
개요
채팅방에 접속했을 때 채팅 이력을 조회한다.
이때 데이터가 쌓이면 쌓일수록 DB 부하가 일어날 것이라고 판단했다.
10만개의 채팅 이력이 쌓였다면 FULL SCAN으로 DB에서 데이터를 모두 조회해서 반환하는 것은 상당한 부하가 갈 것이다.
그렇기에 우선적으로 페이지네이션을 적용하고 캐싱 적용을 고려해보면서 부하테스트를 하기로 했다.
더미데이터 삽입
mongosh를 통해서 아래의 더미데이터를 삽입했다.
const targetRoomId = 2;
const totalMessages = 10000;
// 채팅방에 참여하는 두 사용자의 정보
const userA = {
id: "8fe4708b-4c4d-404d-92aa-614ecbe705cd",
name: "사용자A"
};
const userB = {
id: "fd208f4e-a8da-48f5-b4a5-e1db91337802",
name: "사용자B"
};
// --- 데이터 생성 로직 ---
const messagesToInsert = [];
const startDate = new Date(); // 현재 시간부터 과거로 메시지 생성
print(`Generating ${totalMessages} messages for room ID: ${targetRoomId}...`);
for (let i = 0; i < totalMessages; i++) {
const sender = i % 2 === 0 ? userA : userB;
// 5초 간격으로 과거 방향으로 메시지 타임스탬프 생성
const messageTimestamp = new Date(startDate.getTime() - (totalMessages - i) * 1000 * 5);
const messageDocument = {
roomId: NumberLong(targetRoomId),
senderId: sender.id,
senderName: sender.name,
