Generative Model VS Discriminative Model
주로 머신러닝은 이 두 모델의 학습방법으로 구분된다.
이 포스터의 요점은 두 모델의 학습방법 차이점은 무엇이며, 각각은 새로운 데이터가 들어왔을 때 어떻게 구별하는가에 대해 다뤄보겠다.
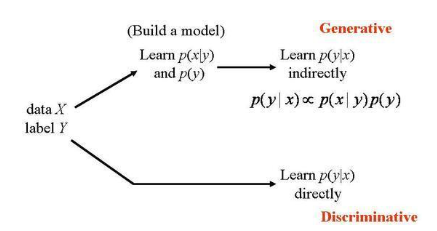
이 두 모델은 Pattern recognition에서 classification의 경우에 정의를 한다.
위에서 보는 것과 같이 새로운 X 데이터가 들어올 때 어느 Y 클래스로 분류될 가능성이 큰지를 확인하는 것이다.
즉, Generative Model이나 Discriminative Model을 써서 decision boundary를 구하고, 이를 통해 classification을 하자!
Generative Model
Generative Model은 각각의 클래스의 "분포도" 를 사용한다.
아래와 같은 경우 녹색과 노란색을 어떻게 구분할까?

Generative Model은 이를 확률 분포도를 이용하여 두 클래스를 구분한다.(가우시안 분포로 가정하겠다.)
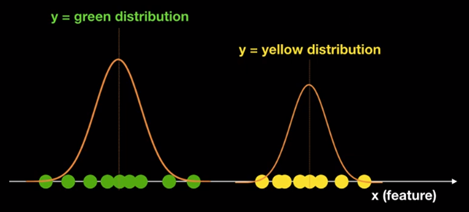 (And now, model can know p(x|y=green), p(x|y=yellow))
(And now, model can know p(x|y=green), p(x|y=yellow))
이렇게 두 클래스를 구분한 후 새로운 데이터가 들어왔을 때, 새로운 데이터는 두 분포 중 어디에 속할지 쉽게 확인할 수 있다!
아래와 같이 빨간 데이터가 들어온다고 했을 때, 이는 초록색으로 classify할 수 있는 것이다.
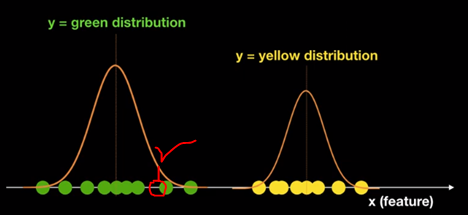
그렇기에 추가로 말하자면, Generative Model은 위와 같이 분포를 사용하기에 새로운 sample dataset 또한 생성해낼 수 있는 model이다.
decision boundary를 구축하기 위해 likelihood나 posterior probability가 사용된다. 이와 관련한 내용은 너무 들어가는 것이 아닌가 싶지만, 다음 포스터에 설명해보겠다!
Discriminative Model
Discriminative Model은 클래스들이 있을 때 클래스 간의 피쳐들 사이에서 "다른 점" 을 확인하고, 이를 통해 각 클래스가 어떻게 다른 가에 대하여 초점을 맞춘다.
다시 아래와 같은 예시를 가져왔을 때, 그림과 같이 빨간 decision boundary를 통해 클래스를 구별하고 새로운 분홍 데이터에 대해 적용시킨다.

