
이전 글에서 블로그 게시물에 이미지 업로드 기능을 추가했습니다.
시간이 지남에 따라 블로그에 상당한 수의 기사가 축적되었다고 상상해 보세요. 새로운 문제가 서서히 나타납니다. 독자들이 원하는 기사를 빠르게 어떻게 찾을 수 있을까요?
물론 답은 검색입니다.
이 튜토리얼에서는 블로그에 전체 텍스트 검색 기능을 추가할 것입니다.
SQL LIKE '%keyword%' 쿼리를 사용하여 검색을 구현할 수 없다고 생각할 수도 있습니다.
간단한 시나리오에서는 확실히 할 수 있습니다. 그러나 LIKE 쿼리는 대규모 텍스트 블록을 처리할 때 성능이 좋지 않고 퍼지 검색을 처리할 수 없습니다(예: "creation"을 검색하면 "create"와 일치하지 않음).
따라서 우리는 더 효율적인 솔루션을 채택할 것입니다. PostgreSQL의 내장 전체 텍스트 검색(FTS) 기능을 활용하는 것입니다. 빠를 뿐만 아니라 스태밍 및 관련성 순위 지정과 같은 기능도 지원하여 LIKE보다 훨씬 뛰어난 검색 기능을 제공합니다.
1단계: 데이터베이스 검색 인프라
PostgreSQL의 FTS 기능을 사용하려면 먼저 post 테이블을 일부 수정해야 합니다. 핵심 아이디어는 고속 검색이 가능한 최적화된 텍스트 데이터를 저장하기 위한 특수 열을 만드는 것입니다.
핵심 개념: tsvector
post 테이블에 tsvector 유형의 새 열을 추가할 것입니다. 기사의 제목과 내용을 개별 단어(어근)로 분해하고 정규화합니다(예: "running"과 "ran"을 모두 "run"으로 처리) 후속 쿼리에 사용합니다.
테이블 구조 수정
다음 SQL 문을 PostgreSQL 데이터베이스에서 실행하여 post 테이블에 search_vector 열을 추가합니다.
ALTER TABLE "post" ADD COLUMN "search_vector" tsvector;데이터베이스가 Leapcell에서 생성된 경우

웹사이트의 데이터베이스 관리 페이지로 이동하여 위의 문을 SQL 인터페이스에 붙여넣고 실행하기만 하면 그래픽 인터페이스를 사용하여 SQL 문을 쉽게 실행할 수 있습니다.
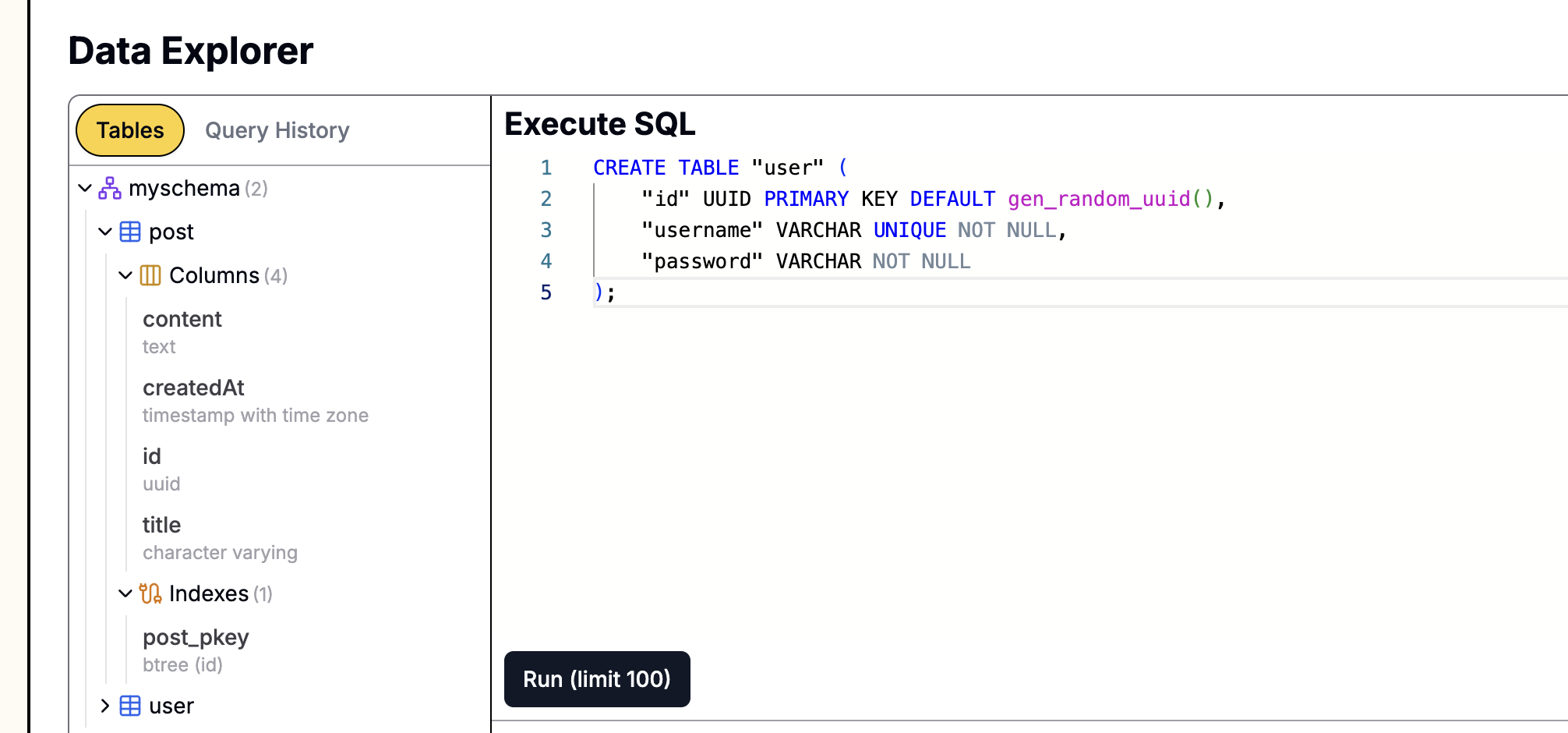
기존 게시물에 대한 검색 벡터 업데이트
검색(search_vector) 벡터를 업데이트하면 게시물을 검색할 수 있게 됩니다.
블로그에 이미 일부 기사가 있으므로 다음 SQL 문을 실행하여 해당 항목에 대한 search_vector 데이터를 생성할 수 있습니다.
UPDATE "post" SET search_vector =
setweight(to_tsvector('english', coalesce(title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(content, '')), 'B');트리거를 사용한 자동 업데이트
