저번 포스팅에서 프론트엔드 CI 쪽은 수정했지만, 백엔드 4개 서비스는 해결하지 못했다. 이번 포스팅에서는 백엔드 쪽 오류를 수정한 과정을 정리해보려 한다.
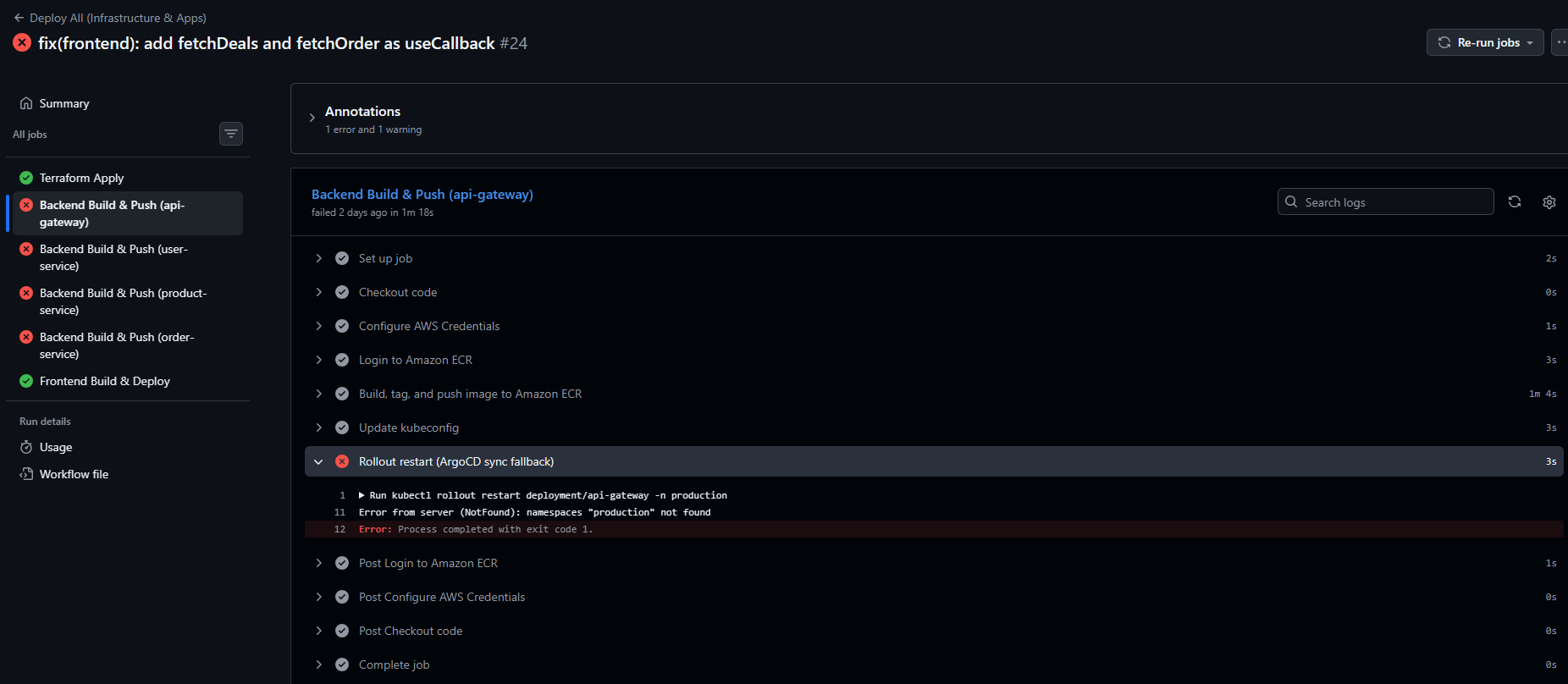
"production" not found 에러
이 에러는 production 네임스페이스가 존재하지 않아 발생하는 오류다.
원인을 파악해보니, terraform apply만 완료된 상태에서 아직 부트스트랩을 실행하지 않았기 때문에 발생하는 문제로 보였다.
기존 워크플로우에는 ECR에 이미지가 푸시된 이후 kubectl rollout restart를 실행하는 단계가 있었는데, ArgoCD가 자동으로 Sync를 수행하므로 해당 스텝은 사실상 불필요했다. 따라서 deploy-all.yml에서 아래 구간을 제거했다.
