
강화학습 튜토리얼 세미나 - 1일차
Video Lectures (by Prof. Sang-Jo Yoo) : https://sites.google.com/view/multinet-inha/lectures
에 대한 간단한 note를 담은 글
인턴 가기전에 RL 튜토리얼 영상을 급하게 듣게 됐다. 간단하게 기억남는 개념 위주로 짧게 정리함
- Lecture 1. Introduction
- Lecture 2. Multi-armed Bandits
.
.
.
.
Lecture 1. Introduction
RL이 따르는 아주 기본적인 Method로 Monte Carlo Method와 Temporal Difference Method가 있다. (특히, Temporal Difference Method에 Q-Learning 등이 있는것 같다.)
다양한 Method들은 나중에 소개
그래서 목적이 뭐냐?
당연하게도 인공지능 목적인 reasoning, planning, perception 등 과 같음.
Trial and error learning
말그대로 시행착오러닝. RL 역사를 소개하자면 이게 가장 먼저 나오지 않을까,,,
Bellan equation
밸만 아재의 방정식. 많은 RL 알고리즘의 중심 개념이지 않을까
Supervised vs Unsupervised
굳이 하나로 나눠라 하면... 데이터에 대한 타게팅이나 라벨링 여부?..
그래서 강화학습이 뭔데
어떤 explicitly명시적인 telling 없이 특정목적을 달성하는 dynamic environment 와의 interact 아닐까?
최종 전체 reward 가 최대가 되는 action을 학습한다 정도.
(카트&폴 예시를 들었다)
명시적으로 말하지 않는다는 의미 : 너의 Action이 좋다/나쁘다를 Environment에서 Agent에게 말해주지 않는다.
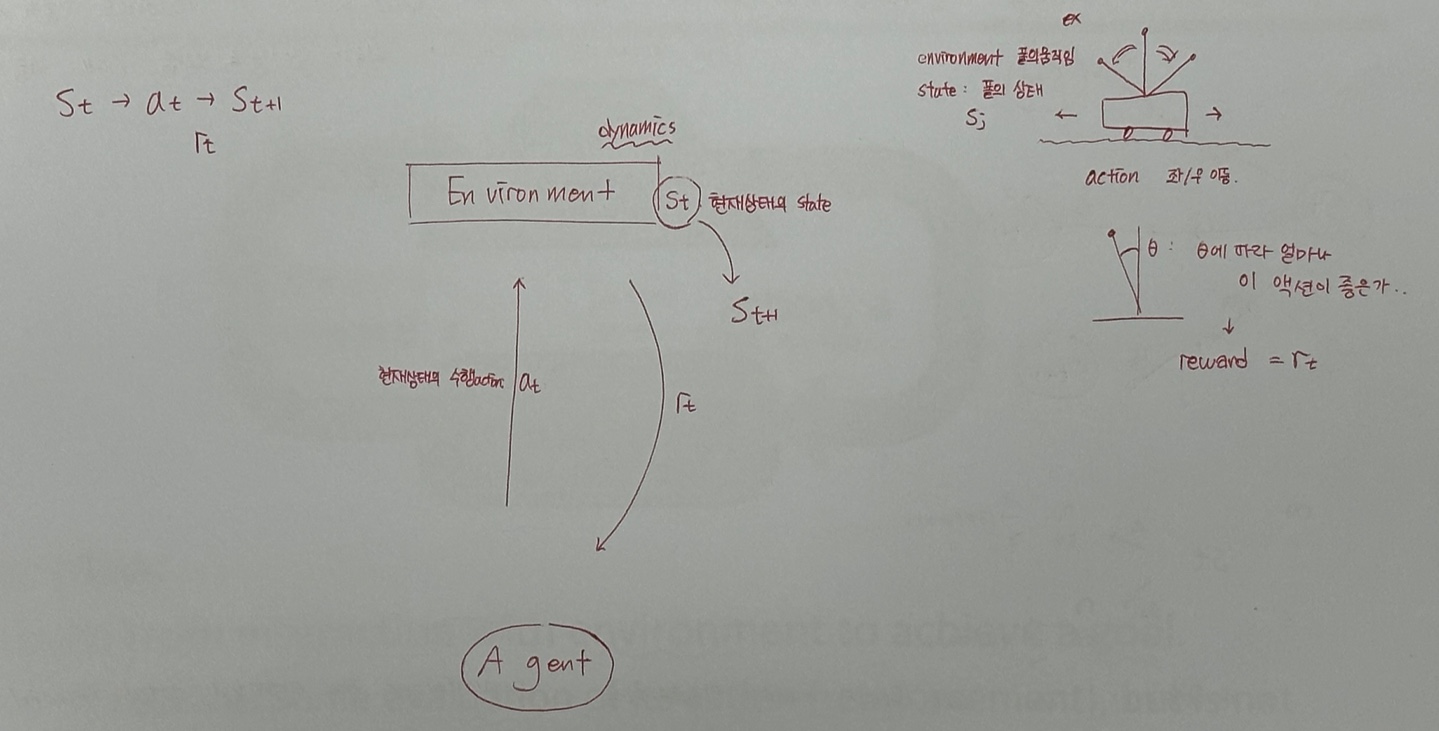

그러니까 결국 어떤 goal을 달성하기 위해 동적인 환경과 상호작용 하여 학습하는 것
환경이 바뀐다
Deterministic vs Stochastic
Determinisitc : 결정론적) 이 Action을 하면 이 State로 간다.
