이번 게시물에서는 Grafana 대시보드에서 Dashboard > New panel을 통해 Histogram 시각화를 직접 만들어보는 과정을 정리해본다.
목표는 Kubernetes API Server 요청 처리 시간의 분포를 히스토그램으로 확인하는 것이다.
API Server 요청 지표 확인
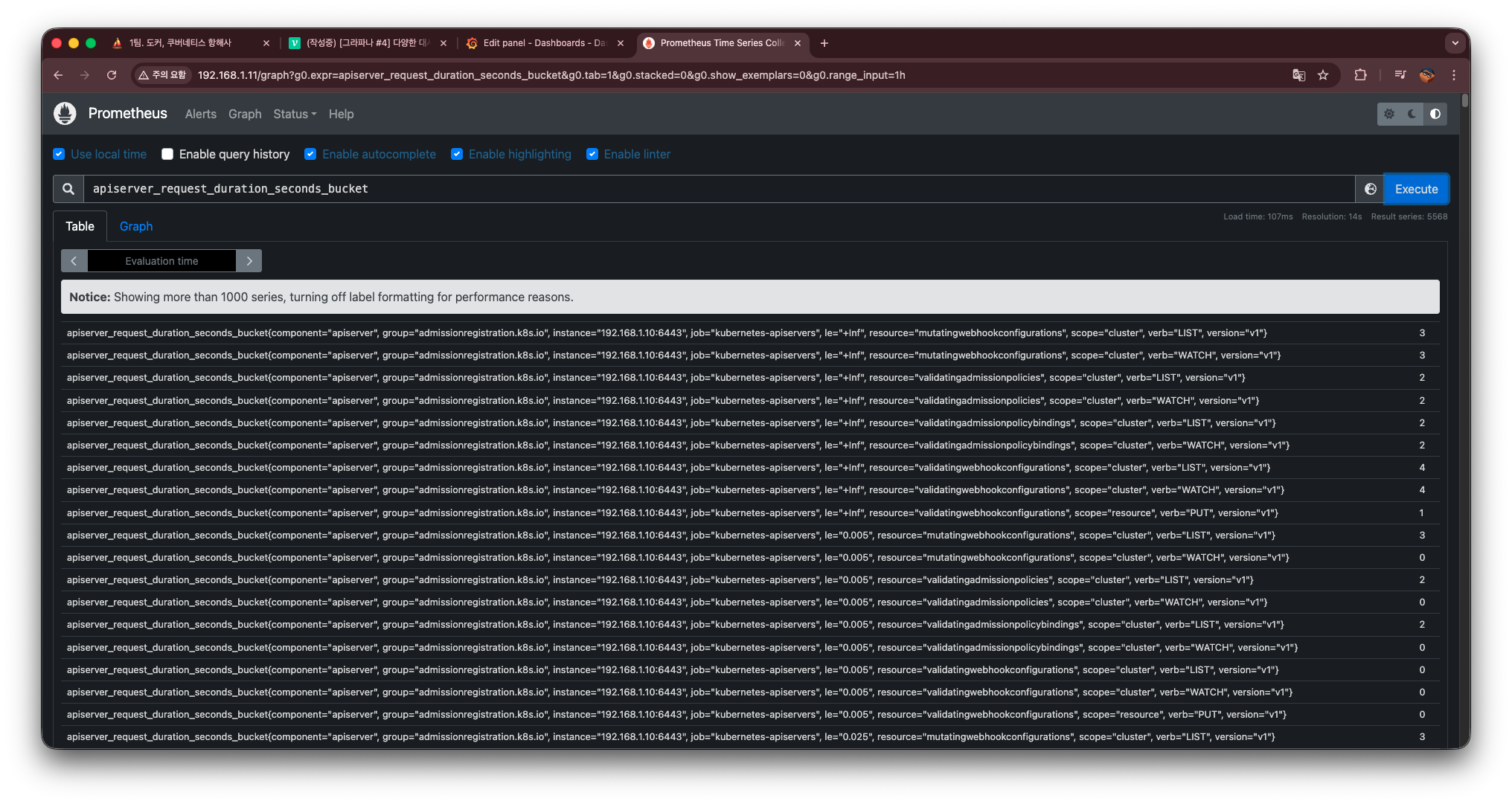
우선, 데이터가 정상적으로 수집되고 있는지를 확인하기 위해 Prometheus 쿼리를 먼저 실행한다.
