1. 문제 정의
구매 의사결정에 중요한 역할을 하는 리뷰에 신뢰성 문제가 있는데 원인은 다음 네가지로 정의.
- 허위리뷰 : 마케팅을 위해 인위적으로 작성되거나 광고의 목적으로 작성된 리뷰
- 악성리뷰 : 악의적인 의도를 가지고 작성된 리뷰
- 관련 없는 내용이 포함된 리뷰
- 긍정적인 리뷰 내에 부정적 평가를 섞는 경우
본 프로젝트를 통해 허위리뷰와 관련 없는 리뷰 제거, 악성리뷰을 판정하여 분리 및 제거, 긍부정이 혼재된 경우에는 맛집을 평가하는 요소를 판별하여 어떤 유형인지 맛집을 분류하고 그에 맞게 리뷰를 파악하는 감성분석 및 키워드 추출을 목표로 하여 소비자가 신뢰할 수 있는 리뷰를 만드는 것이 본 프로젝트의 목표
2. 데이터 수집
네이버 플레이스 리뷰, 블로그 리뷰 크롤링을 통해 원본 데이터 수집
1. 특정 지역 + 맛집 검색 결과로 나오는 식당의 이름과 URL을 우선 수집
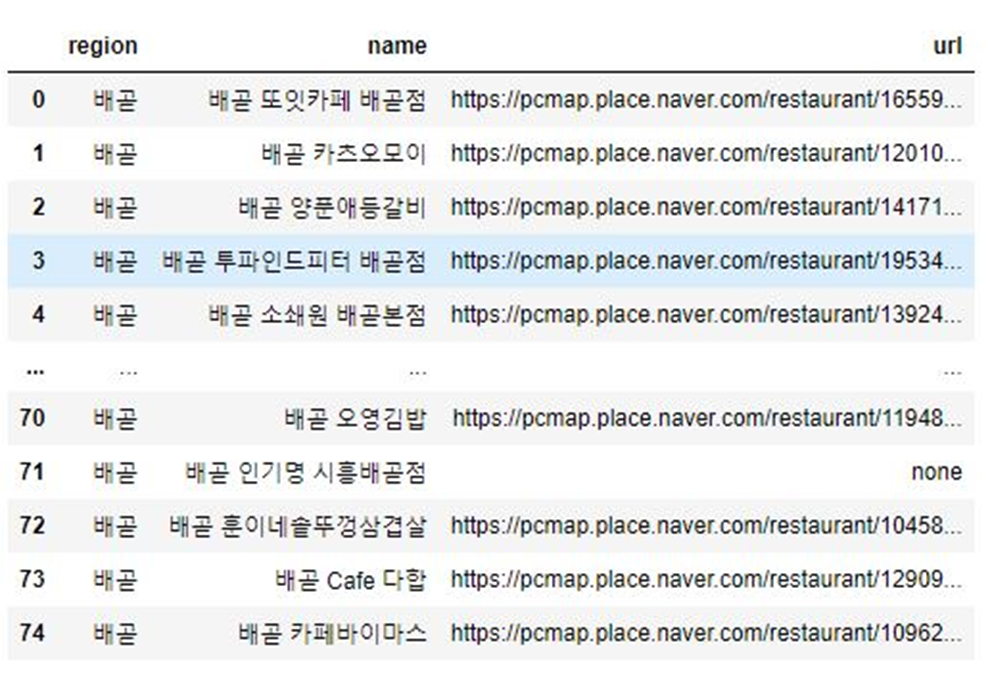
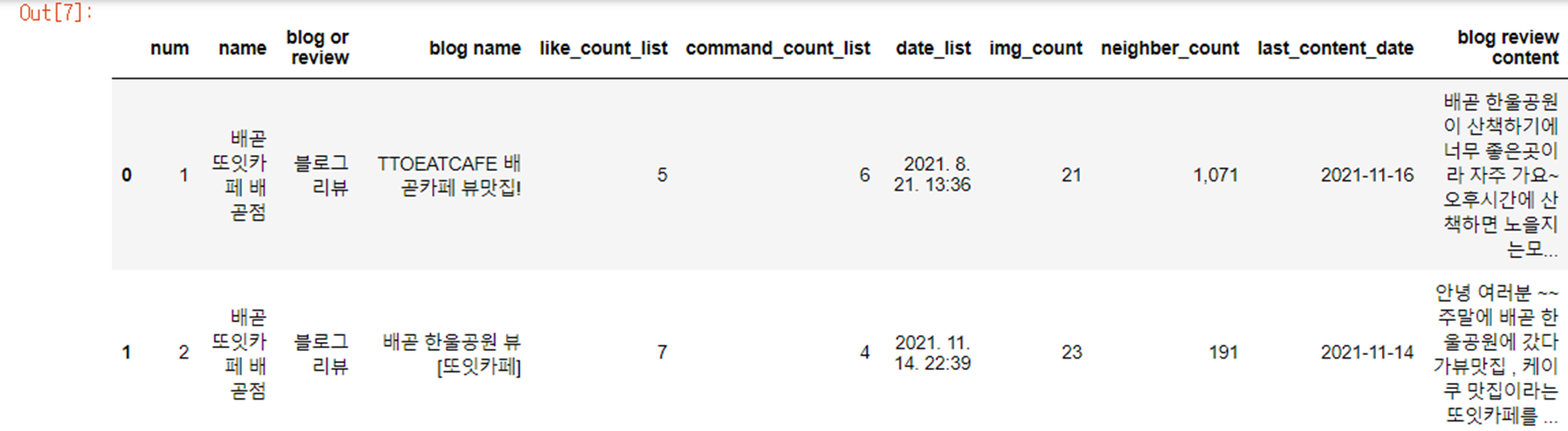
2. 해당 URL을 통해 블로그 리뷰와 플레이스 방문자 리뷰 따로 수집
