















참고
-
object detection에서 최초로 one stage detection 방식을 제안
-
what is object detection?
object classification
: 이미지 내 single object, object class, output:class probability
-> object localization
: 이미지 내 single object, object class, bounding box(물체의 위치), output:(x,y,w,h)
-> object detection
: 이미지 내 multiple object, object class, bounding box, output:class probabilities+(x,y,w,h) 또 다른 객체가 있다면 그 class probabilities+(x,y,w,h)

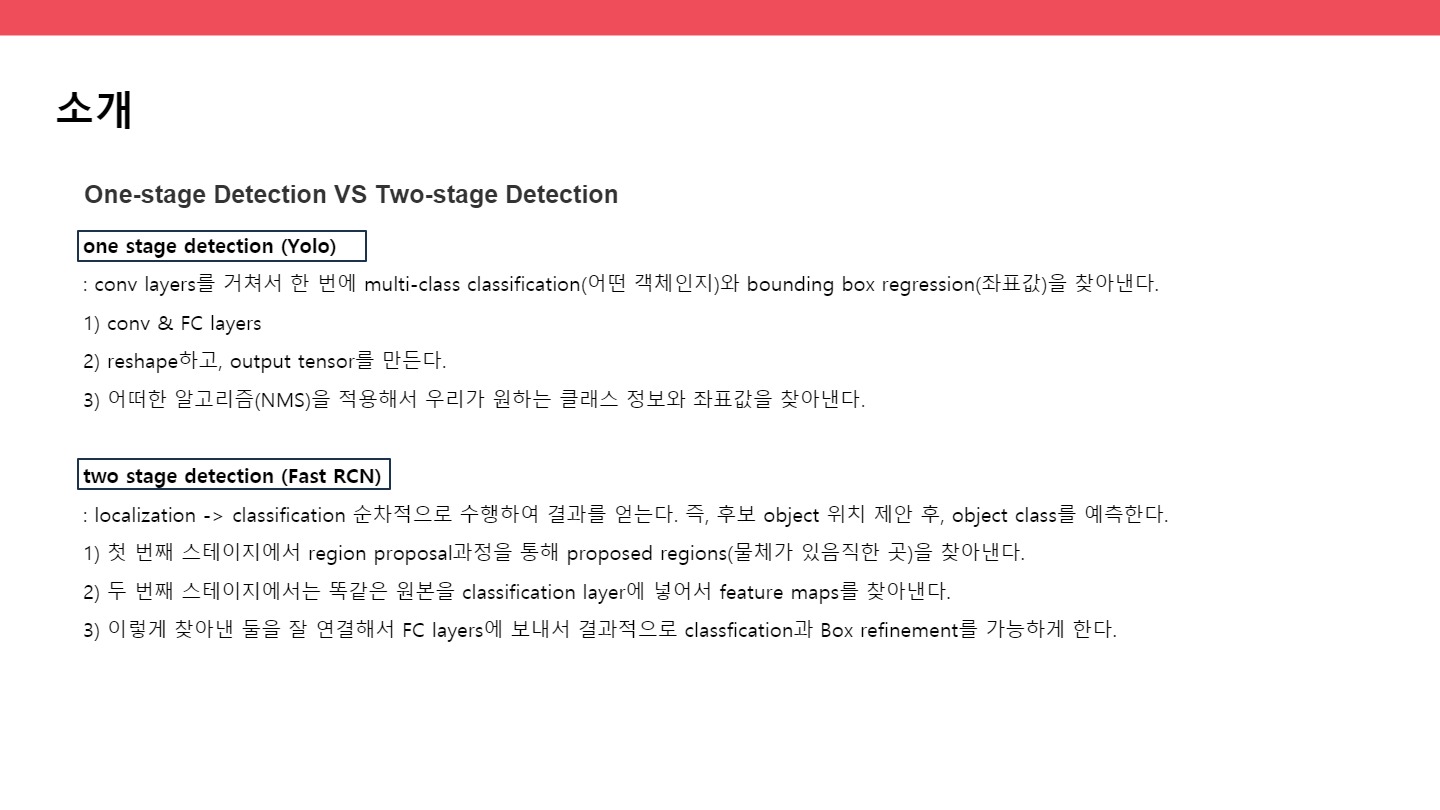
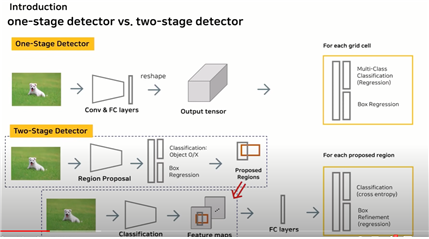
● one stage detection vs two stage detection
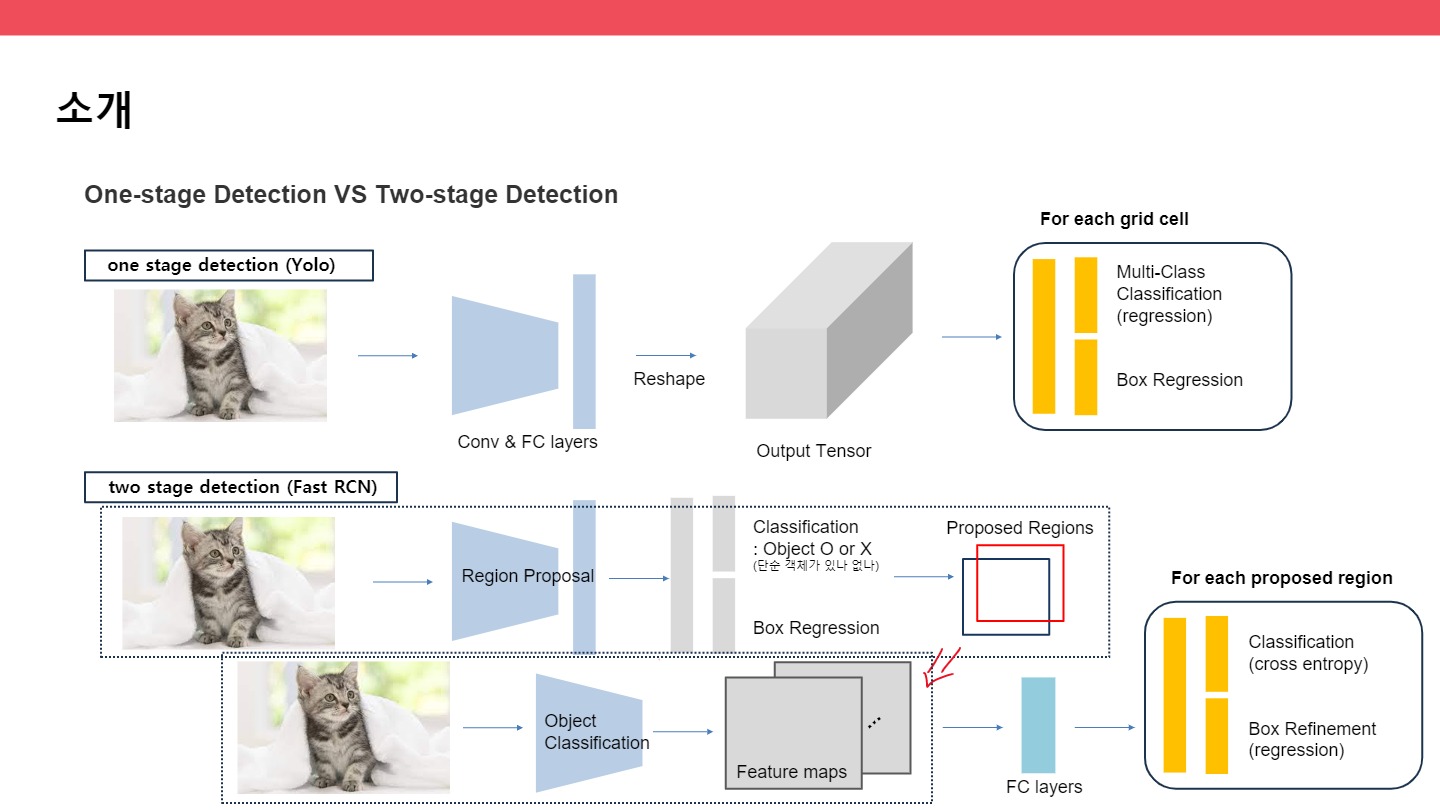
one stage detection (Yolov1) : conv layers를 거쳐서 한 번에 multi-class classification(어떤 객체인지)와 bounding box regression(좌표값)을 찾아낸다.