apiserver_request_duration_seconds_bucket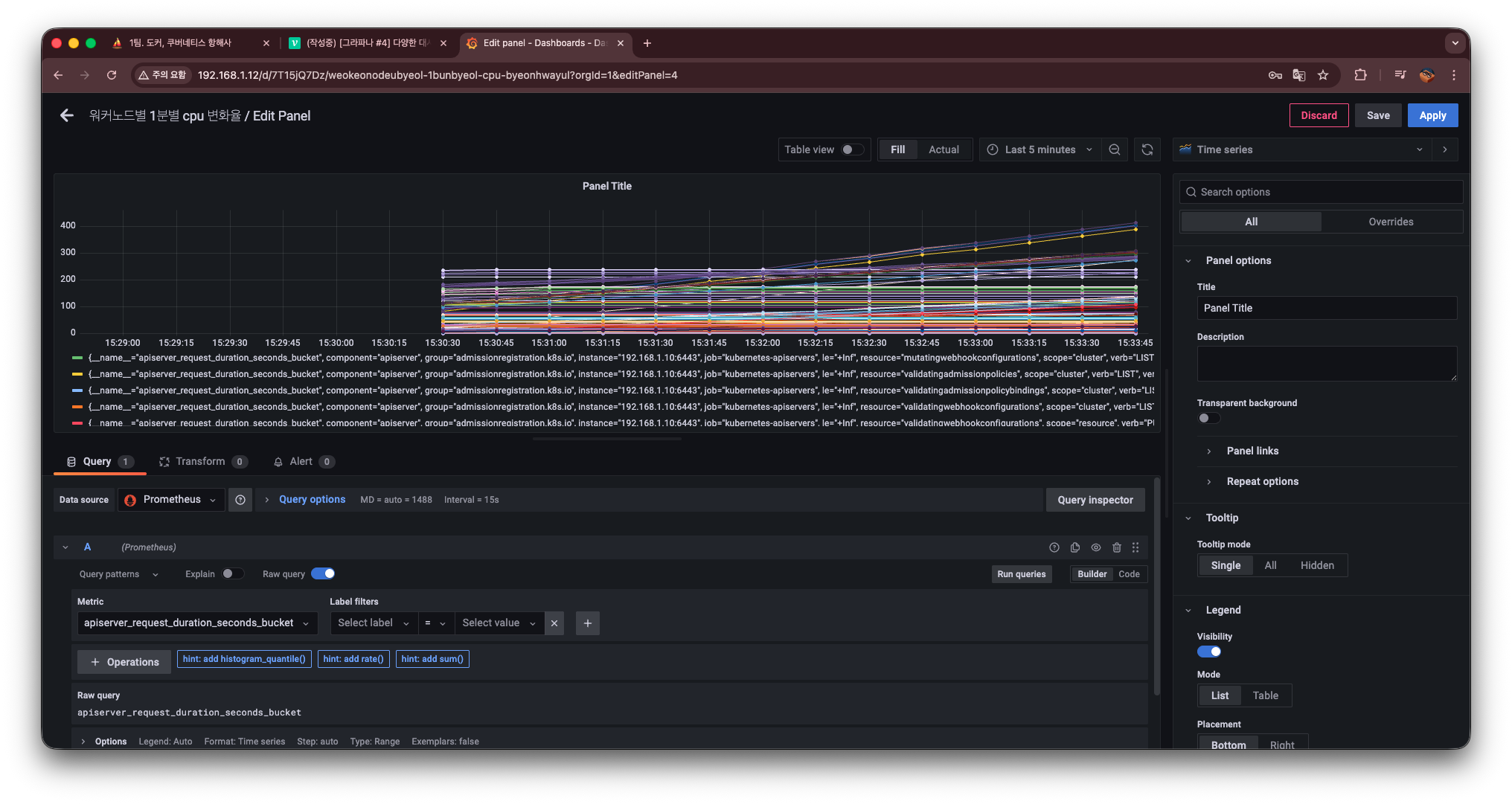
이 쿼리는 Kubernetes API Server가 요청을 처리하는 데 걸린 시간을 버킷(bucket) 단위로 누적 카운트한 히스토그램 메트릭이다.
그래프가 정상적으로 출력된다면, Prometheus에서 해당 메트릭을 문제없이 수집 중이라는 의미다.
histogram_quantile 사용
Grafana의 suggestion에 표시된 쿼리를 클릭해 다음 쿼리를 실행한다.
histogram_quantile(0.95, sum by(le) (rate(apiserver_request_duration_seconds_bucket[$__rate_interval])))이 쿼리의 의미는 다음과 같다.
