PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS

Masked Language Model이 연산적으로 비효율적이기에, 연산적으로 효율성을 개선하고자한 2020 구글 논문입니다.
Introduction
우선 언어 모델이 어떻게 발전되어 왔는지 간략히 설명해보겠습니다.
가장 먼저 제안된 언어 모델은 '1) 통계적 statiscal 언어 모델' 입니다.
이는 데이터 셋에서 조건부 확률을 이용하여 각 토큰 뒤에 무엇이 따라 오는지에 대한 확률을 이용한 언어모델입니다. 이 방식에서는 독립된 모두 똑같은 단어로 취급합니다. 또한 어떤 훈련이 필요없이 데이터셋이 있으면 바로 확률을 구하는 것 입니다.
이를 발전시키고자 나온 것이 '2) 신경망 기반 언어모델' 입니다. 이는 각 토큰을 분산 표현을 통해 임베딩 시키고, 각 토큰들이 얼마나 유사한지도 반영시킵니다. 이렇게 섬세하게 표현된 고차원 벡터를 RNN같은 모델에 넣어 다음 단어를 예측하는 언어모델입니다.
이 다음으로 나온 것은 **3)
Introduction
Masked Language Model입니다. 이는 어떤 문장이 주어지면 이 문장의 일부분을 Masking하고, 이 masking된 부분을 맞추는 것을 통해 학습을 하는 언어모델입니다. 모델은 마스크를 중심으로 주변 단어들을 살피게 되는데, 이는 다시 말해 문맥을 이해할 수 있게 되는 것 입니다! 그렇기에 자연어처리에서 가장 많이 쓰이는 NLU(Natural Language Understanding 자연어 이해)task를 수행할 수 있게 됩니다. Masked Language Model의 대표 주자는 구글의 BERT와 OpenAI의 GPT-2가 있습니다. 이를 기반으로 엄청난 논문들이 쏟아져 나왔습니다.
하지만 모델의 크기가 너무 크고, 학습 데이터 또한 너무 많기에 필요한 가격이 굉장히 비싸다고 합니다.
* Cost
BERT : $6,912 / GPT-2 : $43,008 / XLNet : $61,440그렇기에 구글에서 본 논문인 ELECTRA를 내면서 연산 효율성을 개선시키는 방안을 제시합니다.(=> ELECTRA 학습 4일만에, GPT-2 학습 120일 연산량을 넘어섰습니다.)
Q. 그렇다면, 어떤 문제가 낭비적 연산을 불러일으키는가?
학습 데이터를 Masking시킨 후 이를 언어 모델이 예측하는데, 이를 통해 예측한 값과 정답 값 사이의 Loss를 구하게 됩니다. 여기서 문제가 생기는데, 하나의 example에 대해서 고작 15%만 loss가 발생하고, 이 15%만 학습을 진행하게 되기에 비효율적이라는 것 입니다.
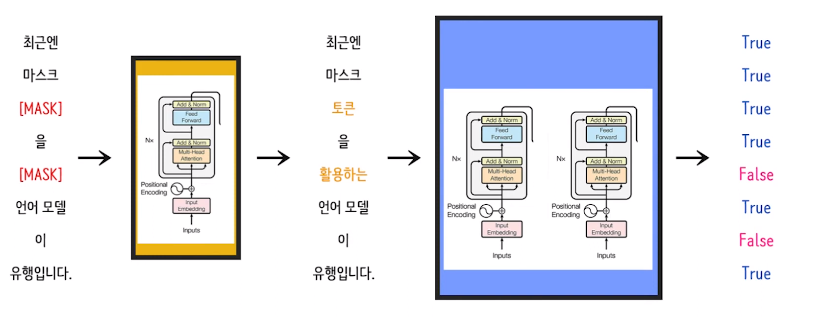
아래를 예시로 보시면, 2개의 토큰에 대해서만 학습이 진행되기에 전체 데이터중 두 단어밖에 학습할 수 없다는 것 입니다. 이렇게 적은 양만 학습한다면, 데이터를 더 모아야 하고, 데이터셋의 크기가 더 커지기에 비용이 많이 들 수 밖에 없다는 것이 논문에서 해결하고자 하는 문제점입니다.