게시물이 생성되거나 업데이트될 때마다 search_vector 열을 수동으로 업데이트하고 싶지 않을 것입니다. 가장 좋은 방법은 데이터베이스가 이 작업을 자동으로 수행하도록 하는 것입니다. 이는 트리거를 만들어 달성할 수 있습니다.
먼저, 위의 쿼리와 마찬가지로 게시물에 대한 search_vector 데이터를 생성하는 함수를 만듭니다.
CREATE OR REPLACE FUNCTION update_post_search_vector()
RETURNS TRIGGER AS $$
BEGIN
NEW.search_vector :=
setweight(to_tsvector('english', coalesce(NEW.title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(NEW.content, '')), 'B');
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
setweight함수를 사용하면 다른 필드의 텍스트에 다른 가중치를 할당할 수 있습니다. 여기서는 제목('A')의 가중치를 내용('B')보다 높게 설정했습니다. 즉, 검색 결과에서 제목에 키워드가 있는 기사가 더 높은 순위로 표시됩니다.
다음으로, 새 게시물이 삽입(INSERT)되거나 업데이트(UPDATE)될 때마다 방금 만든 함수를 자동으로 호출하는 트리거를 만듭니다.
CREATE TRIGGER post_search_vector_update
BEFORE INSERT OR UPDATE ON "post"
FOR EACH ROW EXECUTE FUNCTION update_post_search_vector();검색 인덱스 생성
마지막으로 검색 성능을 보장하기 위해 search_vector 열에 GIN(Generalized Inverted Index)을 생성해야 합니다.
CREATE INDEX post_search_vector_idx ON "post" USING gin(search_vector);이제 데이터베이스가 검색 준비가 되었습니다. 각 기사에 대한 효율적인 검색 인덱스를 자동으로 유지 관리합니다.
2단계: FastAPI에서 검색 로직 구축
데이터베이스 계층이 준비되었습니다. 이제 검색 요청을 처리하기 위한 백엔드 코드를 작성하기 위해 FastAPI 프로젝트로 돌아가겠습니다.
검색 라우트 생성
routers/posts.py 파일에 검색 관련 로직을 직접 추가할 것입니다. SQLModel은 SQLAlchemy를 기반으로 하므로 SQLAlchemy의 text() 함수를 사용하여 원시 SQL 쿼리를 실행할 수 있습니다.
routers/posts.py를 열고 다음 변경 사항을 적용하십시오.
