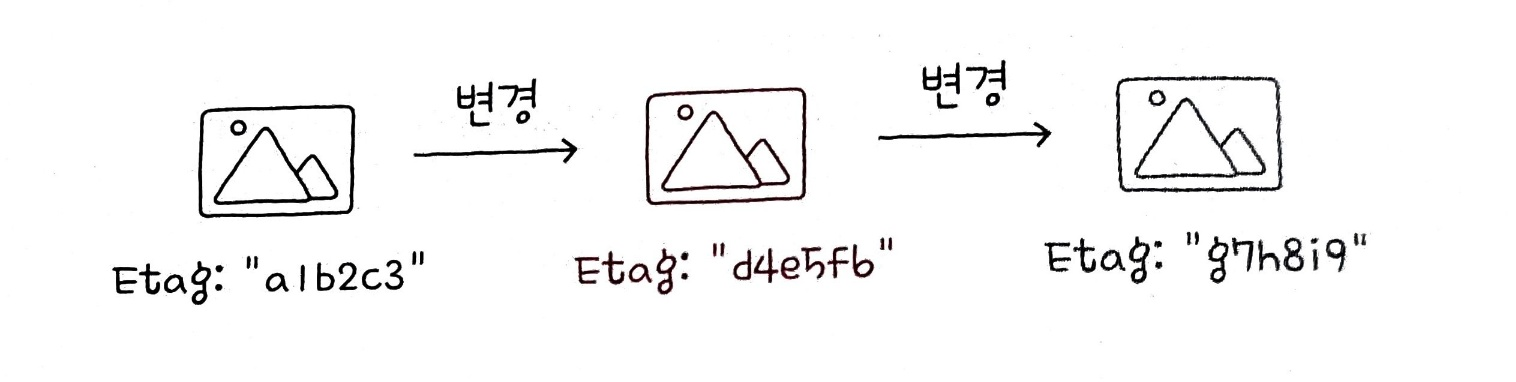
클라이언트는 캐시 신선도를 검사하기 위해 이 Etag 값과 일치하는 값이 있니? 와 같이 물어볼 수 있다.
이를 위해 사용하는 헤더가 바로 If-None-Match 이다.
예를 들어, 다음의 요청 메시지는 혹시 Etag 값이 abc인 www.example.com/index.html 이라는 자원이 있니? 해당 자원이 변경되었다면(Etag 값이 변경되었다면) 그때만 새 자원으로 응답해줘 라는 요청 메시지와 같다.

이 때도 서버의 자원은 다음과 같은 상황 중 하나를 따른다.
- 요청받은 자원이 변경되었음
- 요청받은 자원이 변경되지 않았음
- 요청받은 자원이 삭제되었음
이에 대한 동작은 날짜 기반 재검사와 동일하다.
쿠키
HTTP는 기본적으로 상태를 유지하지 않는 스테이트리스 프로토콜이다.
만약 그렇다면, 다음과 같은 기능은 어떻게 구현되는 것일까?
위 기능은 클라이언트의 상태를 알고 있어야만 구현할 수 있는 기능일텐데 말이다.
HTTP 쿠키(이하 쿠키)를 통해 이러한 기능을 구현할 수 있다.
쿠키(cookie)란 서버에서 생성되어 클라이언트 측에 저장되는 데이터로, 상태를 유지하지 않는 HTTP의 특성을 보완하기 위한 수단이다.
서버가 클라이언트의 상태를 알 수 있게끔 하는 특별한 데이터이다.
쿠키는 개발자도구 -> 애플리케이션 -> 저장 용량 -> 쿠키 에서 확인할 수 있다.
쿠키를 이루는 정보는 기본적으로 <이름, 값> 쌍의 형태를 띠고 있고, 추가로 적용 범위와 만료 기간 등 다양한 속성을 가질 수 있다.
서버는 쿠키를 생성하여 클라이언트에게 전송하고, 클라이언트는 전달받은 쿠키를 저장해 두었다가 추후 동일한 서버에 보내는 요청 메시지에 쿠키를 포함하여 전송한다.
서버는 쿠키 정보를 참고해 두 개의 요청이 같은 클라이언트에서 왔는지, 로그인 상태를 유지하고 있는지 등을 알 수 있다.
서버가 생성하는 쿠키는 응답 메시지의 Set-Cookie 헤더를,
클라이언트가 서버로부터 전달받은 쿠키를 활용할 때는 요청 메시지의 Cookie 헤더를 통해 전달된다.
응답 메시지

응답 메시지의 Set-Cookie 헤더를 통해 쿠키의 이름, 값과 더불어 세미콜론(;) 으로 구분되는 속성들을 전달할 수 있다.
