프로메테우스 Web UI
Runtime & Building information
Status에서 해당 메뉴로 들어가게 되면 다음과 같이 나온다.
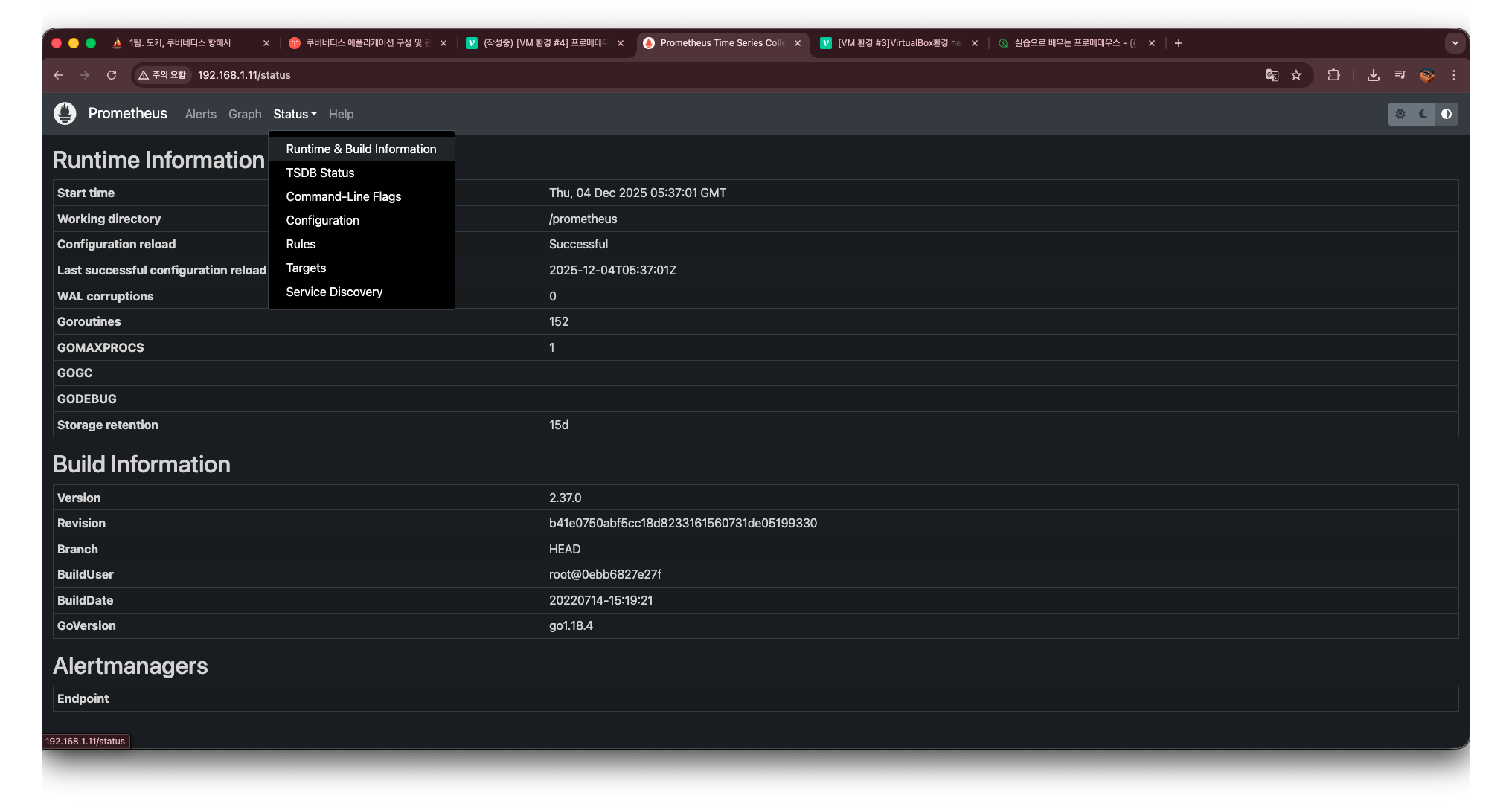
여기에서 중요한 부분은 build information에 있는 version 부분인데,
현재 내가 쓰고 있는 버전은 2.37.0 버전인데 이 버전 정보는 왜 중요하냐면, 프로메테우스는 버전마다 지원하는 기능, 쿼리 문법, 설정 옵션, 플래그, 실험 기능 여부 등이 꽤 크게 달라지기 때문이다.
특히 현재 사용하는 2.37.0 버전은 LTS 느낌으로 많이 쓰이던 안정 버전이지만, 이후 버전들에서는 다음과 같은 변화들이 있었다:
- TSDB 성능 개선
- 메트릭 압축 방식 최적화
- Alertmanager와의 연동 방식 일부 변경
- Experimental 기능들이 정식 기능으로 승격
- Scrape / Evaluation Interval 관련 Flag 변화
- 웹 UI 개선
- 보안 관련 패치 적용
따라서 운영 환경이나 실습 환경에서 문제가 생겼을 때
“현재 내가 쓰는 버전이 어떤 기능을 지원하고 어떤 제약이 있는지”
정확히 파악하는 기준이 된다.
TSDB Status
두 번째 부분은 status를 눌러서 나오는 TSDB Status부분이다.
이 화면에서는 프로메테우스가 내부적으로 저장하고 관리하는 시계열 데이터의 상태를 실시간으로 확인할 수 있다.
