단일행 함수
테이블의 모든 로우에 결과가 반환되는 함수로 문자, 숫자, 날짜, 형변환, 선택 함수(조건 활용) 등이 있다.
문자열 함수
문자열을 처리하는 기능
LENGTH
지정된 컬럼, 리터럴 값의 길이를 출력해주는 함수. LENGTH('문자열'||컬럼명) FROM TABLE명; 형태로 사용한다.
SELECT LENGTH('문자열 길이 확인')
FROM DUAL; -->9출력
--이메일이 16글자 이상인 사원을 조회
SELECT EMP_NAME, EMAIL, LENGTH(EMAIL)
FROM EMPLOYEE
WHERE LENGTH(EMAIL)>=16;LENGTHB
차지하는 BYTE를 출력한다. ECPRESS 버전에서 한글은 3BYTE로 저장하고, ENTERPRISE 버전에서는 2BYTE로 저장한다.
SELECT LENGTHB('ABCD'), LENGTHB('월요일')
FROM DUAL;
--각각 4, 9 출력INSTR
원하는 문자를 찾아내는 함수로 시작 위치와 몇 번째 값을 찾을지 추가로 지정할 수 있다. INSTR('문자열'||컬럼,'찾을 문자',[시작위치,찾을번째]) 형태로 작성한다. JAVA의 INDEXOF와 유사한 기능이다.
--EMAIL주소에 j에 포함되어있는 위치 확인
SELECT EMAIL, INSTR(EMAIL,'j')
FROM EMPLOYEE;
--EMAIL주소에 j가 포함되어 있는 사원 찾기
SELECT EMP_NAME, EMAIL
FROM EMPLOYEE
WHERE INSTR(EMAIL,'j')>0;
--첫번째로 찾은 것만 반환한다.
SELECT INSTR('BB아카데미 BB게임즈 BB음악사 BB화이팅','BB')
,INSTR('BB아카데미 BB게임즈 BB음악사 BB화이팅','BB',3)
--원하는 인덱스 번호를 넣어서 해당 위치부터 찾을 수 있다.
,INSTR('BB아카데미 BB게임즈 BB음악사 BB화이팅','BB',-1)
--음수를 넣으면 역순으로 찾는다.
,INSTR('BB아카데미 BB게임즈 BB음악사 BB화이팅','BB',1,3)
--1부터 시작하고 원하는 번째의 값을 찾는다.
FROM DUAL;
--사원테이블에서 @위치 찾기
SELECT EMAIL,INSTR(EMAIL,'@') AS "@위치"
FROM EMPLOYEE;LPAD/RPAD
문자열의 길이가 지정한 길이만큼 차지 않았을 때 빈 공백을 채워주는 함수로 LPAD/RPAD('문자열'||컬럼, 최대길이, 대체문자) 형태로 사용한다.
SELECT LPAD('ORACLE',10,'L') --왼쪽에 빈 공간을 L로 채운다.
,RPAD('ORACLE',10,'R')
,LPAD('오라클',10) --아무것도 적지 않으면 띄어쓰기로 채운다.
FROM DUAL;
SELECT EMAIL, RPAD(EMAIL,20,'#')
FROM EMPLOYEE;LTRIM/RTRIM
공백이나 특정 문자를 지정해서 제거하는 함수로 특정 문자를 지정하지 않으면 기본적으로 공백을 제거한다. LTRIM/RTIRIM('문자열'||컬럼,'특정문자') 형태로 사용한다.
--공백 삭제
SELECT ' 오라클', LTRIM(' 오라클'), RTRIM(' 오라클 ')
,RTRIM(' 오 라클 ') AS 사이공백
--가운데에 있는 공백은 지우지 않는다.
FROM DUAL;
--특정 문자 삭제
--특정 문자에 12라고 쓰면 OR로 묶인다. 1또는 2를 전부 삭제
SELECT '오라클2222', RTRIM('오라클2222','2')
,RTRIM('오라클22122','2') --오라클221 출력된다. 중간에 다른 값이 나오면 끊긴다.
,RTRIM('오라클2222','12')
FROM DUALTRIM
양쪽 공백값을 제거하는 함수로 기본적으로 공백을 제거하고 설정하면 설정 값을 제거한다. 설정 값은 LTRIM/RTRIM과 다르게 한 글자만 가능하다.