- 블로그 리뷰
- 플레이스 방문자 리뷰
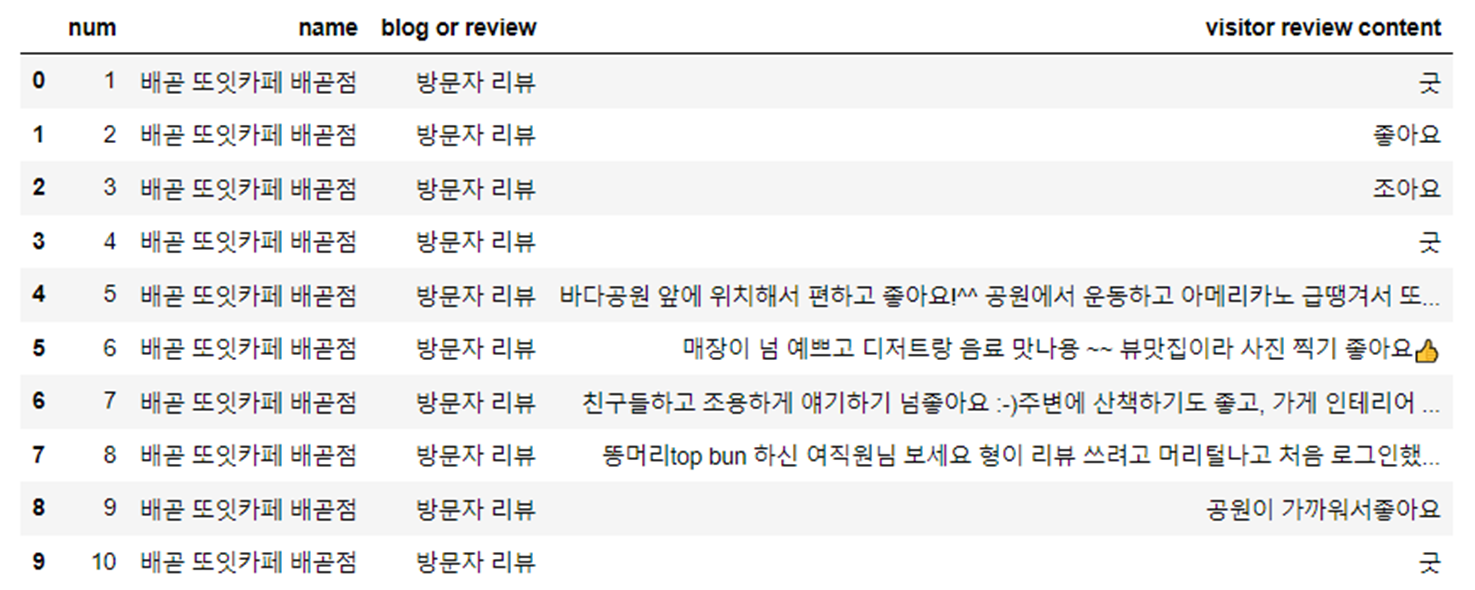
블로그 리뷰 3382개, 방문자 리뷰 14011개 수집
3. 전처리
1. 정규화
- 문장 단위로 분절
- 영어, 자음, 모음, 특수문자 제거
- 띄어쓰기 전처리
- 문장 끝에 '.' 붙여서 문장 단위로 나타냄
2. 불용어 사전
- 허위리뷰를 판별하는 키워드가 들어간 불용어사전 제작
- 리뷰 중 허위 리뷰 판별 키워드가 들어간 리뷰 필터링
3. 라벨링
- 허위리뷰 키워드 사전에 들어가 있는 단어가 존재하면 허위리뷰로 라벨링(0-일반, 1-허위)
- 악성리뷰 라벨링(0-일반,1-비판,2-감정적이거나 악의적)
4. 리뷰필터링
1. 허위리뷰
대부분의 허위리뷰는 블로그 리뷰에서 발생하므로 블로그 리뷰를 대상으로 한 허위리뷰 필터링 실시
Y값만 있는 상황이기 때문에 크롤링시 아래 변수들을 추가로 크롤링
포스트 작성 날짜, 포스트 본문에 사용된 이미지 개수, 포스트 제목 길이, 포스트 공감 개수, 포스트 댓글 개수, 블로그 이웃 수, 블로그 최신 게시물 날짜 등의 정보