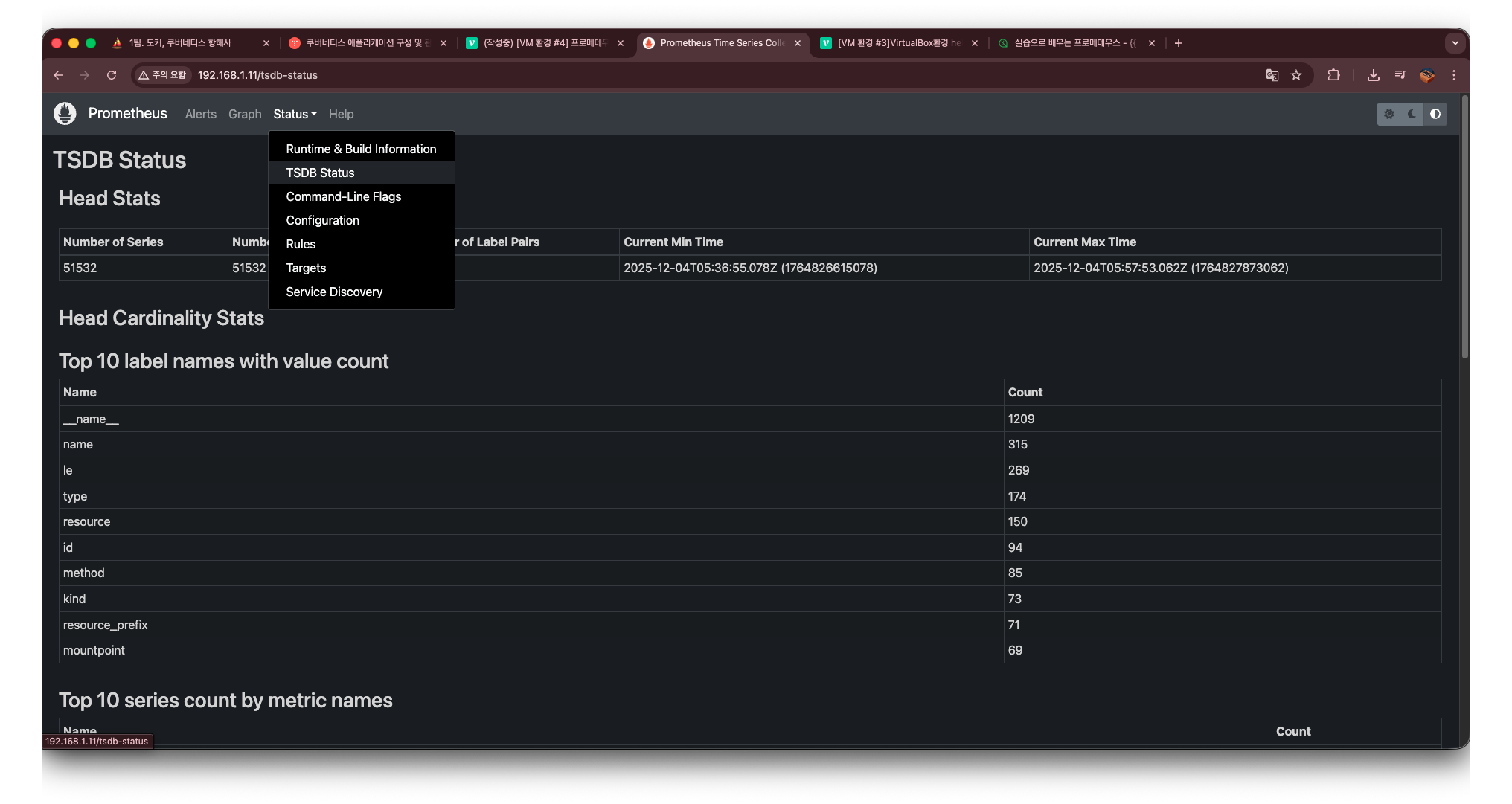
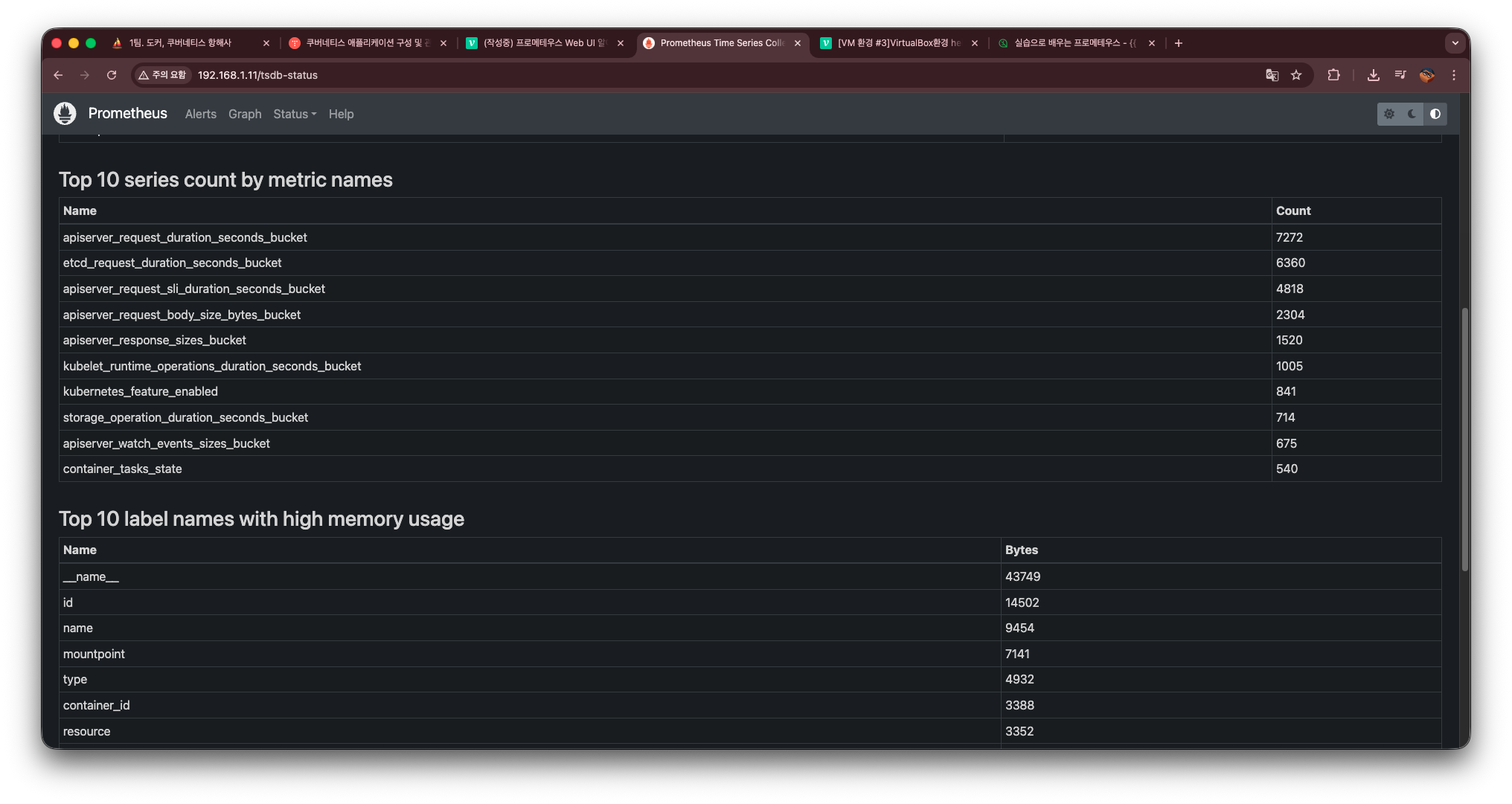
여기에 표시되는 값들은 단순한 정보가 아니라,
PromQL로 직접 조회할 수 있는 메트릭이며, 실제 운영 환경에서 문제를 진단할 때 매우 유용하게 활용된다.
