인덱스
수많은 데이터 중에서 특정 조건을 만족하는 데이터를 조회하는데 일일이 검사를 하면 조회 시간이 엄청 증가한다.
데이터를 전부다 조건을 검사하게 되면 검색 성능이 매우 떨어지는 문제가 발생한다.
이를 해결하기 위한 기술이 인덱스다.
인덱스는 일반적으로 책 뒤에 색인 처럼 어느 페이지에 어떤 단어가 있는지 대략적으로 파악할 수 있는 것을 제공하는 것고 비슷하게 해결한다.
인덱스 구조
B-Tree 인덱스
대부분 RDBMS는 B-Tree 인덱스를 사용한다.
SHOW INDEX FROM product_index;
B-Tree 구조는 다음과 같다.
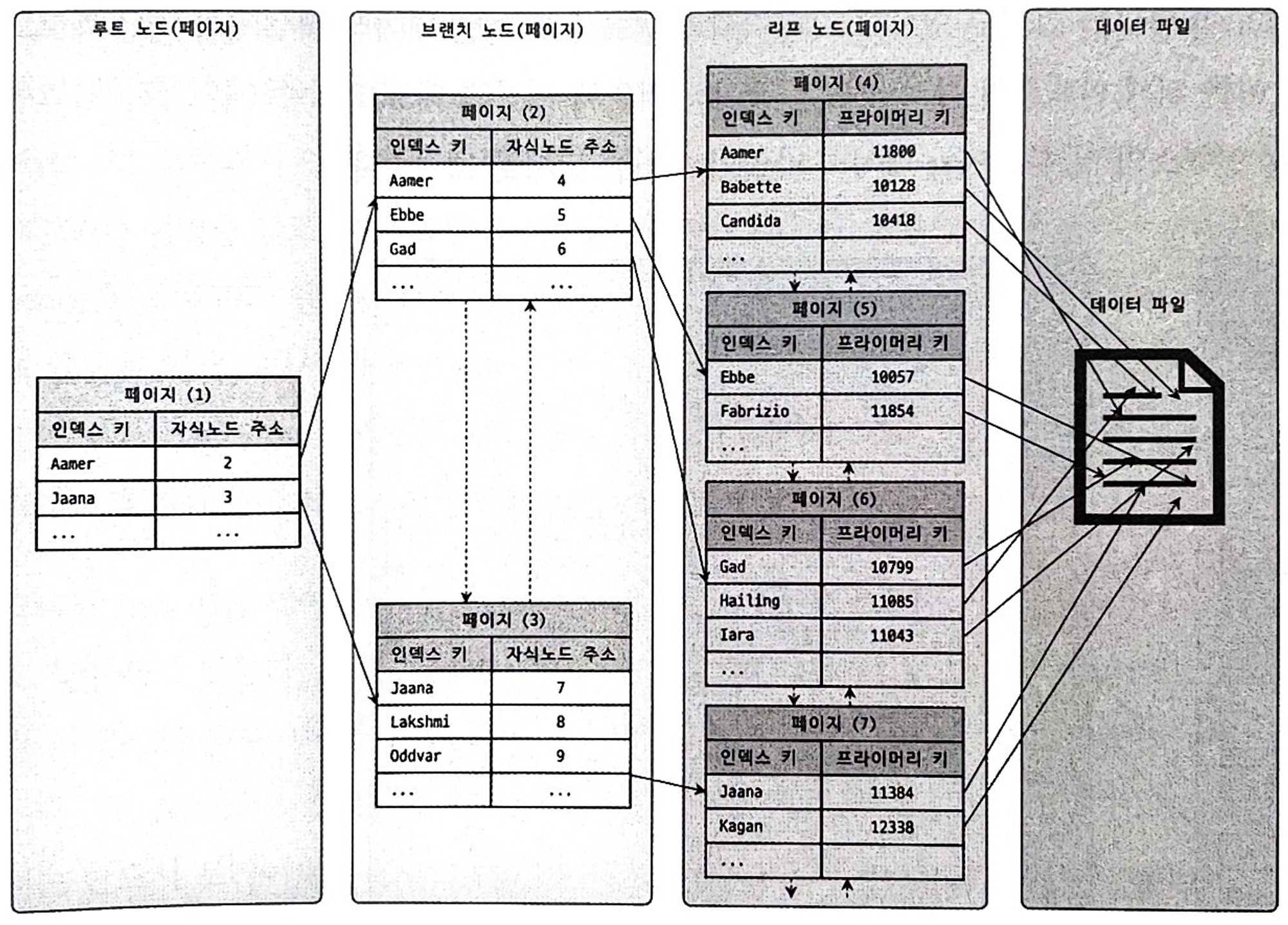
인덱스 컬럼을 관리하기 위해서 트리 자료구조를 사용한다.