허위리뷰에 해당하는 데이터가 너무 적었기 때문에 어떤 모델을 써도 제대로 된 성능이 나오지 않음
기존 Spam 데이터를 이용해 Spam 데이터 생성 및 삽입
이후 Random Forest, Decision Tree, Logisitic Regression, XGBOOST 등의 모델 평가

1. 성능 평가 지표
- Accuracy = TP+TN/TP+TN+FP+FN
- Recall = TP/(TP+FN)
- Precision = TP/(TP+FP)
- F1 Score = 2*{(Precision X Recall)/(Presicion+Recall)}
- ROC 분석을 통한 AUC 수치

-
분석결과

-
성능이 가장 좋은 XGBOOST의 변수 중요도 결과

-
결론
결과적으로 XGBOOST를 사용해 2861개의 데이터 중 67개의 허위리뷰 제거했다. 다만, 적은 양의 데이터, 불균형적인 데이터로 인해 모델의 성능보다 실질적인 성능이 미비할 가능성이 있다. 향후 추가적인 크롤링을 통해서 데이터를 충분히 수집한 뒤에 데이터 부족 문제와 데이터 불균형 문제를 해결한다면 더 좋은 모델을 만들 수 있을 것이다.
2. 관련 없는 내용
블로그 리뷰에는 식당에 대한 리뷰와 관련이 없는 일상적인 내용이 많기 때문에 식당과 관련이 없는 내용을 제거하고 리뷰 데이터만 뽑을 필요가 있음
블로그 리뷰 중 식당에 대한 내용만 있는 리뷰(기준문장)와 다른 리뷰들의 유사도를 계산해서 유사도가 일정 수치보다 낮은 단어를 제거하면 식당 리뷰가 아닌 내용들을 제거할 수 있지 않을까?
- 세가지 모델 활용해 유사도 계산
- FastText 모델
- Word2Vec pretrained 모델
- FastText pretrained 모델
-
유사도 특정치 결정
유사도가 특정치보다 낮은 단어를 제거해야 하기 때문에 기준 문장과 다른 리뷰들 사이의 유사도를 구해서 평균을 구함