-
rate(...)
→ 히스토그램 버킷 값의 초당 증가율을 계산한다. -
sum by(le)
→ 여러 시계열을 le(less than or equal) 버킷 기준으로 합친다. -
histogram_quantile(0.95, ...)
→ 95퍼센타일(95% 요청이 이 값 이하로 처리됨) 을 계산한다.
즉,
“최근 구간에서 API 요청의 95%가 이 시간 이내로 처리된다” 라는 값을 시계열로 보여주는 쿼리다.
실행하면 다음과 같이 표 형태의 결과가 출력된다.
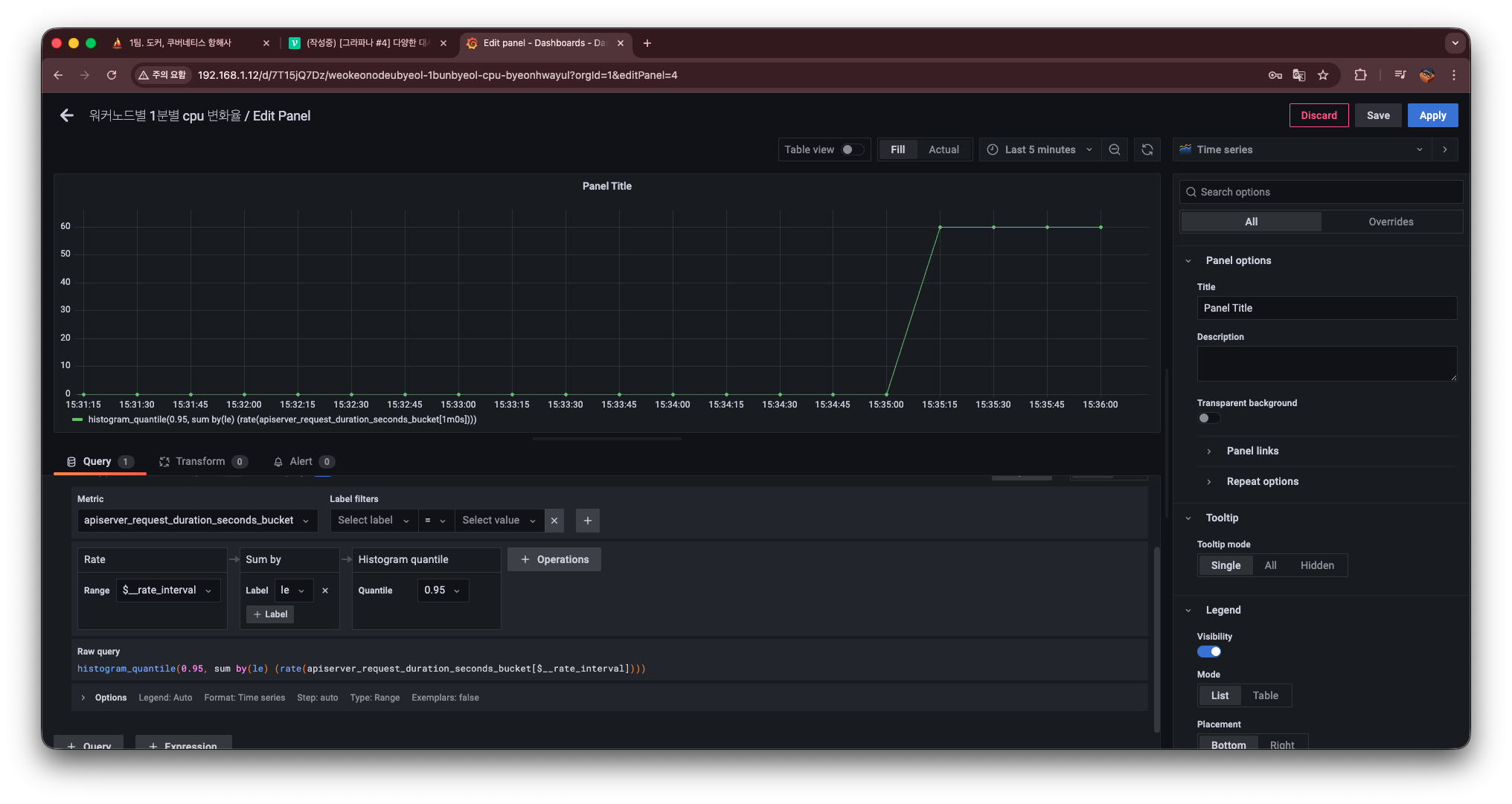
조회 시간을 1분 단위로 변경
기본 $__rate_interval 대신, 고정된 1분 기준으로 보고 싶어서 다음과 같이 수정한다.
