
<TD3 논문 리뷰>
누가 DRL을 묻거든 눈 들어 TD3 논문을 보게 하라...

비교적 최근(?) 논문은 처음 읽는데, 래퍼런스나 요구하는 사전 지식의 스케일이 크다. 최대한 이해하기 쉽게 정리했으니, 이해가 안되는 부분이 있다면 이번 기회에 재정립 하면 좋을 것 같다.
Paper : https://arxiv.org/pdf/1802.09477
DDPG와 거의 같은 형태를 가지고 있기 때문에 구현이 쉽다. (DDPG를 develop 했다고 생각하면 좋다.)
해당 논문에서 해결하려는 Problem 은 2가지
- Overestimation Bias
-> solution : Clipped Double Q-network and Update - Accumulation error from TD update
-> solution : Delayed Policy Update & Target Policy Smoothing
Overestimation Bias
Q-Learning 은 학습에서 Greedy Target을 사용하는데, Greedy Target을 위해 approximator를 사용하는 과정에서 추정오차 발생
-> Greedy Target 에서 max연산은 오차가 포함된 Q값 중 가장 큰 값을 선택한다.
-> 이는 Overestimation bias로 이어짐
Actor - Critic 방식에서도 마찬가지임을 논문에서 보여주고 있다.
Accumulation error from TD update
target network 와 overestimation bias의 연관성을 보이고,
-> policy update를 지연시켜서 update당 error를 줄여 성능을 향상 시킨다.
TD3 얘기하는데 Actor-Critic, Q-Learning 얘기를 왜할까?

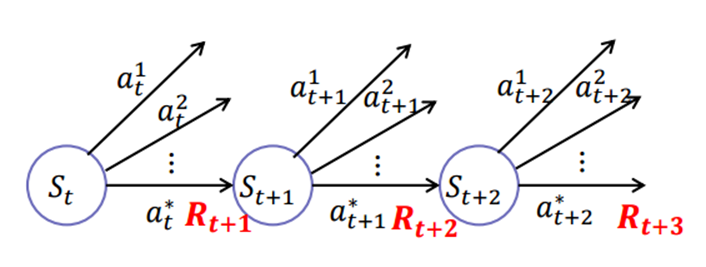
사실 이 얘기만 잘 풀어하면 논문 내용 전체를 다 봤다고 말해도 될거같다.
일단 보이는것처럼 TD3 자체는 Actor-Critic 구조를 갖는 알고리즘이다. Actor-Critic은 기본적으로 Actor, Critic을 동시에 학습한다.
사진처럼 Actor-Critic 구조는 연속적인 행동 공간에서 잘 작동하도록 설정된 반면 Q-Learning은 주로 discrete한 환경에서 사용된다.
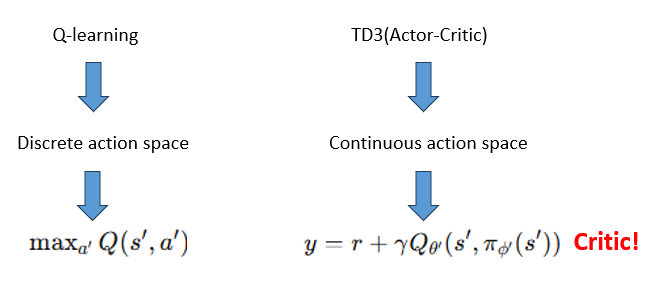
좀 더 자세히 얘기해보면 Q러닝은 위 사진처럼 max a프라임에 관한 큐값을 greedy하게 고르는 방식을 택하여 critic을 학습한다.
-> 이 과정에서 Overestimation Bias가 학습에 부정적인 영향을 미친다.
(왜냐고 하면 몇가지 이유가 있는데, Q러닝에서의 Q업데이트에서는 최대Q를 greedy하게 고른다. 그 때 미래의 상태에서 가장 큰 Q를 사용하는데,,, 이건 실제 값이 아니고 근사치이다. (근사치 Q값 오차가 첫 이유) 또 그 max값 이니까 노이즈나 오차가 더 커질 수 있음. max 연산 본질 자체로 Q값이 overestimated 되는 상황이 발생하게 됨.)
그런데 TD3의 Actor-Critic에서의 Critic도 큐러닝과 유사하게 TD 학습 규칙을 사용한다. 수식을 봐도 알 수 있듯이, 미래 값의 최대값에 대한 추정을 포함하고 있다.
이 논문에서 말하고 싶은게 여기 다 담겨있다..!
"Actor Critic 에서도 Overestimation Bias 문제가 발생하냐?" , "(발생한다면) 어떻게 문제를 해결 할 수 있을까?"
다른 TD방식을 쓰는 알고리즘도 많은데 큐러닝을 가지고 온 이유는, 큐러닝에 관한 연구에서 overestimation bias의 기원이 잘 밝혀졌기 때문이라고 하네요. wow
3. BackGround
논문 3장에서는 background 지식을 다루는데, 다른건 RL의 기본적인 내용들이라 생략하고 좀 짚고 가면 좋을것만 process 대로 정리 해봤다. (생략하는 내용들은 기본적인 강화학습 환경이나 목표, Q value 계산 식 등등)
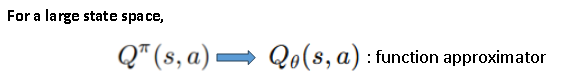
일단 큰 상태 공간에서 값을 estimate 할 때, 상태 공간이 너무 큰 경우 Q밸류를 바로 계산하는건 매우 비효율적이고 그렇기에 큐세타를 사용하여 값을 근사한다. (세타는 NeauralNetwork에서 가중치가 된다.) 이걸로 좀 더 복잡하고 큰 상태 공간에서 state-action 의 관계를 학습할 수 있도록 한다.