TSDB Status에서 확인할 수 있는 대표적인 항목들은 다음과 같다:
-
Head Samples / Head Chunks
→ 메모리에 올라와 있는 최신 샘플 데이터량.
이 수치가 갑자기 급격히 증가하면 스크레이프 폭증 또는 메트릭 폭주 가능성이 있음. -
Number of Series
→ 현재 TSDB가 관리 중인 전체 시계열 메트릭 수.
서비스가 비대해지면 여기 값이 수십만~백만 단위까지 늘어날 수 있으며, OOM 문제와 직결됨. -
Compactions
→ TSDB가 데이터 블록을 디스크에 정리하고 압축하는 작업.
compaction 시간이 너무 길거나 자주 발생하면 디스크 I/O 병목이 의심되는 구간. -
WAL(Write Ahead Log) Size
→ 장애 발생 시 데이터를 복구하기 위해 기록하는 로그.
WAL 파일이 너무 커지면 디스크 사용량 경고나 복구 시간이 길어질 수 있다.
이 값들이 의미하는 것은 크게 두 가지다:
- 현재 프로메테우스가 얼마나 많은 매트릭을 처리하고 있는지
- 성능 문제(메모리 부족, 디스크 I/O 지연 등)를 미리 감지하는 지표
즉, TSDB Status는 프로메테우스의 "건강 상태"를 보여주는 심장박동기 같은 화면이며, 단순 정보가 아니라 모두 PromQL로 조회/대시보드화 가능한 메트릭들이다.
command-line-flags
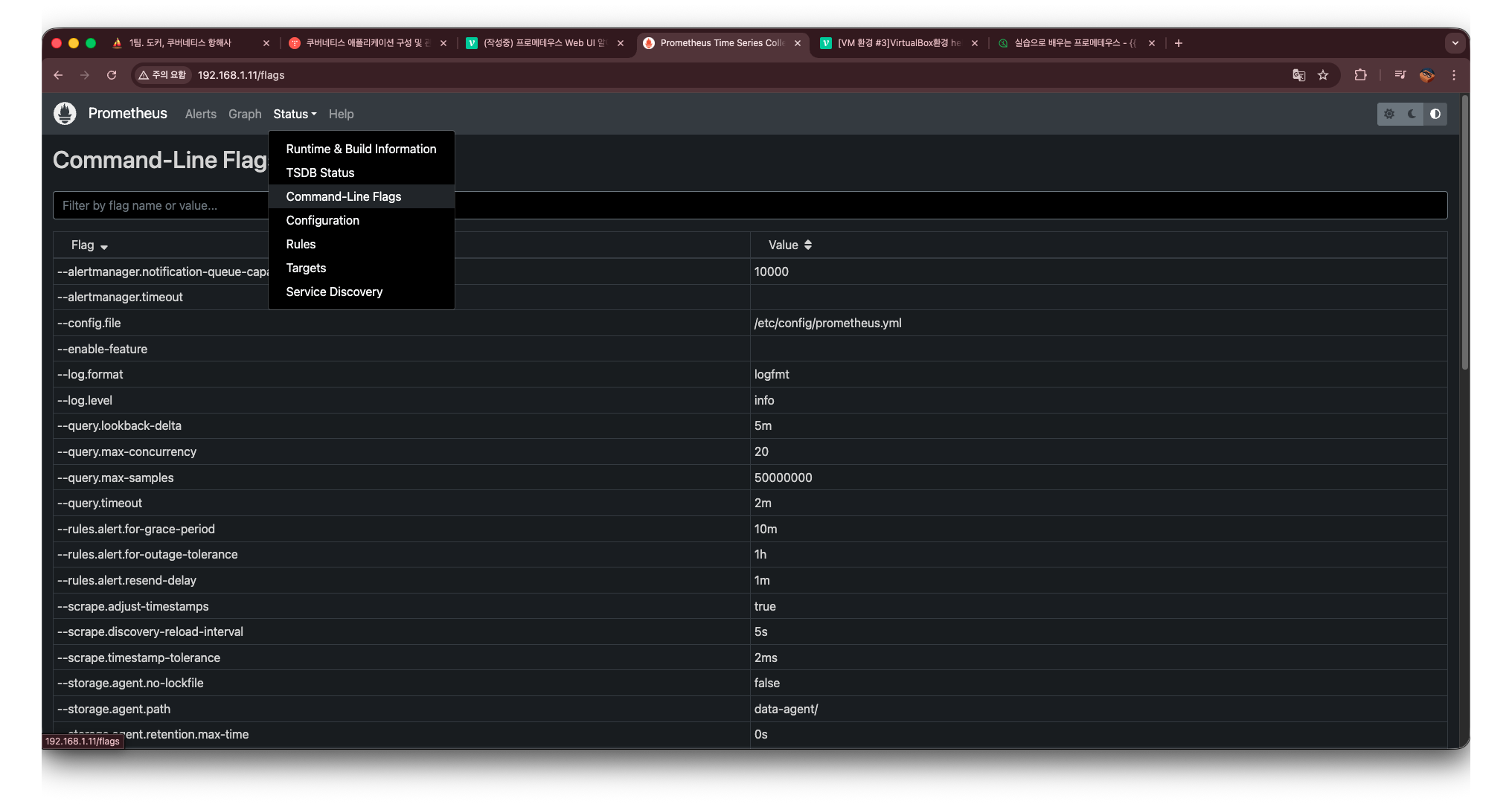
Command-line-flags 메뉴에서는 현재 실행 중인 Prometheus 서버가 어떤 옵션(플래그)들을 사용하여 구동되고 있는지를 한눈에 확인할 수 있다.