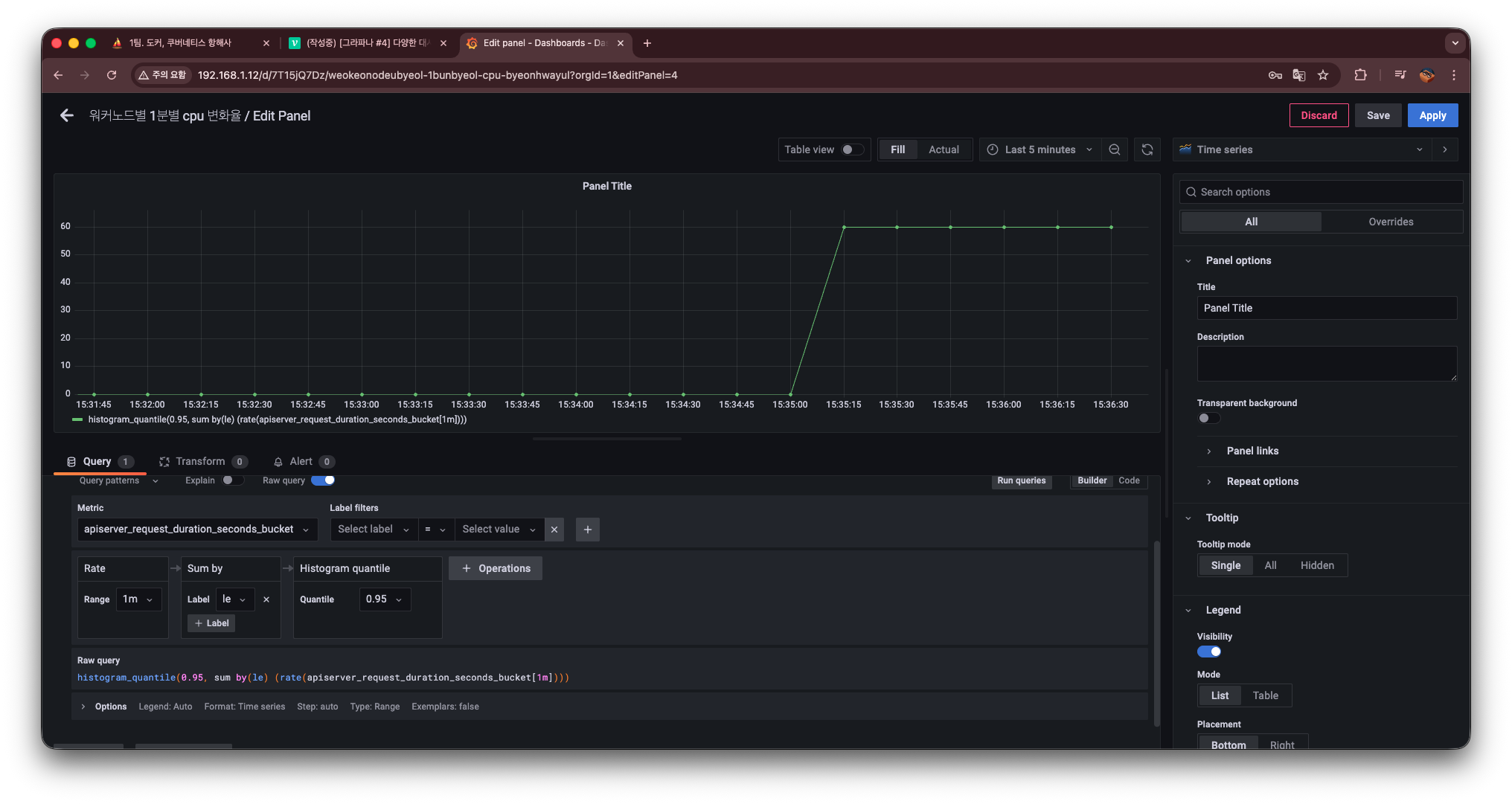
histogram_quantile(0.95, sum by(le) (rate(apiserver_request_duration_seconds_bucket[1m])))이렇게 하면 1분 단위로 계산된 API Server 요청 지연 시간의 95퍼센타일 값을 확인할 수 있다.