DQN에서는 TD Learning 방법으로 함수 큐세타를 학습하는데, 학습의 안정성을 높이기 위해 Q 세타 프라임 이라는 타겟 네트워크를 도입하여 학습과정에서 목표값y를 안정적으로 유지하도록 돕는다.
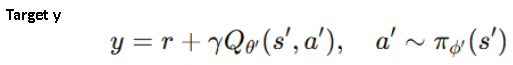
다음으로 Target y. 학습 목표값이고, 이 학습의 목표는 y로 표현되는 이 타겟 값과 현재의 예측값 Q세타 간의 차이를 줄이는 것이다. (프라임은 다음 이라는 의미)

마지막으로 Target Network 자체의 역할이다. 타겟 네트워크 Q세타프라임은 frozen된 상태로 네트워크 Q세타의 학습을 위한 기준으로 사용된다. 네트워크는 타겟 네트워크의 기존 파라미터도 일부 살려주고 새로 학습한 네트워크 세타도 일부 반영하며 업데이트 하는걸 볼 수 있다. -> DQN과 DDPG의 차이점으로도 설명이 가능. (DQN은 일정 주기마다 Q 네트워크의 학습된 세타를 타겟으로 카피해서 옮겨준다. DDPG에서는 이런식으로 비율을 두고 점진적으로 업데이트 했었죠.) + soft(slow)update 라고도 하는...

함수 근사를 통해 큰 상태 공간을 다룰 수 있고, 타겟 네트워크를 통해 학습을 안정되게 유지할 수 있다. 이러한 방법으로 값 추정의 정확성(accuracy of estimation)과 학습 효율성(learning efficiency)을 향상시킨다. 업데이트에서 과거의 데이터를 가져오고 또 reply buffer를 사용하니까 Off-Policy 라고 볼 수 있다.
4. Overestimation Bias
4장에서는 Overestimation Bias에 대해서 다룬다.
Discrete action을 사용하는 Q-Learning 에서는 Q value 추정 단계에서 다음과 같은 greedy target을 사용한다.
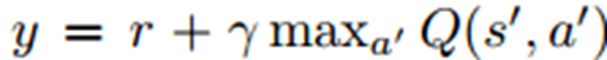
다만, 이러한 방식은 입실론(error)에 취약한 경우 error를 가지는 Q의 max값이 일반적인 true max값보다 크다는게 증명이 됐다.

(해당 논문 내용에서 나온 내용이다, 정리된 수식만 가지고 와봤다.)

그래서 이런 결과가 지속적인 overestimation bias를 만든다. 때문에 approximation을 계속 쓰면 이러한 overestimation은 불가피해진다. (이런 문제는 이미 많이 밝혀진 반면, Actor-Critic에서의 overestimation 발생에 관한 연구가 이전에 많이 없었다고 한다.)
만약 발생한다면?
-> Q-Learning에서 이를 줄이기 위해 사용했던 방식을 그대로 쓸 건지 아니면 더 좋은 다른 방식이 있냐? 에 대해 알아보자 가 해당 section에서 하고 싶었던 말이다.
4-1. Overestimation Bias in Actor-Critic
먼저