content: `이것은 ${i + 1}번째 테스트 메시지입니다.`,
timestamp: NumberLong(messageTimestamp.getTime()),
_class: "com.benecia.lifetracker.db.mongo.chat.ChatMessageDocument"
};
messagesToInsert.push(messageDocument);
}
// insertMany를 사용해 한 번에 모든 데이터를 삽입 (가장 빠름)
db.chat_messages.insertMany(messagesToInsert);
print(`Successfully inserted ${messagesToInsert.length} messages into the 'chat_messages' collection.`);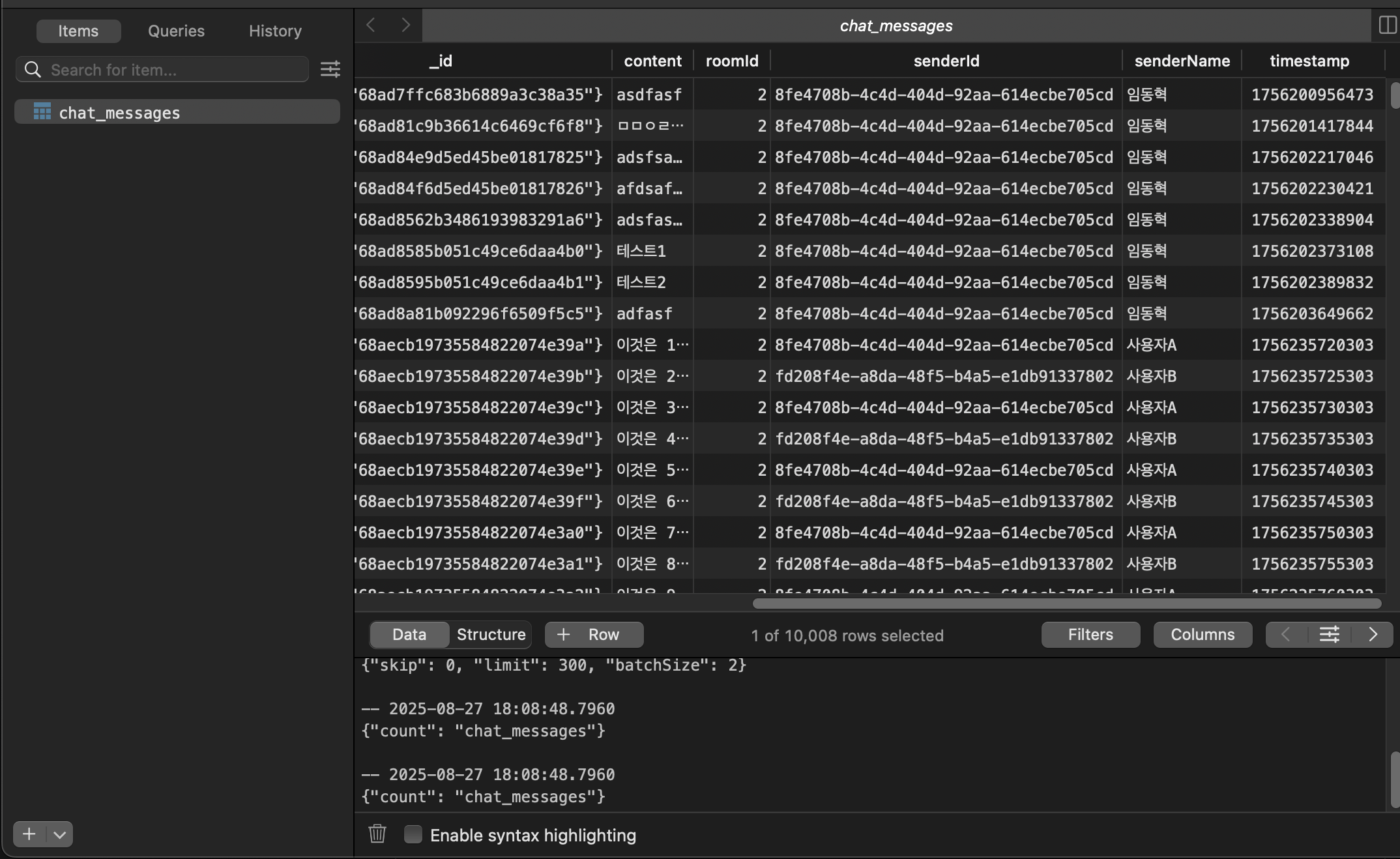
Postman 테스트
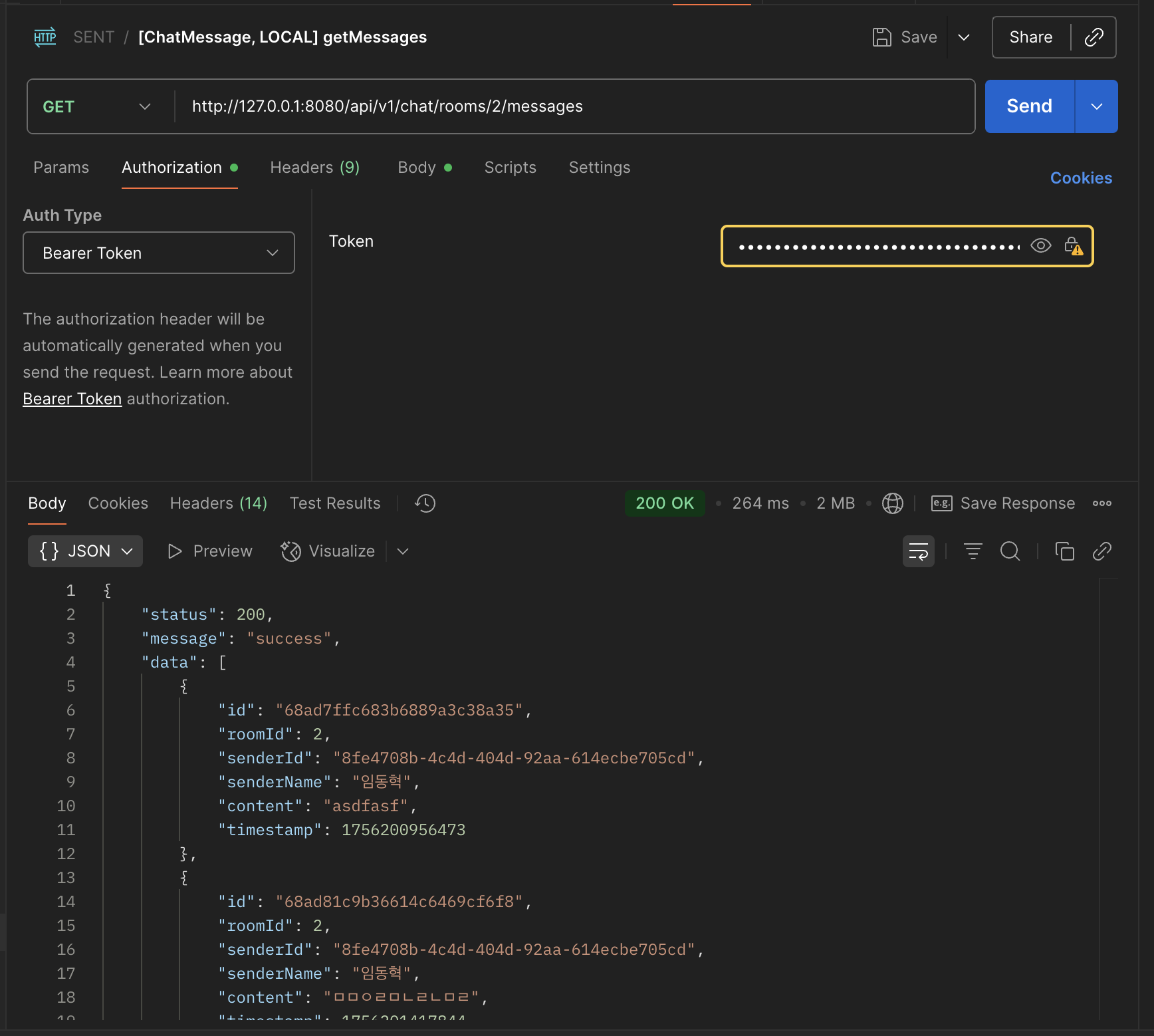
예상과 달리 성능이 나쁘지 않다.
1만개의 데이터를 Full Scan해서 가져왔음에도 불구하고 264ms와 2mb 밖에 나오지 않는 성능을 보인다.
추가적으로 테스트를 해봐야할 점이 무엇일까?
"혼자 테스트할 때"와 "여러 명이 동시에 사용할 때"의 차이가 필요하다.
264ms라는 시간은 크게 두 가지로 나눌 수 있다.
1. DB 처리 시간: DB가 10,000개의 문서를 찾아서 메모리에 올리는 시간
2. 네트워크 전송 시간: 서버가 그 10,000개의 데이터를 Postman(클라이언트)으로 전송하는 시간
Postman으로 혼자 테스트할 때는 서버의 모든 자원(CPU, 메모리, 네트워크)을 혼자 독차지하기 때문에 빨라 보일 수 있다.
K6 부하테스트
k6를 사용해서 부하테스트를 진행한다.
우선적으로 가볍게 스크립트를 작성해보자.
import http from 'k6/http';