쿠키 관련 정보로 이름 값 뿐만 아니라, 도메인 과 경로가 있다.
domain
www.naver.com 에서 받은 쿠키를 전혀 다른 웹사이트인 www.google.com 에 전송하면 안되기에, 쿠키는 사용 가능한 도메인이 정해져 있다.
이는 응답 메시지 속 Set-Cookie 헤더의 domain 속성으로 정해진다.
path
또한 같은 도메인이라도 경로별로 쿠키를 구분하여 사용하고 싶을 때가 있다.
특정 도메인의 특정 하위 경로에서만 사용하고자 하는 쿠키가 있을 수 있기에, 이 때는 Set-Cookie 헤더의 path 속성으로 지정할 수 있다.
그러면, path로 지정된 경로와 그 앞부분이 일치하는 경로(하위 경로) 에서 해당 쿠키 정보를 활용할 수 있게 된다.
Expires / Max-Age
Expires 속성에는 [요일, DD-MM-YY HH:MM:SS GMT] 형식으로 표기되는 쿠키 만료 시점이,
Max-Age 속성에는 초 단위 유효 기간이 전달 될 수 있다.
해당 유효기간이 지나면, 해당 쿠키는 삭제되어 전달되지 않는다.
요청 메시지

요청 메시지의 Cookie 헤더 값은 서버에 전달할 쿠키의 이름과 값을 나타내는 헤더이다.
여러 개의 쿠키 값을 전달해야 한다면, 세미 콜론을 이용한다.
쿠키의 한계
쿠키의 대표적인 한계는 바로 보안 이다.
쿠키에 개인 정보를 비롯해 보안에 민감한 정보를 담아 송수신하고 저장하는 것은 바람직하지 못하다.
쿠키 정보가 쉽게 노출되거나 조작될 수 있기 때문이다.
이를 보완하기 위한 속성으로 Secure 와 HttpOnly 라는 속성이 있다.
Secure
나중에 학습하겠지만, 간단하게 알아보겠다.
HTTPS 프로토콜이 사용되는 경우에만 쿠키를 전송하도록 하는 속성이다.
HTTPS 프로토콜은 HTTP를 더 안전한 방식으로 전송할 수 있는 프로토콜이다.
HttpOnly
HTTP 송수신을 통해서만 쿠키를 이용하도록 제한하는 속성이다.
쿠키는 JS를 통해서도 접근이 가능한데, 악의적 의도를 가진 해커는 (정상적인 HTTP 송수신을 통해서가 아닌) JS로 쿠키를 중간에 가로채거나 위변조할 수 있다.
HttpOnly는 이런 상황을 방지하기 위해 자바스크립트에서 쿠키에 접근하지 못하도록 하는 속성이다.
콘텐츠 협상과 표현
한국에서 접속하거나 한국어 계정으로 특정 URL에 접속하면 한국어로 된 웹 페이지를 볼 수 있고,
해외로 나가서 웹 페이지를 접속하면 해당 국가의 웹 페이지를 볼 수 있는 상황을 경험해 본 적 있을 것이다.
분명 같은 자원을 요청했는데, 어떻게 다른 결과를 얻는걸까?
이는 HTTP의 콘텐츠 협상(content negotiation)을 통해 이루어진다.
콘텐츠 협상 이라나 같은 URI에 대해 가장 적합한 자원의 형태를 제공하는 메커니즘을 의미한다.
이 때, 송수신 가능한 자원의 형태 를 자원의 표현(representation) 이라고 한다.
클라이언트가 선호하는 표현을 반영하고자 콘텐츠 관련 협상 HTTP 헤더들이 사용된다.
선호하는 미디어 타입을 나타내기 위한 Accept,
선호하는 언어를 나타내기 위한Accept-Language,
선호하는 문자 인코딩과 압축 방식을 나타내기 위한 Accept-Charset Accept-Encoding 이 있다.
클라이언트가 선호하는 언어가 한국어일 경우, Accept-Language: ko 를 헤더에 추가하여 서버에 요청하면, 서버는 클라이언트가 선호하는 언어를 인식하여 한국어로 표현된 자원을 보내주게 되는 것이다.
콘텐츠 협상의 우선 순위
콘텐츠 협상에서 중요한 점은 선호도에 우선 순위 를 반영할 수 있다는 점이다.
예를 들어, 한국어를 가장 선호하지만, 영어도 받을 용의가 있다 와 같이 표현이 가능하다.
이러한 우선 순위는 콘텐츠 협상 관련 헤더의 q 값으로 표현된다.
q는 Quality Value 의 약자로, 특정 표현을 얼마나 선호하는지를 나타낸다.
생략 되었을 경우에는 1을 의미하고, 범위는 0부터 1까지이며, 값이 클수록 우선순위가 높다.