특정 요청 타입(GET)만 필터링
이번에는 모든 요청이 아니라, GET 요청만 대상으로 분석해본다.
histogram_quantile(0.95, rate(apiserver_request_duration_seconds_bucket{verb="GET"}[1m]))여기서 {verb="GET"} 은
아래와 같이 apiserver_request_duration_seconds_bucket 메트릭에 포함된 레이블을 기반으로 필터링한 것이다.
apiserver_request_duration_seconds_bucket즉,
API Server로 들어오는 GET 요청의 처리 시간 분포만 따로 분석하게 된다.
그래프가 직관적이지 않은 이유
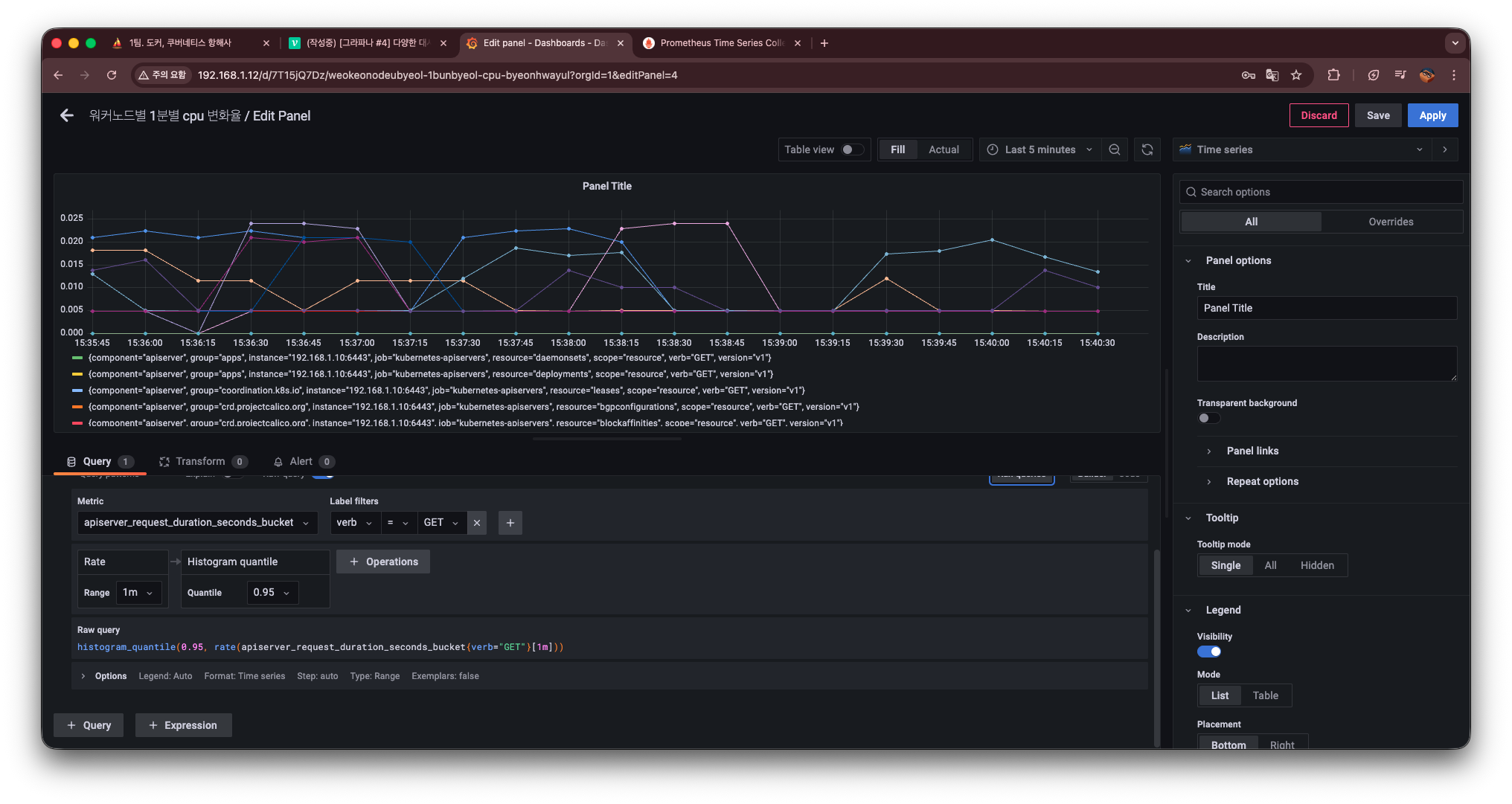
이 상태로 Grafana에서 조회하면 다음과 같이 그래프가 출력된다.