최상위에 루트 노드가 있고 리프 노드에 실제 레코드의 주소를 저장한다.
루트 노드와 리프 노드 사이에는 브랜치 노드가 있다.
루트 노드와 브랜치 노드에는 리프 노드에 대한 매핑 정보를 갖고 있다.
레코드를 찾아가는 방식은 다음과 같다.
- 위 그림에서
Gad인덱스 키가 있는지 찾아본다.- 루트 노드에서 Gad 인덱스 키가 있는지 찾아본다.
Aamer는 자식 노드가 2번,Janna는 자식 노드가 3번임을 확인한다.- Gad는 Aamer, Janna 사이에 있음을 알 수 있다.
- Aamer가 가리키는 2번 자식 노드로 가서 Gad를 탐색한다.
- 2번 노드에서 Gad를 찾았다. 자식노드 6번을 가리키므로 6번 노드로 이동한다.
- 6번 노드에는 다른 자식의 노드가 아닌 실제
프라이머리 키값을 알려준다.- 이를 이용해
데이터 파일에서 해당 프라이머리 키를 갖는 레코드를 찾으면Gad의 정보를 알 수 있다.
- 이를 이용해
InnoDB 인덱스 구조
MySQL에서 가장 많이 쓰는 InnoDB 스토리지 엔진에서 기본으로 하는 인덱스 구조는 아래와 같다.
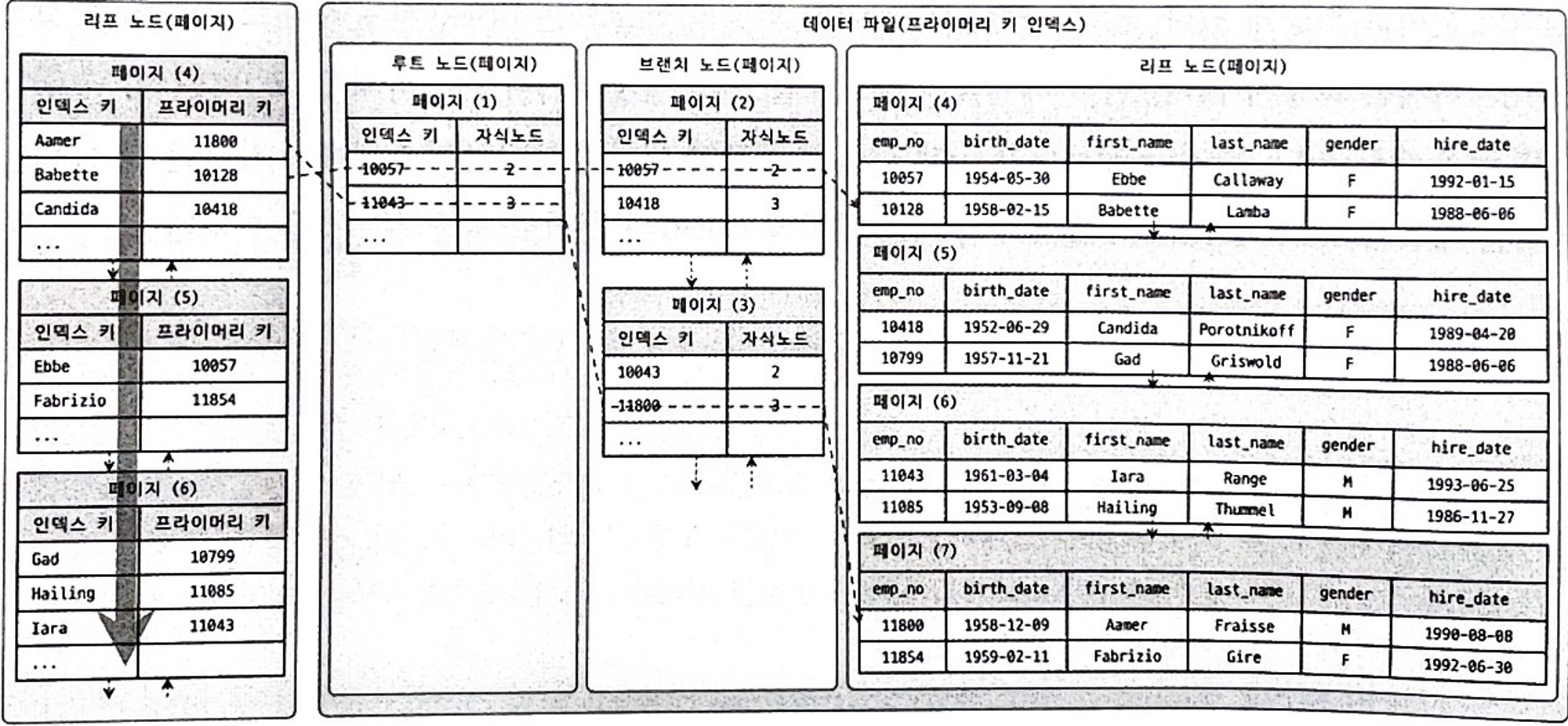
B-Tree와 유사하고 데이터 파일을 관리하는게 다르다.
B-Tree 인덱스에서는 데이터 파일이 순차적으로 있지 않고 여러 위치에 뒤죽박죽 순서로 저장돼있다.