1) conv & FC layers 2) reshape하고, output tensor를 만든다. 3) 어떠한 알고리즘을 적용해서 우리가 원하는 클래스 정보와 좌표값을 찾아낸다.
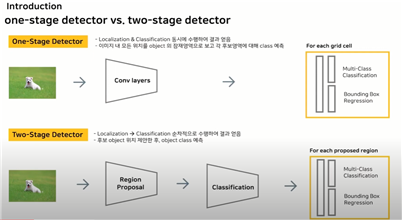
two stage detection (Fast RCN) : localization -> classification 순차적으로 수행하여 결과를 얻는다. 즉, 후보 object 위치 제안 후, object class를 예측한다.
1) 첫 번째 스테이지에서 region proposal과정을 통해 proposed regions(물체가 있음직한 곳)을 찾아낸다. 2) 두 번째 스테이지에서는 똑같은 원본을 classification layer에 넣어서 feature maps를 찾아낸다.
3) 이렇게 찾아낸 둘을 잘 연결해서 FC layers에 보내서 결과적으로 classfication과 Box refinement를 가능하게 한다.
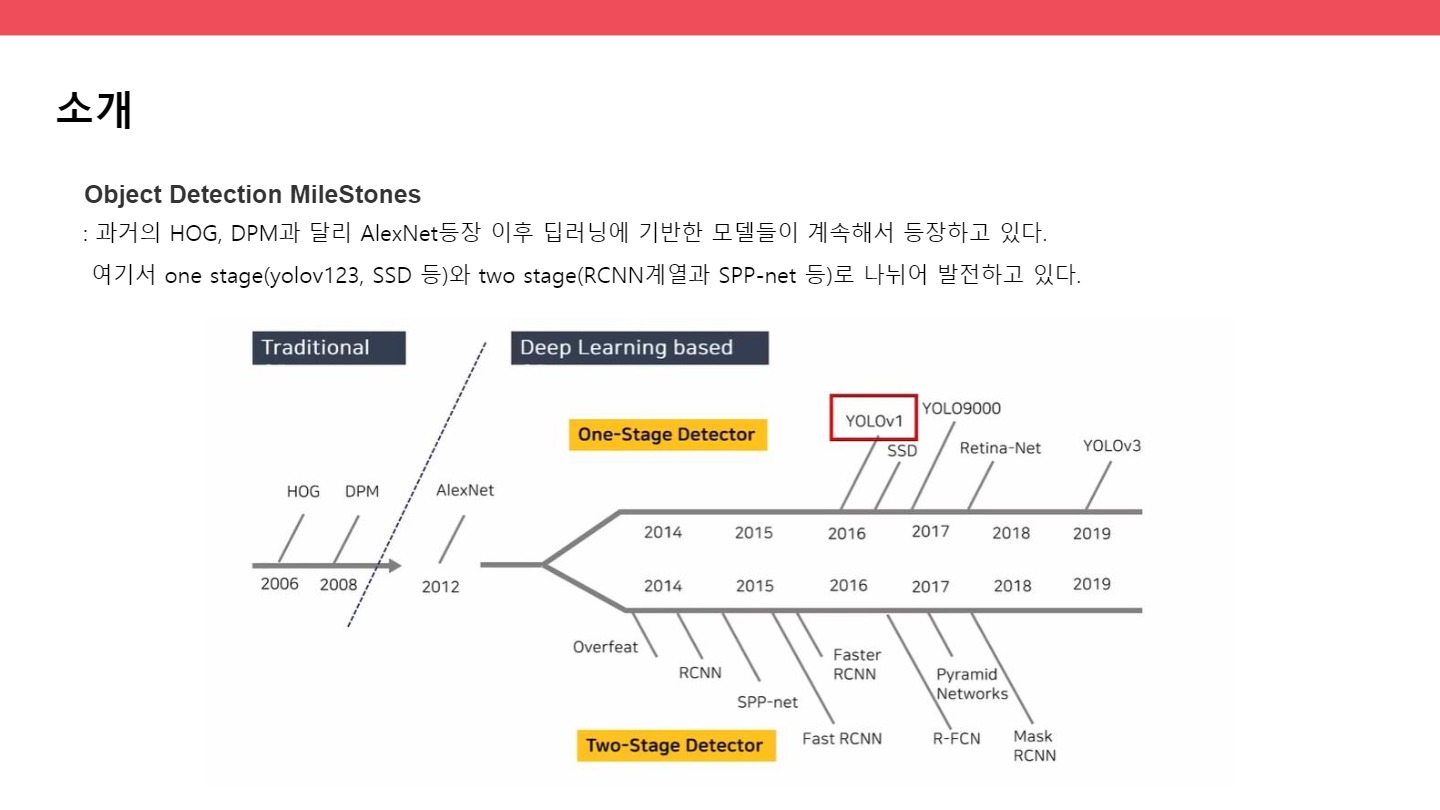
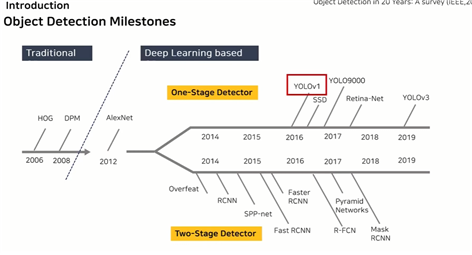
● Object detection milestones
과거의 HOG, DPM과 달리 AlexNet등장 이후 딥러닝에 기반한 모델들이 계속해서 등장하고 있다. 여기서 one stage(yolov123, SSD 등)와 two stage(RCNN계열과 SPP-net 등)로 나뉘어 발전하고 있다.