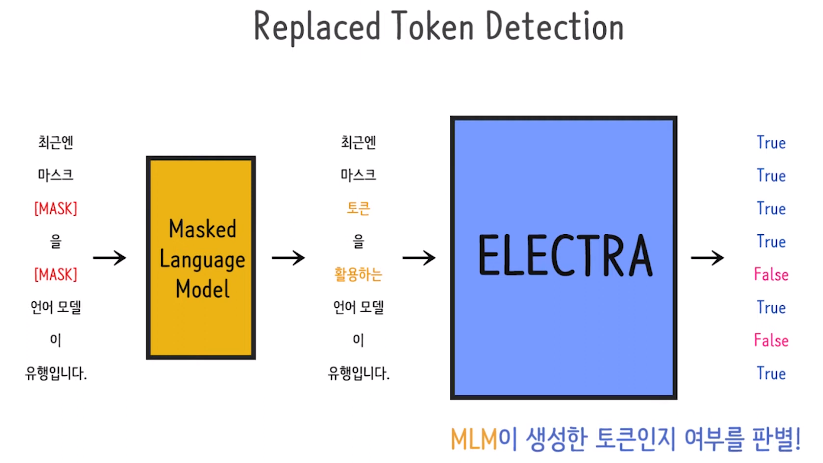
이를 "Replaced Token Detection(RTD)" 을 통해 개선시키고, 이 개념으로 training한 것이 "ELECTRA" 입니다!
MLM을 통해 생성한 가짜 토큰인지 원본 토큰인지 여부를 판단하는 이진분류를 실시하게 합니다.
여부를 판단하기 위해 이는 모든 토큰을 살펴야 하고, 각 토큰을 볼 때마다 주변 문맥을 다 봐야하기에 MLM이 학습하듯이 문맥을 학습하게 됩니다. 이렇게 모든 토큰에 대해 이진 분류를 진행하는데, 여기서 모든 토큰에 대한 loss를 구하기에 모든 토큰을 학습하는 효과가 있게 되는 것 입니다.
Method
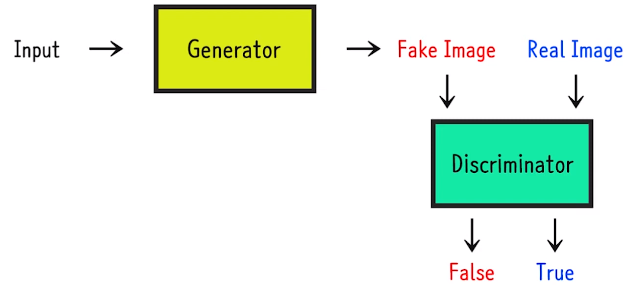
ELECTRA의 구조는 generator G와 discriminator D가 존재하며 GAN과 비슷합니다.
"GAN : Generative Adversarial Networks"
GAN의 Generator는 랜덤 이미지를 받고 이를 Real image와 비슷하게 Fake image를생성해 냅니다.
GAN의 Discriminator는 받은 image가 Rela인지, 생성자가 만든 Fake인지 판단합니다.
: 이는 서로의 실수를 유발시키며, 적대적으로 동작하며 학습하기에 Adversarial Network라고 합니다.
"ELECTRA"
그렇다면 ELECTRA를 한번 살펴보겠습니다. 아래와 같은데 이는 GAN과 유사하지만 GAN이라고 부를 수는 없습니다. 가짜 문장을 MLM이 만들고, 이를 ELECTRA가 T/F로 이진분류를 실시하긴 하지만, 가짜 문장을 True라고 했다고 MLM이 받는 보상은 없기 때문입니다. MLM은 ELETRA가 T/F 아무거나 판단해도 상관없이 그냥 문장을 잘 만들고자 하는 것 입니다. 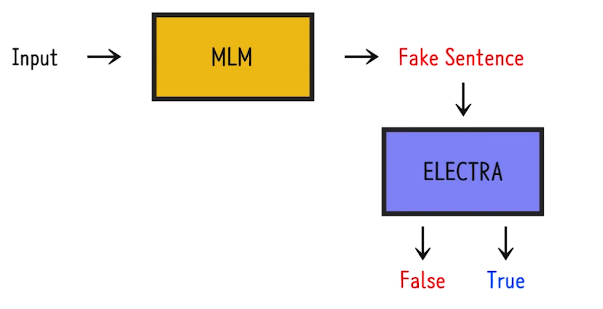
즉, GAN과 목적 자체가 다릅니다!