프로메테우스는 설정 파일(prometheus.yml) 외에도, 실행 시 전달되는 CLI 플래그에 따라 내부 동작 방식이 크게 달라진다. 이 메뉴에서는 실제로 컨테이너 또는 바이너리가 어떤 파라미터로 실행되었는지 그대로 확인할 수 있다.
여기서 확인 가능한 정보는 다음과 같다:
-
config.file
→ 프로메테우스가 어떤 설정 파일을 사용하고 있는지
(Helm chart로 배포했을 경우 ConfigMap 경로가 표시됨) -
storage.tsdb.path
→ TSDB가 디스크에 저장되는 위치.
디스크 용량 모니터링이나 persistence 설정할 때 중요한 값. -
web.enable-lifecycle
→ /-/reload API 활성화 여부.
설정 파일을 수정한 뒤 Prometheus를 재시작 없이 reload할 수 있는지 결정하는 옵션. -
storage.tsdb.retention.time
→ 메트릭 데이터를 얼마나 오래 보관할지 결정하는 옵션.
보통 15d, 30d, 90d 등으로 설정하며 디스크 용량과 직결된다. -
query.timeout / query.max-concurrency
→ PromQL 쿼리 수행 시 타임아웃 및 동시 요청 제한.
대규모 클러스터에서 쿼리 병목을 막기 위해 중요한 파라미터. -
log.level
→ Prometheus 로그 레벨 (info / debug / warn 등).
문제 해결 시 레벨을 조정해 더 자세한 로그를 볼 수 있다.
즉,Command-line-flags 메뉴는 ‘지금 프로메테우스가 어떤 설정으로, 어떤 모드로, 어떤 파라미터를 적용해 실행 중인지’를 가장 정확하게 보여주는 곳이다.
Configuration
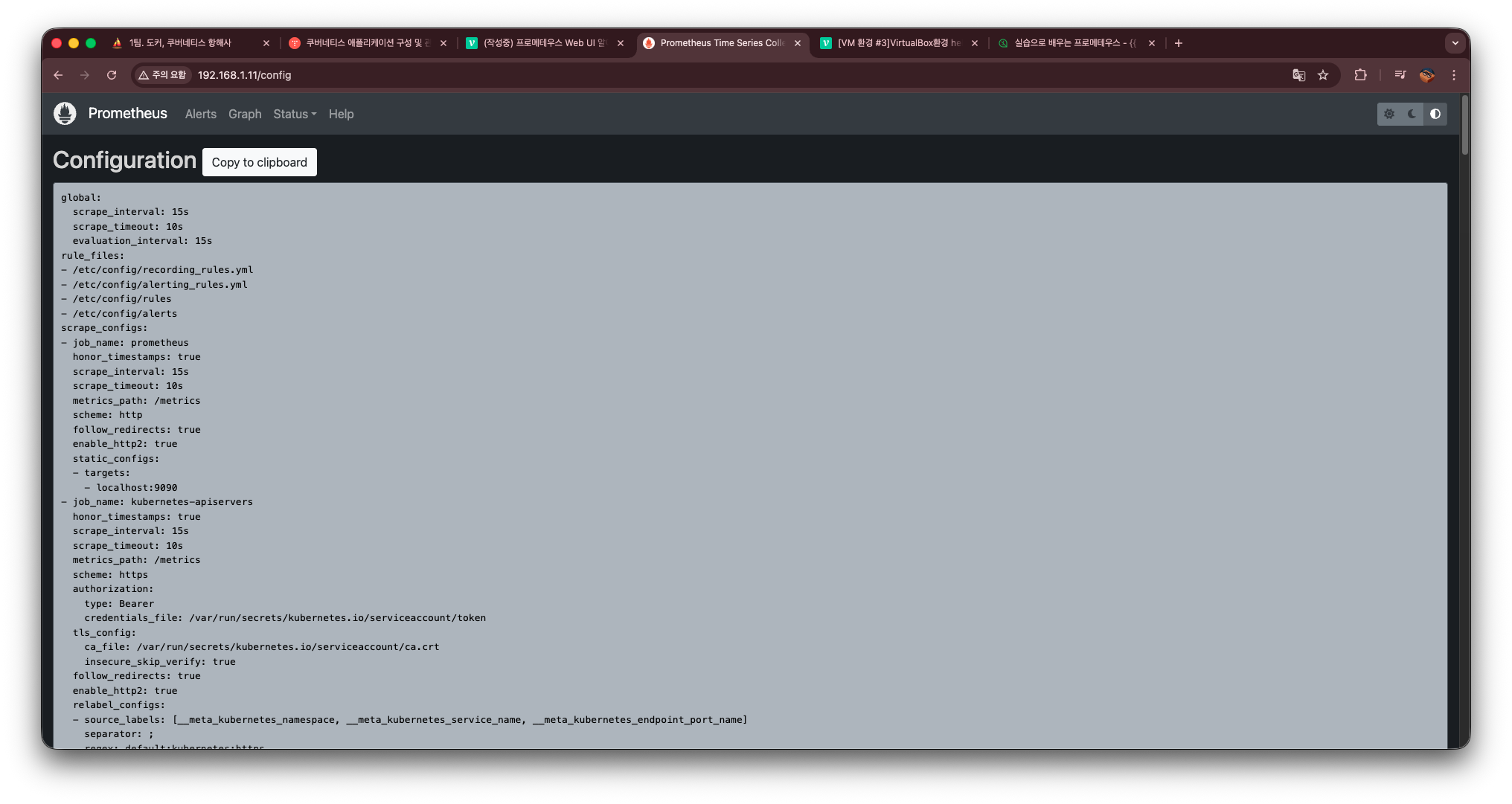
Configuration 메뉴에서는 현재 Prometheus 서버가 사용 중인 설정 파일(prometheus.yml)의 실제 적용 내용을 그대로 확인할 수 있다.