● COCO데이터를 이용한 결과
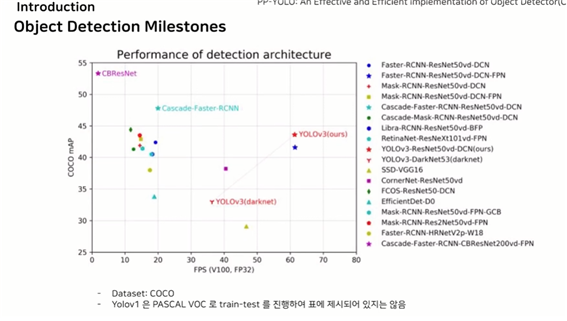
one stage계열은 속도는 빠르지만 정확성은 낮고, two stage는 속도는 비교적 느리지만 정확성이 높다는 것을 확인해 볼 수 있음
● yolo의 발전과정
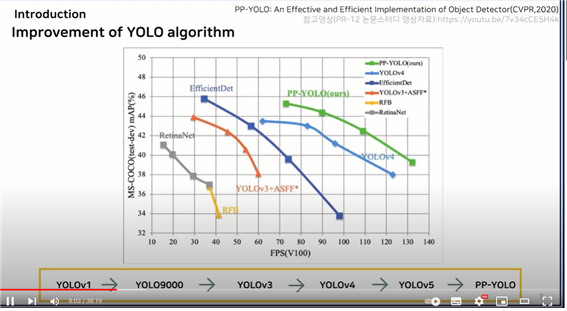
● you only look once : unified, real-time object detection

● main contribution
1) object detection을 regression problem으로 관점 전환
2) unified architecture: 하나의 신경망으로 classification&localization예측
3) DPM, RCNN 모델보다 월등한 속도 개선
4) 여러 도메인에서 object detection가능 – 실험부분에서 소개

● unified detection
- region proposal, feature extraction, classification, bbox regression
=> one-stage detection으로 통합 - 이미지 전체로 얻은 feature map을 활용해서 bbox 예측& 모든 클래스에 대한 확률계산
- SxS grid cell -> each grid cell, B bbox prediction + confidence&class probabilities -> SxSx(B*5+C)
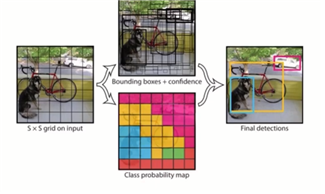
: 그림을 보면 bbox찾기와 class probability가 병렬적으로 이루어지고 있다.
ex) S : 4x4 / B : 각 그리드 셀 마다 예측하는 Bbox개수 2개 / C : 전체 고려하는 클래스
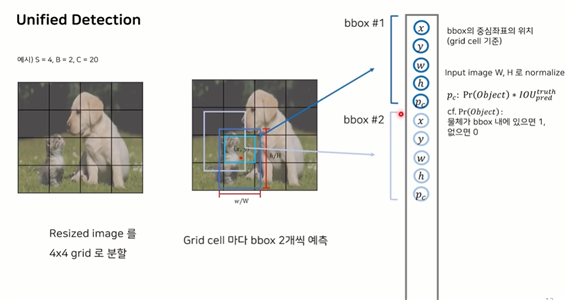