이는 실제 레코드 수가 몇 개 안되더라도 그것들이 다 다른 위치(페이지)에 있다면 메모리로 읽어와야 할 페이지(단위) 수는 많아져서 I/O에 효율이 떨어질 수 있다.
InnoDB의 인덱스는 데이터 파일에 저장 방식 자체를 프라이머리 키 인덱스로 정렬하여 관리
하므로 I/O로 효율이 떨어지는 문제를 해결했다.
MySQL의 인덱스 종류
- 프라이머리 키 인덱스
- 프라이커리 키를 기준으로 만들어지는 인덱스
- 세컨더리 인덱스
- 프라이커리 키를 제외한 모든 인덱스
프라이머리 키 인덱스는 반드시 존재한다.
데이터 레코드 저장 자체를 프라이머리 키 인덱스로 저장한다.
세컨더리 키 인덱스로 탐색했을 때 마지막 리프 노드에는 프라이머리 키 값을 가지고 있다.
이 프라이머리 키 값으로 프라이머리 키 인덱스를 다시 탐색해서 실제 레코드에 접근한다.
인덱스 키 검색
B-Tree 인덱스를 사용하는 경우 일치 검색(=) 또는 앞부분 일치(Like%)를 이용한 검색, 부등호 비교<>도 인덱스를 사용할 수 있다.
하지만 뒷부분 일치(%Like)를 이용한 검색은 불가능하다.
인덱스 키가 문자열인 경우 맨 앞글자를 기준으로 정렬 돼 있다.
뒷부분이 일치하는지를 검색하려고 하면 정렬된 인덱스는 효과가 없기 때문에 사용하지 않는다.
부등호 비교나 일치 검색은 정렬돼있기 때문에 어디까지 읽어야 하는지 혹은 정확하게 일치하는 게 걸리면 즉시 응답해주면 되기 때문에 인덱스를 이용할 수 있다.