SELECT ' 월요일 ', TRIM(' 월요일 ') AS 월
,'ZZZZZ마징가ZZZZZ', TRIM('Z' FROM 'ZZZZZ마징가ZZZZZ') AS BOTH
--아무것도 작성 안 하면 BOTH
,TRIM(LEADING 'Z'FROM'ZZZZZ마징가ZZZZZ') AS LEADING
--앞에만 지운다
,TRIM(TRAILING 'Z' FROM 'ZZZZZ마징가ZZZZZ') AS TRAILING
--뒤에만 지운다
FROM EMPLOYEE;SUBSTR
문자열을 잘라내는 기능으로 JAVA의 SUBSTRIMG메소드와 동일하다. SUBSTR('문자열'||컬럼,시작인덱스,[길이]) 형태로 작성하며 시작 인덱스를 포함해서 원하는 길이까지 저장하고 길이를 지정하지 않으면 끝까지 출력한다.
SELECT SUBSTR('SHOWMETHEMONEY',5), SUBSTR('SHOWMETHEMONEY',5,2)
,SUBSTR('SHOWMETHEMONEY',INSTR('SHOWMETHEMONEY','MONEY'))
-->INSTR함수를 이용해서 원하는 문자열의 인덱스를 찾아서 입력할 수 있다.
,SUBSTR('SHOWMETHEMONEY',-5) --음수는 역순.
FROM DUAL;UPPER, LOWER, INITCAP
영문자를 처리하는 함수로 UPPER은 전부 대문자로 변환하고 LOWER은 전부 소문자로, INITCAP은 공백을 기준으로 첫 글자는 대문자로 나머지는 소문자로 변환한다.
SELECT UPPER('Wellcome to ORACLE world') --WELLCOME TO ORACLE WORLD
,LOWER('Wellcome to ORACLE world') --wellcome to oracle world
,INITCAP('Wellcome to ORACLE world') --Wellcome To Oracle World
FROM DUAL;CONCAT
문자열 결합하는 함수로 ||연산자와 동일한 기능을 한다. CONCAT(문자열||컬럼) 형태로 사용하고 소괄호 안에 CONCAT 함수를 중복해서 사용할 수 있다.
SELECT EMP_NAME||EMAIL, CONCAT(EMP_NAME,EMAIL), CONCAT(CONCAT(EMP_NAME,EMAIL),SALARY)
FROM EMPLOYEE;REPLACE
대상 문자에서 지정 문자를 찾아서 특정 문자로 변경하는 함수다. REPLACE('문자열'||컬럼,'찾을문자','대체문자') 형태로 작성한다.
--naver.com이라고 되어있는 이메일 주소를 ORACLE.com으로 바꾸기
SELECT EMAIL, REPLACE(EMAIL,'naver','ORACLE')
FROM EMPLOYEE;REVERSE
문자열을 거꾸로 만들어주는 기능을 수행하는 함수로 byte단위로 계산한다. 때문에 한글은 깨져서 결과가 반환된다.
SELECT EMAIL, REVERSE(EMAIL), REVERSE(EMP_NAME) --���렄처럼 깨져서 출력
FROM EMPLOYEE;TRANSLATE
매칭되는 문자로 변경해주는 함수. TRANSLATE(’문자열’,’기준 문자열’,’대체 문자열’) 형태로 작성한다.
SELECT TRANSLATE('010-1234-5678','01023456789','영일이삼사오육칠팔구')
-->영일영-일이삼사-오육칠팔 출력
FROM DUAL;숫자 처리 함수
ABS : 절댓값을 처리하는 함수
MOD(나눌 값, 나눌 수) : 나머지를 구하는 함수, 자바의 %연산자와 동일하다.
SELECT ABS(-10), ABS(10)
FROM DUAL;
SELECT MOD(3,2)
FROM DUAL;SELECT SALARY, MOD(SALARY,3)
FROM EMPLOYEE;
SELECT E.*, MOD(SALARY,3)
FROM EMPLOYEE E;소수점을 처리하는 함수
ROUND(숫자||컬럼,[자릿수]) : 소수점을 반올림하는 함수
FLOOR : 소수점 자리를 별다른 처리 없이 버린다.
TRUNC : 소수점 자리를 버리지만 자릿수를 지정 가능한 함수. 음수를 작성하면 소수점 앞으로 가서 남은 금액을 버린다.
CEIL : 소수점을 무조건 올려서 계산하는 함수.