Likelihood Maximize
: GAN의 생성자의 목적은 판별자가 틀리도록 하는 것 이지만, ELETRA의 MLM은 기존의 BERT와 똑같은 loss를 사용하가에 문맥적으로 말이 되게 좋은 문장을 만드는 것이 목표입니다!또한 text GAN에 적용시킬 수가 없는데, 그 이유로는 GAN의 이미지 생성은 '95% 강아지', '100% 강아지' 와 같이 측정할 수 있지만, text는 다음 단어를 결정할 때 현재 상황에서 가장 적합한 단어를 '선택'하는 것이기 때문입니다.(95%의 강아지 단어는 없습니다)
다시 말해, Generator는 discriminator를 속이기 위해 adversarial하게 학습하는 것이 아니고, maximum likelihood로 학습합니다. (현재 상황에서 다음 단어를 예측하는 확률분포에서 가장 높은 확률을 갖는 단어를 '선택'하는 것 입니다.) Generator에서 샘플링하는 과정 때문에 gradient가 끊어지고 backpro를 하지 않기에 GAN에 적용할 수 없는 것 입니다.
대략적인 틀을 잡았으면, 본격적으로 수식과 함께 설명하겠습니다.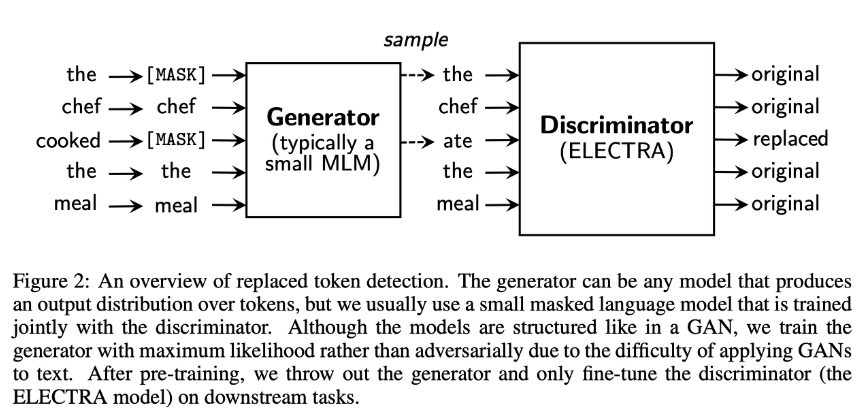
본 논문의 approach는 위에서 말한 generator G와 discriminator D를 train하는 것 입니다. 각 네트워크는 Transformer Encoder로 구성되어 있고, 시퀀스 x=[x1,x2,...,xn]을 입력으로 받아 문맥 정보를 반영한 벡터 시퀀스 h(x)=[h1,h2,...hn]으로 매핑시킵니다.
- Generator
생성자는 BERT의 MLM과 동일합니다.
1) 입력 시퀀스 x=[x1,x2,...,xn]에 대해 마스킹할 위치의 집합 m=[m1,...mk]을 결정합니다.(보통 k=0.15n, 즉 전체 토큰의 15% mask-out)
2) 결정한 위치에 있는 토큰을 [MASK]로 치환합니다.(x_masked=REPLACE(x,m,[MASK]))
3) 이렇게 마스킹된 x_masked에 대해 주어진 위치 t에 대하여 어떤 토큰 x_t를 생성할 확률을 output으로 리턴합니다. 이렇게 G는 원래 토큰이 무엇인지 예측하여 생성하는데, 이 생성된 토큰을 x_corrupted라고 표기하고 판별자에게 넘기게 됩니다.
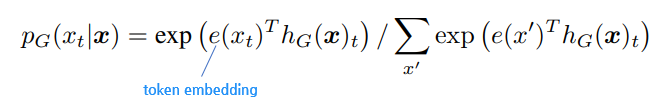
- Discriminator
판별자는 생성자가 만들어낸 토큰 시퀀스에 대해 각 토큰이 original인지 replace인지 이진 분류를 수행합니다.
1) generator로 masked-out된 토큰들을 처리한 x_corrupt를 받습니다.
2) 판별자가 x_corrupt의 어떤 토큰이 original input과 match되는지 예측하도록 학습시킵니다.(이진분류)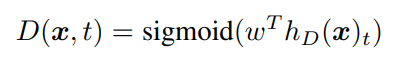
- Loss function
최종적으로 ELECTRA는 대용량 코퍼스 x에 대해 G loss와 D loss의 합을 최소화 하도록 학습시킵니다. 이 때, 람다는 50을 사용했으며, 이 파라미터는 binary classificaion인 D loss와 30000 class 분류인 G loss의 스케일을 맞추는 역할을 합니다. G의 sampling 과정이 있기에 D loss는 G로 역전파되지 않고, 위 구조로 pre-training을 마친 뒤 G는 버리고 D만 취해서 downstream task로 fine-tuning을 진행하게 됩니다.