Helm Chart나 ConfigMap으로 배포했더라도, 여기서는 런타임 기준 최종 반영된 설정이 보이기 때문에 가장 신뢰할 수 있는 설정 확인 방법이다.
이 화면에서 가장 먼저 눈에 띄는 부분이 바로 수집 주기(scrape_interval)인데, 프로메테우스가 얼마 주기로 메트릭을 긁어오는지를 제일 명확하게 확인할 수 있다.
예를 들어:
scrape_interval: 15s이 값은 프로메테우스가 15초마다 모든 scrape 대상에서 메트릭을 가져온다는 의미이다.
Global 단락
global: 블록은 프로메테우스 전체에 공통적으로 적용되는 기본 설정을 정의한다.
주로 포함되는 항목:
- scrape_interval : 기본 스크레이프 주기
- evaluation_interval : Alert 규칙 평가 주기
- scrape_timeout : 스크레이프 타임아웃
- 기본 labels (external_labels)
즉,
별도 설정이 없는 job은 모두 global에서 정의한 interval을 따르게 된다.
프로메테우스의 "기본 운영 속도"를 결정하는 가장 중요한 부분이다.
scrape_configs 단락
scrape_configs: 는 실제로 어떤 타겟(노드·애플리케이션·서비스·엔드포인트)을 어떻게 긁어올지 정의하는 목록이다.
여기에는 다음과 같은 정보가 포함된다:
- job_name: 메트릭 수집 대상 그룹 이름
- static_configs: 특정 IP나 서비스 엔드포인트 명시
- kubernetes_sd_configs: K8s 환경에서 자동 서비스 디스커버리
- relabel_configs: 라벨 변환 및 필터링 규칙
- metrics_path: 기본 /metrics를 다른 경로로 변경할 때 사용
- scheme: http / https 지정
즉,
scrape_configs는 프로메테우스가 “어디에서 무엇을 어떻게 수집할지” 정의하는 핵심 영역이다.
여기 정의된 job들(node-exporter, kube-state-metrics, kubelet 등)을 기준으로
실제로 TSDB에 저장되는 모든 시계열 데이터가 생성된다.
Target
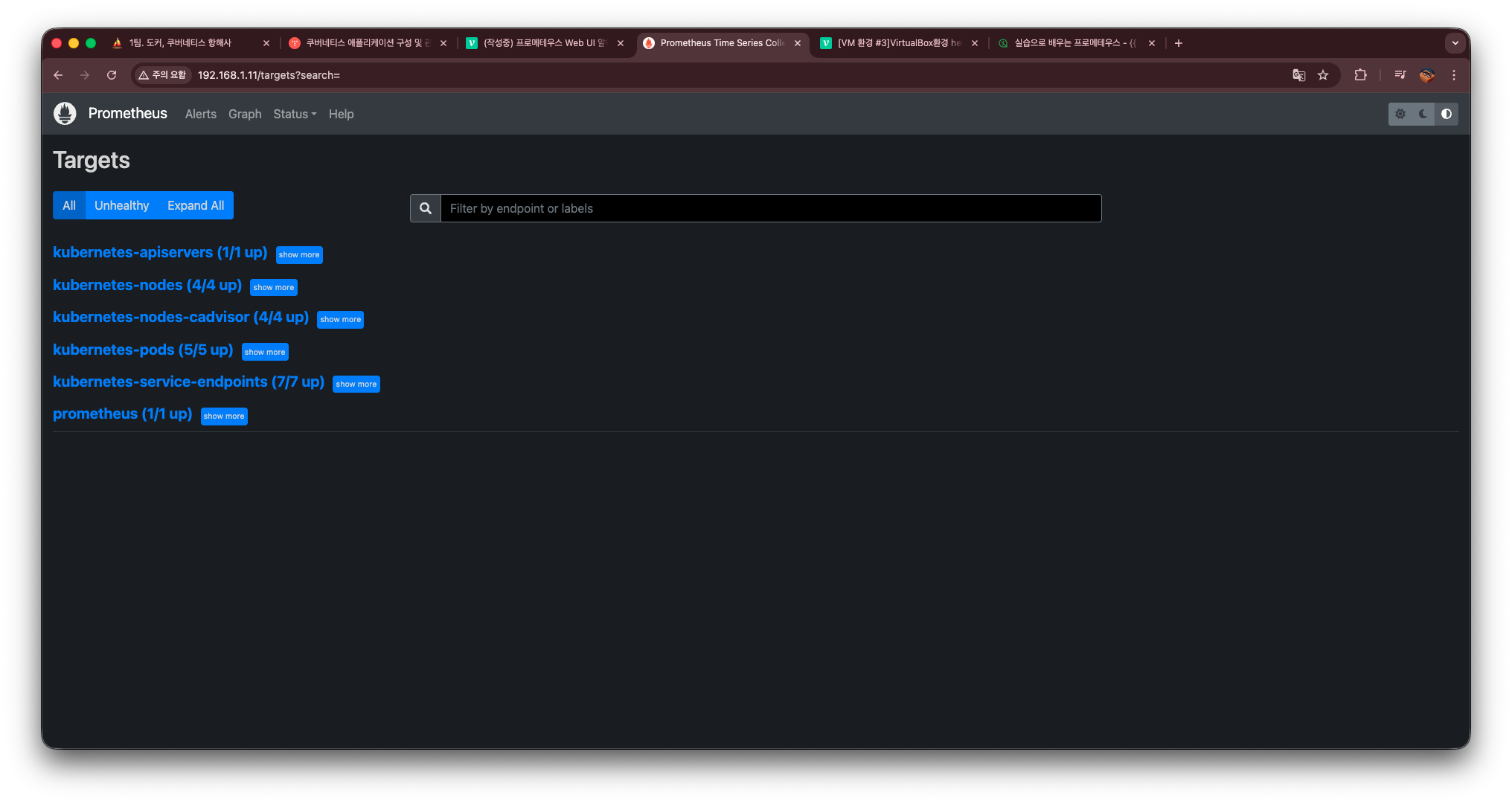
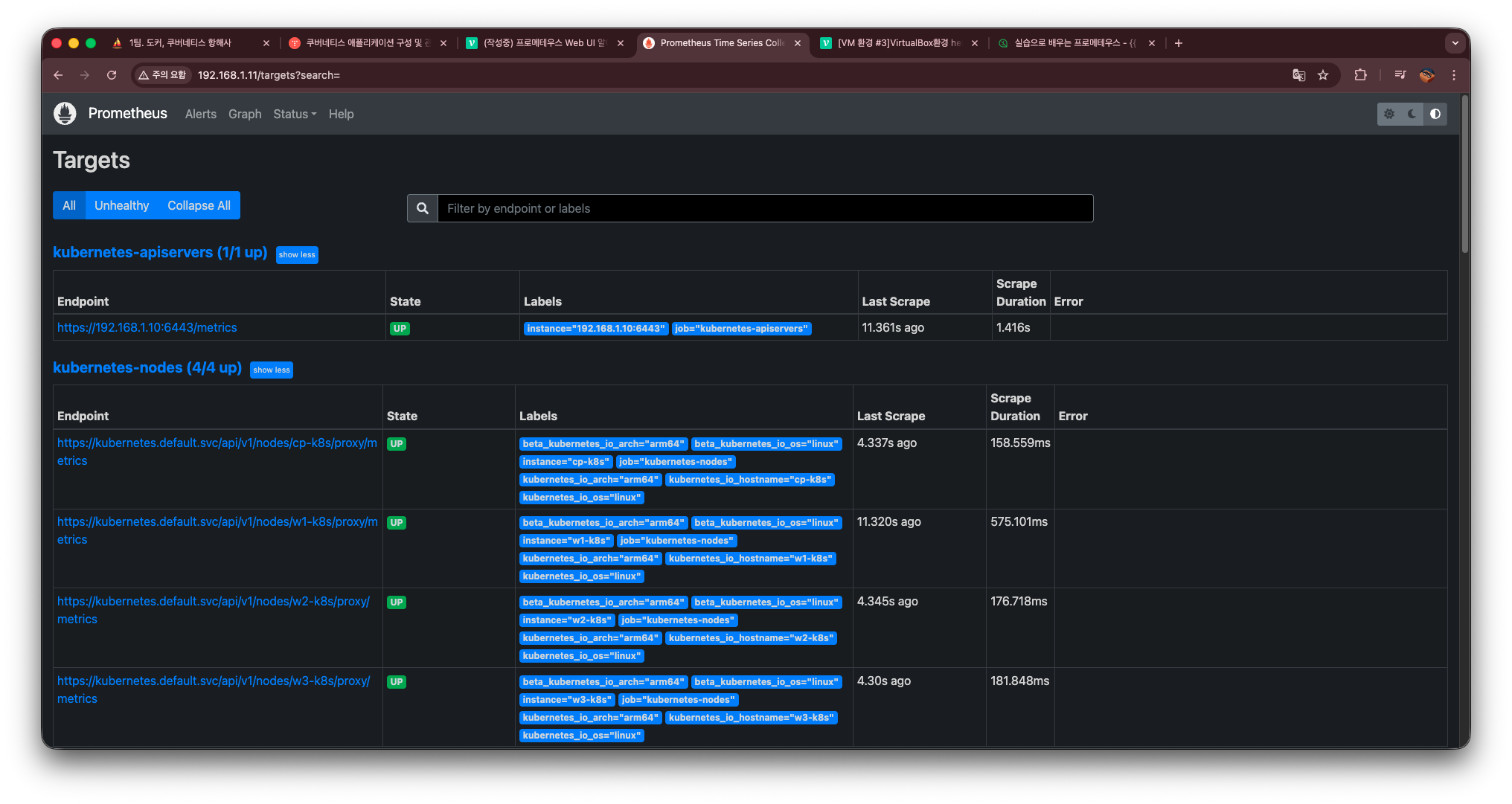
Target 탭은 Prometheus가 현재 어떤 엔드포인트(서비스, 노드, 애플리케이션 등)로부터 메트릭을 수집하고 있는지, 그리고 그 수집 상태가 정상인지를 한눈에 확인할 수 있는 메뉴이다.
여기서는 단순히 “대상이 올라왔는가?”만 보는 것이 아니라, 실제 운영 환경에서 매우 중요한 다음 요소들을 모두 확인할 수 있다.
1) UP / DOWN 상태 확인
Target 항목의 가장 중요한 부분이다.