다음 예시를 보면, 한국어, 영어 순으로 선호하고, HTML, XML, 일반 텍스트순으로 선호한다는 것을 알 수 있다.

DNS가 뭔가요?
DNS는 도메인 네임을 IP 주소로 변환해주는 애플리케이션 계층 프로토콜이자, 계층적이고 분산된 도메인 네임에 대한 관리체계입니다.
DNS 작동 방식에 대해 설명해주세요.
사용자가 웹 브라우저에 도메인 이름을 입력하면, 브라우저는 먼저 로컬 캐시에서 해당 도메인의 IP 주소를 확인하려 시도합니다.
만약 로컬 캐시에 없으면, 브라우저는 DNS 서버에 요청을 보냅니다. DNS 서버는 해당 도메인 이름에 대한 IP 주소를 찾아서 브라우저에 반환합니다.
이 과정에서 DNS 서버는 루트 네임 서버, TLD 네임 서버, 책임 네임 서버로 나뉜 여러 계층을 거쳐 IP 주소를 찾을 수 있습니다.
이후 브라우저는 받은 IP 주소를 사용하여 실제 웹 서버에 HTTP 요청을 보냅니다.
이로써 웹 페이지가 로드됩니다.
DNS 질의 종류에 대해 설명해주세요.
DNS 질의에는 재귀적 질의와 반복적 질의가 있습니다.
재귀적 질의는 클라이언트가 로컬 네임서버에게 도메인 네임을 질의하면, 로컬 네임 서버는 루트 네임 서버에게, 루트 네임 서버는 TLD 네임 서버에게, TLD 네임 서버는 다음 단계에 질의하는 과정을 반복하며, 최종 응답을 역순으로 전달받는, 즉 재귀적으로 질의가 이루어지는 방식입니다.
반복적 질의는 클라이언트가 로컬 네임서버에게 도메인 네임을 질의하면, 로컬 네임 서버는 루트 도메인에게 질의해서 다음으로 질의할 네임 서버의 주소를 응답 받고, 이렇게 다음으로 질의할 네임 서버의 주소를 응답받는 과정을 반복하다가 최종 응답 결과를 클라이언트에게 알려주는 방식입니다.
DNS 서버에게 IP 주소를 요청할 때, 왜 UDP를 사용하나요?
DNS는 신뢰성보다 속도가 더 중요한 서비스이기 때문에 연결 설정 비용이 없는 UDP를 사용합니다.
따라서 연결 지향적인 TCP보다 빠르고 효율적인 UDP를 사용하는 것이 유리합니다.
DNS 레코드가 무엇인가요?
DNS 서버는 데이터베이스 서버의 한 유형이며, 클라이언트로부터 질의를 받았을 때 그에 맞는 데이터를 응답해야 합니다. 데이터베이스의 한 항목(row)을 DNS 서버에서는 리소스 레코드라고 부릅니다.
예를들어 A 레코드는 도메인 이름을 IPv4 주소로 매핑하는 데 사용됩니다.
HTTP 프로토콜에 대해서 설명해주세요.
HTTP는 웹에서 클라이언트와 서버 간에 정보를 주고받기 위한 프로토콜입니다.
클라이언트는 HTTP 메서드를 사용해 요청을 보내고, 서버는 HTTP 상태 코드로 응답합니다.
HTTP는 비연결성 프로토콜로, 요청과 응답 간에 상태를 유지하지 않으며, GET, POST, PUT, DELETE 등의 메서드를 사용하여 데이터를 처리합니다.
HTTP의 요청/응답 모델에 대해 설명해주세요.
HTTP의 요청/응답 모델은 클라이언트가 서버에 요청을 보내면, 서버가 이에 대한 응답을 반환하는 방식입니다.
클라이언트는 GET, POST 등의 HTTP 메서드와 함께 요청을 보내고, 서버는 요청에 대한 처리 결과를 HTTP 상태 코드와 함께 응답합니다.
이 모델은 비연결성이므로, 요청과 응답 간에 상태를 유지하지 않습니다.
HTTP 메서드중 GET과 POST의 차이점에 대해 설명해주세요.
GET 메서드는 클라이언트가 서버에게 데이터를 요청할 때 사용합니다. 이때 요청은 URL에 포함된 쿼리 파라미터를 통해 데이터를 전달합니다. 서버는 요청에 대한 응답으로 데이터를 클라이언트에게 전달합니다.
POST 메서드는 클라이언트가 서버에 데이터를 보낼 때 사용합니다. 주로 폼 데이터를 전송할 때 사용하며, 서버는 데이터를 받아 처리하고, 보통 저장하거나 처리한 결과를 응답합니다.