import { check, sleep } from 'k6';
// 테스트 옵션: 10명의 가상 유저(vus)가 30초(duration) 동안 계속 요청
export const options = {
vus: 10,
duration: '30s',
};
// --- 테스트 전 설정 ---
const accessToken = 'ACCESS_TOKEN';
const roomId = 2;
export default function () {
const url = `http://localhost:8080/api/v1/chat/rooms/${roomId}/messages`;
const params = {
headers: {
'Authorization': `Bearer ${accessToken}`,
},
};
const res = http.get(url, params);
check(res, { 'status was 200': (r) => r.status == 200 });
sleep(1);
}활성화 사용자 수를 10명으로 지정하고 30초 동안 계속 요청해보자.,
1차 k6 부하 테스트 결과 (페이지네이션 적용 전)
| 지표 (Metric) | 결과 (Result) | 분석 |
|---|---|---|
| 평균 응답 시간 (avg) | 229.98 ms | 한 번의 요청을 처리하는 데 평균 약 0.23초가 소요 |
| p(95) 응답 시간 | 423.98 ms | 95%의 요청은 0.42초 이상 걸렸으며, 일부 사용자는 눈에 띄는 지연을 경험할 수 있음 |
| 데이터 전송량 | 526 MB | 30초 동안 526MB의 많은 데이터가 전송되었습니다. 이는 시스템의 가장 큰 비효율 지점 |
| 요청 성공률 | 100 % | 모든 요청이 실패 없이 성공적으로 처리되어, 현재 부하 수준에서는 서버가 안정적임을 보여줌 |
이렇게만 하지말고 저번에 Todo를 부하테스트 했듯이 같은 시나리오로 돌리고 측정해보자.
