요약
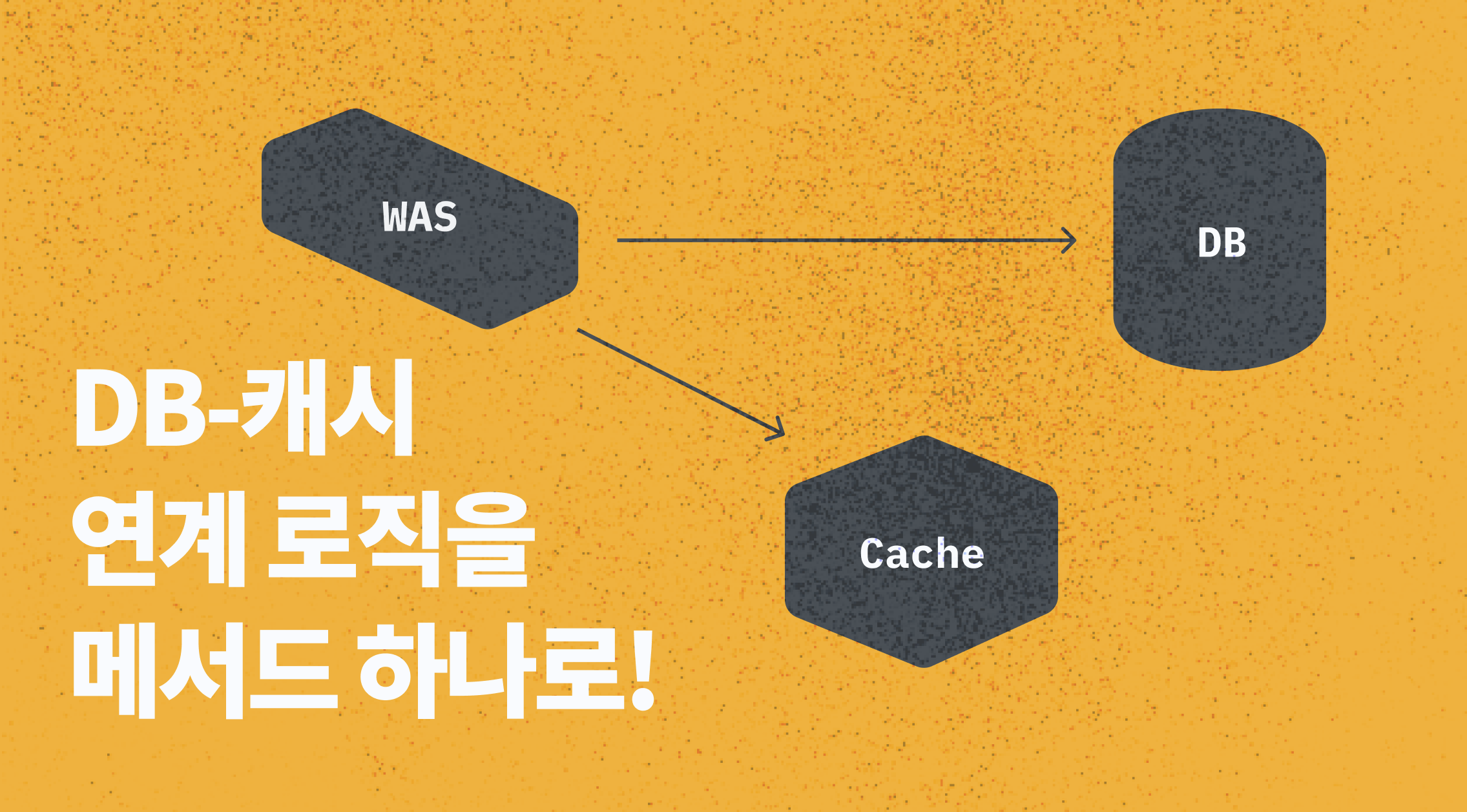
Self-Invocation 문제 때문에 @Cacheable 대신 직접 캐시모듈을 만들어 사용했습니다. look-aside 전략으로 캐시와 DB를 조회하는 getCacheOrLoad 메서드를 예로 들자면 캐시타입(이름)과 캐시키, DB 조회 함수를 인자로 받습니다. 인자로 받은 캐시타입과 키를 기반으로 레디스 캐시키를 생성해서 캐시를 먼저 조회해보고, 캐시가 없으면 인자로 받은 DB 조회 로직으로 DB를 조회합니다. DB 조회 로직의 대부분은 Repository를 이용해 findById로 조회하기 때문에 Repository 빈을 인자로 받아 DB를 조회할 수도 있지만, DB를 조회하는 방법에 유연성을 주기 위해 DB 조회 함수를 인자로 받는 방식을 택했습니다.