HTTP 메서드중 PUT과 PATCH의 차이점에 대해 설명해주세요.
PUT 메서드는 리소스를 덮어쓰거나 새로 생성할 때 사용합니다. 주로 요청 본문에 포함된 데이터로 해당 리소스를 덮어쓰는 방식으로 작동합니다. 만약 리소스가 없으면 새로 생성하기도 합니다.
PATCH 메서드는 리소스의 일부만 수정할 때 사용합니다.
전체 리소스를 덮어쓰지 않고, 요청 본문에 포함된 일부 데이터만 수정합니다.
HTTP 상태 코드가 뭔가요? 알고 있는 상태 코드 몇가지 설명해주세요
HTTP 상태 코드는 서버가 클라이언트의 요청을 처리한 후 그 결과를 나타내는 코드입니다.
상태 코드는 3자리 숫자로 이루어져 있으며, 첫 번째 숫자는 응답의 범주를 나타냅니다.
예를 들어, 상태 코드 200은 요청이 성공적으로 처리되었음을 의미하고, 상태 코드 404는 요청한 자원을 찾을 수 없음을 의미하고, 상태코드 500은 서버의 예기치 못한 상황으로 요청을 처리할 수 없음을 의미합니다.
HTTP 헤더가 뭘까요? 알고 있는 헤더 몇 가지 설명해주세요.
HTTP 헤더는 클라이언트와 서버 간에 전송되는 추가적인 메타데이터입니다.
예를 들어, Content-Type 헤더는 요청이나 응답 본문의 데이터 형식을 명시합니다.
Authorization 헤더는 클라이언트의 인증 정보를 포함합니다.
User-Agent 헤더는 클라이언트의 브라우저나 운영체제에 대한 정보를 포함합니다.
HTTP의 무상태성(Stateless)에 대해서 설명해주세요.
HTTP의 무상태성이란, 서버가 HTTP 요청을 보낸 클라이언트와 관련된 상태를 기억하지 않는다는 의미입니다.
즉, 각 요청은 기본적으로 독립적인 요청으로 간주됩니다.
무상태성 덕분에 언제든 쉽게 서버를 추가할 수 있어 확장성이 높아지고 서버 장애시 쉽게 다른 서버로 대체가 가능해 견고성이 높아집니다.
HTTP Keep-Alive에 대해서 설명해주세요.
HTTP Keep-Alive는 HTTP 요청과 응답 간에 TCP 연결을 유지하는 기능입니다.
이를 통해 여러 요청과 응답을 하나의 연결로 처리할 수 있어, 매번 새로운 연결을 설정할 필요가 없고, 그로 인해 웹 응답 속도가 빨라집니다.
HTTP 파이프라이닝에 대해서 설명해주세요.
HTTP 파이프라이닝은 요청에 대한 응답을 기다리지 않고 여러 개의 요청을 한 번에 보내는 기법입니다.
응답을 기다리지 않기 때문에 서버와 클라이언트 간의 대기 시간을 줄여서 성능을 향상시킬 수 있습니다.
HTTP/1.1, HTTP/2, HTTP/3 각각의 특징에 대해 설명해주세요.
HTTP/1.1은 전통적인 HTTP 프로토콜로, 각 요청마다 독립적인 TCP 연결을 사용합니다.
이로 인해 여러 요청을 처리할 때 대기 시간이 발생할 수 있습니다.
HTTP/2는 성능 향상을 위해 여러 요청을 하나의 연결로 처리할 수 있는 다중화 기능을 제공합니다.
이로 인해 여러 요청을 병렬로 처리할 수 있어 대기 시간이 줄어듭니다.
HTTP/3는 QUIC(Quick UDP Internet Connections) 프로토콜을 기반으로 한 HTTP 버전으로, TCP 대신 UDP를 사용합니다.
이로 인해 연결 설정 시간이 단축되고, 패킷 손실에 대한 회복력이 향상되어 더 빠르고 안정적인 통신을 제공합니다.
쿠키와 세션에 대해서 설명해주세요.
쿠키는 HTTP 서버가 클라이언트를 식별할 수 있도록 하기 위해서 사용됩니다.
클라이언트가 웹 서버에 처음 접속하면, 서버는 쿠키를 생성해 클라이언트에게 전달합니다.
이후 클라이언트는 서버에 요청을 보낼 때 쿠키를 함께 전송하며, 서버는 이를 통해 클라이언트를 식별합니다.
쿠키는 클라이언트 측에 저장되기 때문에, 유출될 위험이 있을 수 있습니다.
그리고 세션은 쿠키와 유사하지만 서버 측에서 클라이언트의 정보를 저장한다는 점에서 차이가 있습니다.