① 리뷰에 있는 토큰과 기준 문장에 있는 모든 토큰들 사이의 유사도 계산 후 평균 계산
② ①번의 값이 위의 표에 있는 유사도 평균 값보다 낮다면 그 단어 제거 -
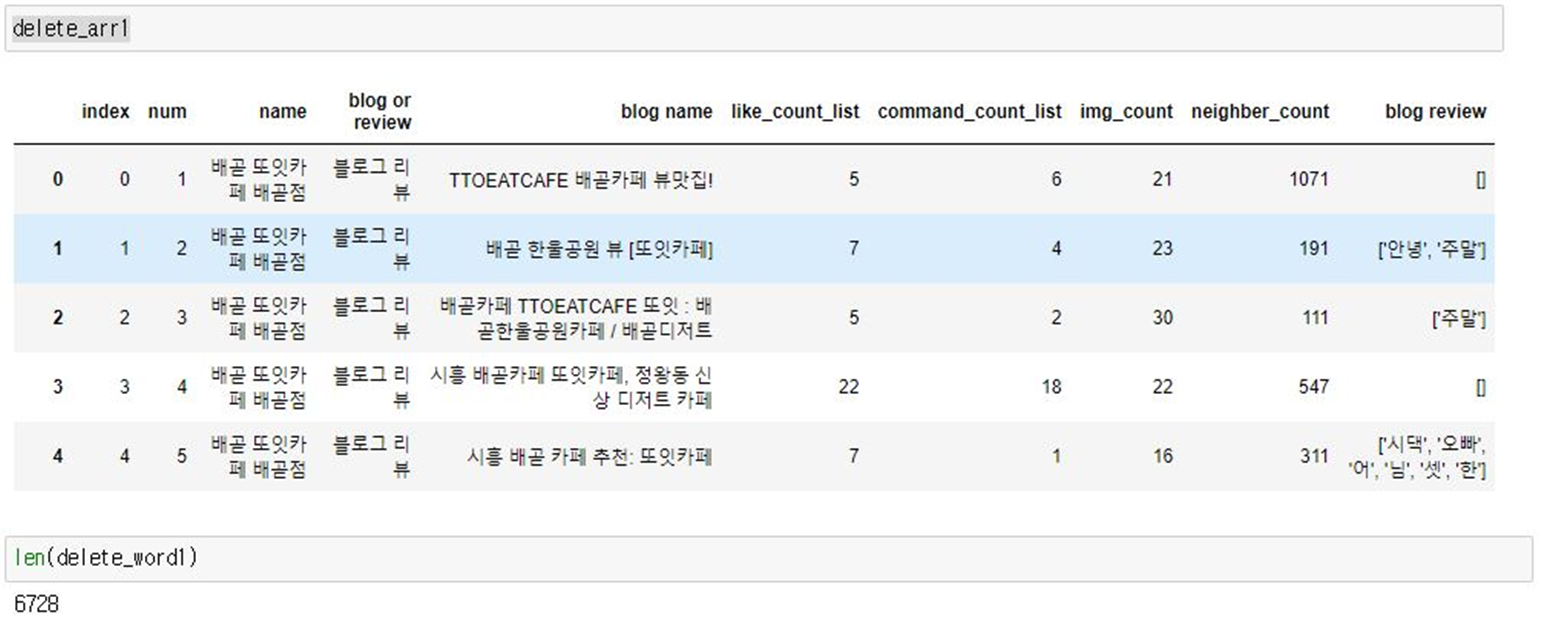
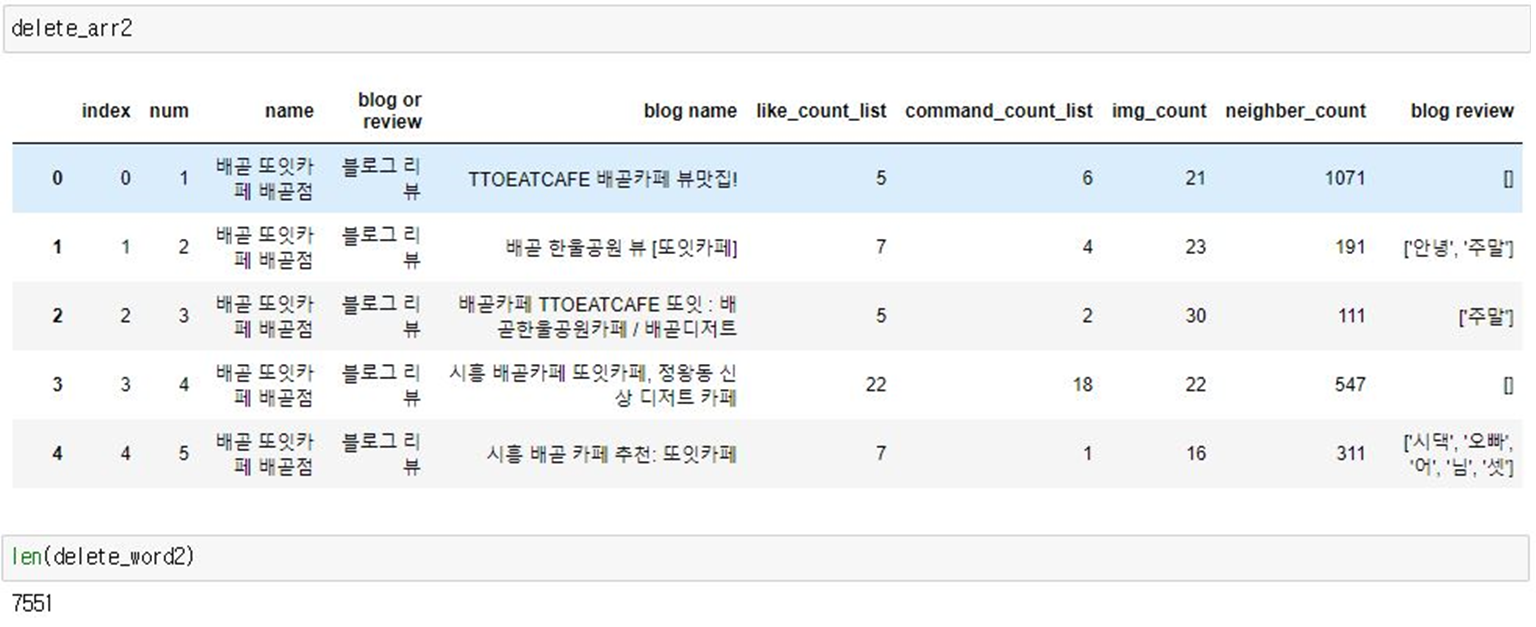
리뷰 필터링
- FastText 모델
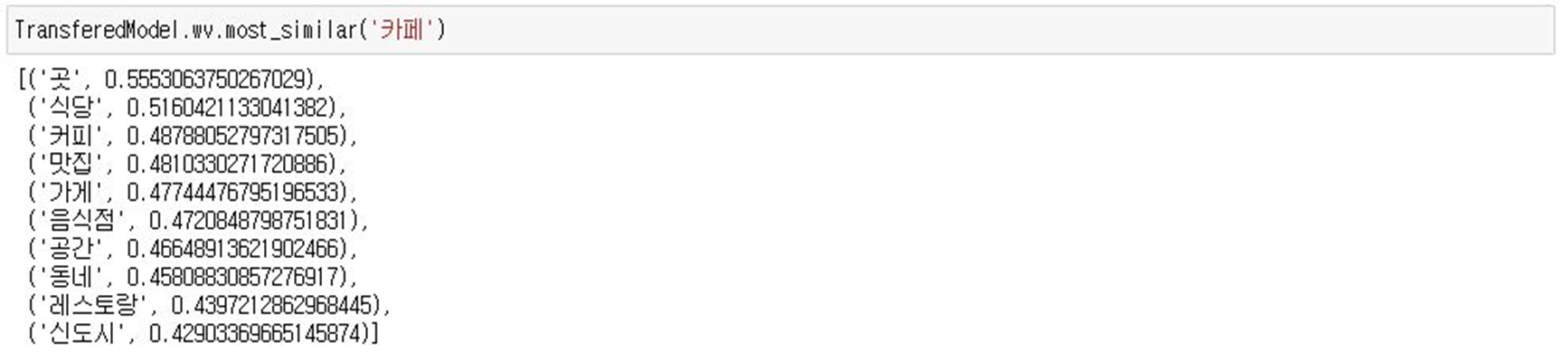
