6.2 인덱스의 내부 작동
균형 트리
균형 트리
나무를 거꾸로 표현한 자료 구조
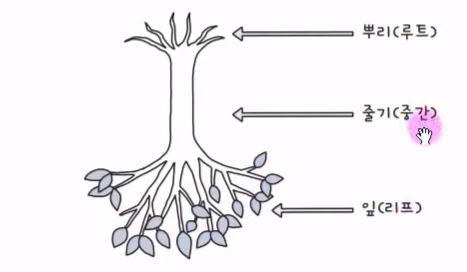
(균형 트리 - 혼공SQL 교재)
균형 트리 구조에서 데이터가 저장되는 공간을 노드(페이지)라고 한다.
루트 노드(페이지)는 노드의 가장 상위 노드를 뜻 하고, 모든 출발은 루트 노드에서 시작이 된다.
리프 노드(페이지)는 제일 마지막에 존재하는 노드를 말한다.
이 둘 사이에 끼인 노드들은 중간 노드라고 말한다.
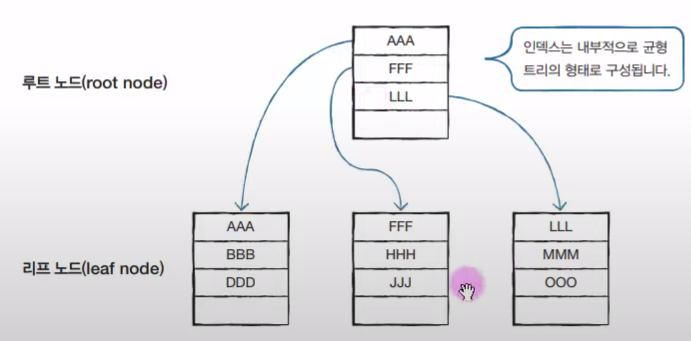
(노드 - 혼공SQL 교재)
인덱스가 없다면, 데이터를 처음부터 끝까지 검색해야 한다.(Full table scan)
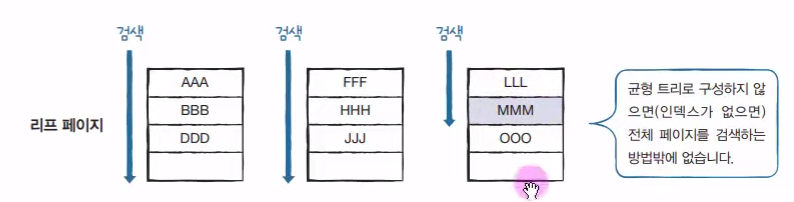
(페이지 스캔 - 혼공SQL 교재)
: MMM을 찾기 위해서 3 페이지를 뒤져야 한다.(데이터 몇 개를 읽었다기 보다는, 몇 개의 페이지를 읽었느냐로 효율성을 판단) 만약 천만 페이지가 있다면 엄청난 시간이 소요될 것
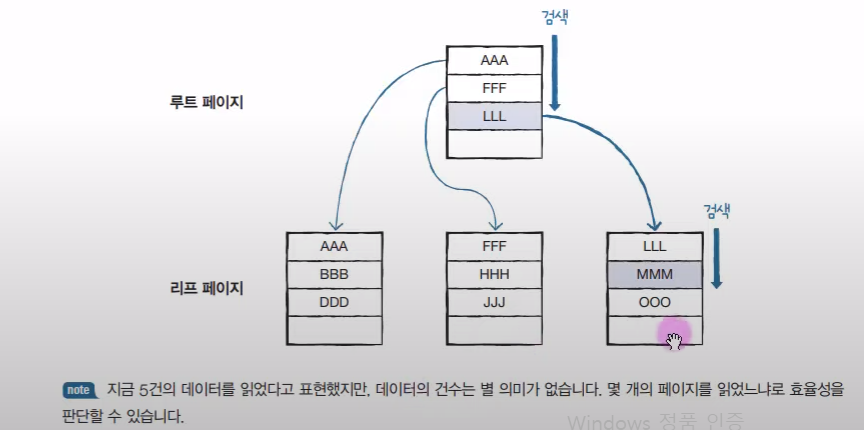
인덱스를 구성해서 효율적으로 만든다!
2 페이지를 읽음으로 효율성을 늘렸다!
균형 트리의 페이지 분할
앞서 데이터를 검색하는 데 균형 트리가 더 효율적임을 확인해 볼 수 있었다.
인덱스를 만들면 SELECT의 속도를 향상시킬 수 있다.