검색 테스트
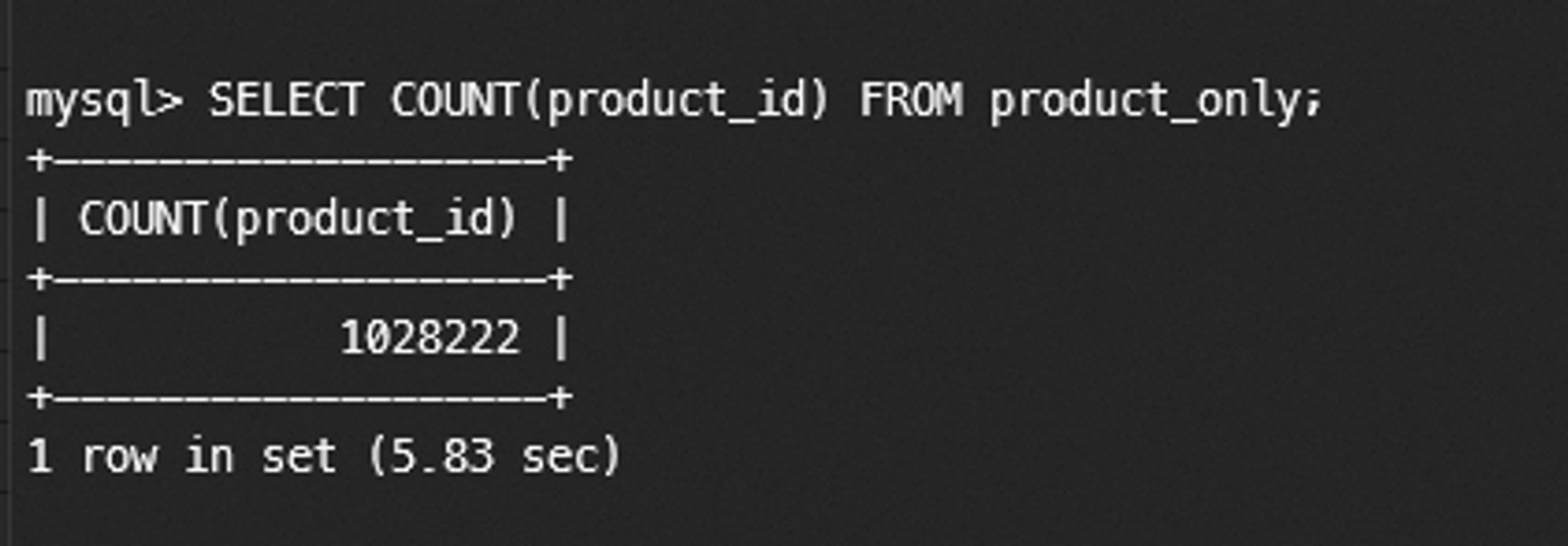
테스트 데이터 개수 1,028,222개
검색 코드
public List<ProductSimpleResp> searchPageFilter(String keyword, Pageable pageable) {
List<ProductSimpleResp> results = queryFactory
.select(Projections.constructor(ProductSimpleResp.class,
product.productId,
product.productName,
product.price,
product.img))
.from(product)