Pc: bbox내에 물체가 있을 확률인 confidence score.
하나의 그리드 셀에 대해 내부 object가 어떤 클래스에 속하는지 확률
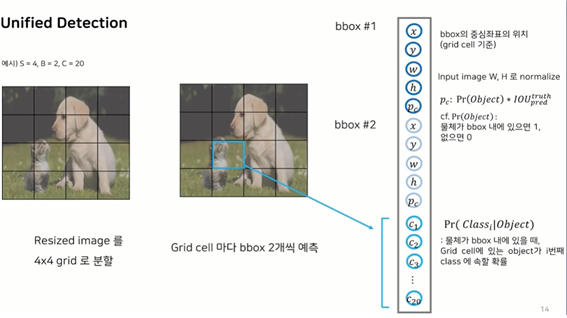
4x4에서 하나의 바운딩박스에 대해 나오는 output값이 5개이다
하나의 그리드 셀에서 2개의 bbox를 그리기에 52
총 클래스 개수가 20이기에
: 4x4x(52+20)
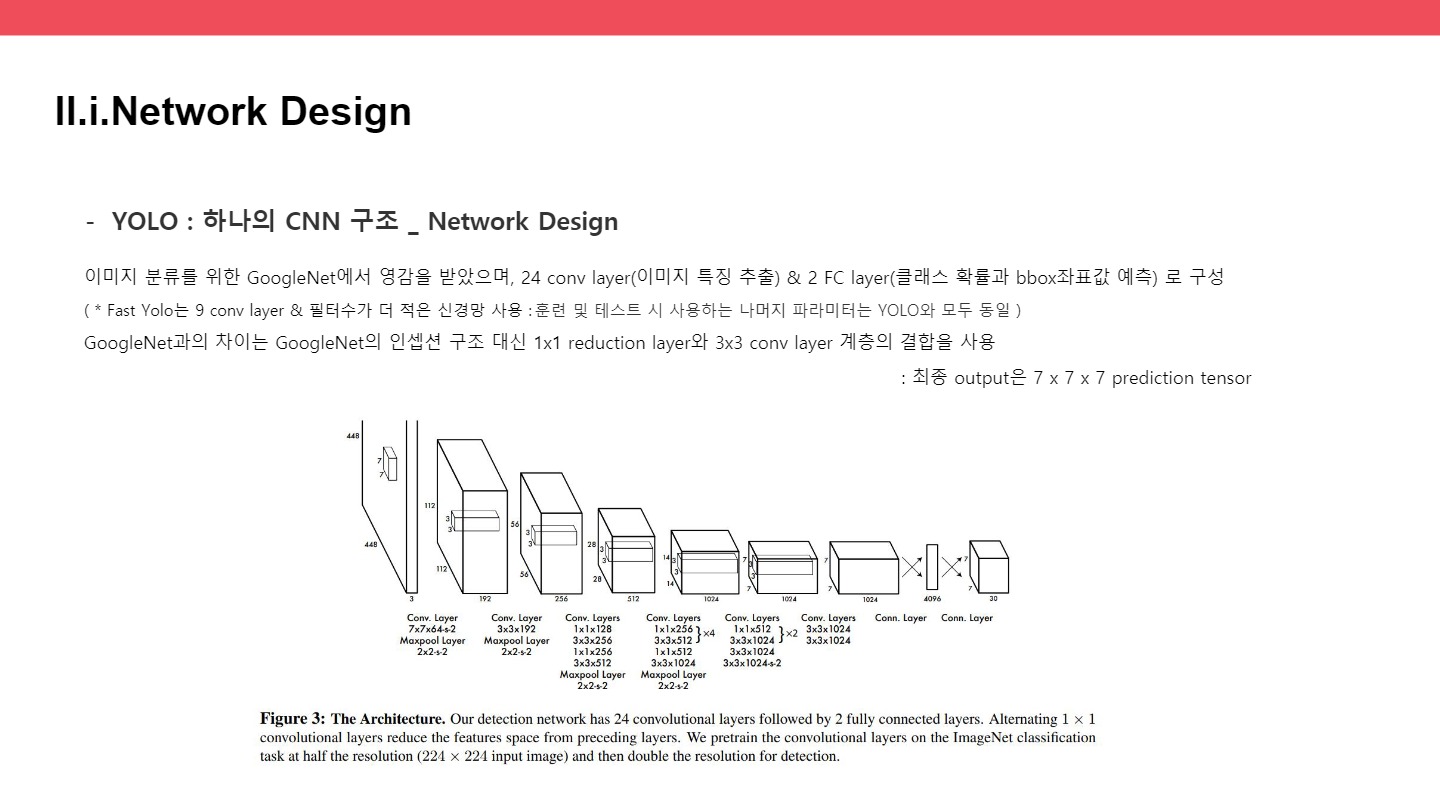
● Network Design – GoogleNet
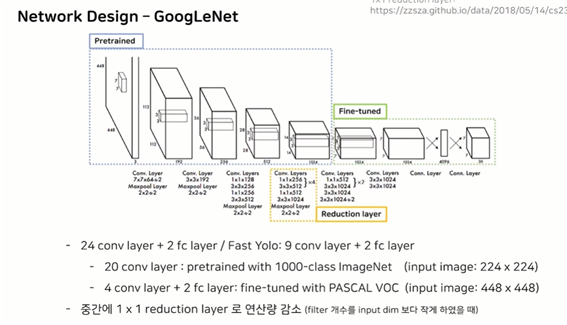
pretrained / fine-tuned
reduction layer : conv layer을 깊게 쌓을수록 연산량이 증가하니, 1x1 layer로 연산량을 감소시킴
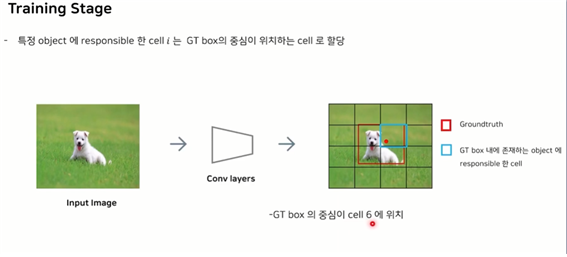
● training stage :
특정 오브젝트에 대해 responsible한 셀을 찾아야 한다.
GroundTruth(GT box)의 중심이 어느 셀에 있는가? 그 중심이 있는 셀이 GT box 내에 존재하는 objct에 대한 responsible한 cell이 된다.
yolo가 많은 bouding box를 예측하지만, 학습을 진행할 때는 딱 하나의 Bbox만 학습한다!
=> 바로 IOU가 가장 높은 bbox 1개만 사용
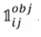
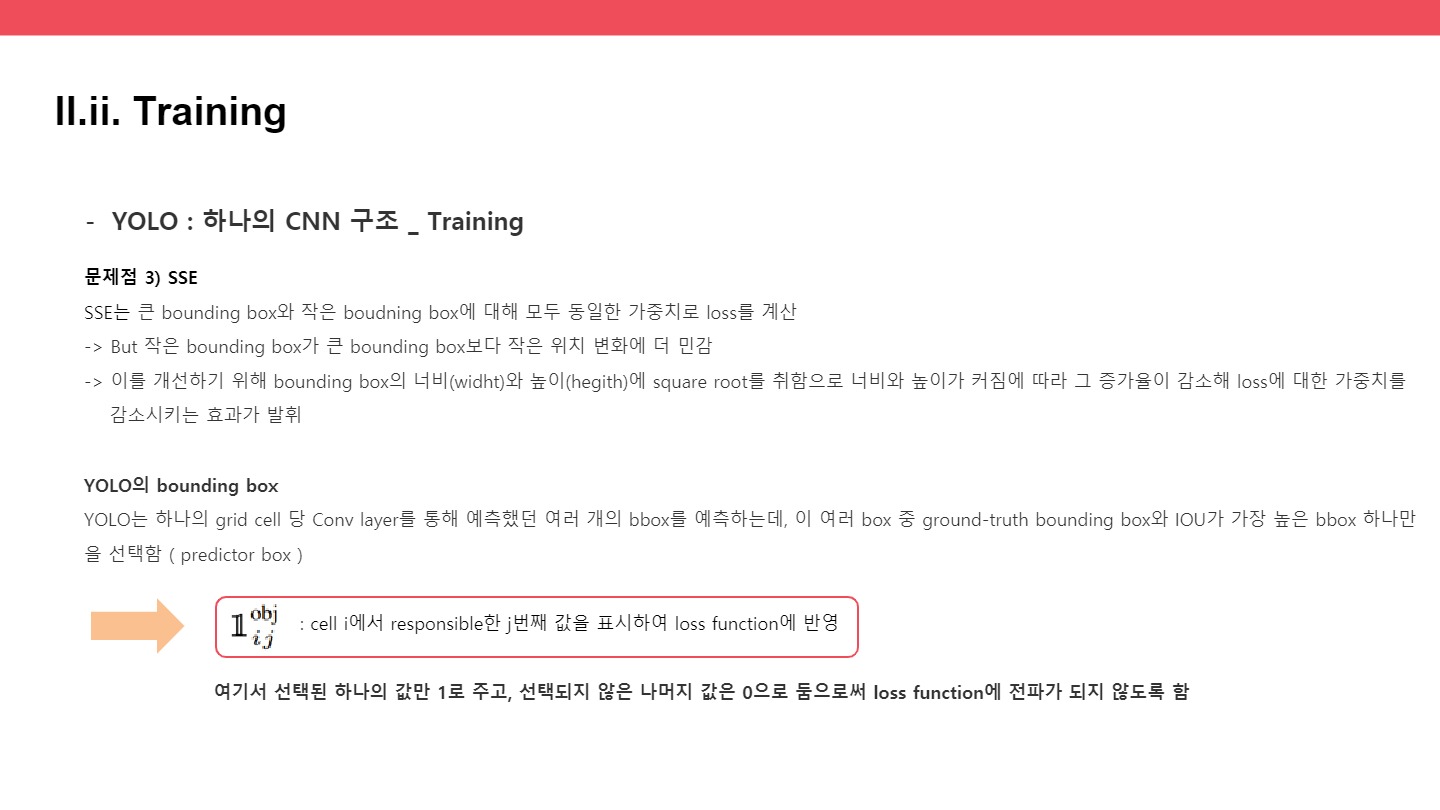
: cell i에서 responsible한 j번째 값을 표시하여 loss function에 반영
: GT box가 존재하고 이 box와 Conv layer를 통해 예측했던 bbox가 가장 많이 겹치는 것을 선택!
