셋 & 해시 셋
셋(Set)
- 데이터를 저장하는 추상자료형(ADT)
- 순서를 보장하지 않음
- 데이터의 중복을 허용하지 않음
- 데이터 조회가 List보다 빠름
Set의 활용처
- 중복된 데이터를 제거해야 할 때(중복 미허용 특성 활용)
- 데이터의 존재 여부를 확일해야 할 때(빠른 데이터 조회 속도 특성)
Set 구현체
- hash set
- linked hash set(java)
- tree set(java)
Hash Set
해시 테이블을 사용하여 구현하기 때문에 크기 상관없이 데이터 조회가 매우 빠르다.
Java에서의 hash set 구현체
생성자로 Java의 HashMap을 사용하고 있다.
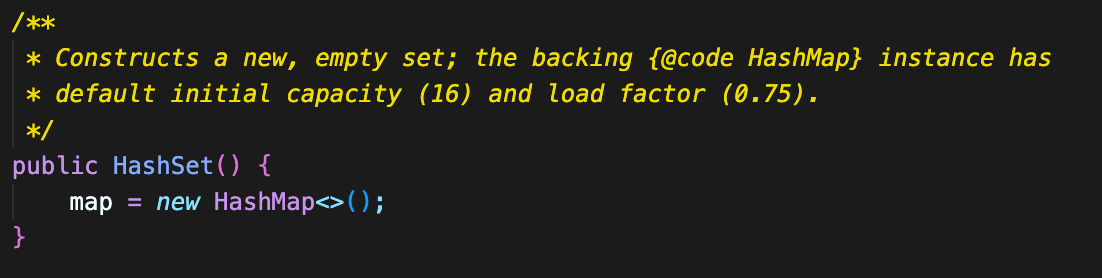
HashSet의 add 메소드 또한 내부적으로 HashMap을 사용하고 있기 떄문에 map.put() 메서드를 사용한다.
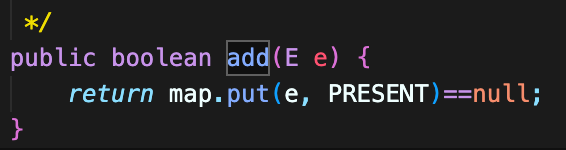
map.put()의 value 값은 더미 객체를 사용한다.

Java HashSet 사용 예제
Set<String> unique = new HashSet<>();
unique.add("가");
unique.add("나");
unique.add("다");
System.out.println(unique.size()); // 2
System.out.println(unique.contains("나")); // true
System.out.println(unique.contains("라")); // falseJava HashSet 특징
| Java HashSet | |
|---|---|
| 구현 | hash table 사용 |
| 데이터 접근 시간 | (일반적으로) 모든 데이터를 상수 시간에 접근 |
| 해시 충돌 해결 방법 | Separate chaining |
| default init capacity | 16 |
| resize 타이밍 | (일반적으로) 맵 사이즈의 3/4 이상 데이터 존재 시 |
| resize 규모 | 2배 |
| hash table capacity | power of 2(2의 승으로만 존재) |
List와 Set 중 무엇을 써야할까?
상기 'Set의 활용처'와 같이 Set을 사용하는게 더 적절한 상황이 아니라면, 거의 대부분 List를 사용해도 무리가 없다.
만약 데이터들이 이미 중복이 없고, 순서가 문제가 되지 않을 때 iteration 목적으로만 저장하려 한다면?
List가 메모리도 적게 사용하고(해시값을 저장하지 않음), set보다 단순한 list의 구현 특성 상 iteration이 더 빠르기 때문에 이 경우에도 List 특히 ArrayList를 사용하는 것이 좋다.
List와 Set의 차이점
| List | Set | |
|---|---|---|
| 구현체 | array list, linked list | hash set, linked hash set, tree set |
| 중복 데이터 저장 | 가능 | 불가능 |
| 데이터 조회 속도 | 상대적으로 느림 | 상대적으로 빠름 |
| 순서 존재 유무 | 있음 | 구현체에 따라 다름(hash set은 불가능) |
| 메모리 사용량 | 상대적으로 덜 사용 | 상대적으로 더 사용 |

나의 개발로그