-
UP(● green)
→ scrape 주기마다 정상적으로 메트릭 수집이 되고 있는 상태 -
DOWN(● red)
→ 타겟이 응답하지 않거나 /metrics 엔드포인트 자체가 열려있지 않은 상태
→ 네트워크 문제, 권한 문제, 파드 종료 등이 의심.
UP/DOWN 여부는 Prometheus의 availability를 실시간으로 보여주는 지표다.
2) last scrape 시간
Prometheus가 마지막으로 이 타겟에서 메트릭을 가져간 시각.
scrape_interval 설정과 비교했을 때 “지연”이 있는지 확인할 수 있다.
ex)
- scrape_interval = 15s
- last scrape = 50s ago → 문제 의심
3) scrape duration (수집 소요 시간)
메트릭을 긁어오는 데 걸린 시간.
이 값이 갑자기 증가하면:
- 타겟 서버 부하 증가
- 네트워크 지연
- /metrics 출력량 증가
같은 원인들이 의심될 수 있다.
4) Labels 확인
Prometheus는 수집한 타겟마다 다양한 라벨을 자동으로 붙인다.
ex)
instance="192.168.1.10:9100"
job="node-exporter"
namespace="monitoring"
pod="prometheus-node-exporter-xxxx"이 라벨들이 후에 PromQL 쿼리나 Grafana 대시보드에서 핵심 역할을 한다.
5) Discovery 정보 확인
Target 페이지에서 Service Discovery를 클릭하면
Prometheus가 Kubernetes 내부에서 어떤 식으로 타겟을 자동 감지했는지도 볼 수 있다.
이는 kubelet, node-exporter, kube-state-metrics 같은 기본 컴포넌트들이
왜 자동으로 수집되는지 이해하는 데 도움이 된다.
6) 요약
Target 탭은 “Prometheus가 실제로 메트릭을 잘 긁어오고 있는지”를 기술적으로 검증하는 가장 핵심적인 화면이다.
여기 UP/DOWN 상태만 보더라도 현재 클러스터가 건강한지 빠르게 판단할 수 있다.
Service Discovery
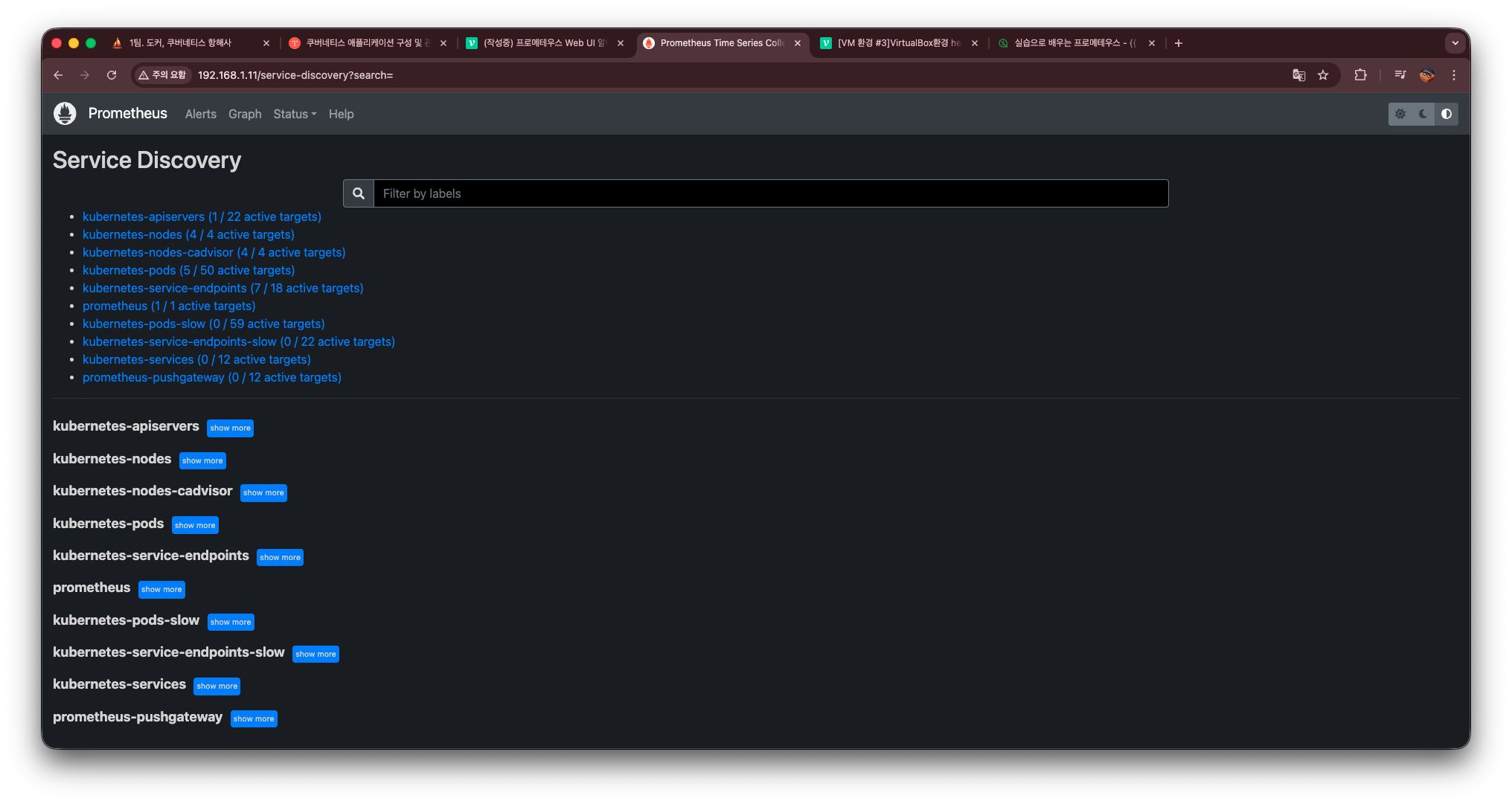
Service Discovery는 Prometheus가 어떤 방식으로 메트릭 수집 대상(Target)을 자동으로 찾아내고, 그 타겟이 어떤 정보에서 유래했는지(출처)를 보여주는 메뉴이다.