즉, IOU가 가장 높은 것을 선택!
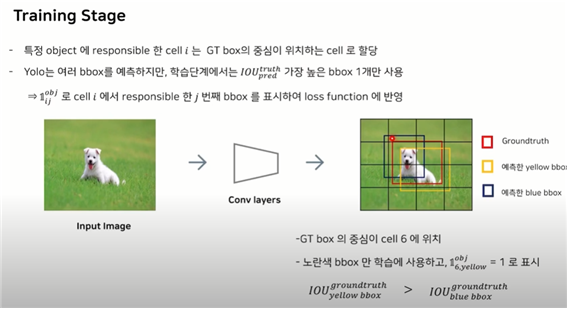
아래 적혀있는 것과 같이 IOU가 가장 높은 노란색 bbox만 학습에 사용할 경우
이와 같이 셀6번째에서 responsible한 yello bbox를 : 1로 표시하고, 나머지 예측했던 bbox=0으로 두어 loss function에서 loss가 전혀 전파가 되지 않도록 한다.
- Training-Stage – Loss Function : Mean-Squared-Error

예측값으로 찾아 내었던, x,y,h,w / 각 클래스에 대한 확률 / confidence score 각각
을 예측값과 빼서 그 제곱합을 에러로 활용
1) x,y,w,h
2) B개의 클래스에 속할 확률값과 GT값의 차이
3) 모든 그리드셀의 confidence score와 실제 정답값의 차이를 구한다.
1:(스칼라)어떤 셀이 그 물체를 예측하는데 가장 responsible하며 몇 번째 bbox가 가장 예측을 하는지 / 그 셀에서 예측력이 좋은 bbox가 어떤 것인지
2:(스칼라) 셀 I에서 물체가 나타났는지 안 나타났는지 표시하는 값 : 나타내는 나타나면1 아니면 0
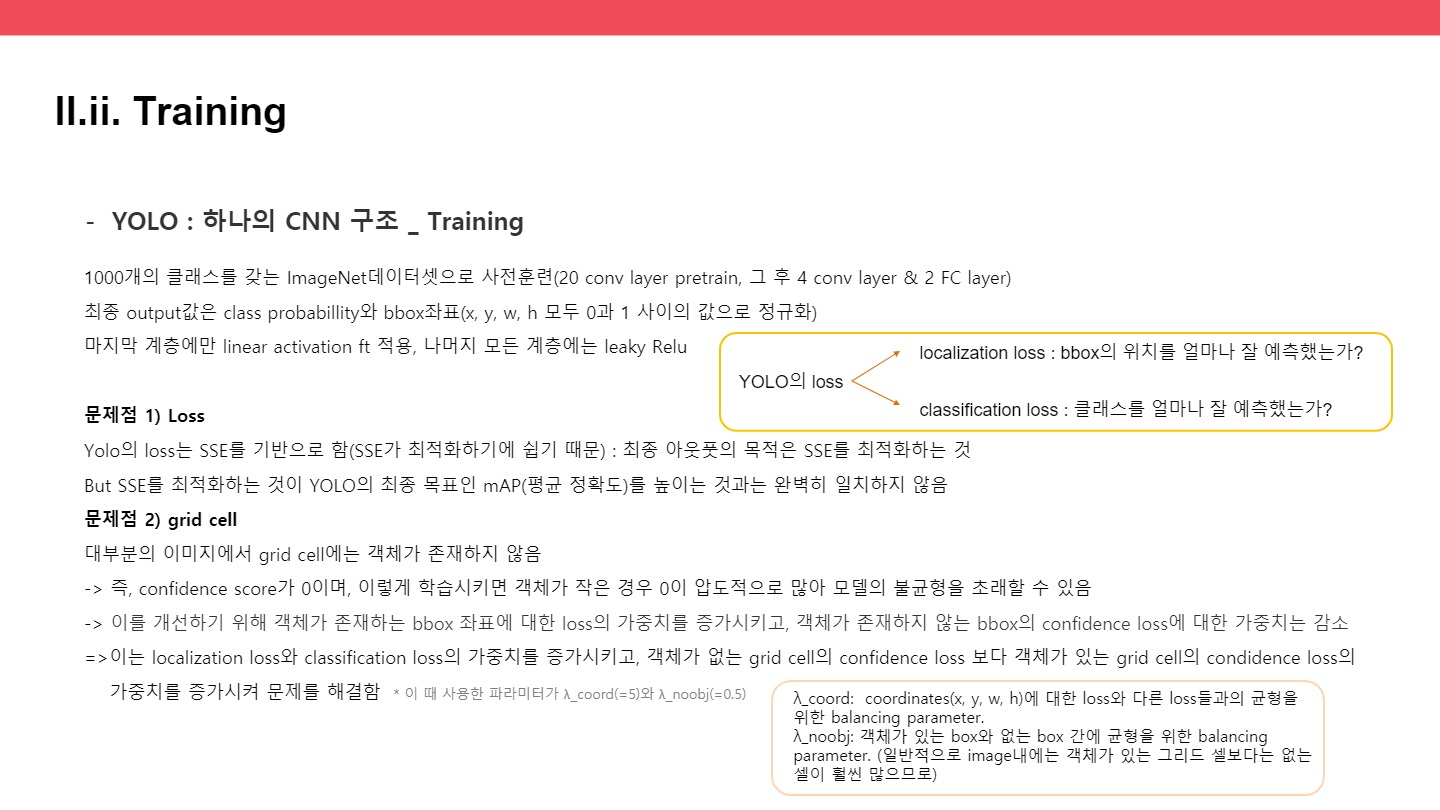
3,4:어떤 로스를 더 반영할 것인가 조정하는 람다 값
=> loss function을 한 마디로 정리하면, grid cell에 object가 존재하는 경우의 오차와 predictor box로 선정된 경우의 오차만 1 0 을 통해 학습하게 된다.