# routers/posts.py
import uuid
from fastapi import APIRouter, Request, Depends, Form, Query
from fastapi.responses import HTMLResponse, RedirectResponse
from fastapi.templating import Jinja2Templates
from sqlmodel import Session, select
from sqlalchemy import text # text 함수 가져오기
from database import get_session
from models import Post
from auth_dependencies import get_user_from_session, login_required
import comments_service
import markdown2
router = APIRouter()
templates = Jinja2Templates(directory="templates")
# ... 다른 라우트 ...
@router.get("/posts/search", response_class=HTMLResponse)
def search_posts(
request: Request,
q: str = Query(None), # 쿼리 매개변수에서 검색어 가져오기
session: Session = Depends(get_session),
user: dict | None = Depends(get_user_from_session)
):
posts = []
if q:
# 사용자 입력(예: "fastapi blog")을 to_tsquery가 이해할 수 있는 형식("fastapi & blog")으로 변환
search_query = " & ".join(q.strip().split())
# 전체 텍스트 검색에 대한 원시 SQL 사용
statement = text("""
SELECT id, title, content, "createdAt"
FROM post
WHERE search_vector @@ to_tsquery('english', :query)
ORDER BY ts_rank(search_vector, to_tsquery('english', :query)) DESC
""")
results = session.exec(statement, {"query": search_query}).mappings().all()
posts = list(results)
return templates.TemplateResponse(
"search-results.html",
{
"request": request,
"posts": posts,
"query": q,
"user": user,
"title": f"Search Results for '{q}'"
}
)
# 이 라우트를 /posts/search 뒤에 배치하여 라우트 충돌을 피하십시오.
@router.get("/posts/{post_id}}", response_class=HTMLResponse)
def get_post_by_id(
# ... 함수 내용이 동일하게 유지됨
# ...코드 설명:
- 파일 상단에
from sqlalchemy import text를 추가합니다. - 새
/posts/search라우트를 추가합니다./posts/{post_id}라우트와 충돌하지 않도록 이 새 라우트를get_post_by_id라우트 앞에 배치해야 합니다. q: str = Query(None): FastAPI는 URL의 쿼리 문자열(예:/posts/search?q=keyword)에서q의 값을 가져옵니다.to_tsquery('english', :query): 이 함수는 사용자 제공 검색 문자열을tsvector열과 일치시킬 수 있는 특수 쿼리 유형으로 변환합니다.&를 사용하여 여러 단어를 연결하여 모든 단어가 일치해야 함을 나타냅니다.@@연산자: 전체 텍스트 검색을 위한 "일치" 연산자입니다.WHERE search_vector @@ ...줄이 검색 작업의 핵심입니다.ts_rank(...): 이 함수는 쿼리 용어가 블로그 게시물과 얼마나 잘 일치하는지에 따라 "관련성 순위"를 계산합니다. 가장 관련성 높은 기사가 먼저 나타나도록 이 순위로 정렬합니다.session.exec(statement, {"query": search_query}).mappings().all()): 원시 SQL 쿼리를 실행하고.mappings().all()을 사용하여 결과를 딕셔너리 목록으로 변환하여 템플릿에서 쉽게 사용할 수 있습니다.
3단계: 프런트엔드에 검색 기능 통합
백엔드 API가 준비되었습니다. 이제 사용자 인터페이스에 검색 상자와 검색 결과 페이지를 추가해 보겠습니다.
검색 상자 추가
templates/_header.html 파일을 열고 탐색 모음에 검색 양식을 추가합니다.
<header>
<h1><a href="/">My Blog</a></h1>
<nav>
<form action="/posts/search" method="GET" class="search-form">
<input type="search" name="q" placeholder="Search posts..." required>
<button type="submit">Search</button>
</form>
{% if user %}
<span class="welcome-msg">Welcome, {{ user.username }}</span>
<a href="/posts/new" class="new-post-btn">New Post</a>
<a href="/auth/logout" class="nav-link">Logout</a>
{% else %}
<a href="/users/register" class="nav-link">Register</a>
<a href="/auth/login" class="nav-link">Login</a>
{% endif %}
</nav>
</header>검색 결과 페이지 생성
templates 디렉토리에 search-results.html이라는 새 파일을 만듭니다. 이 페이지는 검색 결과를 표시하는 데 사용됩니다.