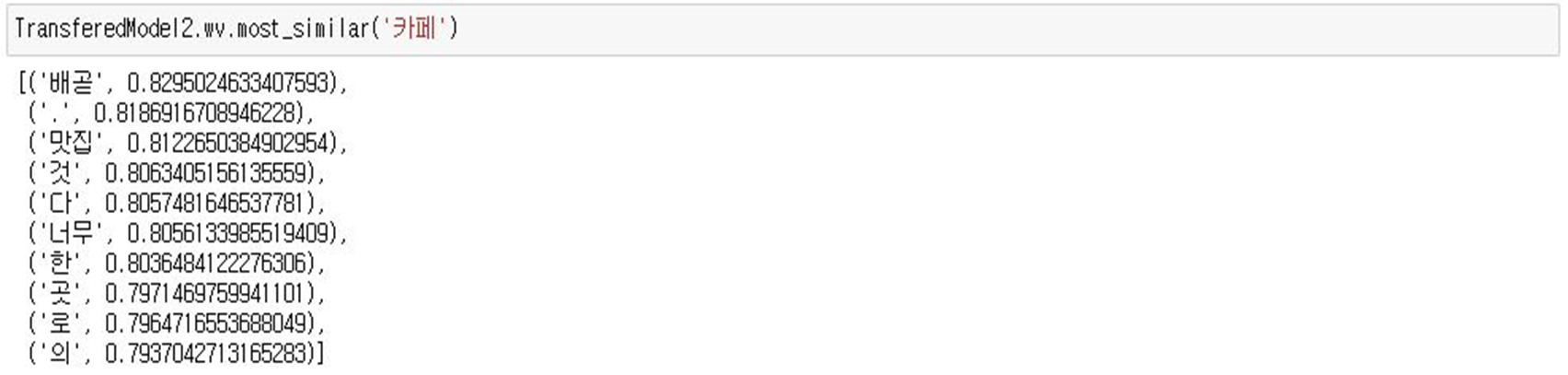
- Word2Vec pretrained 모델을 활용한 Transfered Model1
- FastText pretrained 모델을 활용한 Transfered Model2
3가지 모델 모두를 사용해 3개의 모델에서 삭제된 단어의 중복을 제거하고 모아서 원래 리뷰에서 제거하는 방식으로 진행
- 3가지 모델 통합 결과
- 중복을 제거한 후 삭제할 단어들의 리스트