.where(keywordLike(keyword))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(productSort(pageable))
.fetch();
return results;
}
private BooleanExpression keywordLike(String keyword) {
return isEmpty(keyword) ? null : product.productName.like(keyword + "%");
}동% 키워드로 검색
http://localhost:8080/api/product/list/test?search=동&orderby=&page=0&size=20&sort=price,ascNo Index 검색
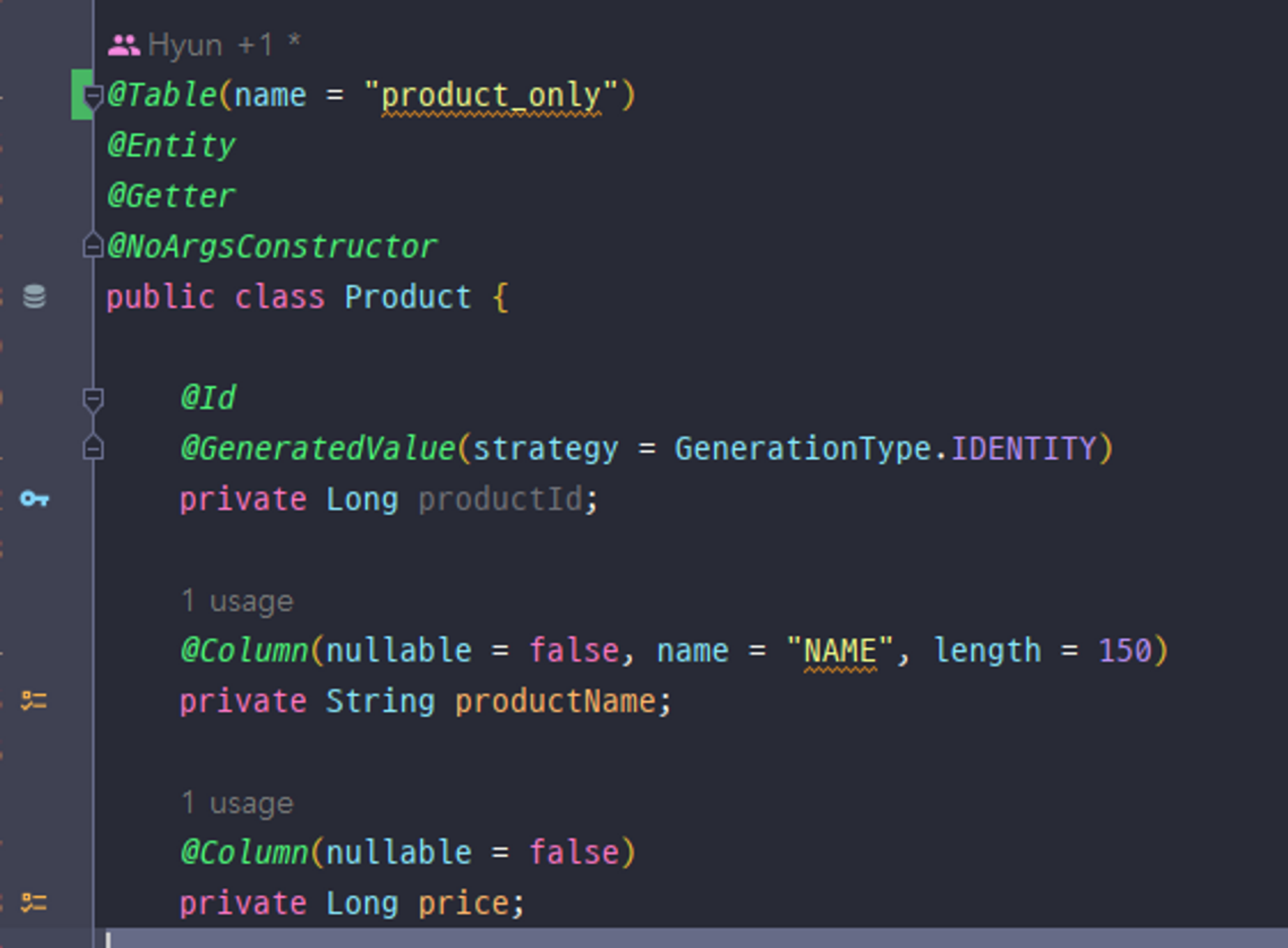