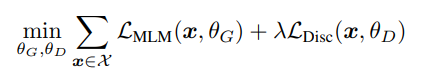
Generator : Maximum likelihood
Discriminator : cross entropy이렇게 사전학습이 완료되면, 각 downstream task에 맞게 fine-tuning을 진행하게 됩니다. 여기서는 Generator는 그대로 두고, Discriminator만 특정 task에 맞게 학습을 진행합니다!
왜 판별자만?!?
Generator는 이미 대규모 말뭉치로부터 많은 텍스트의 패턴과 통계를 학습했습니다. 그러나 Discriminator는 지도 학습이 아니라 단순히 텍스트가 실제인지 가짜인지 판별하는 것으로 학습되었기 때문에 추가적인 특정 task를 수행하기 위해 fine-tuning을 실시하게 되는 것 입니다!=> Generator를 그대로 두고 Discriminator만 fine-tuning하는 것으로 인해 ELECTRA는 더 적은 파라미터로도 높은 성능을 달성할 수 있습니다. 또한, Generator와 Discriminator의 구분을 통해 pretraining과 fine-tuning 단계의 목적을 분리함으로써, 각 단계가 효과적으로 수행되도록 하는 것이 가능해집니다. 이러한 효율적인 fine-tuning 접근 방식(+아래에서 언급할 weight sharing)은 ELECTRA의 성공적인 학습과 결과에 기여한 핵심적인 아이디어입니다.
예시를 하나 들어보겠습니다 : 영화리뷰 task fine-tuning
사전학습(pretraining) 단계에서 Discriminator의 목적은 Generator가 생성한 토큰인지 아닌지를 판별하는 것입니다. 이때 사용되는 목적함수는 각 토큰에 대해 이진 분류(Binary Classification)를 수행하는데, 일반적으로 Binary Cross Entropy(이진 교차 엔트로피)를 사용합니다.하지만 영화 리뷰 분류와 같은 특정 downstream task에 대한 fine-tuning 단계에서는 목적이 달라집니다. 이때의 목적은 전체 문장에 대한 이진 분류로 바뀝니다. Discriminator는 fine-tuning 단계에서 영화 리뷰 텍스트를 입력으로 받아서 해당 리뷰가 긍정적인지 부정적인지를 판별하는 문제로 학습됩니다.
따라서 fine-tuning 시에는 Generator를 그대로 두고, Discriminator만 특정 downstream task에 맞게 학습된 데이터를 사용하여 문장 전체에 대한 이진 분류를 수행하도록 조정됩니다. 이때 사용되는 목적함수는 fine-tuning에 맞게 영화 리뷰의 전체 문장에 대한 이진 교차 엔트로피가 될 것입니다.
이렇게 사전학습과 fine-tuning 단계에서 각각의 목적에 맞게 Generator와 Discriminator가 활용되는데, 이것이 ELECTRA의 효과적인 학습 방법을 이루는 중요한 요소 중 하나입니다.
모델 아키텍쳐
아래와 같이 표현할 수 있는데, MLM은 Transformer 인코더 1개를 사용하고 ELECTRA는 Transformer 인코더 2개를 사용하였습니다.(일반적으로 MLM이 ELECTRA보다 인코더 개수가 적었을 때 성능이 좋았다고 합니다)
실험 중 하나를 소개하겠습니다.
Weight Sharing
말 그대로, MLM의 가중치와 ELECTRA의 가중치를 공유하는 것 입니다.
파라미터 수가 너무 많다보니, 파라미터 자체를 줄이는 것 만으로도 normalization되는 효과가 있고, global minimum에 수렴하는 속도가 빠른 효과가 있습니다.
하지만 이는 ELECTRA에는 적합하지 않았는데, 이를 실행하기 위해서는 MLM의 크기와 ELECTRA의 크기를 똑같이 맞춰줘야 하기에 인코더를 2개씩 써야 했기 때문입니다. 이는말이 2개인 것이지, 사실상 하나가 버트정도의 크기라고 생각한다면 버트의 두 배가 되는 것 입니다. 따라서 이를 개선할 방안을 생각해냈는데, 그것이 바로 임베딩만 sharing하는 것 입니다.