- 전체 리뷰에서 삭제된 단어들

- 한계점 및 향후 방향성
리뷰를 문장 단위가 아니라 형태소 단위로만 처리하였고 이로 인해, 문맥에 대한 정보를 모두 반영하지 못해서 식당 리뷰와 관련이 있는 내용도 삭제되는 경우가 발생하였다. 블로그 리뷰 글의 특징을 파악하여 문맥에 대한 정보를 다 반영할 수 있도록 시도해 보완할 필요가 있다.
3. 악성리뷰
방문자 리뷰에는 식당에 대한 리뷰나 식당의 개선을 기대하는 비판 리뷰 외에도 감정적이거나 악의적인 내용을 담은 악성리뷰가 존재한다. 이를 라벨링 처리를 한 뒤 머신러닝을 통해 악성리뷰를 분류하고 예측해 활용
1. 변수 설명
visitor review - X
label - Y

데이터가 너무 적고 불균형이 심해 어떤 모델을 써도 성능이 낮은 문제가 허위리뷰와 동일하게 발생하였다. 그래서 악성 리뷰 데이터만 추가로 수집하였고, 데이터의 복제도 수행하였다.
2. 모델링
Decision Tree, XGBOOST, Light GBM 모델 사용
성능 평가 지표는 허위리뷰와 동일하고, Light GBM이 가장 성능이 좋았다.


3. 결론
13892개의 데이터 중 132개의 악성리뷰 제거하였다. 다만 허위리뷰와 마찬가지로 적고 불균형적인 데이터가 발목을 잡았다. 추가적인 크롤링이나 데이터 수집을 통해 문제를 해결한다면 더 좋은 모델을 만들 수 있을 것이다.
5. 감성분석
- 감성사전 제작
서비스, 맛, 가격, 분위기, 재방문의사 5가지 부분의 긍부정 감성사전을 아래 3가지 작업을 통해 제작
- 맛집 리뷰의 감성 표현에 대한 연구
- KNU 감성 사전 목록 참고
- 감성 용어 분류 작업 - 형태소 분석 및 키워드 추출
okt.pos를 통한 형태소 분석을 통해 토큰화하여 특성 키워드 추출 및 감성 분석을 용이하게 함
또한 단어 단위로 감성분석을 하기보다는 구 단위로 감성분석을 하는 것이 유의미하기 때문에 각 특성의 키워드와 주변 요소도 함께 추출

- 감성 추출
키워드와 키워드가 포함된 구에서 해당 특성의 감성 사전에 포함된 긍부정어가 있는지 확인해 최종적인 긍부정을 파악

- 결론

각 특성별 긍정리뷰/전체리뷰로 특성을 점수화 하였고, krwordbank의 summarize_with_sentence 수행 결과로 나온 키워드 추출 결과를 함께 제시해 키워드 정보와 리뷰 점수를 통해 식당을 한 눈에 파악할 수 있도록 하였다