Stochastic : 확률적) 이 Action을 했을 때의 State와 Reward 값이 많음.
강화학습을 위한 모델의 구성
State : 환경의 상태 S
Action : 에이전트의 동작 A
상태간 Transitions(전이) : 어느상태로, 어떤확률로 변할 것인지
전이에서의 즉각적인 Reward 스칼라 : R
What the agent observes : S 가 어느상태 S'로 바뀌었는지 관측 가능해야하고, 얼마만큼의 R을 받는지도 관측 가능해야함 => 그래야 강화학습 진행 가능
.
.
.
.
Lecture 2. Multi-armed Bandits
lecture 내내 slot machine으로 예를 들었던... 기억나지?
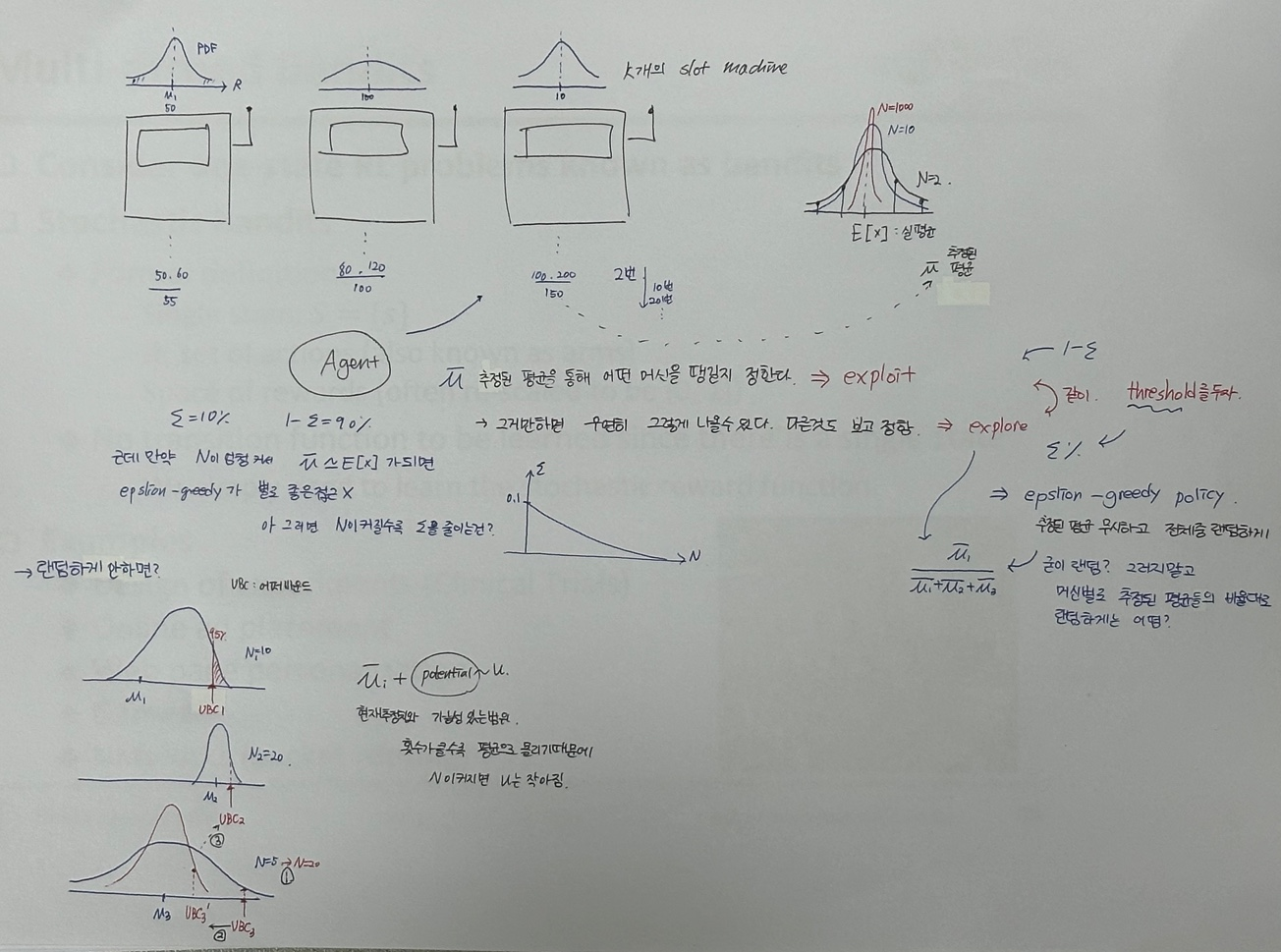
(위 사진이 Multi-armed Bandits의 전부이긴 하다)
K개의 Action을 하는 머신이 있고, 모든 머신은 사용자에게 알려지지않은 정적확률분포(PDF)에서 Reward 값을 받아, 리턴해준다. (슬롯 머신의 확률은 사용자가 알수없다는 의미같음)
우리의 목적은 : 전체 기대reward를 최대로 하는 것
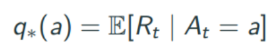
q*(a) : a슬롯 머신을 선택했을때 받아지는 Reawrd의 기대치
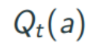
Qt(a) : Action Value , 특정 action a에 대해서 시간t까지의 추정치 -> 이걸 기반으로 머신을 당기겠다 왜? True값을 우리는 모르니까