--보너스를 포함한 월급을 반올림해서 계산
SELECT EMP_NAME,SALARY, ROUND(SALARY+SALARY*NVL(BONUS,0)-(SALARY*0.03))
,SALARY+SALARY*NVL(BONUS,0)-(SALARY*0.03)
FROM EMPLOYEE;
SELECT 126.567, FLOOR(126.567)
FROM DUAL;
SELECT 126.567, TRUNC(126.567), TRUNC(126.567,2), TRUNC(126.567,-2)
,TRUNC(2123456.32,-1)
FROM DUAL;
SELECT 126.567, CEIL(126.567), CEIL(126.111)
FROM DUAL;날짜 처리 함수
SYSDATE 예약어 : 날짜를 표시. 년,월,일 오늘 날짜(오라클 설치된 컴퓨터의 시간)을 출력
SYSTIMESTAMP 예약어 : 날짜+시간까지 출력
날짜 처리도 +, - 연산이 가능하며 계산은 일 단위로 된다. 날짜를 작성할 때는 문자열로 작성되고 출력되더라도 컴퓨터 내부에서는 LONG타입으로 연산한다.
SELECT SYSDATE, SYSTIMESTAMP
FROM DUAL;
SELECT SYSDATE, SYSDATE-7 AS 일주일전, SYSDATE+30 AS 한달뒤
FROM DUAL;NEXT_DAY(SYSDATE, '지정요일') : 매개변수로 전달 받은 요일 중 가장 가까운 다음 날짜를 출력한다. 요일은 프로그램 설정에 맞춰진 언어로 입력한다. 현재 설정이 한국어로 되어있다면 영어로 요일을 입력했을 땐 오류가 발생한다.
LAST_DAY : 달의 마지막 날의 출력한다.
ADD_MONTHS : 개월 수를 더하는 함수.
MONTHS_BETWEEN : 두 개의 날짜를 받아서 두 날짜의 개월 수를 계산하는 함수
EXTRACT(YEAR||MONTH||DAY FROM 날짜) : 날짜의 년도, 월, 일자를 따로 숫자로 출력할 수 있는 함수
SELECT SYSDATE, NEXT_DAY(SYSDATE,'월') AS 다음주월요일
--, NEXT_DAY(SYSDATE,'MON')
FROM DUAL;
SELECT SYSDATE, LAST_DAY(SYSDATE),LAST_DAY(SYSDATE+30)
FROM DUAL;
SELECT SYSDATE, ADD_MONTHS(SYSDATE,4), ADD_MONTHS(SYSDATE,10)
FROM DUAL;
SELECT FLOOR(MONTHS_BETWEEN('23/08/17',SYSDATE))
FROM DUAL;
SELECT EXTRACT(YEAR FROM SYSDATE) AS 년, EXTRACT(MONTH FROM SYSDATE) AS 월
, EXTRACT(DAY FROM SYSDATE) AS 일
FROM DUAL;형변환 함수
오라클에서는 자동 형변환이 잘 작동한다. 하지만 데이터를 저장할 때 데이터 타입이 존재한다.
TO_CHAR
날짜, 숫자를 문자형으로 변환할 때 사용하는 함수이다.
날짜 데이터를 기호로 표시해서 문자형으로 변환한다. 날짜 기호는 Y : 년도, M : 월, D : 일, H : 시간, MI : 분, SS : 초 으로 사용한다.
SELECT SYSDATE, TO_CHAR(SYSDATE,'YYYY-MM-DD'), TO_CHAR(SYSDATE,'YY-MM-DD HH24:MI:SS')
FROM DUAL;
--예)23-04-04 15:45:30
SELECT SYSDATE, TO_CHAR(SYSDATE,'YYYY-MM-DD'), TO_CHAR(SYSDATE,'YY-MM-DD HH:MI:SS')
FROM DUAL;
--예)23-04-04 03:46:38자릿수를 어떻게 표현할지 선택한 패턴에 맞춰서 변환한다. 통화를 표시하고 싶을 땐 L을 표시한다.
0 : 변환 대상의 값의 자릿수가 지정한 자릿수와 일치하지 않을 때, 값이 없는 자리에 0을 출력하는 패턴
9 : 변환 대상의 값의 자릿수가 지정한 자릿수와 일치하지 않을 때, 값이 없는 자리의 표시를 생략하는 패턴
SELECT 1234567, TO_CHAR(1234567,'000,000,000'), TO_CHAR(1234567,'999,999,999')
,TO_CHAR(300,'L999,999'), TO_CHAR(1234567,'999,000,000.00')
--1234567/001,234,567/ 1,234,567/ ₩300/ 1,234,567.00 출력
FROM DUAL;TO_NUMBER
문자를 숫자형 데이터로 변환할 때 사용하는 함수이다. TO_NUBBER(’문자열’) 형태로 작성해서 사용한다.