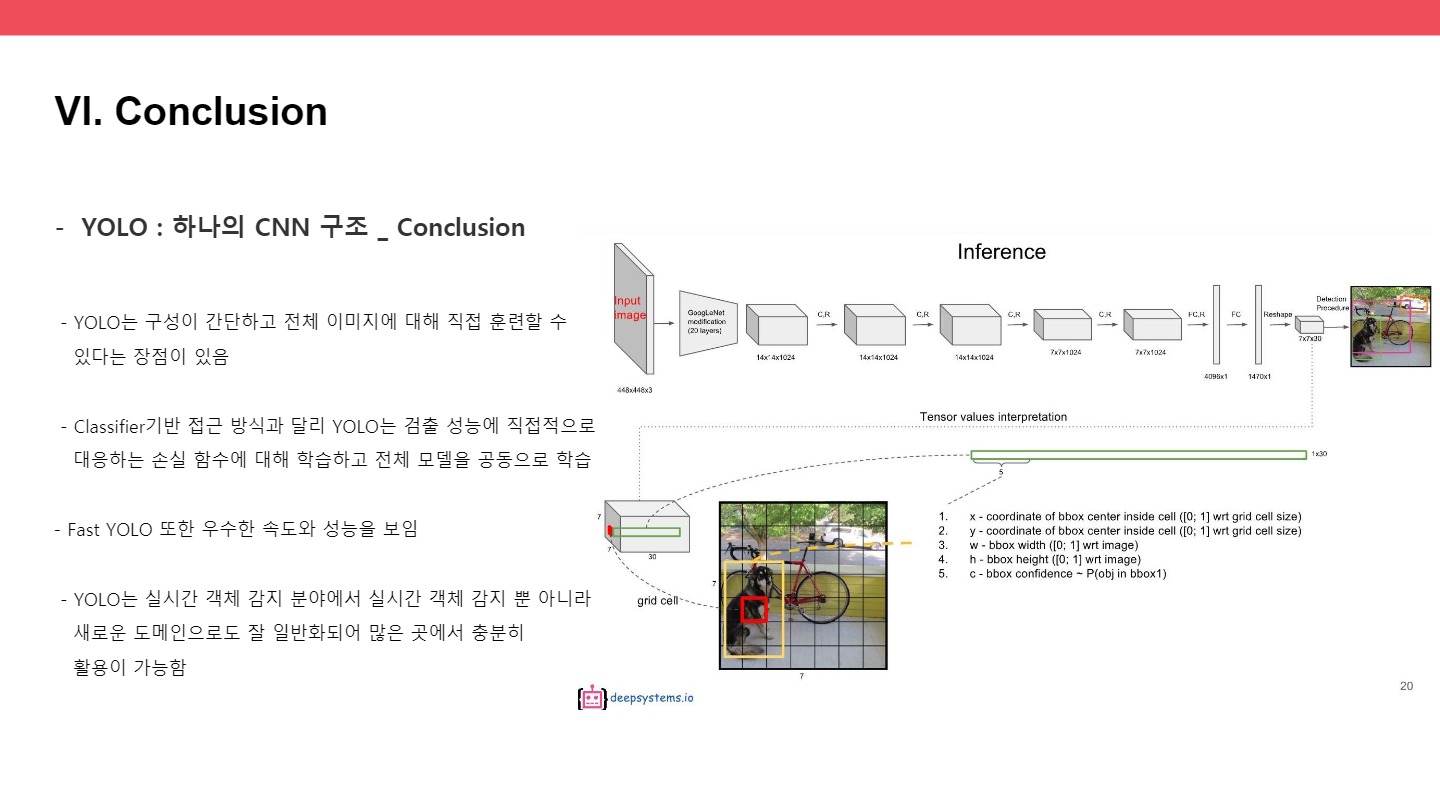
● Inference stage
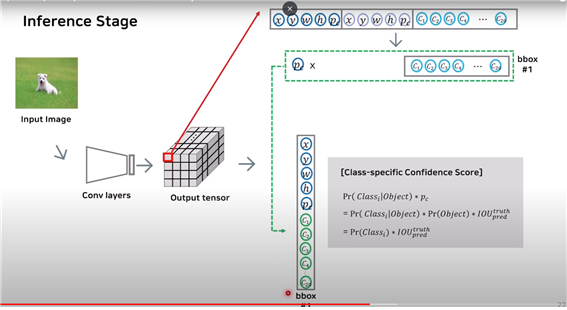
첫 번째 bbox의 confidence score(pc)와 이전에 구했던 class probability를 곱해서 class-specific confidence score를 각 bbox마다 구한다.
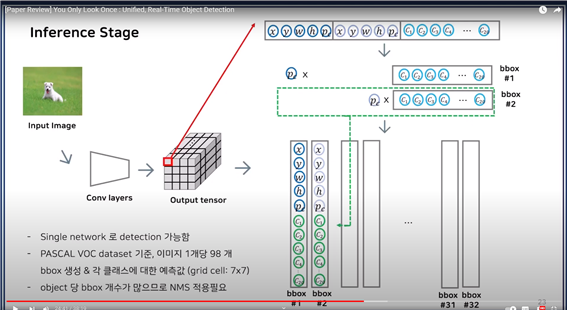
두 번째 box에서도 마찬가지로 두 번째 박스의 confidence score와 class probability를 곱해서 새롭게 1부터 20까지 넣는다. 예측한 bbox의 개수가 32개이므로, 32개의 결과가 나온다.
이 그림을 통해 single network로 detection이 가능함을 확인해 볼 수 있었다.
그리드를 7x7로 나누었기에, 각 bbox를 그리드셀마다 2개씩 예측하게 된다면 pascal voc dataset기준으로 이미지 1개당 98개의 bbox가 나타나게 된다.
즉, 위의 그림에서 bbox의 개수가 32가 아닌 98이 된다.
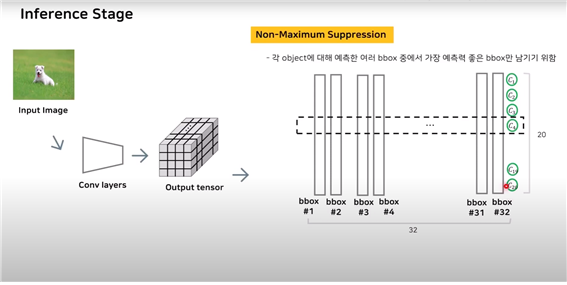
하나의 오브젝트마다 bbox의 개수가 너무 많아져서 알고리즘을 적용해준다. : NMS 적용
Non-Maximum Suppression : 각 오브젝트에 대해 여러 bbox중에서 가장 예측력이 좋은 bbox만 남기기 위함 : 각각의 class에서 예측이 가장 좋은 bbox만을 남기고 별로 적용한다.
예시
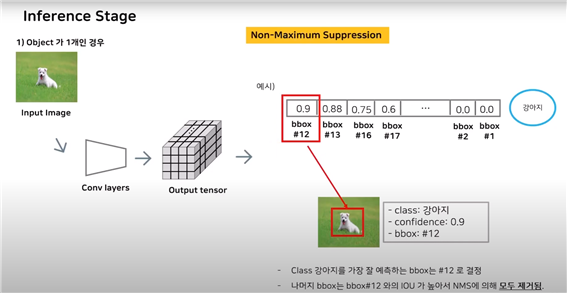
class-specific confidence score(:어떤 클래스를 예측한 확률)들을 나열시킨 후 임계값을 넘지 못하는(ex:bbox1,bbox2) bbox를 제거한다. 그 후 가장 높은 bbox를 선정 후(bbox12:ground truth) 나머지와 IOU를 계산 :
나는 가장 높은 하나만 남기고 싶기에 IOU가 높게 나오면 다 제거해버린다.(왜냐하면 같은 객체를 가리키는 것은 하나만 필요하기에)
물체가 1개이기에 당연히 12와 나머지를(13, 16, 17, ...) 비교했을 때 모두 높은 IOU값을 가지게 된다. 따라서 NMS에 의해 모두 제거된다.