Exploitation 과 Exploration 간단하게 비교
Exploitation : epsilon greedy action , 가장 max값 선택 (추정된 머신별 평균을 통해 그 중 가장 높은 확률의 머신을 뽑는다.)
Exploration : select nongreedy action (그러면 우연히 높은값 샘플로 인해 잘못 추정될 수 있으니 다른것도 explore 해보고 정하자.)
exploitaion 에 (1-앱실론) 을, exploration 에 (앱실론)을 준다.

stepsize 는 1/n 을 의미한다.
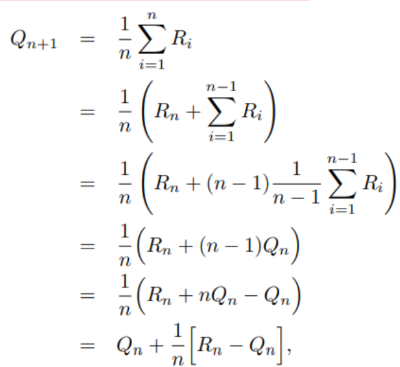
맨 윗줄은, 1스텝씩 가면서 번돈 Ri의 평균을 계산하는 것. 그러니까 1/n을 했겠지
진짜 문제는 이제나온다.

PDF가 stationary 하지 않는게 보통일 것이다. (실세계는 정적이지 않다. 당연히 PDF가 종종 바뀌겠지)
이때 step size로 사용했던 1/n 대신에 constant 값을 넣어준다! 왜?

오른쪽 식을 잘 뜯어먹어보자. 특히 저 노란줄
constant값 0.2, n을 10으로 넣었을때 Reward값이 과거로 갈수록(i가 1에가까운 녀석일수록) 값의 비율이 엄청 작아지는 것을 알수있다.
=> 이를 통해 과거의 비중은 낮추고 최근의 비중은 높게! PDF를 바꿔도 과거값 비중이 점점 작아져서 non-stationary 상황에 잘 적응할 수 있구나! 를 알수있음.
.
.
.
.
영알못은 웁니다.
explicitly : 명시적인
Stochastic : 확률적인