BUT! 인덱스를 구성하면 데이터 변경 작업(INSERT, UPDATE, DELETE) 시 성능이 나빠진다. 특히 INSERT작업이 일어날 때 더 느리게 입력되는데, 이러한 이유는 페이지 분할이라는 작업이 발생하기 때문이다. 페이지 분할이란 새로운 페이지를 준비해서 데이터를 나누는 작업을 의미하는데, 페이지 분할이 일어나면 MySQL이 느려지고, 너무 자주 일어나면 성능에 큰 영향을 주기 때문이다.
아래 그림에서 III가 삽입된다고 가정하면 JJJ를 한 칸 내리고 III를 삽입한다. 이는 큰 무리가 되지 않는다. 하지만 만약 GGG를 입력한다면??
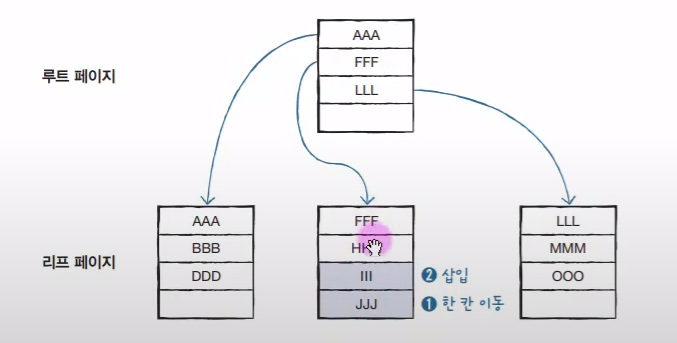
(페이지 분할 - 혼공SQL 교재)
-> 우선 페이지에 입력할 수 있는 칸이 없다. 그렇기에 여기서 페이지 분할이 일어난다.
새로운 페이지를 준비하고 데이터를 적당히 나눠서 작업을 실시한다.
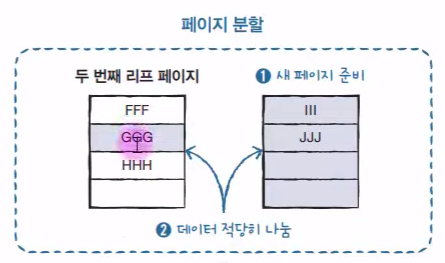
이를 실행한 결과 아래이다. 여기서 III를 새로운 페이지의 머리로 할당했기에 루트 페이지에 III를 루트에 등록해야 한다.
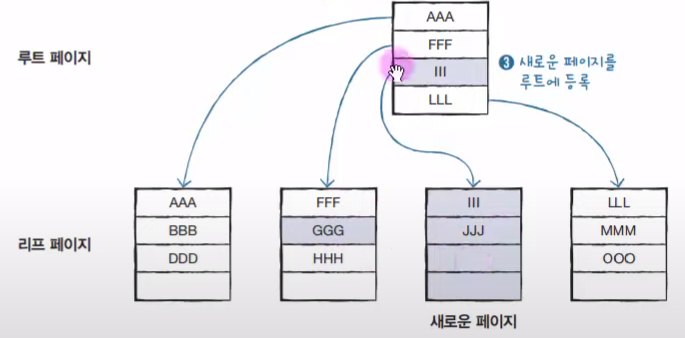
이러한 상황 때문에 속도가 굉장히 느려진다.
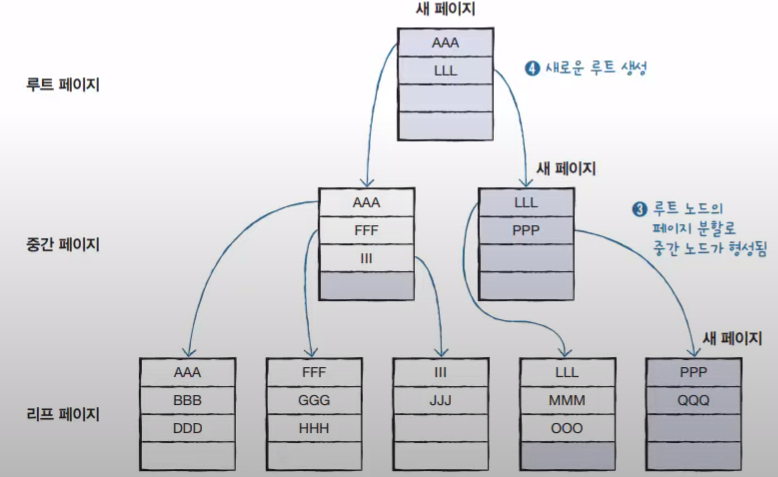
이제 슬슬 감이 온다. 여기서 만약에 또 추가로 들어온다면?!
아래 그림과 같이 우선 PPP가 입력되고, 추가로 QQQ가 들어오는 상황을 가정한다면, 또 새로운 페이지가 만들어져야 한다.