{% include "_header.html" %}
<div class="search-results-container">
<h2>Search Results for: "{{ query }}"</h2>
{% if posts %}
<div class="post-list">
{% for post in posts %}
<article class="post-item">
<h2><a href="/posts/{{ post.id }}">{{ post.title }}</a></h2>
<p>{{ post.content[:150] }}...</p>
<small>{{ post.createdAt.strftime('%Y-%m-%d') }}</small>
</article>
{% endfor %}
</div>
{% else %}
<p>No posts found matching your search. Please try different keywords.</p>
{% endif %}
</div>
{% include "_footer.html" %}실행 및 테스트
애플리케이션을 다시 시작합니다.
uvicorn main:app --reload브라우저를 열고 블로그 홈페이지로 이동합니다.
"testing"이라는 키워드가 포함된 새 기사를 작성해 보겠습니다.
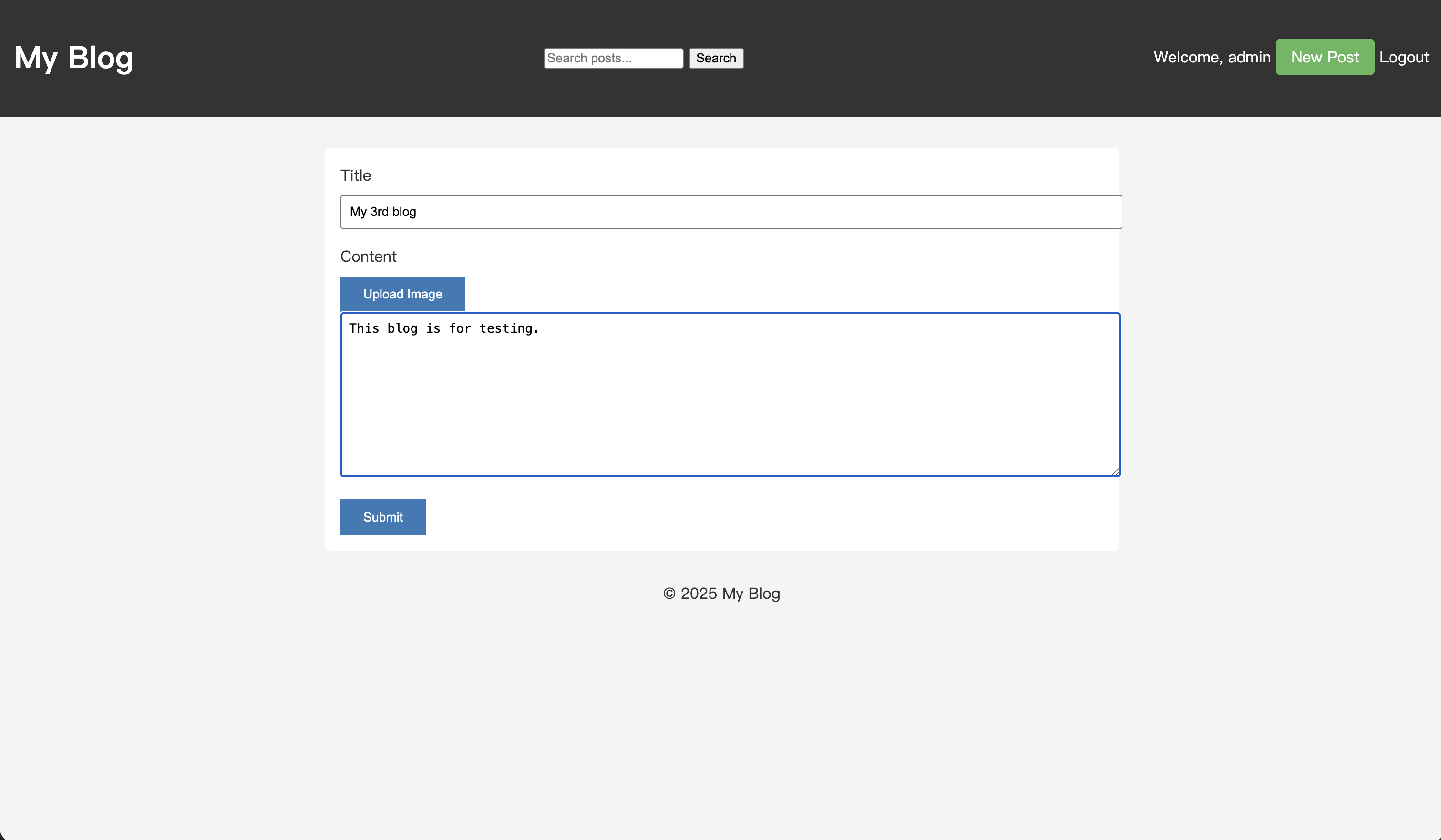
게시물을 저장한 후 검색 상자에 "test"를 입력하고 검색을 수행합니다.
