세그먼트 트리란?
주어진 데이터의 구간 합과 데이터 업데이트를 빠르게 수행하기 위해 고안된 자료구조의 형태이다. 더 큰 범위는 '인덱스 트리'라고 불린다.
세그먼트 트리의 종류는 구간 합, 최대, 최소 구하기로 나눌 수 있고,
구현 단계는 하기와 같이 나눌 수 있다.
- 트리 초기화하기
- 질의값 구하기(구간 합 또는 최대, 최소)
- 데이터 업데이트하기
1. 트리 초기화 하기
리프 노드의 개수가 데이터의 개수(N) 이상이 되도록 1차원 트리 배열을 만든다.
트리 배열의 크기를 구하는 방법은 2^k >= N을 만족하는 k의 최솟값을 구한 후 2^k * 2를 트리 배열의 크기로 정의한다.
예를 들어 {5, 8, 4, 3, 7, 2, 1, 6}의 데이터가 있다면,
N = 8 이므로 2^3 >= 8이니 2^3 * 2 = 16으로 배열의 크기를 정의한다.
{5, 8, 4, 3, 7, 2, 1, 6} 예제 데이터를 리프 노드에 입력한다.
이 때 리프 노드의 시작 위치(인덱스)를 구해야 하는데, 구하는 방식은 2^k를 시작 인덱스로 취하면된다 따라서 start index = 8이 된다.

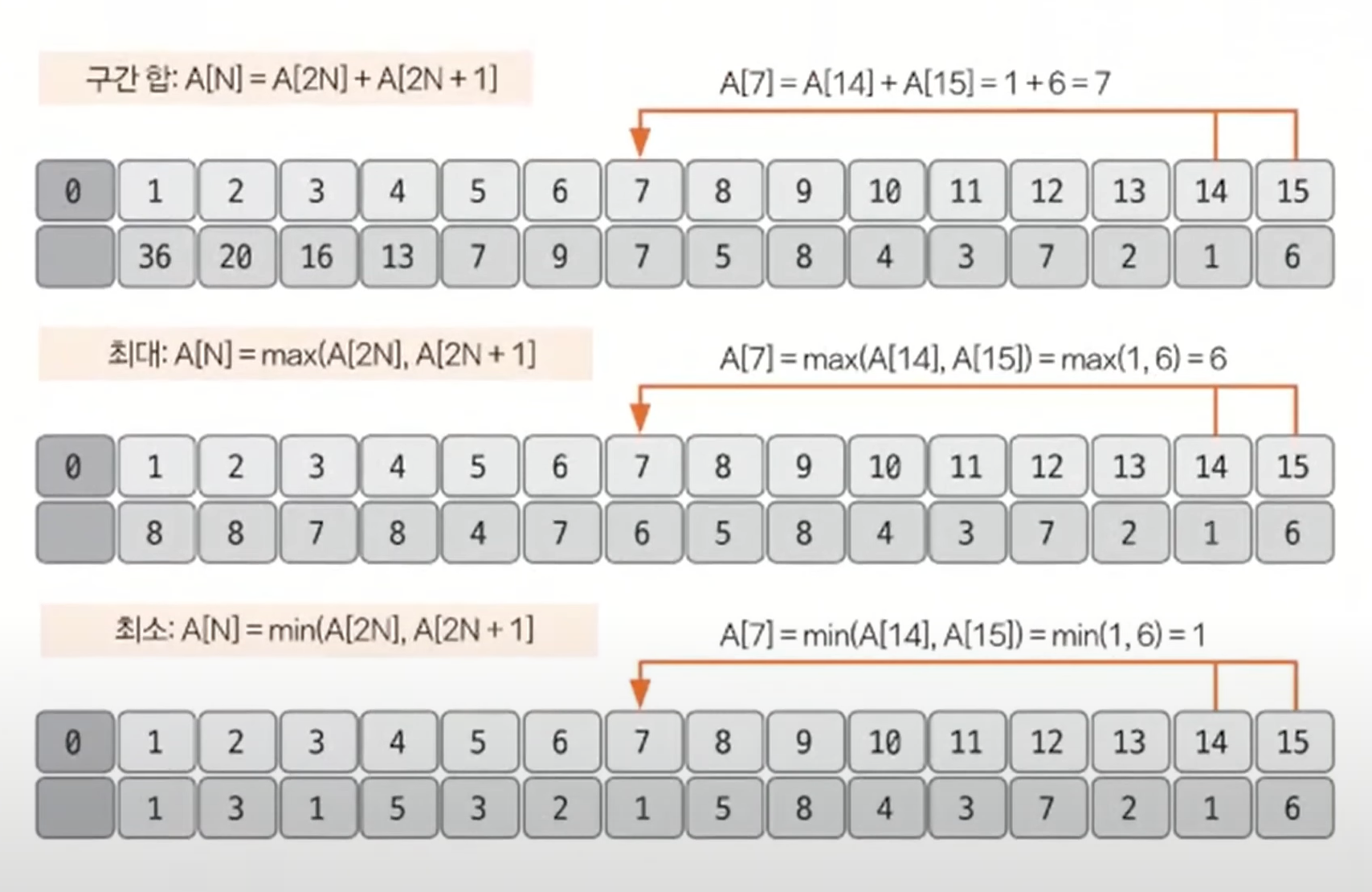
채워진 리프노드를 제외한 나머지 노드의 값(2^K - 1 부터 1번 인덱스 방향으로)을 케이스(구간 합, 최대, 최소값 등)에 따라 채운다.