하지만 이 그래프는
시간에 따른 값 변화는 보이지만, 요청 지연 시간 분포를 한눈에 파악하기는 어렵다
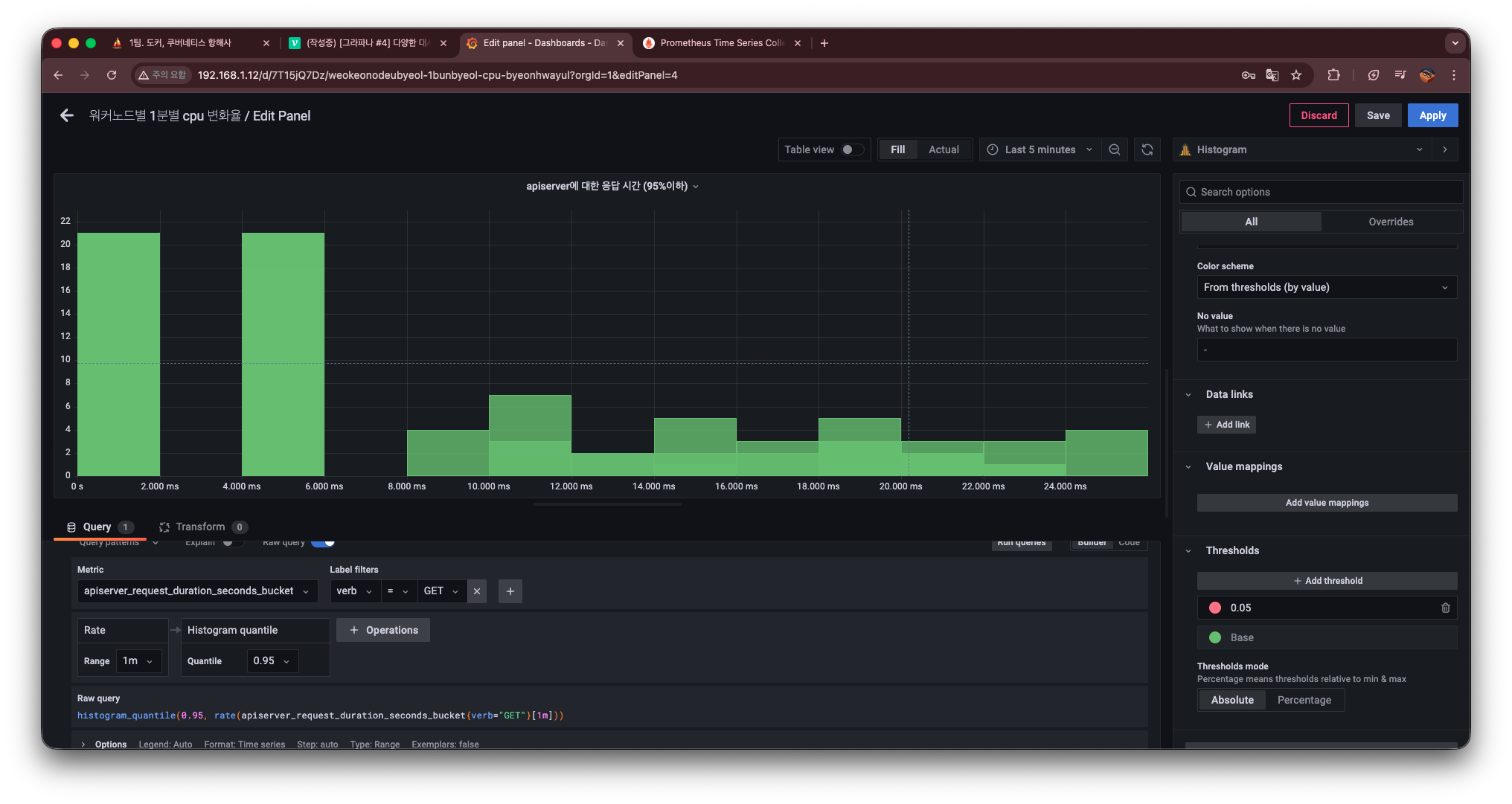
그래서 여기서 Visualization을 Histogram으로 변경한다.