- name: Update kubeconfig
run: aws eks update-kubeconfig --region ${{ env.AWS_REGION }} --name ${{ env.EKS_CLUSTER }}
- name: Rollout restart (ArgoCD sync fallback)
run: |
kubectl rollout restart deployment/${{ matrix.service }} -n production그런 다음 자동으로 Actions가 실행되기 때문에 기다려주었다.
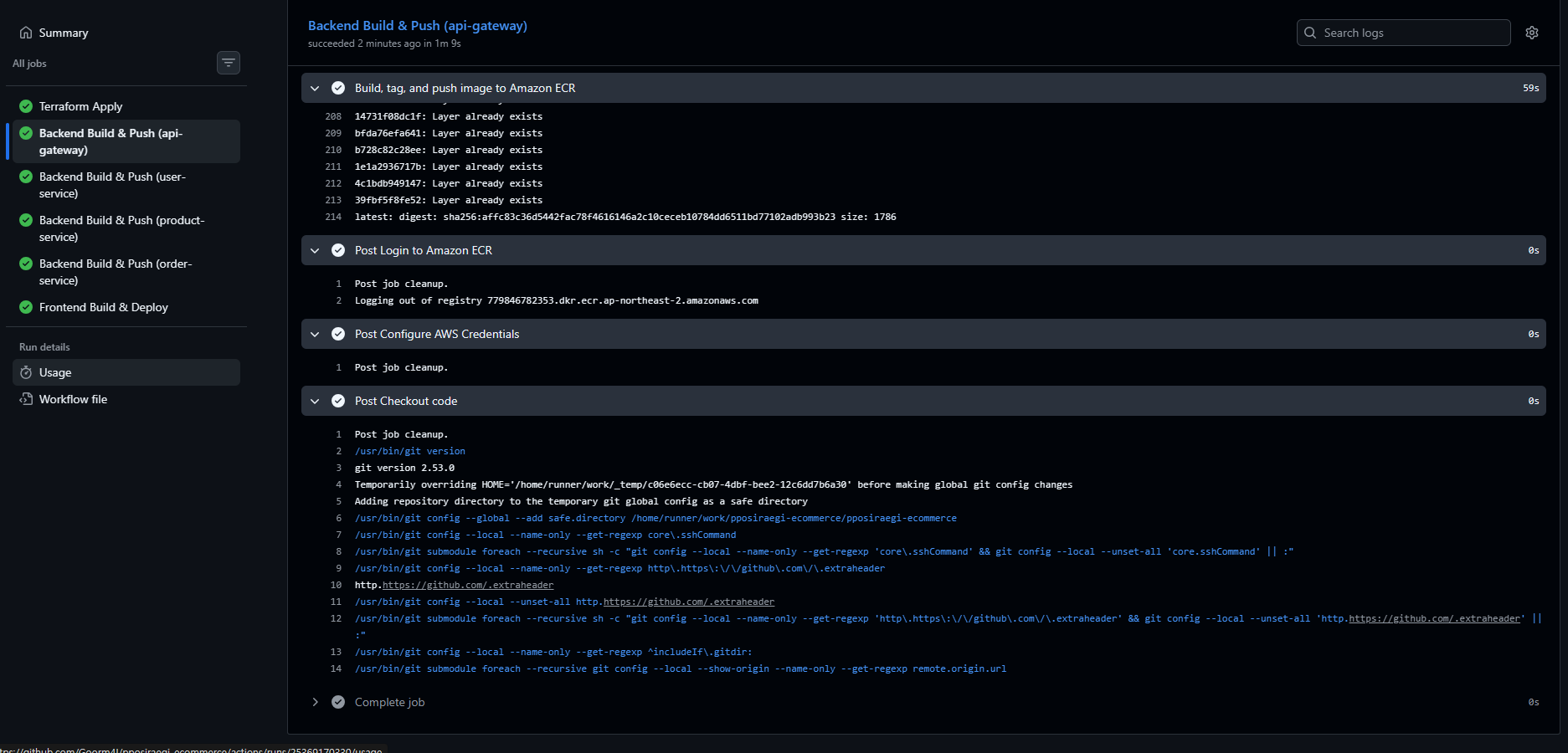
수정 후 GitHub Actions가 자동으로 트리거되었고, 결과는 성공이었다.

정도를 걷는 엔지니어