채워야하는 인덱스가 N이라면 자신의 자식 노드를 이용해 값을 채울 수 있다.
자식 노드의 인덱스는 이진 트리 형식이기 때문에 2N, 2N + 1이 된다.
케이스 별 나머지 노드 채우는 방식(트리 배열)
케이스 별 나머지 노드 채우는 방식(트리)
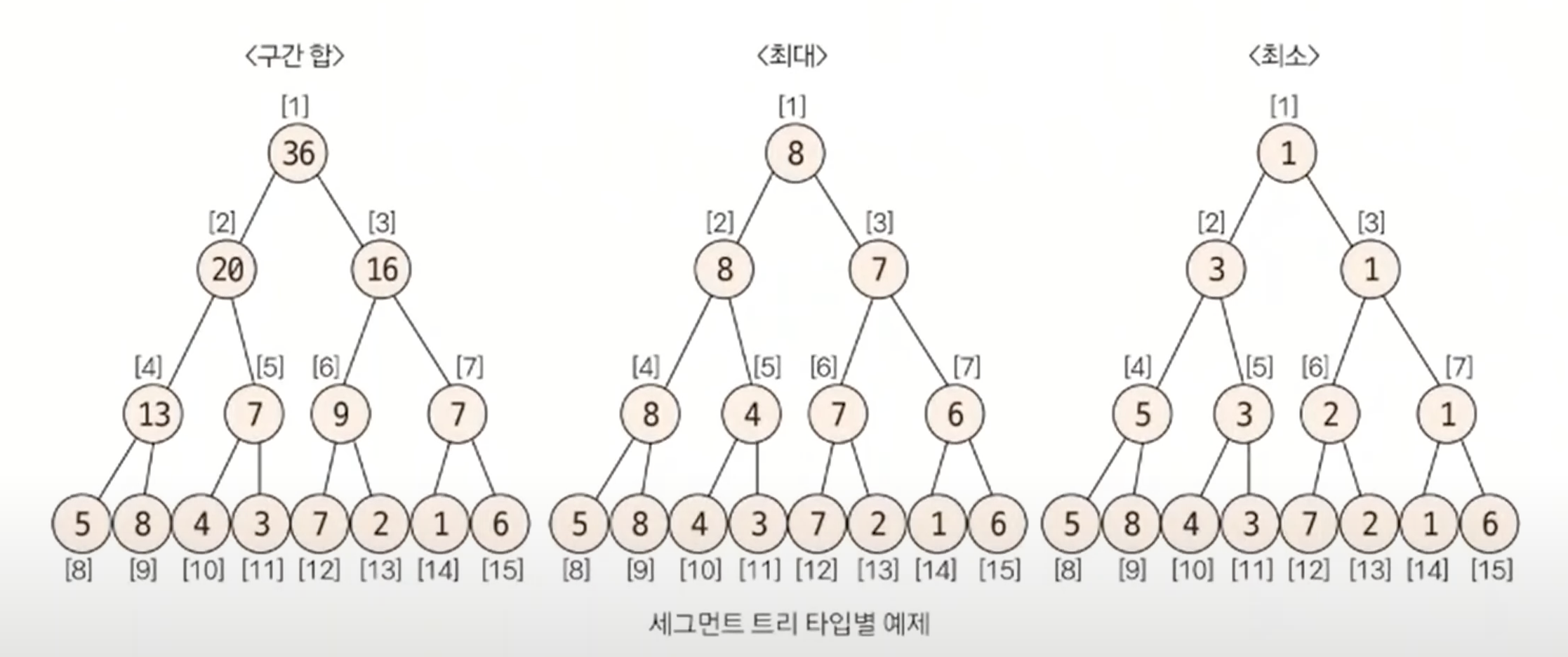
이 절차를 마치면 트리 초기화하기 절차가 완료된다.
2. 질의값 구하기
주어진 질의 인덱스를 세그먼트 트리의 리프 노드에 해당하는 인덱스로 변경한다.