Histogram 시각화 적용
Visualization에서 Histogram을 선택하면 다음과 같이 변경된다.
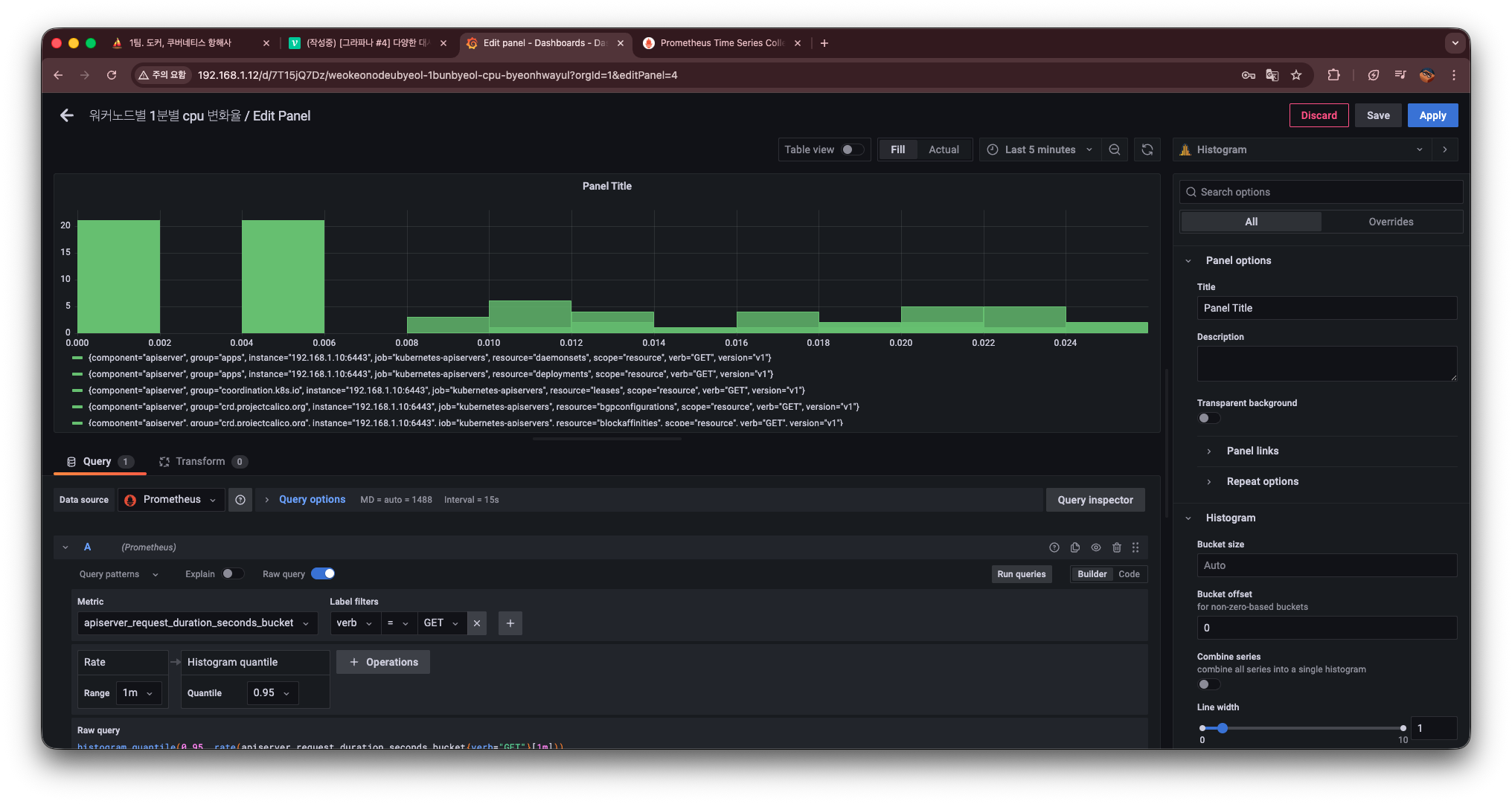
그러면 이와 같이 히스토그램으로 변경된 것을 확인할 수 있으며, API 서버의 요청 시간에 따른 각 구간의 빈도수를 시각적으로 효과적으로 확인할 수 있게 된다.
단위 및 임계값(Threshold) 설정
마지막으로 가독성을 높이기 위해 단위와 임계값을 설정한다.
