1.오늘은 gan 모델보다 더 효과적으로 이미지 처리를 할 수 있는 딥러닝 모델에 대해 알아보고자 한다.
코넬 대학교의 논문을 참고 했으며, 아래는 논문을 다운 받을 수 있는 사이트이다.
또한, 코드도 볼 수 있다.
https://www.tensorflow.org/tutorials/generative/style_transfer?hl=ko
2.내용 정리
이미지 처리 작업에서 가장 강력한 심층 신경망 클래스는
cnn(Convolutional Neural Networks)이다.
cnn은 visual information을 계층적으로 처리하는 작은 계산 단위로 구성되어 있다.
각각의 층은 이미지 필터의 집합체로 되어 있다.
이런 필터들은 삽입된 이미지의 특징들을 추출해 낸다.
이런 과정을 거쳐서 나온 output은
이미지의 feature maps이라고 할 수 있다.
cnn이 대상을 인식하기 위해 train 된다면,
실제 이미지는 점점 그 이미지를 대표하는 데이터로 변한다.
이 과정에서, 우리는 단 단계에서의 데이터를 이미지로 즉시 시각화할 수 있다.
3.그림으로 하는 설명

필터가 더 많을수록 processing의 과정이 더 많아진다.
그리고 필터된 이미지는 사이즈가 downsampling 매커니즘에 따라 감소된다.
또한, input image는 그림의 필터들을 거쳐서 재구축된다.
그림을 봤을 때, 처음 몇 단계에서의 재구축은 거의 완벽함을 알 수 있다.
하지만, 단계가 갈 수록 디테일적인 부분에서 약간의 아쉬움이 있다.
이런 과정을 통해 크기를 조절하고, 특정 이미지의 스타일과 일치하는 이미지를 생성한다.
4.자, 이런 과정을 거쳐서 무엇을 할 수 있을까?
우리는 이미지의 특징을 포착해서 그 정보를 시각화 할 수 있는 것을 알았다.
그리고, 이를 통해 우리는 두 개의 서로 다른 소스 이미지의 콘텐츠와
스타일 표현을 혼합하는 이미지를 생성한다.
이 말이 뭔지 모르겠다고?
스크린샷을 보면 이해가 빠를 것이다.

그림 a에서, b로 바뀌었는데, b의 사이드에 있는 사진의 스타일대로 바뀐 것을 알 수 있다.
이런 식으로 바뀌는 것이다.
5.이렇게 이미지 변환을 잘 할 수 있는 방법은 무엇일까?
네트워크의 상위 계층까지 스타일 표현을 일치시킬 때, 이미지 구조는 점점
더 큰 규모로 일치되어서 더 부드럽고 더 정교하게 변한다.
그 결과로 가장 매력적인 이미지가 생성이 된다.
물론 100프로 완벽한 이미지가 생성되지는 않는다.
(두 그림의 조건을 완벽하게 일치시키는 이미지가 생성되기는 어렵다는 의미이다.)
6.하지만 방법은 있다.
이미지 합성 중에 손실함수를 잘 활용하면, 두 이미지를 합성하는데 있어서의 정확도를 올릴 수 있다.
7.방법 설명
들어가기 앞서,
이 사이트의 설명을 토대로 이해하고 글을 적었음을 밝힌다.(감사합니다! ^^)
우선, 이미지가 2개 있다고 치자.
그러면 2개의 거리를 정의한다.(dc,ds)
Dc: measures how different the content is between two images(두 그림이 얼마나 다른지 측정)
Ds: measures how different the style is between two images
(두 그림의 '스타일'이 얼마나 다른지 측정)
이렇게 2가지를 정의하고, 입력의 세번째 이미지를 가져와서 content image와 style image와의 dc와 ds를 최소화하도록 변환한다.
8.알고리즘 컨셉

위 그림을 풀어서 이야기하자면,
input image가 a와 얼머나 다른지 표현하는 loss function,
x와 b간의 style이 얼마나 다른지 표현하는 loss function을 최소화하는
x를 구현하는 것이다.
9.모델
모델은 vgg19를 사용한다.
물론 vgg를 사용한다는 이야기는 앞서 이야기했을 것이다.
하지만, vgg19는 vgg의 하나의 버전이라고 볼 수 있기 때문에,
자세하게 설명을 하겠다.
1.100만개가 넘는 이미지에 대해 훈련된 cnn
2.16개의 convolution layer, 5개의 pooling layer, 3개의 fully connected layer로 구성이 된다.
3.max pooling이 아닌 average pooling 사용
(average pooling이 학습이 잘되어서 쓴 듯 하다.)
10.알고리즘
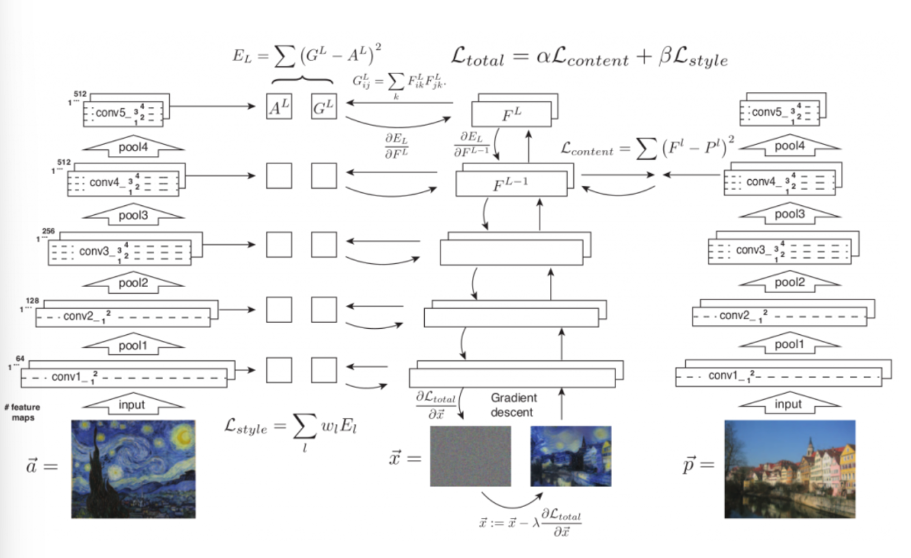

11.total loss
total loss는 다음과 같이 구성된다.
Total loss = Content loss + style loss
이 중에서 content loss에 가중치를 주면 컨텐츠 중심적인 이미지가 생성이 되고(스타일에 별 상관을 안한다는 의미.)
style loss에 가중치를 주면 스타일 중심적인 이미지가 생성이 된다.
아래 그림의 예시를 보면서 이해를 하면 이해가 빠를 것이다.