질의 인덱스를 세그먼트 트리 인덱스로 변경하는 방법
세그먼트 트리 index = 주어진 질의 index + 2^k - 1
주어진 질의 인덱스의 범위가 1 ~ 3이라면,
세그먼트 트리 인덱스로 변경 시
1 + 2^3 - 1 = 8
3 + 2^3 - 1 = 10 이다.
질의값 구하는 과정
1. start_index % 2 == 1일 때 해당 노드를 선택
2. end_index % 2 == 0일 때 해당 노드를 선택
3. start_index depth(레벨) 변경: start_index = (start_index + 1) / 2 연산을 수행
4. end_index depth(레벨) 변경: end_index = (end_index - 1) / 2 연산을 수행
5. 1~4 단계를 반복하다가 start_index > end_index가 되면 종료한다.
해당 과정을 반복하여 질의값을 구할 수 있다.
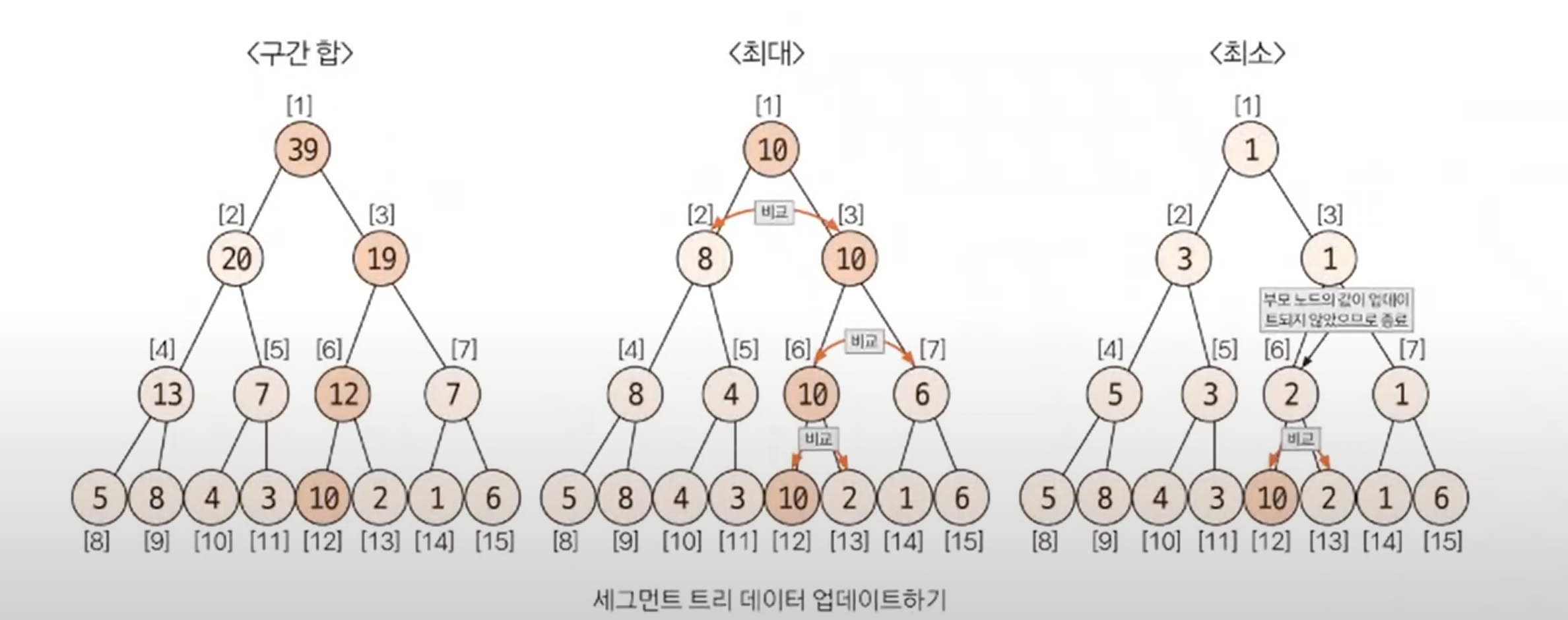
3. 데이터 업데이트 하기
업데이트 방식은 자신의 부모 노드로 이동하면서 업데이트한다는 것은 동일하지만, 어떤 값으로 업데이트할 것인지는 트리 타입별로 조금 달라진다.
*부모 노드로 이동하는 방식은 세그먼트 트리가 이진 트리이므로 index = index / 2로 변경하면 된다.
5번 데이터의 값을 7에서 10으로 업데이트 하는 예시
5번 데이터의 인덱스를 리프 노드 인덱스로 변경
5 + 2^3 - 1 = 12번 인덱스