import http from 'k6/http';
import { check, sleep } from 'k6';
// 옵션을 단계별(stages) 부하 시나리오로 변경
export const options = {
stages: [
{ duration: '30s', target: 10 }, // 30초 동안 10명까지 부하 증가 (스모크)
{ duration: '30s', target: 50 }, // 이어서 30초 동안 50명까지 증가 (소규모)
{ duration: '1m', target: 200 }, // 이어서 1분 동안 200명까지 증가 (중간 부하)
{ duration: '1m', target: 500 }, // 이어서 1분 동안 500명까지 증가 (스트레스)
{ duration: '2m', target: 1000 }, // 이어서 2분 동안 1000명까지 증가 (한계)
],
gracefulStop: '30s', // 테스트 종료 후 30초간 정리 시간
};
// --- 테스트 전 설정 ---
const accessToken = 'ACCESS_TOKEN';
const roomId = 2; // 더미 데이터가 있는 채팅방 ID
export default function () {
const url = `http://localhost:8080/api/v1/chat/rooms/${roomId}/messages`;
const params = {
headers: { 'Authorization': `Bearer ${accessToken}` },
};
const res = http.get(url, params);
check(res, { 'status was 200': (r) => r.status == 200 });
sleep(1);
}시나리오대로 점진적으로 부하를 늘려가면서 버틸 수 있는 지에 대해 부하테스트를 진행한다.
2차 부하테스트 결과 (페이지네이션 적용 전)
중간에 터지기 시작하더니 터짐과 성공을 반복했다.
401이 터지길래 토큰이 만료되었나 싶었는데 요청이 잘 가지다가 다시 터지는걸 보고 DB에서 지금 유저도 못 긁고 있구나를 알 수 있었다.
2차 k6 부하 테스트 결과 요약 (페이지네이션 적용 전)
| 지표 | 값 | 해설 |
|---|---|---|
| 평균 응답 속도 (avg) | 16.18 s | 평균적으로 요청 하나를 처리하는 데 16초 이상 걸림 (사용 불가 수준) |
| 최소 응답 속도 (min) | 109.06 ms | 부하가 가장 적었던 테스트 초반의 가장 빠른 응답 |
| 중앙값 (med) | 12.03 s | 전체 요청의 50%는 12초 이내에 처리되었음을 의미 |
| 최대 응답 속도 (max) | 1m 0s | 가장 오래 걸린 요청은 1분이 소요 (사실상 타임아웃) |
| p(90) 응답 속도 | 42.11 s | 요청의 90%가 42초 이내에 응답 |
| p(95) 응답 속도 | 50.58 s | 요청의 95%가 50초 이내에 응답했으며, 대부분의 사용자가 극심한 지연을 겪었음을 보여줌 |
| 요청 성공률 | 55.05 % | 전체 요청의 약 45%가 실패했습니다. 서버가 부하를 전혀 감당하지 못하고 있음 |
| 총 요청 수 (http_reqs) | 7,629 | 테스트 시간(5분) 동안 총 7,629회의 요청이 시도됨 |
종합 평가
시스템 붕괴 (System Collapse)
이 결과는 서버가 점진적으로 증가하는 부하를 감당하지 못하고 완전히 무너지는 과정을 보여주었다.
응답 시간은 사용자가 기다릴 수 없는 수준으로 폭증했으며, 결국에는 요청의 절반 가까이를 처리하지 못하고 실패시켰다.
페이지네이션이 없는 현재 API는 실제 서비스 환경에서 사용할 수 없음이 명확하게 증명되었다.
페이지네이션을 넣어서 최적화를 해보자.