Weight Sharing(Only Embedding share)
일반적으로 임베딩을 정의할 때, 데이터셋을 기반으로 tokenize를 다 하고 단어장vocab을 구성하고, 임베딩을 구성합니다. 그렇기에 데이터셋의 모든 단어에 대해 공평하게 임베딩하는 기회는 MLM밖에 없습니다. 예를 들어 MLM에서 학습해서 나온 값이 어떤 단어가 마음에 안들어서 생성을 하나도 하지 않았다면 electra는 그 단어를 튜닝할 수 없기에 임베딩이 편향적으로 될 수 있습니다.즉, generator에 의존적으로 되는 것입니다. 그렇기에 임베딩층을 sharing 해주는 것이 효율이 좋았고, 이를 통해 모델의 크기는 조절할 수 있게 변경한 것 입니다.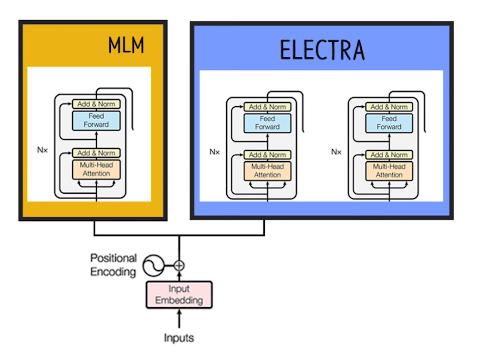
모델 사이즈
이제 모델의 크기를 조절할 수 있게 되었습니다!
Q. 그렇다면 어느 정도 크기로 구성할 때 가장 우수할까요?
아래의 그림을 보시면, 판별자 모델의 크기에 따른 생성자 사이즈별 성능입니다.
판별자가 768사이즈를 가질 때 생성자는 256에서 가장 우수한 성능을 보였고,
판별자가 512면 생성자는 256,
판별자가 256이면 생성자는 64, 의 성능을 보이며 판별자 크기의 약 1/4~1/2 사이일 때 좋은 성능을 나타냄을 확인할 수 있습니다.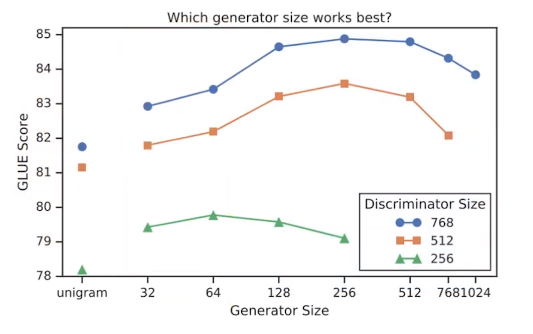
모델의 훈련
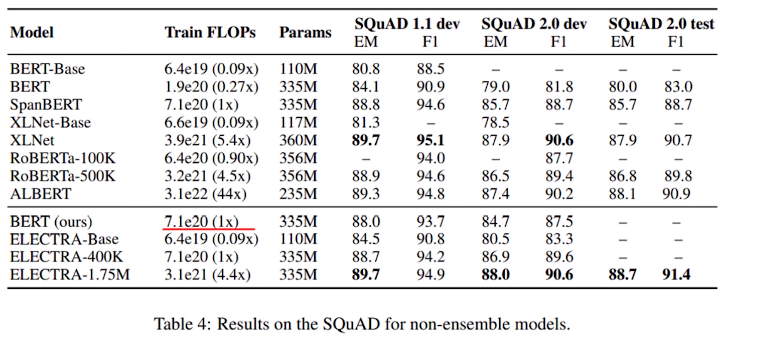
아래의 표는 모델을 훈련을 시키고 각 데이터셋에 대한 평가를 확인한 것 입니다.
맨 아래의 ELECTRA를 확인해보면, 하나의 데이터셋 빼고(이것도 0.2만 차이) 모두 가장 우수한 성능을 보임을 알 수 있습니다. 물론 드라마틱하게 우수한 성능을 띄지는 않지만 조금이라고 성능을 높였다는 점과 연산량을 줄일 수 있다는 점을 고려한다면 꽤나 괜찮은 모델임을 알 수 있습니다.
Conclusion
본 논문은 기존의 연산 비효율성을 지적하고, language representation learning을 위한 새로운 self-supervision task인 Replaced Token Detection(RTD)을 제안했습니다. 또한 임베딩만 공유하고, 생성자와 판별자의 크기를 조정하며 성능 개선과 함께 최적의 효율적 모델을 구상함을 볼 수 있었습니다.
본 논문의 저자는 이 효율적인 모델을 통해 많은 연구자들이 적은 컴퓨팅 리소스로도 언어모델의 사전학습에 대한 많은 연구 및 개발을 할 수 있길 바람을 남겼습니다.
참고 : https://www.youtube.com/watch?v=ayVS904xQpQ
https://aboutnlp.tistory.com/29
