1-2 Transfer Learning
1. Transfer Learning
- 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법
- 기존보다 모델 학습 속도가 빨라지고 새로운 태스크를 더 잘 수행
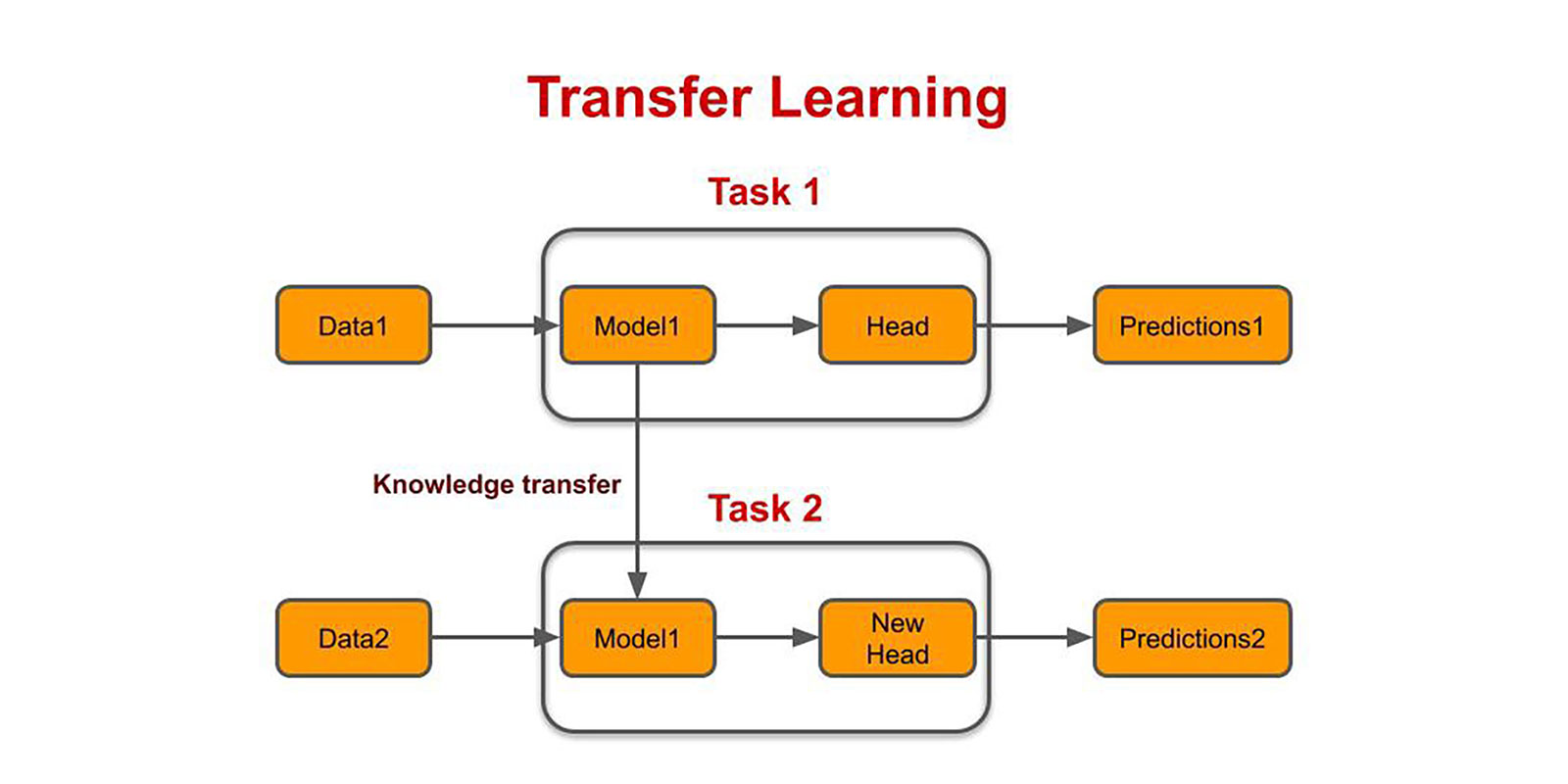
업스트림 태스크
- 위 그림에서 Task 1에 해당 (모델을 학습시키는 용도의 태스크)
- 다음 단어 맞히기: 업스트림 태스크 중 하나로, 이 태스크로 업스트림 태스크를 수행한 모델을 언어 모델이라고 함(GPT)
- 빈칸 채우기: 업스트림 태스크 중 하나로, 이 태스크로 업스트림 태스크를 수행한 모델을 마스크 언어 모델이라고 함(BERT)
- 업스트림 태스크를 학습하는 과정을 프리트레인이라고 부름
- 업스트림 태스크로 프리트레인을 할 경우, 자연어의 풍부한 문맥을 모델에 내재화할 수 있어 모델 성능이 좋아짐.