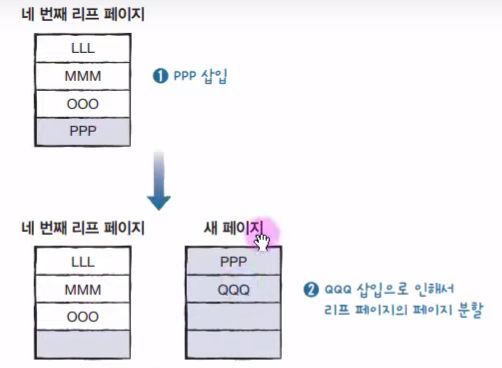
그렇게 된다면, 루트 노드는 새로운 페이지 분할로 인해 PPP를 받아야 한다.
하지만!! 여기서 또 칸이 없기에 루트 노드는 페이지 분할을 하게 되고, 새로운 중간 페이지가 생기게 되는 것이다. 또 추가로 이를 받을 상위 루트 노드가 생성된다.
하나의 데이터를 넣기 위해서 페이지 분할이 세 번이나 일어나는 것이다..!
인덱스의 구조
-
인덱스
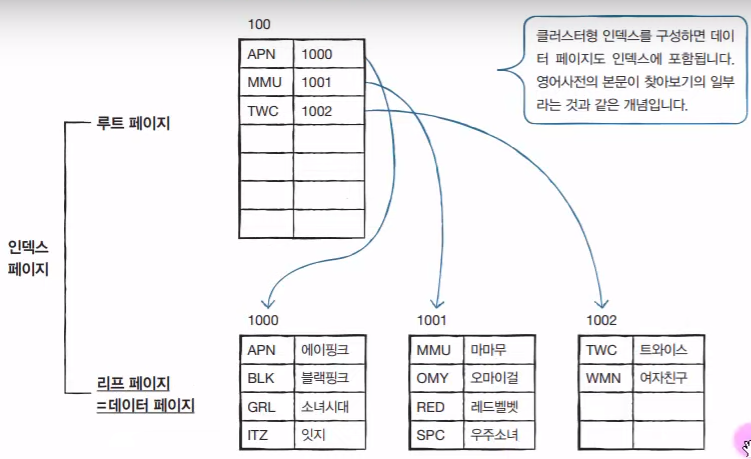
클러스터형 인덱스
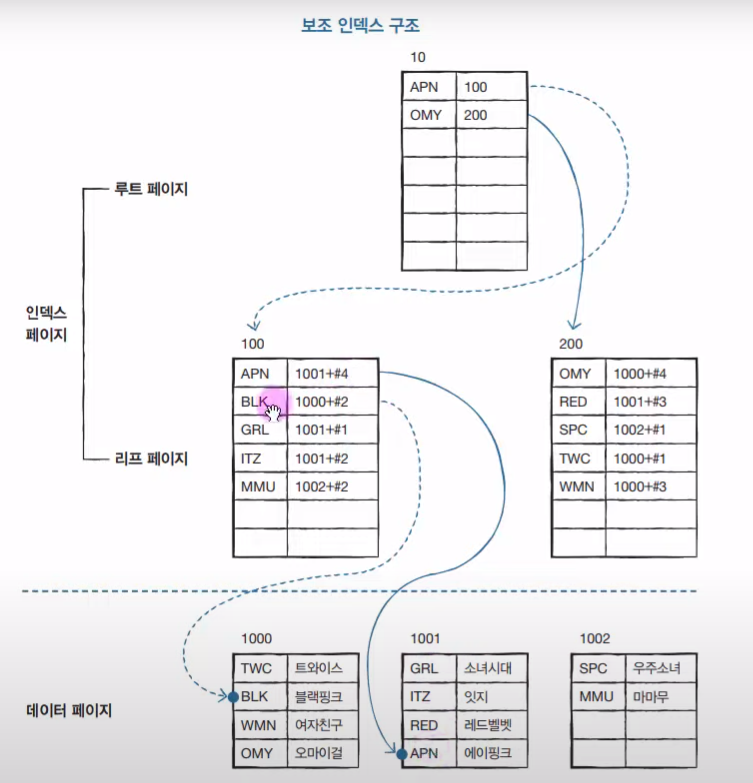
보조 인덱스 -
둘 다 빠른데 누가 더 빠를까?