대상 테이블 product_only
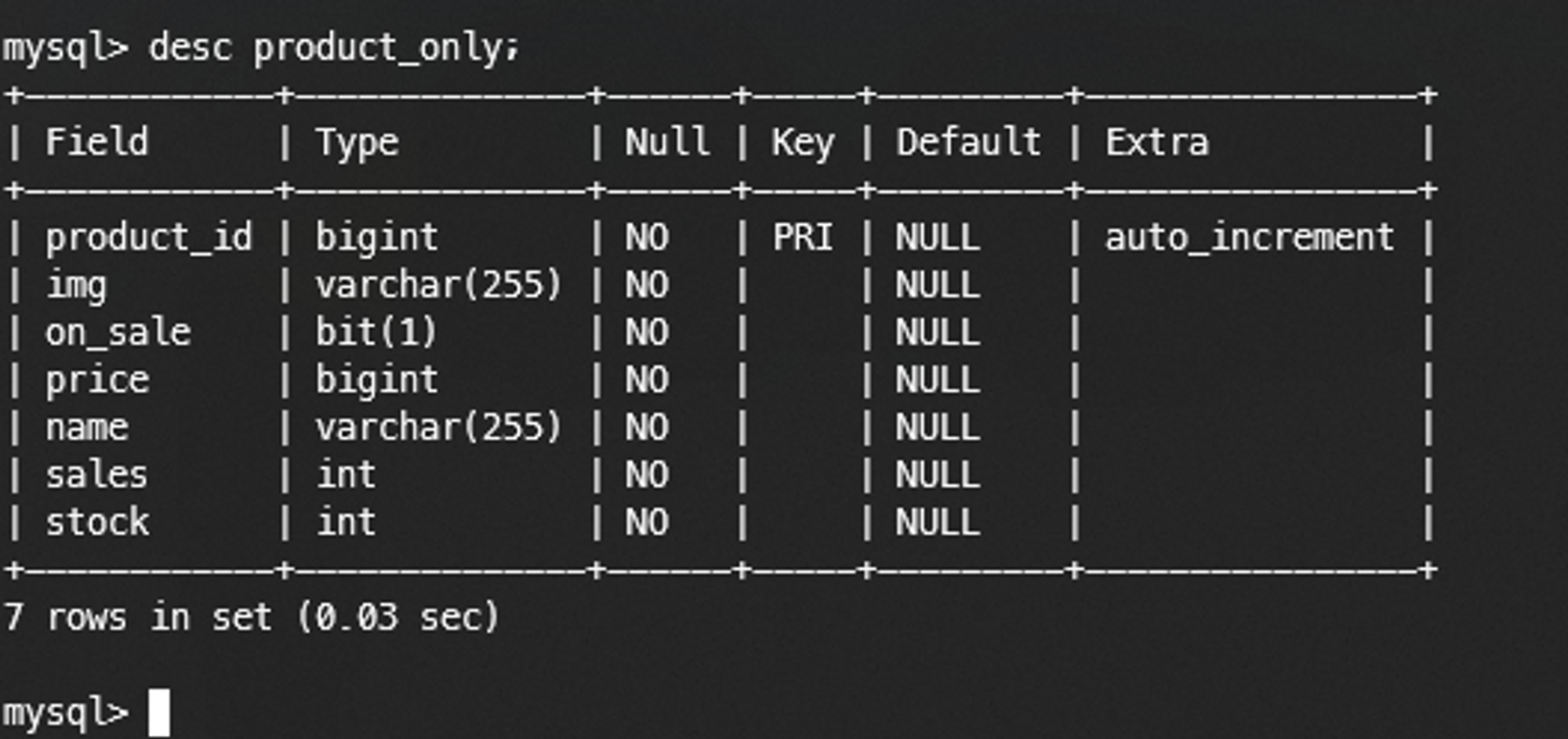
검색 대상 엔터티
포스트맨 요청 5회 결과
| 횟수 | 시간 (초) |
|---|---|
| 1차 | 22.06s |
| 2차 | 15.53s |
| 3차 | 17.15s |
| 4차 | 9.17s |
| 5차 | 9.06s |
Index 검색
대상 테이블 product_only_index
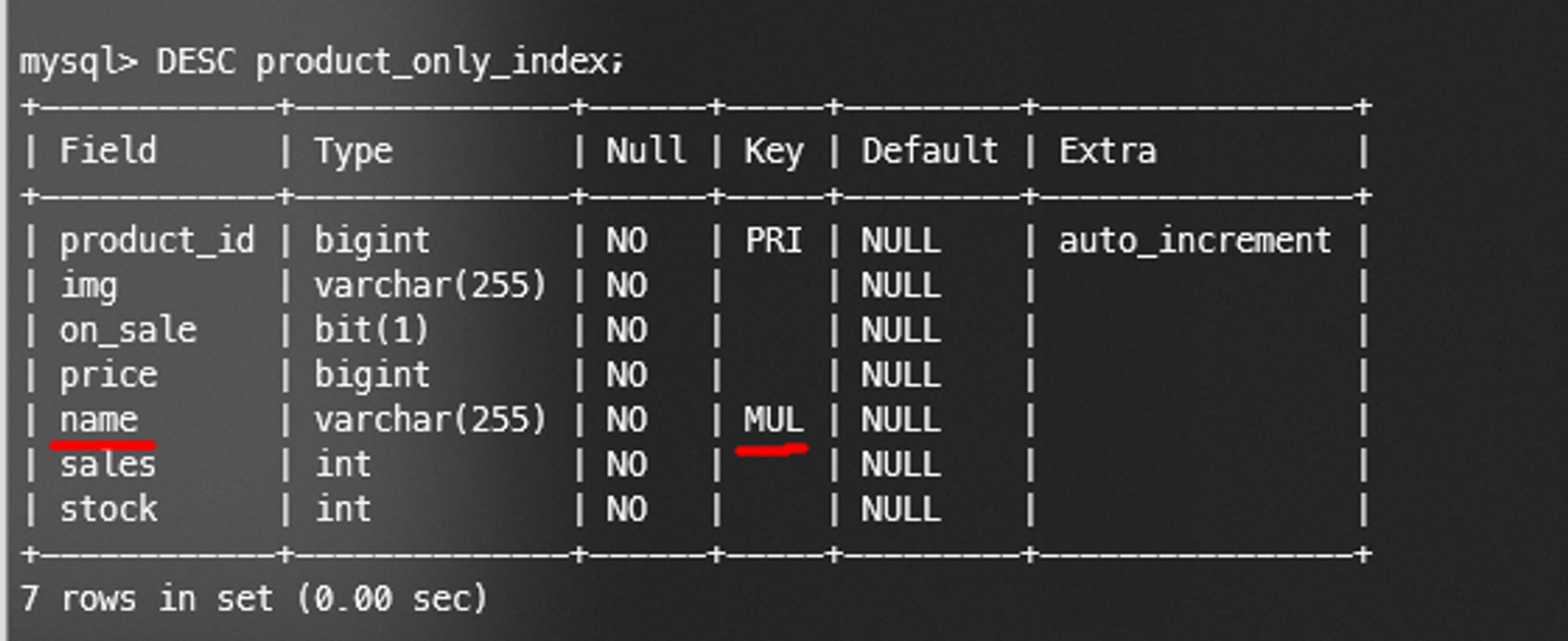

검색 대상 엔터티
포스트맨 요청 5회 결과
| 횟수 | 시간 (밀리초) |
|---|---|
| 1차 | 1924ms |
| 2차 | 70ms |
| 3차 | 57ms |
| 4차 | 90ms |
| 5차 | 52ms |
No Index vs Index
No Index
| 횟수 | 시간 (초) |
|---|---|
| 1차 | 22.06s |
| 2차 | 15.53s |
| 3차 | 17.15s |
| 4차 | 9.17s |
| 5차 | 9.06s |
Index
| 횟수 | 시간 (밀리초) |
|---|---|
| 1차 | 1924ms |
| 2차 | 70ms |
| 3차 | 57ms |
| 4차 | 90ms |
| 5차 | 52ms |
결론
Index를 부여한것으로 엄청난 속도 향상을 볼 수 있다.
하지만 단순 Index는 Keyword% 검색만 되므로 우리가 원하는 %Keyword% 검색을 할 수 없다.
이를 위해 Full Text Index, Covering Index를 부여해서 다음에 진행한다.