- 감성 분석은 사람이 일일이 레이블을 만들어줘야 하는 반면(지도 학습), 빈칸 채우기나 다음단어 맞추기같은 업스트림 태스크는 레이블 없이도 데이터 내에 정답이 있기 때문에 수작업 없이 다량의 학습 데이터를 만들어낼 수 있음(자기 지도 학습)
- 다운스트림 태스크
- 우리가 풀어야 할 자연어 처리의 구체적인 과제
- 프리트레인을 마친 모델을 구조 변경 없이 그대로 사용하거나 태스크 모듈을 덧붙인 형태로 수행
- 태스크 모듈은 수행 과제에 따라 달라짐
- 대표적인 다운스트림 태스크에는 문서 분류, 자연어 추론, 개체명 인식, 질이응답, 문장 생성 등이 있음
- 다운스트림를 학습시키는 방식에는 여러 종류가 있는데, 파인튜닝을 많이 씀
- 파인 튜닝
- 프리트레인을 마친 모델을 다운스트림 태스크에 맞게 업데이트하는 기법 중 하나
- 다운스트림 태스크 전체를 사용해, 모델 전체를 업데이트
- 프롬프트 튜닝, 인컨텍스트 러닝 등 다른 다운스트림 태스크 학습 기법에 비해 비용이 많이 듦
- 문서 분류를 수행할 경우 프리트레인을 마친 BERT 모델 전체를 문서 분류 데이터로 업데이트, 개체명 인식을 수행할 경우 BERT 모델 전체를 해당 데이터로 업데이트
1-3 학습 파이프라인 소개
- 각종 설정값 정하기
- 어떤 프리트레인 모델 쓸건지, 어떤 데이터 쓸 건지, 학습 결과 어디에 저장할 건지, 하이퍼파라미터(Learning rate, batch size 등)
# 설정값 선언
from ratsnlp.nlpbook.classification import ClassificationTrainArguments
args = ClassificationTrainArguments(
pretrained_model_name = 'beomi/kcbert-base',
downstream_corpus_name = 'nsmc',
downstream_corpus_root_dir = '/content/Korpora',
downstream_model_dir = '/gdrive/Mydrive/nlpbook/checkpoint-doccls',
learning_rate = 5e-5,
batch_size = 32,
max_seq_length = 128,
epochs = 3,
seed = 7
)- 데이터 내려받기
- 데이터를 내려받아서 설정값에서 정의한 디렉토리에 저장함
# 데이터 다운로드
from Korpora import Korpora
Korpora.fetch(
corpus_name = args.downstream_corpus_name,
root_dir = args.downstream_corpus_root_dir,
force_download = True
)- 프리트레인을 마친 모델 준비하기
- 모델을 내려받기
# kcbert-base 모델 준비
from transformers import BertConfig, BertForSequenceClassification
pretrained_model_config = BertConfig.from_pretrained(
args.pretrained_model_name,
num_labels=2
)
model = BertForSequenceClassification.from_pretrained(
args.pretrained_model_name,
config = pretrained_model_config
)- 토크나이저 준비하기
# kcbert-base 토크나이저 준비
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
args.pretrained_model_name,
do_lower_case = False
)- 데이터로더 준비하기
from torch.utils.data import DataLoader, RandomSampler- 태스크 정의하기
- 모델 학습하기

😎