Transformer
- 특정 문장(=단어 나열)이 등장할 확률을 계산해주는 모델(언어모델)
- Attention의 병렬적 사용을 통해 효율적인 학습이 가능
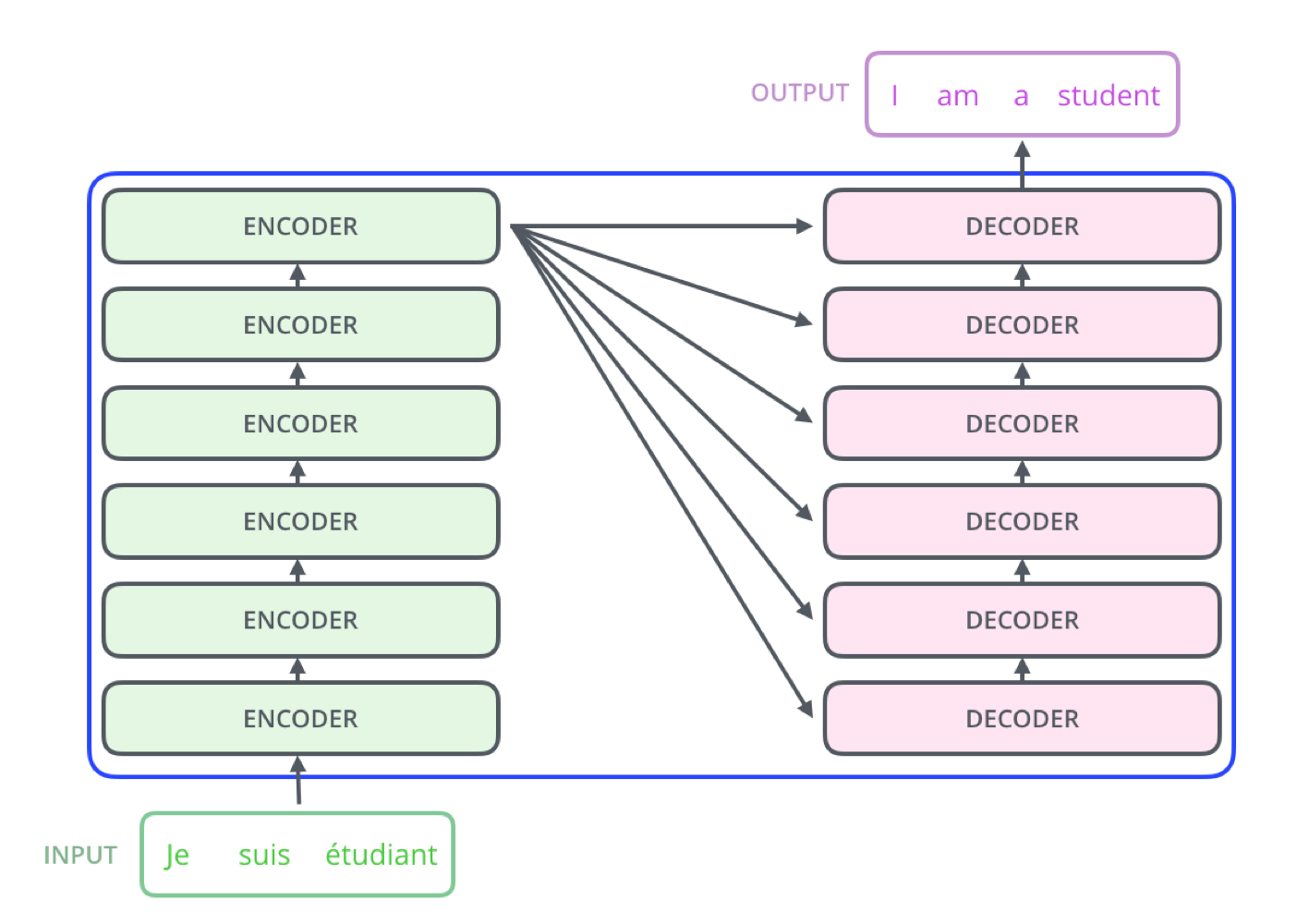
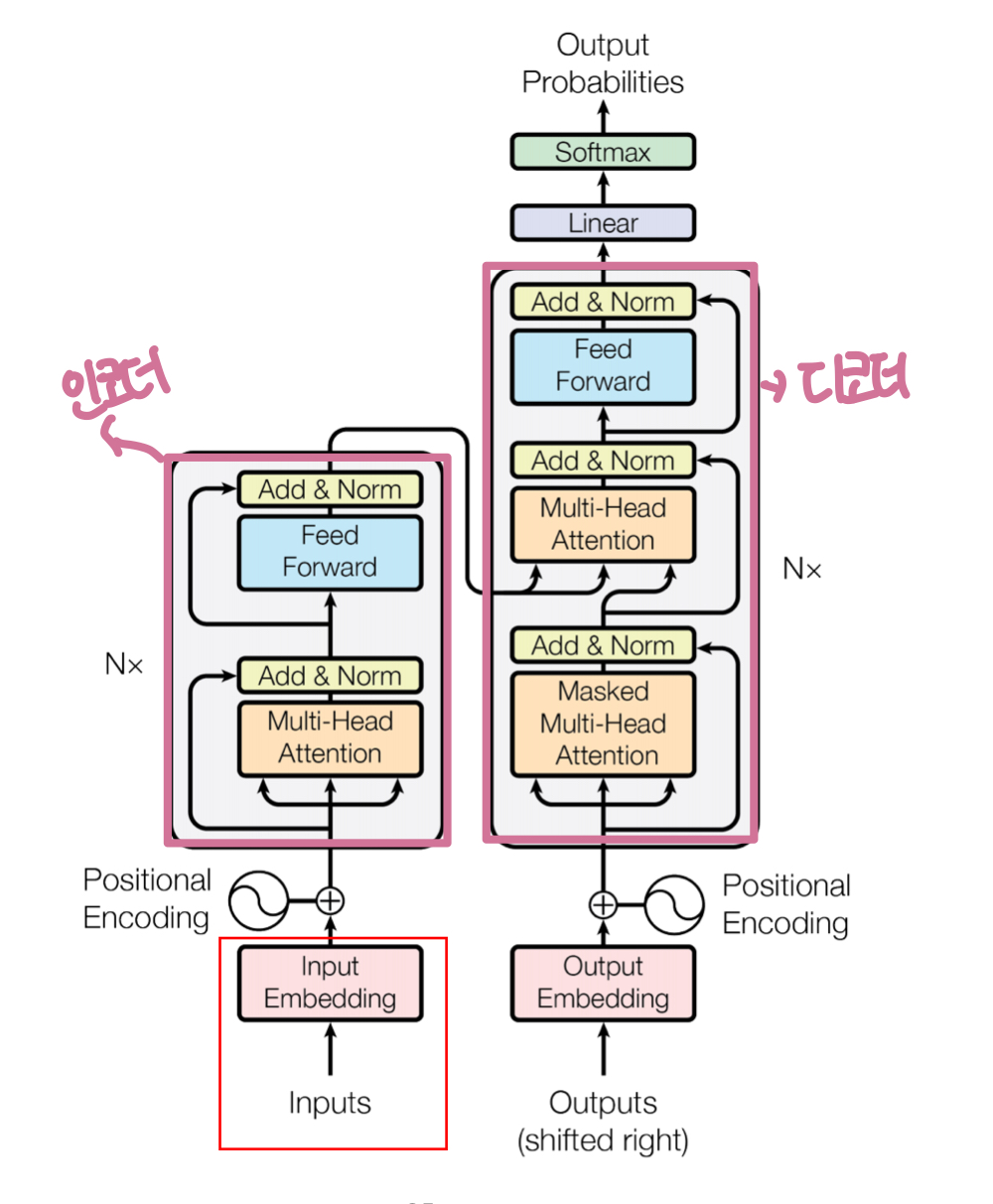
: 내부 인코더 파트와 디코더 파트가 존재하며 둘 사이를 이어주는 연결고리 존재
: Encoder의 output은 다음 Encoder의 Input으로 사용하고 마지막 Encoder가 Decoder에 정보를 전달하는 구조
Encoder 작동원리
input Embedding: 가장 아래에 위치한 Encoder에서만 입력을 1회 사용Positional Encoding: 단어를 한번에 받는 구조임으로 입력 시퀀스에서 단어 간 위치 관계를 표현Multi-Head Attention: 문서(문장) 안 단어들이 어떤 연관관계를 가진지 해석(Query토큰에 대해 다양한 관섬으로 표현할 수 있는 능력 제공)
- Self Attention
- step1:입력 벡터의 3가지 vector생성(query,key,value행렬 곱한값)
Query: 표현하고자 하는 대상이 되는 현재 단어에 대한 임베딩벡터key: query가 들어왔을 때 다른 단어 매칭을 위해 사용되는 레이블Value: key와 연결된 실제 단어
- step2: 지금 표현하고자 하는 단어(q)에 대해 어떤 단어를 고려하는지(k)를 알려주는 score산출(QxK)
- step3: 스코어를 로 나눔
- step4: step3에 softmax적용해 단어에 대한 집중도 산출(softmax(step3))
- step5: 집중도와 해당 단어 key와 곱함
- step6: step5를 모두 더한 값을 output
- step1:입력 벡터의 3가지 vector생성(query,key,value행렬 곱한값)
- Multi-Head Attention
- attention결과물들은 병합 후 가중치 행렬과 연산을 통해 입력과 같은 차원의 출력을 생성
Feed Forward:
Decoder 작동원리
Masked Multi-head Attention: 셀프 어텐션은 query토큰보다 뒤에 위치한 토근들에 대한 정보는 Masking 처리Final Linear and Softmax Layer:
- Linear layer: 단순 FFNN형태로 마지막 디코더 output을 이용해 모든 단어의 출력 확률 산출을 위해 차원을 늘리는 역할
- Softmax layer: 개별 단어들의 출력확률 반환
Time-Series Transformer(TST)
TST는 크게 Pre-training + Fine-tuning 과정 사용
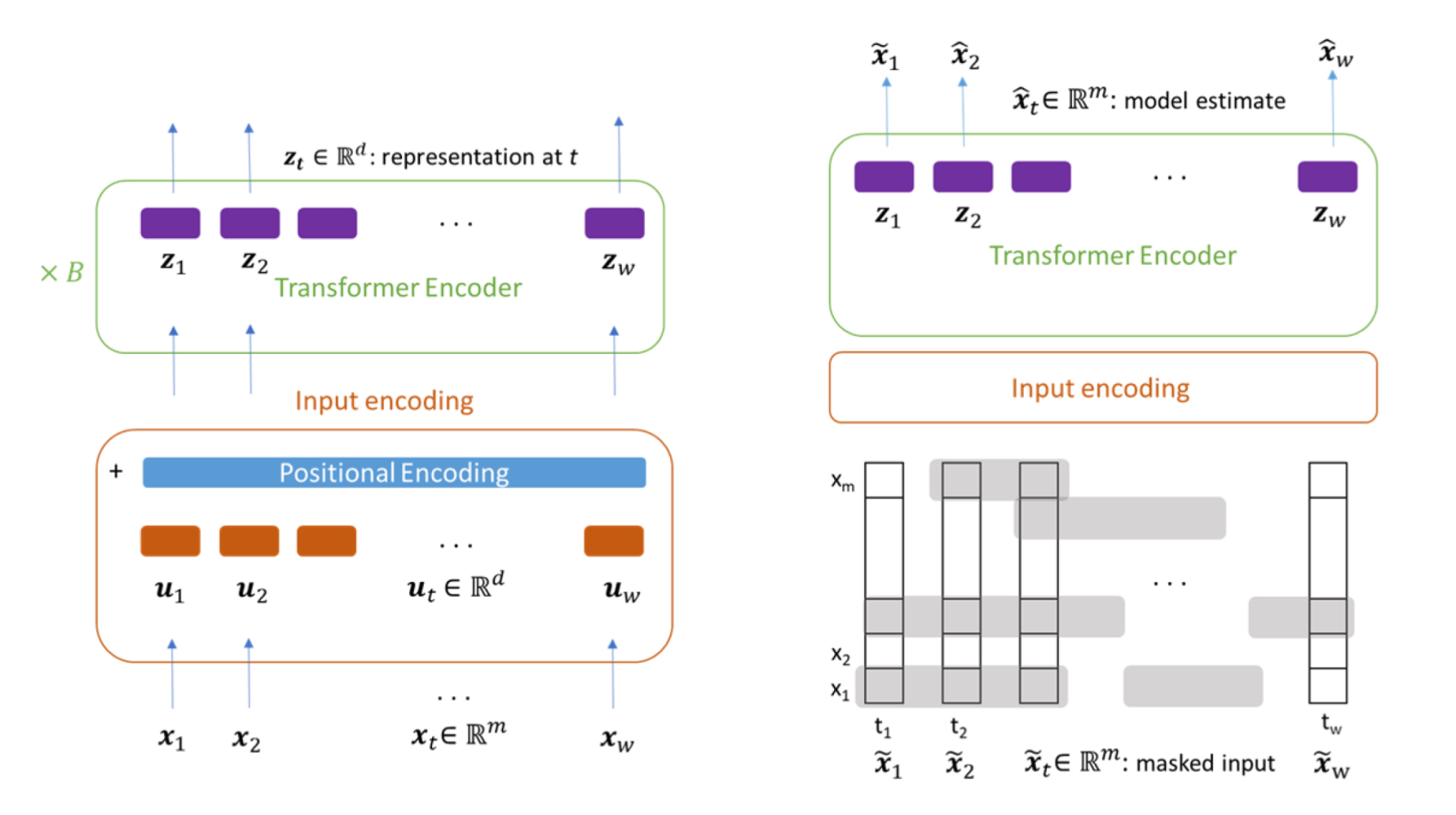
- Transformer의 Encoder구조만 사용
- Pre-training과업을 위해 연속길이의 input masking 사용
- Layer Normalization -> Batch Normalization사용
- 입력데이터 변환
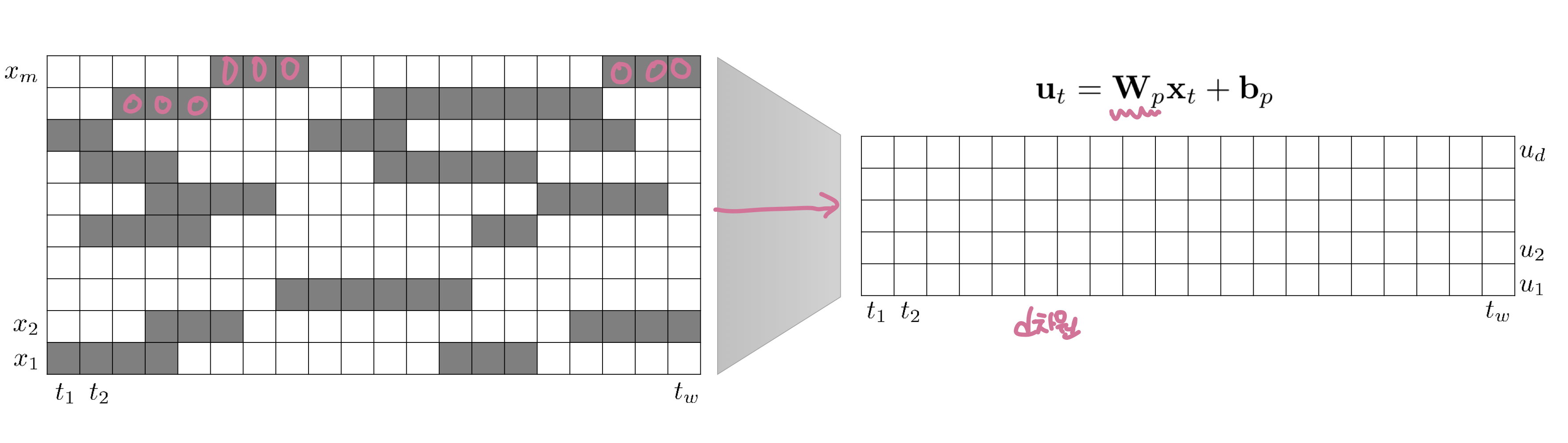
- Pre-training과정은 이 중 일부를 Masking처리 후 Transformer의 input이 되는 d차원으로 변환
- Fine-tuning과정은 masking처리 x
- 포지션 인코딩
- NLP의 transformer
- 6개의 Encoder
- Batch Normalization
- TS의 transformer
- 3개의 Encoder
- Layer Normalization
- NLP의 transformer