- Unit → time / seconds 로 설정
→ 요청 처리 시간이 초 단위라는 것을 명확히 표시
그리고 SRI / SLO 관점에서 임계값을 보기 위해 Threshold를 추가한다.
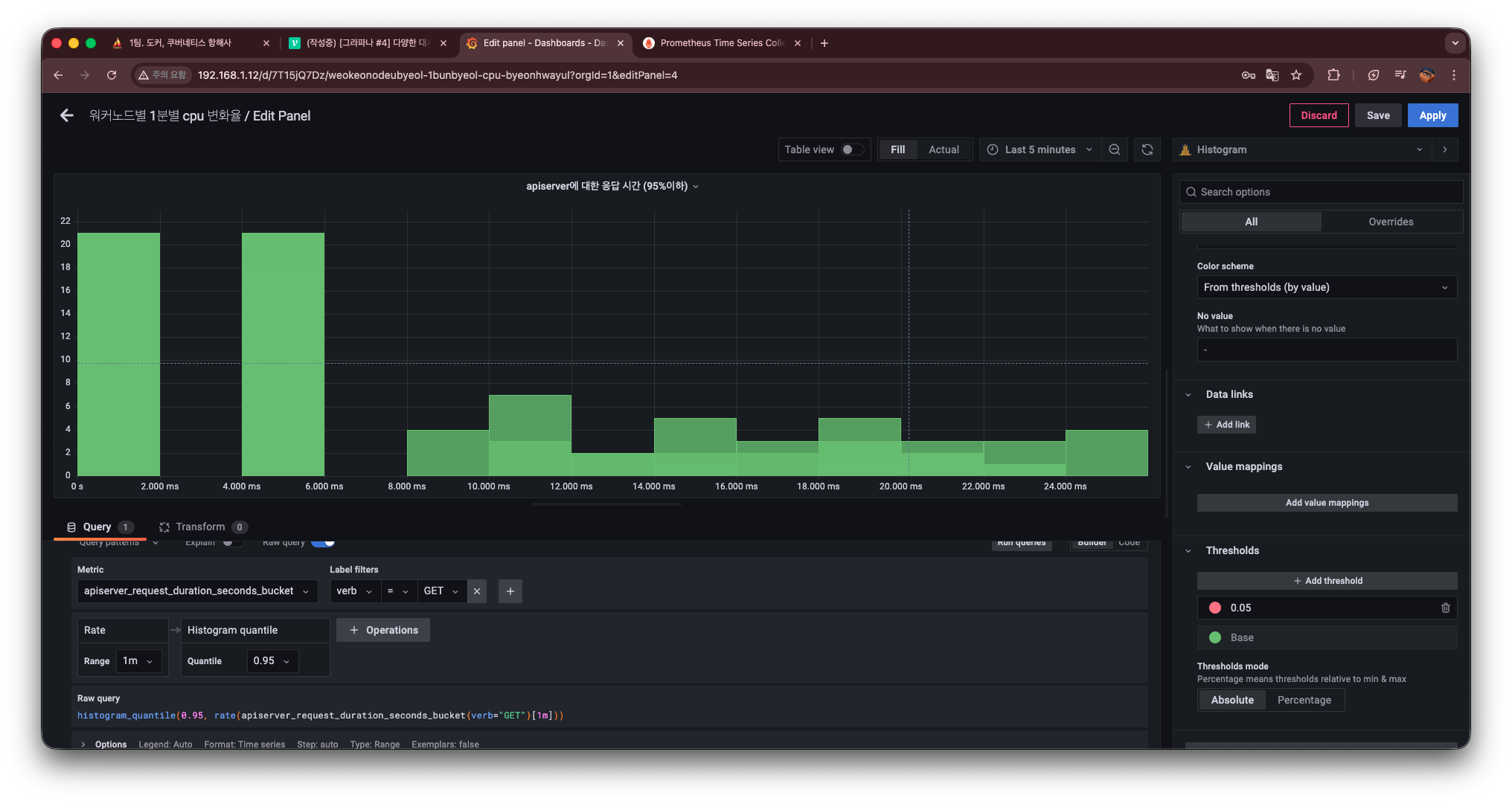
- Threshold 값: 0.05
- 색상: 빨간색
이렇게 설정하면
0.05초 이하 구간에 있는 요청들을 “문제가 있는 영역”으로 직관적으로 인지할 수 있다.
해당 게시물은 인프런 강의 중 "실습으로 배우는 그라파나"를 참고하여 작성하였습니다.