검색 결과 페이지에서 방금 만든 기사가 결과에 나타납니다.
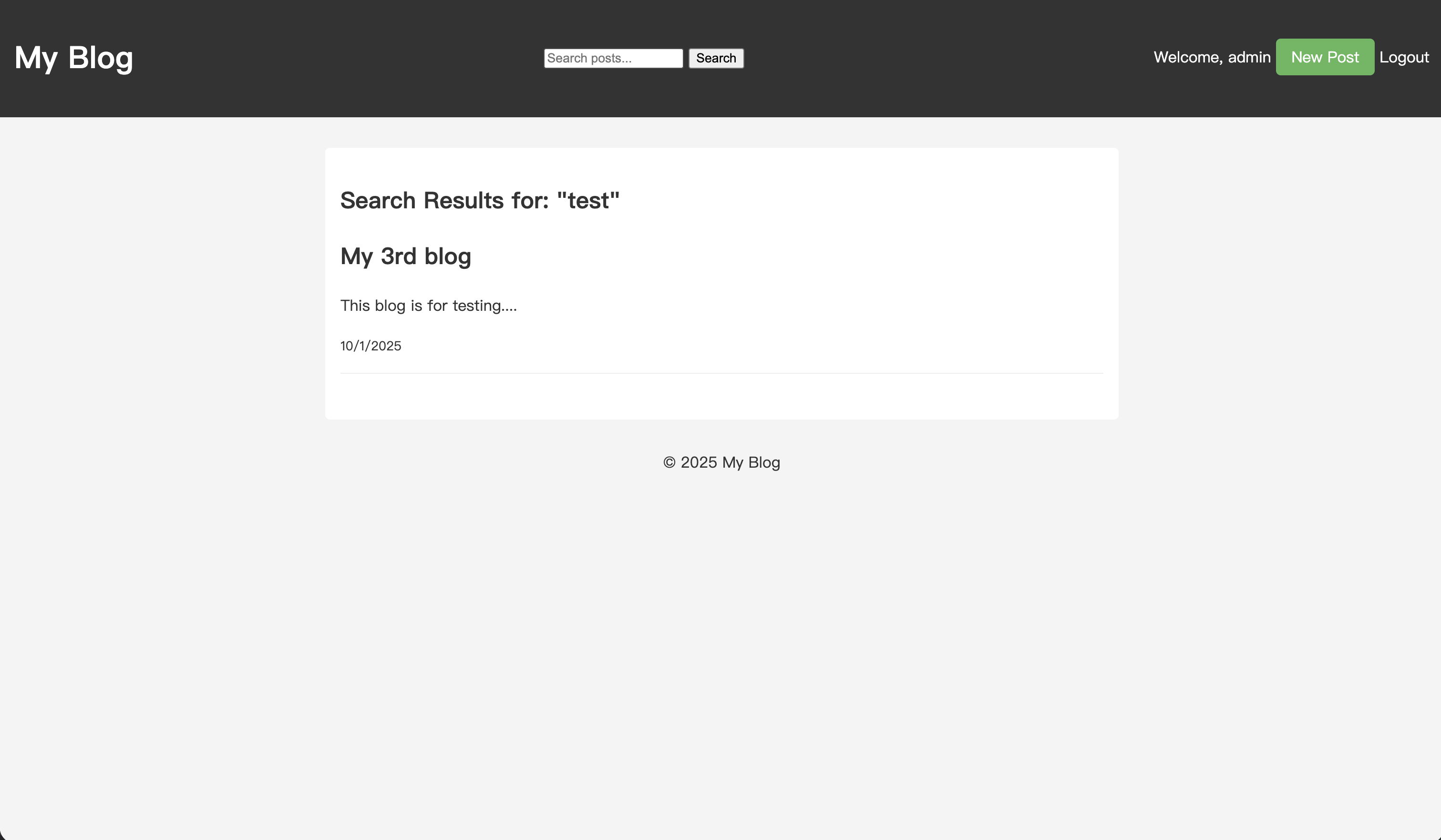
이제 블로그에서 전체 텍스트 검색 기능을 지원합니다. 얼마나 많이 쓰든 독자들이 더 이상 길을 잃지 않을 것입니다.
X에서 저희를 팔로우하세요: @LeapcellKR
관련 글:
