Ops란 무엇인가
MLOps는 ML 시스템 개발(Dev) 과 ML 시스템 운영(Ops) 을 통합하는 방식을 의미한다. 소위 말해 단순 AI 모델 배포에서 끝나는게 아니라, 배포 전후 발생하는 이슈 모니터링 & 버그 발생시 Fix & 해당 버그를 Fix하여 새롭게 Commit한 버전을 배포 & 다시 모니터링을 포함한 운영적 관점에서의 ML 시스템을 자동화하는 것을 의미한다.
(전자) ML 시스템 개발에 대한 Flow는 대부분 회사에서 정립되어 있겠지만, (후자) 그에 대한 Ops 영역은 다방면에 두각을 나타내는 AI 전문가를 필요로 하기 때문에 각 서비스에 담당자가 분포되어 있을뿐 통합적으로 그 시스템이 관리되고 있지는 않다고 생각한다.
예컨대, 경진대회 같은 경우 하나의 정적인 Data Set 내에서 최고의 성능을 나타내는 것이 목표이기 때문에, 단 한 번의 올바른 모델 학습-추론만이 존재하면 된다. 하지만 실제 상용 서비스에서는 실시간 또는 배치성으로 데이터 수집 - 전처리 - 학습 - 추론 - 후처리 - 서빙이 발생하기 때문에, 해당 파이프라인에 대한 모니터링 - 운영 - 관리가 필요하게 된다.
다른 예시로, 내가 만든 train.py에 어느 순간 에러가 발생했다고 가정하자. MLOps가 아닌 비효율적인 조직에서는 그 이슈에 대한 원인을 파악하고자 ① 원천 데이터 서버와의 연동이 끊겼는지 ② 원천 데이터 서버의 규격이 변경되었는지 ③ 원천 데이터 서버와 시간 불일치로 인하여 배치 실패가 뜬건지 ④ train.py 결과물이 저장되는 저장소에 디스크 용량이 꽉차서 그런지 ⑤ 개발자와 관리자의 실수로 인하여 오류 버전이 배포된건지 ⑥ 타 서비스의 모델이 동일 시간에 실행되어서 GPU 메모리가 부족했는지 등 수백개 경우의 수를 따져서 이슈를 해결해야 한다. 이러한 경우 소위 ML이 시스템화, Ops화 되어있지 않는 한 그만큼의 MM이 소요될 것이고 이는 타 프로젝트에 병목현상을 발생시킬 수 있다.
"결론이 뭐야?" "Ops의 실체가 뭐라는건지 알려줘"
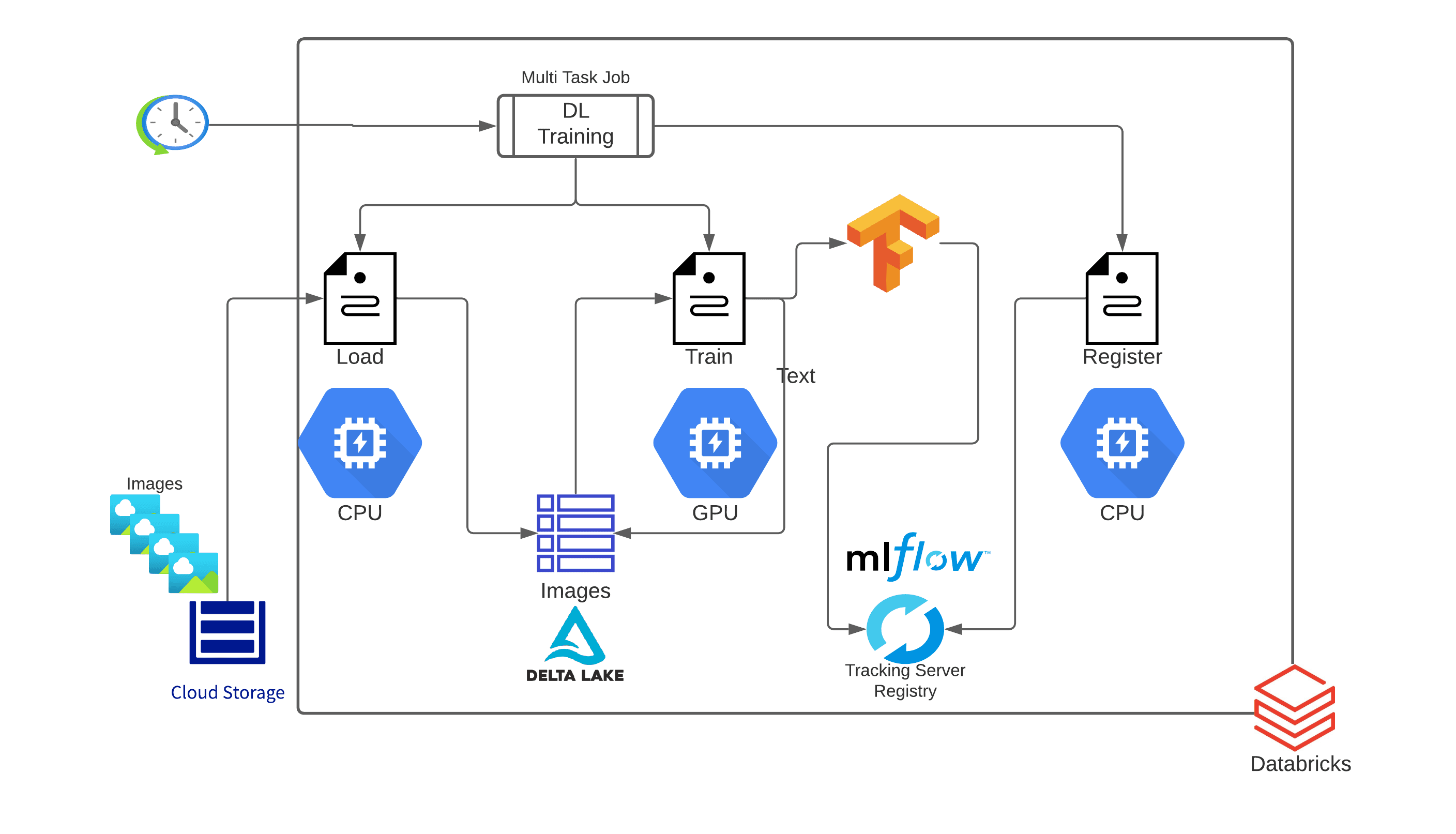
결국 Ops라는 것은 <데이터 수집 - 저장 - 관리 - 모델 개발 - 모델 버전 관리 - 배치 스케줄링 관리 - 모델 패키징 - 서빙 - 결과 모니터링 - 전체 파이프라인 매니징>와 같이 전반적인 ML 시스템 Flow에 관리 시스템을 구축하는 것이라고 생각한다.
예를 들어, 데이터 수집에는 Kafka, Sqoop, Flume / 데이터 저장에는 Hadoop, AWS S3, MySQL / 데이터 관리에는 TFDV, DVC, Feast / 모델 개발에는 Docker, Kubeflow, Optuna / 버전 관리에는 Git, MLFlow / 스케줄링 관리에는 Kubernetes / 모델 패키징에는 BentoML, Docker, Flask, FastAPI / 서빙에는 Prometheus / 전체 파이프라인 매니징에는 Airflow가 있을 수 있다.
(물론 AWS SageMaker나 GCP Vertex AI와 같이 위에 언급된 부분을 대부분 포함한 SaaS도 있다.)
이 태그에서 전부를 다루기는 시간이 오래 걸릴 것 같고, 우선적으로 회사에서 Feasibility를 체크하고자 하는 영역에 대한 지식만 정리하고자 한다.