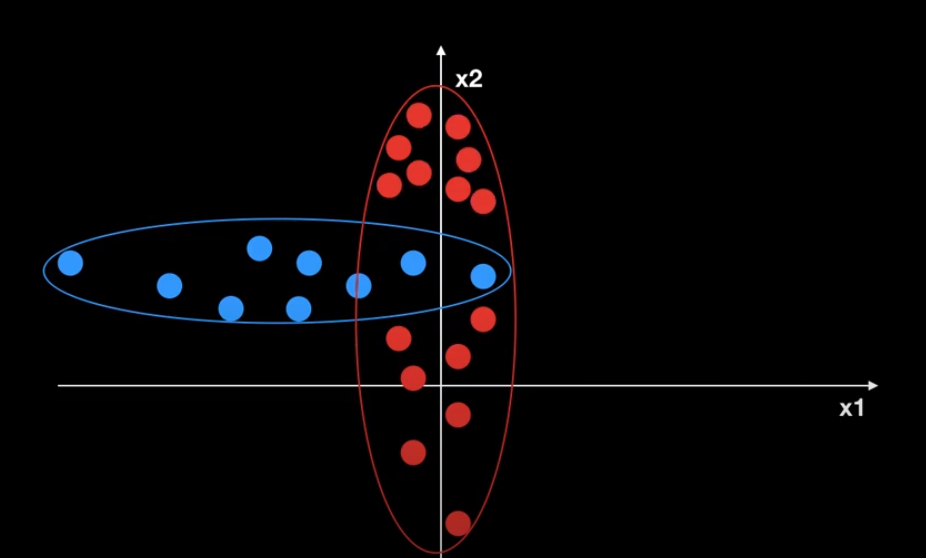
하지만 Discriminative model은 아래와 같은 단점이 있다.
만약 아래 그림과 같은 샘플(학습) 데이터 분포가 있을 때, 어떻게 구별할 것인가?
Discriminative model은 위의 두 빨간 데이터를 outlier로 판단해버리고 decision boundary를 그을 것이다.
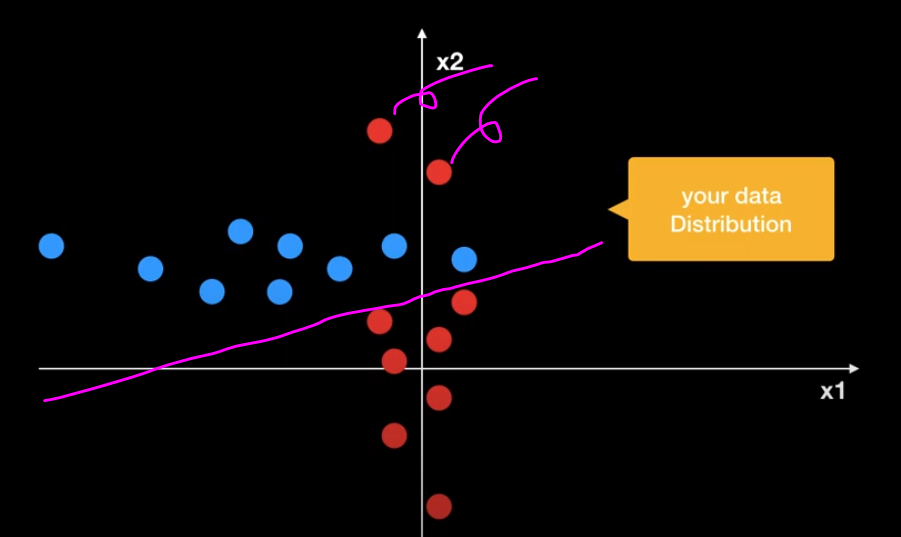
But 실제 데이터는 아래와 같은 경우라면?!
=> 위의 데이터들을 모두 파란색으로 구분하여 좋은 성능을 발휘하지 못 하게 된다.
이러한 경우에는 Generative Model을 사용하는 것이 효율적일 것이다.