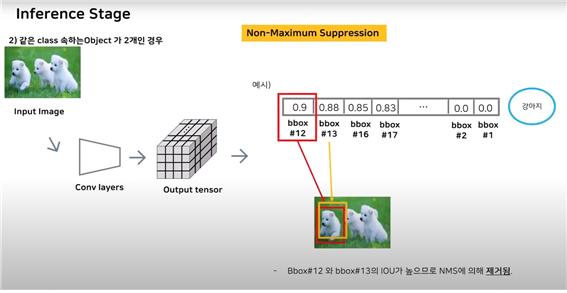
같은 클래스에 속하는 객체가 2개인 경우
마찬가지로 class-specific confidence score들을 순서대로 나열한 후 임계값을 넘지 못하는 bbox 우선적으로 제거
그 후 가장 높은 bbox12를 선택하고, bbox12와 나머지들을 순차적으로 IOU값을 계산
IOU가 높다는 것은 같은 객체를 가리키고 있다는 것이기에 NMS에 의해 없앤다.
: 여기서는 bbox13이 12와 가리키는 것이 일치하기에 IOU값이 높아 제거한다.
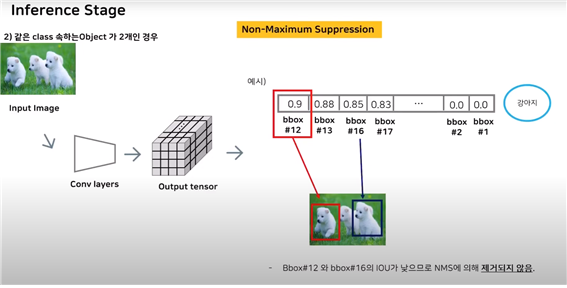
하지만 bbox16과는 같은 클래스이지만 다른 객체를 가리키고 있기에 IOU값이 낮으므로 NMS에 의해 제거되지 않는다.
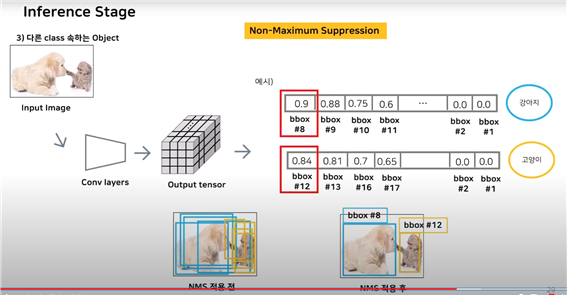
서로 다른 클래스의 객체 탐지는 어떨까?
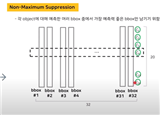
NMS알고리즘에서 설명한 바와 같이 각 클래스별로 구한다.
각 클래스의 class-specific confidence score를 구한 후 sorting을 하고, 예시에서는 각 클래스가 하나씩 있기에 당연스럽게 가장 높은 bbox8과 bbox12를 제외한 bbox를 NMS에 의해 모두 제거하고 남은 둘만 선택한다.
따라서 가장 예측력이 좋은 bbox 하나만을 남기게 된다.
● experiement
총 5가지의 실험을 진행하였는데, 유투브에서는 3개만 말함
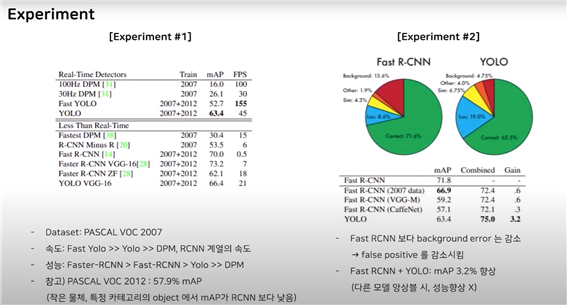
실험 1 : pascal voc 2007
dataset : pascal voc 2007
속도, 성능
표에서 FPS를 보면 yolo는 45 FastYolo는 155정도이다. 다른 모델을에 비해서는 속도가 월등히 빠르다
mAP는 52.7 63.4정도 : R-CNN이 two stage 계열이다 보니 성능은 더 좋다.
실험 2 : FastRCNN과 YOLO의 비교
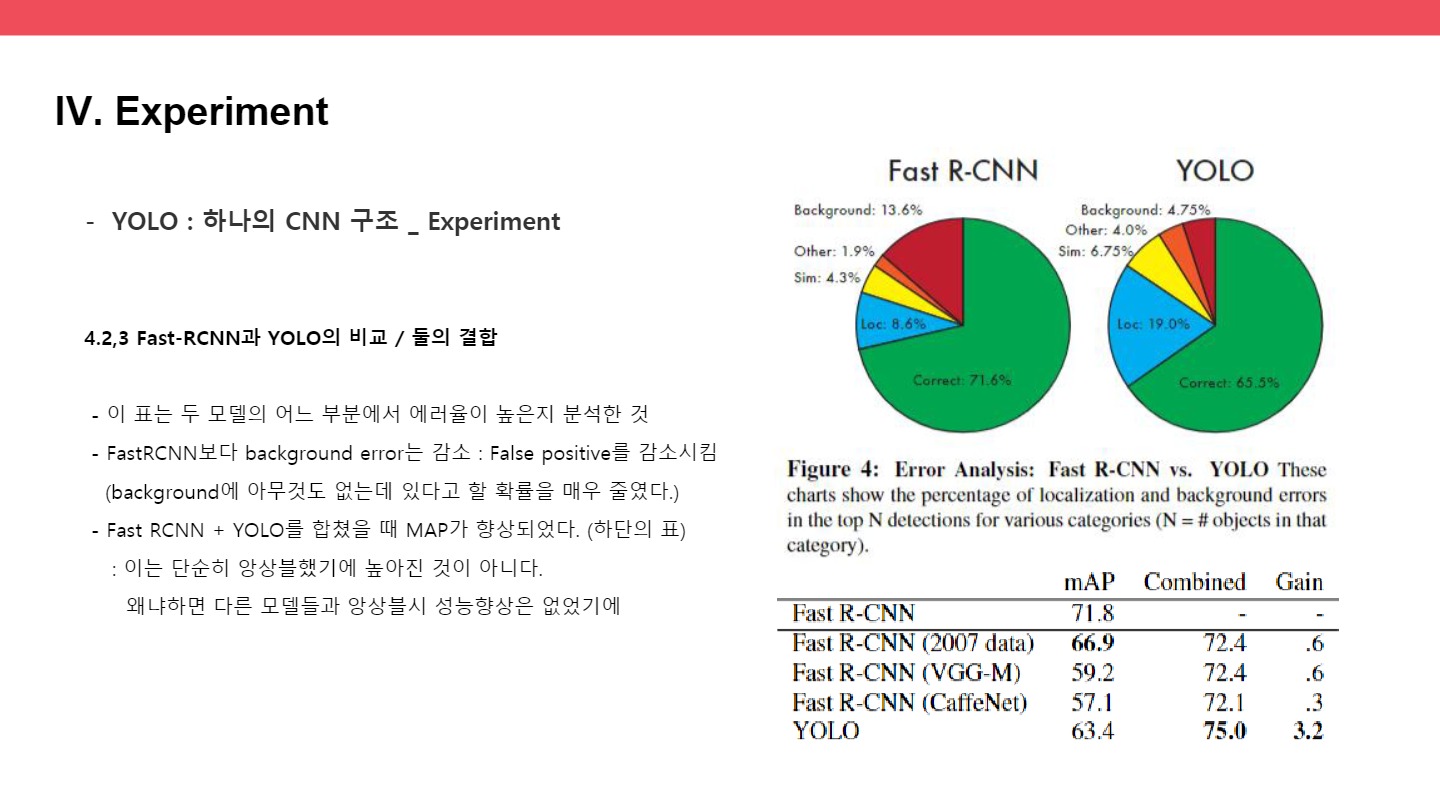
두 번째 표는 두 모델의 어느 부분에서 에러율이 높은지 분석한 것
FastRCNN보다 background error는 감소 : False positive를 감소시킴(background에 아무것도 없는데 있다고 할 확률을 매우 줄였다.)