SELECT 1000000+1000000, TO_NUMBER('1,000,000','999,999,999')+1000000 AS 문자열연산
FROM DUAL;
-->결과 값은 둘 다 2000000이 나온다.
TO_DATE
숫자, 문자를 날짜형 데이터로 변환할 때 사용하는 함수이다. TO_DATE(’문자열’||숫자) 형태로 작성해서 사용한다.
--문자열을 변환해서 날짜형으로 연산처리
SELECT FLOOR(TO_DATE('23/12/25','YY/MM/DD')-SYSDATE) AS "크리스마스D-DAY"
, TO_DATE('211225','YYMMDD'), TO_DATE('25-12-25','YY-MM-DD')
FROM DUAL;
--숫자를 변환
SELECT TO_DATE(20230405,'YYYYMMDD'), TO_DATE(230505,'YYMMDD') AS 어린이날
,TO_DATE(TO_CHAR(000224,'000000'),'YYMMDD')
FROM DUAL;NVL, NVL2
NULL 값을 구분해서 처리해주는 함수로 NVL(컬럼,대체값), NVL2(컬럼, NULL이 아닐때, NULL일때) 형태로 작성해서 사용한다.
SELECT EMP_NAME, DEPT_CODE, NVL(DEPT_CODE,'인턴'), NVL2(DEPT_CODE,'부서O','부서X')
FROM EMPLOYEE;DECODE
조건의 예상 값에 따라 지정된 대체 값을 반환하는 함수로 자바의 SWITCH와 비슷한 기능을 한다.. 마지막에 예상 값 없이 대체 값만 작성하면 앞에 예상 값이 아닌 경우 전부 해당 값으로 반환한다.
DECODE (컬럼||'문자열','예상값','대체값','예상값2','대체값2',...) 형태로 작성한다.
--주민번호에서 8번째 자리 값이 1이면 남자를 반환, 2이면 여자를 반환하는 가상 컬럼 추가
SELECT EMP_NAME, EMP_NO, DECODE(SUBSTR(EMP_NO,8,1),'1','남자','2','여자') AS GENDER
FROM EMPLOYEE;CASE WHEN THEN ELSE
자바의 IF~ELSE문과 비슷한 기능을 하는 함수이다. CASE [중복 조건 비교 값] WHEN 조건식 THEN 실행 내용 ELSE 실행 내용 END 로 작성하며 실행 내용은 WHEN~THEN은 여러 개를 중복 해서 사용할 수 있다. ELSE 뒤에 오는 실행 내용은 위에 조건이 만족하지 않은 모든 경우에 해당한다.
SELECT EMP_NAME, JOB_CODE
,CASE
WHEN JOB_CODE='J1' THEN '대표'
WHEN JOB_CODE='J2' THEN '부사장'
WHEN JOB_CODE='J3' THEN '부장'
WHEN JOB_CODE='J4' THEN '과장'
ELSE '사원' --위 조건에 만족하지 않으면 사원으로 출력한다.
END AS 직책,
CASE JOB_CODE --중복되는 조건의 비교 값을 CASE 뒤에 작성할 수 있다.
WHEN 'J1' THEN'대표'
WHEN 'J2' THEN '부사장'
END
FROM EMPLOYEE;Oracle의 날짜형에서 세기 구분
년도 표기를 RR로 했을 경우
| 현재 년도 | 입력 년도 | 계산한 세기 |
|---|---|---|
| 00~49 | 00~49 | 현세기 |
| 00~49 | 50~49 | 전세기 |
| 50~99 | 00~49 | 다음 세기 |
| 50~99 | 50~99 | 현세기 |
주민번호를 가지고 사원의 현재 나이를 구하는 쿼리를 작성한다고 할 때 아래처럼 작성할 수 있다.