- 지금까지 너무 Discriminative model의 단점만 말한 것 같은데, 미안하니 Generative model의 단점도 살펴보자:)
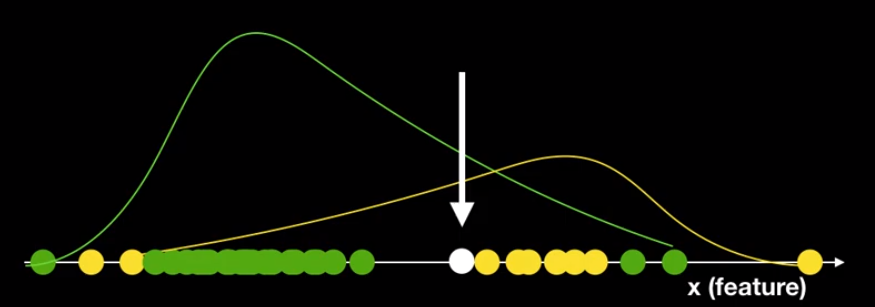
만약 아래와 같은 데이터들이 있을 때, 흰 데이터가 새로 들어온다면 어떤 클래스로 구분해야 할까?
일반적으로는 노란색으로 구별하겠지만, Generative model의 경우 분포도를 살피기에 이를 녹색 클래스로 구분할 확률이 크다.
이러한 1차원적인 쉽게 구별할 수 있는 데이터는 Discriminative model을 사용하는 것이 효율적인 것이다.
정리
- Generative model(Gaussian Mixture Model(GMM))
각 클래스의 분포에 주목하여 어떤 분포에 들어갈 가능성이 큰가에 따라 classify하는 모델이다.
데이터가 많을 수록 효율적인 분포를 찾아 클래스를 잘 구별할 수 있지만, 여러가지 확률값을 알아야 하기에 연산량이 많다.- Discriminative model(Logistic regression, Neural Networks,..)
각 클래스의 차이에 주목하여 바로바로 어떤 클래스에 들어가야 하는 지 결정하는 모델이다.
작은 모델로도 잘 작동하고 연산량도 작지만, 오버피팅을 조심해야 한다.
참고 정리
generative training과 discriminative training은 자연어 처리 및 기계 학습 분야에서 각각 다른 목적과 방식으로 사용된다.
Generative Training (생성적인 학습)
- 목적: 데이터의 분포를 모델링하고 새로운 데이터를 생성하기 위해 사용됩니다.
- 활용 예시
1) 언어 모델: 주어진 문맥에서 다음 단어 또는 문장을 생성합니다.
2) 텍스트 생성: 소설, 시, 기사 등과 같은 텍스트를 생성합니다.
3) 음악 생성: 새로운 음악을 생성합니다.
4) 이미지 생성: 새로운 이미지를 생성합니다.
Discriminative Training (판별적인 학습)
- 목적: 입력 데이터와 해당 데이터의 레이블 간의 조건부 확률을 모델링하여 분류, 예측 또는 판별 작업에 사용됩니다.
- 활용 예시
1) 분류 문제: 이미지를 특정 클래스로 분류합니다.
2) 개체명 인식: 주어진 텍스트에서 특정 유형의 개체를 인식합니다.
3) 감성 분석: 문장의 감정(긍정, 부정)을 분석합니다.
4) 의도 파악: 주어진 문장의 의도(질문, 명령, 요구 등)를 파악합니다.
주로 generative training은 생성 모델에 사용되며, 데이터 분포를 모델링하여 새로운 데이터를 생성하는 데 중점을 둔다. discriminative training은 구분 모델에 사용되며, 입력과 출력 간의 조건부 확률을 모델링하여 분류, 예측 또는 판별 작업에 사용된다.
물론, 이 두 가지 방법은 서로 상호 보완적이기도 한다. 예를 들어, 생성 모델을 통해 생성된 데이터를 사용하여 구분 모델을 훈련시키는 경우가 있다. 또는 구분 모델을 사용하여 생성 모델의 결과를 평가하거나 보정하는 데에 활용할 수도 있다.
따라서 문제의 성격과 목적에 따라 generative training과 discriminative training을 유연하게 조합하여 사용한다고 생각하면 된다는 것을 말하며 이 포스터를 마치겠다.
++ 다음 포스터 내용으로는 posterior과 bayesian에 대해 말해보겠다:)
참고 : https://sens.tistory.com/408
https://www.youtube.com/watch?v=6F4zxCN0Wtc