Fast RCNN + YOLO를 합쳤을 때 MAP가 향상되었다.(하단의 표)
: 이는 단순히 앙상블했기에 높아진 것이 아니다. 왜냐하면 다른 모델들과 앙상블시 성능향상은 없었기에
실험 3 : 욜로가 다양한 도메인의 로버스트한 디텍션 알고리즘이다. (contribution)
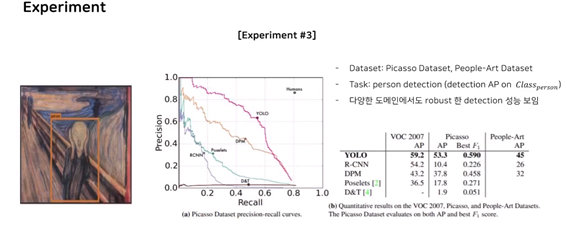
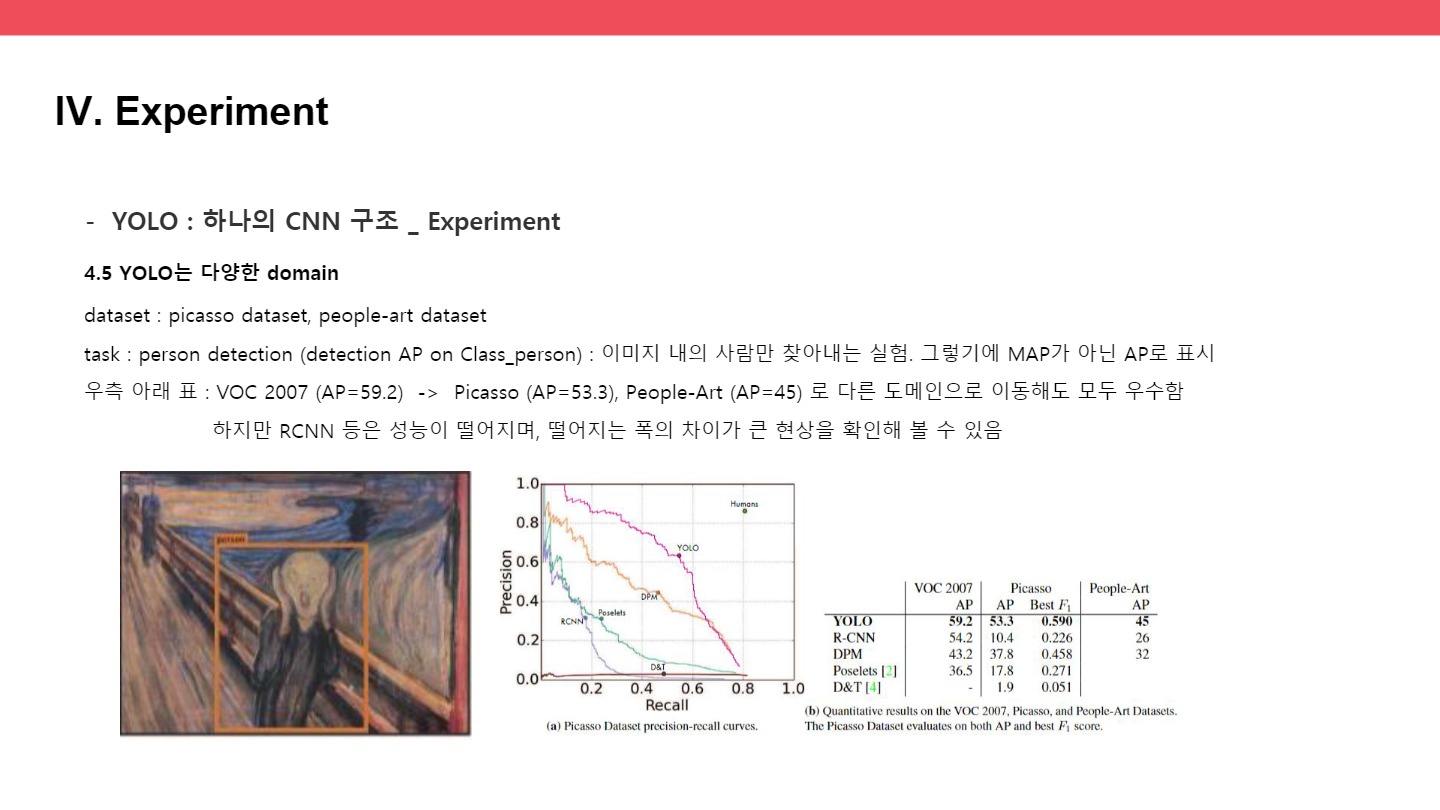
dataset : picasso dataset, people-art dataset
task : person detection (detection AP on Class_person) : 이미지 내의 사람만 찾아내는 실험. 그렇기에 MAP가 아닌 AP로 표시
우측 아래 표 : voc 59.2 -> picasso 53.3 people art 45 로 이동해도 모두 우수함
하지만 RCNN 등은 성능이 떨어지며, 떨어지는 폭의 차이가 큰 현상을 확인해 볼 수 있었다.
● Limitation

1) 작은 물체에 대해 탐지 성능이 낮다.
객체가 크면 bbox 간의 IOU값의 차이가 커져서, 적절한 predictor를 선택할 수 있지만, 객체가 작으면 bbox도 작아지고 bbox간의 IOU값의 차이가 작아서 근소한 차이로 predictor가 결정된다.(IOU값이 큰 것들은 제거하고 작은 것들은 다른 객체라고 봐야 하는데 쉽지 않다.)
2) 일반화된 지식과 다르게 객체 비율이 달라지면 detection 성능이 낮아진다.
대부분의 detection 모델들의 한계점이다.