Prometheus는 단순히 static_configs에 적힌 주소만 긁는 방식이 아니라,
쿠버네티스 환경에서는 자동 감지(Auto Discovery) 기능을 통해 동적으로 타겟을 생성한다.
이때 실제로 어떤 리소스에서 어떤 타겟이 만들어졌는지 확인하는 것이 바로 이 화면이다.
1) 쿠버네티스 기반 서비스 디스커버리(Kubernetes SD) 확인
Prometheus Helm chart에서는 다음과 같은 방식으로 자동 탐색이 설정되어 있다:
-
Node
→ 노드의 Internal IP를 기반으로 node-exporter 타겟 생성 -
Pod
→ prometheus.io/scrape: "true" 라벨이 붙은 Pod 자동 감지 -
Service
→ 특정 포트가 노출된 Service를 자동 감지 -
Endpoints / EndpointSlice
→ Service 뒤에 실제 연결된 Pod 목록 기반으로 Target 생성
Service Discovery 메뉴에서는 위와 같은 각 소스별로
Prometheus가 어떤 메트릭 엔드포인트를 발견했는지가 리스트로 표시된다.
2) 라벨과 메타데이터 확인
각 발견된 항목에는 다양한 Kubernetes 메타데이터가 포함된다.
ex)
__meta_kubernetes_namespace
__meta_kubernetes_pod_name
__meta_kubernetes_service_name
__meta_kubernetes_node_name이 메타데이터들은 Prometheus 내부에서 relabel_configs 규칙을 통해
실제 타겟의 라벨(instance, job 등)로 변환되어 최종 Target이 된다.
즉, Service Discovery는 raw discovery → relabeling → final target
전체 과정 중 “raw discovery” 단계를 보여준다고 보면 된다.
3) Target이 어떻게 만들어졌는지 역추적 가능
예를 들어 Target 탭에서
node-exporter (192.168.1.10:9100) - UP
이런 항목을 보았을 때,
Service Discovery로 들어가면:
- 어떤 Node 리소스를 기반으로 만들어졌는지
- 어떤 relabel 작업을 거쳤는지
- 왜 이 Target이 포함되었는지 / 제외되었는지
이 모든 것을 확인할 수 있다.
운영 환경에서는 Target이 누락되거나 중복 있을 때,
문제 원인을 찾기 위해 반드시 확인하는 메뉴다.
Prometheus Service Discovery → Configuration → Target 생성 흐름도
┌─────────────────────────────────┐
│ prometheus.yml │
│ (Configuration) │
├─────────────────────────────────┤
│ global: │
│ scrape_interval: 15s │
│ scrape_configs: │
│ - job_name: 'kubernetes-nodes'│
│ - job_name: 'kube-state-metrics'
│ - job_name: 'node-exporter' │
└─────────────────────────────────┘
│
▼
┌─────────────────────────────────┐
│ Service Discovery (SD Phase) │
├─────────────────────────────────┤
│ Kubernetes API Server 조회 │
│ │
│ - Node 리스트 │
│ - Pod 리스트 │
│ - Service / Endpoints │
│ - Metadata(라벨, namespace 등) │
└─────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────┐
│ Raw Targets (초기 발견된 원시 타겟 목록) │
├────────────────────────────────────────────────┤
│ __meta_kubernetes_namespace="monitoring" │
│ __meta_kubernetes_pod_name="node-exporter-1" │
│ __meta_kubernetes_service_name="node-exporter" │
│ __address__="192.168.1.101:9100" │
└────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────┐
│ relabel_configs 적용 단계 │
├────────────────────────────────────┤
│ - __meta_* 값 → instance 라벨 변환 │
│ - 필요 없는 타겟 drop │
│ - metrics_path 변경 │
│ - job 라벨 생성 │
└────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────┐
│ Final Targets (최종 수집 대상) │
├──────────────────────────────────────────┤
│ instance="192.168.1.101:9100" │
│ job="node-exporter" │
│ namespace="monitoring" │
└──────────────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ Target 화면 │
├──────────────────────────────────┤
│ ● UP / DOWN 상태 확인 │
│ last scrape 시간 확인 │
│ scrape duration 확인 │
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────────────┐
│ Prometheus TSDB 저장 (15초 주기) │
├──────────────────────────────────────────┤
│ scrape_interval (global 기본값) │
│ → 메트릭 수집 → TSDB에 저장 │
└──────────────────────────────────────────┘
흐름은 다음과 같다.
1. Configuration(prometheus.yml)
- scrape_interval, scrape_configs 설정
- job name들을 통해 수집되는 대상을 만든다.(Service Discovery)
- sd_config: service discovery들을 위한 config라고 보면 된다.
- reachable, 도달할 수 있는 것들을 모아놓은 것들이 -> Targets
- Service Discovery
- Kubernetes API에서 Node/Pod/Service 자동 탐색
- metadata 기반으로 raw target 목록 생성
(3. Relabeling
- _meta_kubernetes* 메타데이터를 instance/job 라벨로 변환
- 필요 없는 대상 drop
- metrics_path, scheme 설정)
- Target 생성
- 최종적으로 실제 메트릭을 수집할 endpoint 확정
- Target UI에서 UP/DOWN 확인 가능
(5. TSDB 저장
- scrape_interval마다 메트릭 수집 → TSDB에 저장
- 이후 Query, Grafana 대시보드 등에서 활용)
즉 프로메테우스는 쿠버네티스 환경에서 “수집 가능한 대상(Endpoints)”을 자동으로 찾아내고,
그 엔드포인트가 노출하는 메트릭을 주기적으로 스크레이프하여 TSDB에 저장하게 된다.
위 글은 실습으로 배우는 프로메테우스를 참고하였습니다.