페이지네이션 적용 부하테스트
30개씩 조회를 처리했을 때는 231ms와 6.65kb이다.
생각보다 30개 밖에 조회를 하지 않음에도 불구하고 시간 차이는 별로 나지 않는다.
한번 더 요청하면 메모리 캐시 덕에 60ms까지 줄어든다.
첫 페이지 조회 부하 테스트 (페이지네이션 적용)
메세지 조회 테스트를 본격적으로 시작해보자.
보통 카카오톡이나 인스타그램 DM을 사용하면서 가장 많이 조회가 될 것이 바로 채팅창에 진입했을 때 최근 채팅 목록이며, 그 위로 올리는 경우가 많지는 않다.
그렇기에 사용자의 채팅을 보여줄 수 있는 첫 30개에 대한 목록을 불러온다.
import http from 'k6/http';
import { check, sleep } from 'k6';
// 옵션: 10명부터 1000명까지 점진적으로 부하를 높이는 시나리오
export const options = {
stages: [
{ duration: '30s', target: 10 }, // 30초 동안 10명까지 부하 증가 (스모크)
{ duration: '30s', target: 50 }, // 이어서 30초 동안 50명까지 증가 (소규모)
{ duration: '1m', target: 200 }, // 이어서 1분 동안 200명까지 증가 (중간 부하)
{ duration: '1m', target: 500 }, // 이어서 1분 동안 500명까지 증가 (스트레스)
{ duration: '2m', target: 1000 }, // 이어서 2분 동안 1000명까지 증가 (한계)
],
gracefulStop: '30s', // 테스트 종료 후 30초간 정리 시간
};
// --- 테스트 전 설정 ---
const accessToken = 'ACCESS_TOKEN';
const roomId = 2; // 더미 데이터가 있는 채팅방 ID
export default function () {
// URL에 size=30 쿼리 파라미터를 추가하여 페이지네이션을 적용합니다.
const url = `http://localhost:8080/api/v1/chat/rooms/${roomId}/messages?size=30`;
const params = {
headers: { 'Authorization': `Bearer ${accessToken}` },
};
const res = http.get(url, params);
check(res, { 'status was 200': (r) => r.status == 200 });
sleep(1);
}k6 부하 테스트 결과 요약 (페이지네이션 적용 후)
| 지표 | 값 | 해설 |
|---|---|---|
| 평균 응답 속도 (avg) | 174.66 ms | 평균적으로 요청 하나를 0.17초 만에 처리 (매우 빠르고 안정적인 수준) |
| 최소 응답 속도 (min) | 5.97 ms | 가장 빠르게 처리된 요청으로, 캐시 등이 준비된 상태에서의 이상적인 속도 |
| 중앙값 (med) | 21.63 ms | 전체 요청의 절반이 0.02초라는 매우 빠른 시간 안에 처리되었음을 의미 |
| 최대 응답 속도 (max) | 1.19 s | 가장 부하가 심했던 순간에도 1.2초 내에 응답하여, 타임아웃 없이 안정적 |
| p(90) 응답 속도 | 511.11 ms | 대부분(90%)의 요청이 약 0.5초 안에 응답하여 쾌적한 사용자 경험을 제공 |
| p(95) 응답 속도 | 634.05 ms | 거의 모든 사용자(95%)가 0.63초 안에 응답을 받아, 높은 부하에서도 성능이 안정적 |
| 요청 성공률 | 99.34 % | 전체 요청의 99% 이상이 성공 |
| 0.66%의 실패는 일시적인 네트워크 문제 등으로 보이며, 시스템은 매우 안정적 | ||
| 총 요청 수 (http_reqs) | 102,278 | 5분 동안 이전 테스트보다 13배 이상 많은 10만 건 이상의 요청을 성공적으로 처리 |
종합 평가
이전 테스트에서 '사용 불가' 판정을 받았던 API가 페이지네이션 이후, 실제 서비스로 운영해도 될 만큼 훌륭한 성능과 안정성을 보여주었다.