1) 클러스터형 인덱스
클러스터형 인덱스 : PRIAMRY KEY
로 지정하면 알파벳 순으로 정렬이 된다. (영어사전과 같이)
2) 보조 인덱스
보조 인덱스 : UNIQUE
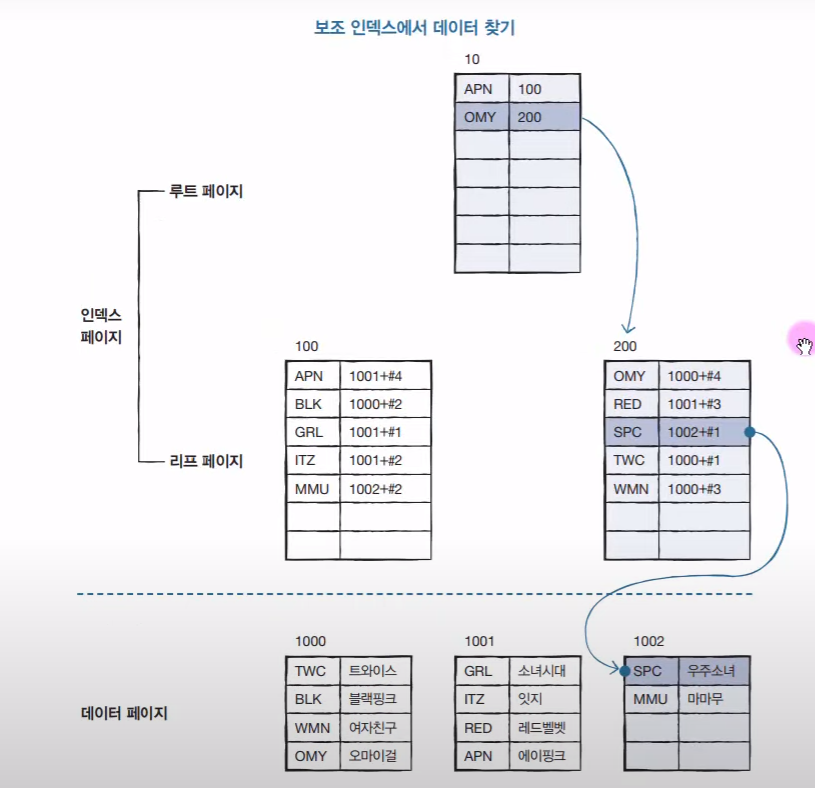
책 뒤에 찾아보기가 따로 만들어진다.
데이터 페이지에 있는 데이터들은 순서가 바뀌지 않고 입력한 그대로 있는다. 하지만 찾아보기 페이지에서는 정렬이 된다. (#은 몇 번째 인지)
- 데이터를 검색할 때 어떤 인덱스가 더 효율적일까?
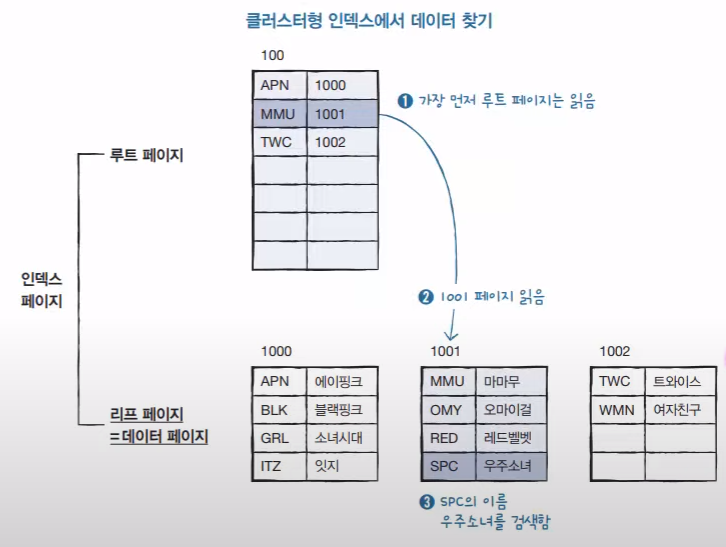
1) 클러스터형 인덱스
클러스터형 인덱스 : PRIAMRY KEY
로 지정하면 알파벳 순으로 정렬이 된다. (영어사전과 같이)
SELECT * FROM table_name
WHRER 'id'='SPC'SPC 가 해당되는 이름이 무엇인지 알아내기 위해 2 페이지를 읽어냈다.
(페이지 검색 - 혼공SQL 교재)
2) 보조 인덱스
보조 인덱스 : UNIQUE
책 뒤에 찾아보기가 따로 만들어진다.
데이터 페이지에 있는 데이터들은 순서가 바뀌지 않고 입력한 그대로 있는다. 하지만 찾아보기 페이지에서는 정렬이 된다. (#은 몇 번째 인지)
SPC 가 해당되는 이름이 무엇인지 알아내기 위해 3 페이지를 읽어냈다.
둘 다 빠르긴 한데 따라서 클러스터형 인덱스가 검색에서 더 효율적임을 확인할 수 있었다!!!