SELECT EMP_NAME, EMP_NO, EXTRACT(YEAR FROM SYSDATE)
-EXTRACT(YEAR FROM TO_DATE(SUBSTR(EMP_NO,1,2),'YY'))||'살' AS 나이
,EXTRACT(YEAR FROM SYSDATE)
-EXTRACT(YEAR FROM TO_DATE(SUBSTR(EMP_NO,1,2),'RR'))||'살' AS 나이
,EXTRACT(YEAR FROM SYSDATE)-(
TO_NUMBER(SUBSTR(EMP_NO,1,2))+
CASE
WHEN SUBSTR(EMP_NO,8,1) IN (1,2) THEN 1900
WHEN SUBSTR(EMP_NO,8,1) IN (3,4) THEN 2000
END
) AS 살
FROM EMPLOYEE;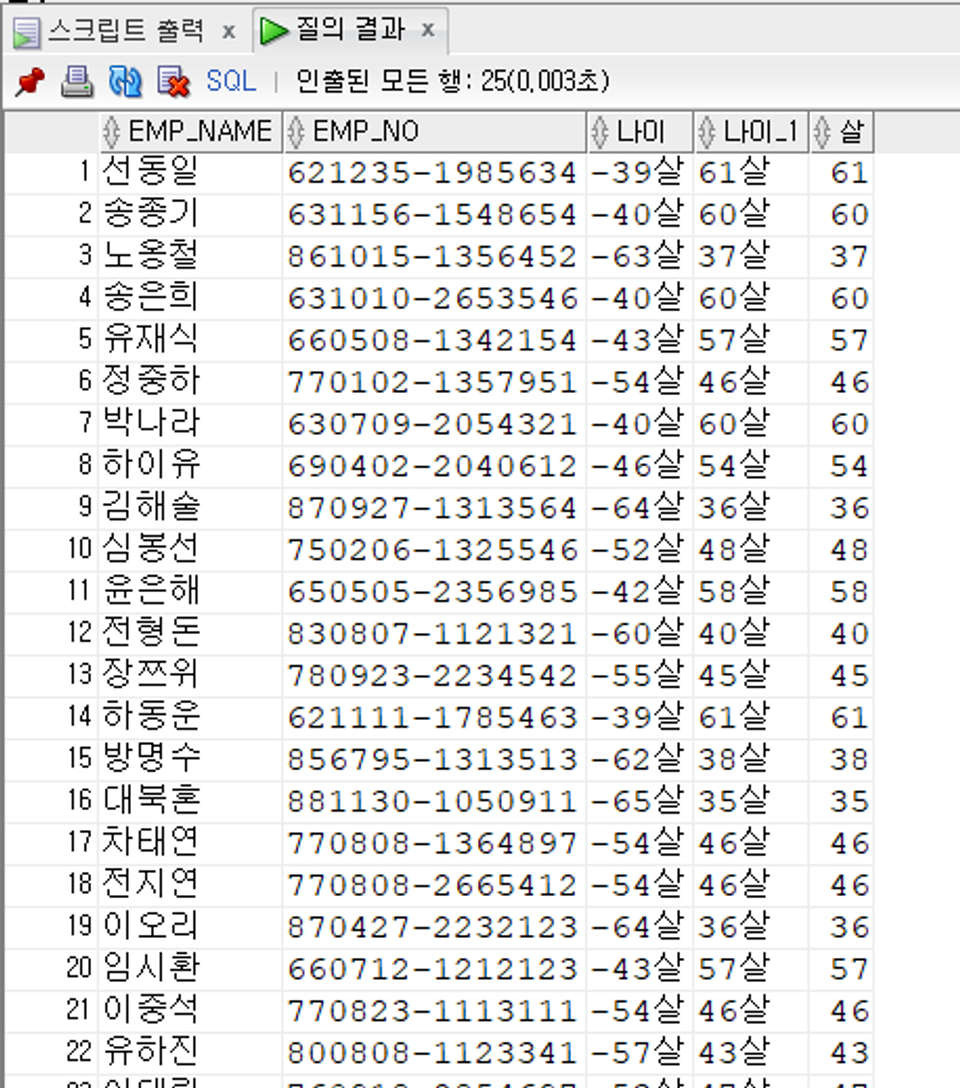
RESULT SET을 보면 해당 결과가 나오는데 이 때 EXTRACT(YEAR FROM SYSDATE)-EXTRACT(YEAR FROM TO_DATE(SUBSTR(EMP_NO,1,2),'YY')) 로 작성한 컬럼의 값은 전부 음수가 나오게 된다. 현재 년도에서 주민번호 앞자리를 뺏지만 DATE로 변환하면 현 세기의 년도로 계산해서 20YY년으로 가져왔기 때문이다.
이때 나이_1 컬럼처럼 년도 표시 방식을 RR로 변경하면 세기를 구분해준다. 따라서 EXTRACT(YEAR FROM SYSDATE)-EXTRACT(YEAR FROM TO_DATE(SUBSTR(EMP_NO,1,2),'RR')) 방식으로 구하게 되면 결과 값이 정상적으로 잘 나타나는데 이 때 새로운 문제가 생긴다. 1949년 이전에 태어난 사람은 다시 현세기로 구분하게 된다는 점이다.
이때는 그 이 전세기를 따로 계산하는 방식이 없으므로 해당 경우의 수에 대한 분기 처리를 작성해준다.