최대 1,000명의 동시 사용자가 몰리는 극한의 부하 상황에서도 시스템은 무너지지 않고, 대부분의 사용자에게 1초 미만의 빠른 응답 속도를 제공한다. 이로써 성능 개선 작업이 성공적으로 완료되었음을 명확히 확인할 수 있습니다.
추가적으로 해볼 점
기존에는 더미데이터를 다 조회하는 걸로 부하를 줬다고 가정하면 지금 상황에서는 30개만 불러올 수 있다.
하지만 비즈니스적으로 생각해보자.
- 현재 우리가 해결해야할 문제는 채팅 목록 조회에 대한 성능 최적화이다.
- 대부분의 사용자는 채팅방에 진입했을 때 마지막으로 주고받은 메세지를 확인하고 과거 메세지를 조회하는 일은 드물다.
- 그런데 굳이 엄청나게 많이 쌓인 데이터를 처음부터 전부 조회해줄 필요가 없다는 것이다.
- 그렇기에 커서 기반 페이지네이션을 적용하여 최근 30개의 메세지를 보여주고, 스크롤을 통해서 위로 올렸을 때 마지막으로 메세지를 보낸 시간을 기준점으로 그 위의 30개의 메세지를 또 보여준다면 한 번에 1만개의 데이터를 뿌려줄 필요가 없어진다.
여기서 추가적으로 해볼만한 점은 다양한 테스트, 최근 주고 받은 30건 정도의 메세지는 캐싱을 적용하여 자주 채팅방을 들락날락 할 때의 부하를 좀 더 줄이는 방법, MongoDB에 인덱스를 걸어서 FULL SCAN을 해소하는 방법이 있다.
이 테스트 정도는 비즈니스적으로 가장 많이 조회가 될 화면에 대한 테스트는 적합하다.
-
무한 스크롤 테스트: 각 가상 유저(VU)가 첫 페이지를 조회하고, 응답에서 가장 오래된 메시지의
timestamp를 뽑아내어 다음 페이지를 계속해서 요청
이는 페이지가 깊어져도(아주 오래된 메시지를 조회해도) 성능이 유지되는지 확인할 때 유용하다. -
복합 시나리오 테스트: 실제 사용자 행동처럼 여러 API를 섞어서 테스트
예를 들어, 가상 유저의 80%는 채팅방 목록과 첫 페이지만 조회하고, 15%는 스크롤을 올리며, 5%는 새로운 메시지를 보내는 식이다.
이는 시스템 전체의 안정성을 검증하는 데 효과적이다. -
채팅 메세지가 현재 동기적으로 일어나는데 비동기로 처리할 것
→ https://ldhbenecia.notion.site/25d4fa8f67dd800a9131c90f75386cc0?source=copy_link
복합 인덱스 적용
FULL SCAN을 방지하기 위해서 MongoDB에 복합 인덱스를 적용해보자.
(roomId, timestamp)에 복합 인덱스(Compound Index)를 적용하면, 데이터베이스는 더 이상 전체 데이터를 훑어볼 필요가 없다.
1. Mongo Shell 접속
먼저, 이전과 같이 인증 정보를 포함하여 Docker 컨테이너 내부의 Mongo Shell에 접속한다.
docker exec -it CONTAINER mongosh -u DBNAME -p --authenticationDatabase admin2. 데이터베이스 선택
use DB3. 인덱스 생성 명령어 실행
db.chat_messages.createIndex({ roomId: 1, timestamp: -1 })인덱스가 일하는 방식
가장 간단한 사전으로 비유를 들겠다.
10,000 페이지짜리 백과사전에서 "프로그래밍"에 대한 내용 중 가장 최신 정보 30건만 찾는다고 상상하자.
- 인덱스가 없을 때 (Full Scan)
- 백과사전 1페이지부터 10,000 페이지까지 모든 페이지를 한 장씩 넘겨가면서 "프로그래밍"이라는 단어가 있는지 모두 확인한다.
- 찾은 모든 내용의 발행일을 비교하여 가장 최신 정보 30건을 필터링한다.
- 결과: 30건의 정보를 찾기 위해 책 전체를 다 읽는다.
- 인덱스가 있을 때 (Index Scan) - 현재 방식
- 백과사전 맨 뒤의 "찾아보기(인덱스)"를 펼친다. (보통 사전 제일 뒤에 있는 빠르게 찾기 기능)
- "ㅍ"섹션에서 "프로그래밍" 항목을 찾는다. 이 항목에는 "프로그래밍" 관련 내용이 몇 페이지에 있는 지, 이미 발행일 순으로 정렬되어있다.
- 정렬된 목록의 가장 마지막 부분으로 이동해서, 거기서부터 30건의 페이지만 확인하고 책을 덮는다.
- 결과: 30건의 정보를 찾기 위해 책의 딱 그 부분만 읽었다.
복합 인덱스 거는 코드에서
db.chat_messages.createIndex({ roomId: 1, timestamp: -1 })이 명령어가 인덱스를 생성하는 명령어이며, 백과사전의 "찾아보기" 기능을 만드는 과정이다.
roomId별로 메세지를 그룹화 하고, 그 안에서 timestamp를 기준으로 정렬한다.
최종 성능 비교: 페이지네이션 vs 페이지네이션 + 인덱스
| 지표 (Metric) | 페이지네이션만 적용 | 페이지네이션 + 인덱스 적용 | 분석 |
|---|---|---|---|
| 평균 응답 시간 (avg) | 174.66 ms | 22.85 ms | 약 7.6배 빨라짐. DB가 더 이상 Full Scan을 하지 않고 인덱스를 통해 즉시 데이터를 찾기 때문 |
| p(95) 응답 시간 | 634.05 ms | 72.37 ms | 약 8.8배 안정적. 부하가 높아져도 DB 작업이 매우 빠르고 일정하므로, 대부분 사용자의 경험이 일관되게 빨라짐 |
| 요청 실패율 | 0.66 % | 0.00 % | 사라짐. DB 부하가 크게 줄어들면서 최고 부하 지점에서 발생하던 일시적인 오류들이 완전히 해소 |
| 총 요청 처리량 | 102,278 회 | 117,133 회 | 약 14% 증가. 각 요청을 더 빨리 처리하면서, 같은 시간 동안 더 많은 트래픽을 소화할 수 있게 됨 |
최종 정리
이 두 테스트 결과를 통해 우리는 두 가지 중요한 최적화의 역할을 명확히 구분할 수 있다.
- 페이지네이션의 효과 (16초 → 174ms)
- 서버의 메모리 사용량과 네트워크 트래픽을 줄여 시스템 붕괴를 막는 결정적인 역할을 했다.
45%에 달하던 실패율을 거의 없애고 서비스를 안정화시켰다.
- 서버의 메모리 사용량과 네트워크 트래픽을 줄여 시스템 붕괴를 막는 결정적인 역할을 했다.
- 인덱스의 효과 (174ms → 22ms)
- 이미 안정화된 시스템의 DB 조회 성능을 극한까지 끌어올려 훨씬 더 빠르고 일관된 응답 속도를 만들었다.
평균 응답 속도를 7배 이상 단축 시킬 수 있었다.
- 이미 안정화된 시스템의 DB 조회 성능을 극한까지 끌어올려 훨씬 더 빠르고 일관된 응답 속도를 만들었다.
결론적으로, 페이지네이션이 서버를 안정시키는 방어막 역할을 했다면, 인덱스는 그 안정된 서버를 고성능 스포츠카로 튜닝하는 역할을 한 셈이다.
최종 성능 비교 요약 (단계별 최적화 과정)
| 지표 (Metric) | 최적화 전 (No Pagination/Index) | 1차 최적화 (Pagination Only) | 최종 최적화 (Pagination + Index) |
|---|---|---|---|
| 평균 응답 시간 (avg) | 16.18 s | 174.66 ms | 22.85 ms |
| p(95) 응답 시간 | 50.58 s | 634.05 ms | 72.37 ms |
| 요청 실패율 | 44.94 % | 0.66 % | 0.00 % |
| 총 요청 처리량 | 7,629 회 | 102,278 회 | 117,133 회 |

좋은 글입니다. 응원합니다!