Entity의 id를 이용해 캐시와 DB를 조작하는 것은 범용적으로 쓰이는 로직이기 때문에, 이런 부분은 더 간결하게 쓸 수 있게끔 한 번 더 CacheableRepository라는 클래스로 감싸고 CacheType, JpaRepository 등 도메인 특화 필드를 주입하는 식으로 만들었습니다. 덕분에 JpaRepository처럼 캐시키 인자 정도만으로도 쉽게 캐시-DB 연계 로직을 수행할 수 있습니다.
enum을 이용해 캐시이름과 TTL 등을 쉽게 관리했고, 대부분의 경우 레디스 캐시키를
CacheName::entityId형식으로 만듬으로써 관리하기 쉽게 했습니다.
@Cacheable 대신 RedisTemplate을 이용한 캐시 모듈
캐시는 Look-aside, Write-through, flush(캐시를 DB에 적용) 등, DB와 함께 사용되어 다양한 전략으로 활용될 수 있습니다. @Cacheable 방식은 캐시 활용방식이 유연하지 않고, AOP의 Self-Invocation 문제도 있고, 해당 로직이 숨겨지게 되어 동료 개발자로 하여금 실수를 유발할 수 있을 것이라 생각되어 사용하지 않았습니다. 대신 RedisTemplate을 이용해서 Look-aside, Write-through, flush 등의 동작을 지원하는 캐시모듈을 만들었고 이를 담배200 프로젝트 전반에서 사용했습니다.
제네릭 활용
많은 Util 클래스가 그러하듯 다양한 타입의 객체를 캐시로 활용하기 위해 제네릭을 적극활용했습니다.
Enum으로 캐시 이름과 TTL, 저장할 레디스 서버 관리
문제
위의 캐시모듈 코드에서 CacheType이라는 타입을 볼 수 있습니다. 제가 정의한 enum인데 왜 만들었는지 설명드리겠습니다.
@Cacheable의 경우, 레디스 접근이 RedisCache에 의해 이뤄지고 여기 쓰이는 설정값들은 RedisCacheManager에서 설정할 수 있습니다. 캐시 이름과 함께 TTL을 지정해줄 수가 있는데, 이러면 'key'라는 키로 캐시를 저장할 때 자동적으로 키 앞에 캐시 이름을 붙여 CacheName::key로 캐시키를 만들어줍니다. 하지만 저는 Cacheable 말고 RedisTemplate을 사용했고, 이는 RedisManager의 설정에 영향을 받지 않아, 캐시 이름과 TTL을 글로벌하게 설정해줄 수 없었습니다. 그렇다고 캐시모듈 메서드를 매번 호출할 때마다 캐시 키와 TTL을 직접 생성해서 넘겨주는 건 문제라고 생각했습니다.
Enum으로 해결
캐시의 이름과 TTL을 관리하는 CacheType 이라는 Enum을 만들고, 캐시 모듈의 메서드는 CacheType값을 인자로 전달받아, 캐시 모듈 내부에서 redisTemplate을 호출할 때 CacheType enum 안의 캐시 이름 값과 TTL, 사용할 Redis 서버 값을 사용함으로써, 캐시 모듈을 사용하는 사용자는 캐시 이름과 TTL, 지정된 서버를 신경쓰지 않아도 되게 했습니다. (어떤 캐시가 어떤 Redis 서버에 저장될지)
@Getter
@AllArgsConstructor
public enum CacheType {
SESSION_INFO("SessionInfo", ONE_DAY * 7, RedisServerType.SESSION),
CIGARETTE("Cigarette", ONE_DAY, RedisServerType.CACHE),
ACCESS("Access", ONE_HOUR, RedisServerType.CACHE),
CIGARETTE_LIST("CigaretteList", ONE_HOUR, RedisServerType.CACHE),
CIGARETTE_DIRTY("CigaretteDirty", ONE_HOUR, RedisServerType.CACHE),
STORE("Store", ONE_HOUR, RedisServerType.CACHE),
USER("User",ONE_HOUR, RedisServerType.CACHE),
NOTIFIACTION("Notification", ONE_MINUTE * 10, RedisServerType.CACHE),
TEST("Test", ONE_DAY, RedisServerType.CACHE);
private String cacheName;
private int ttlSecond;
private RedisServerType redisServerType;
} // 인자로 넘겨진 cacheType eum을 통해 캐시키와 TTL, RedisTemplate을 추출해 캐시 작성
public <K, V> void put(CacheType cacheType, K key, V value){
ValueOperations ops = redisTemplateFinder.findOf(cacheType).opsForValue();
String cacheKey = getCacheKey(cacheType, key);
ops.set(cacheKey, value, cacheType.getTtlSecond(), TimeUnit.SECONDS);
} // cacheKey를 생성하는 메서드는 static import되어 hash, set 전용 캐시 모듈 등에서 사용된다.
public class CacheKeyGenerator {
public static <K> String getCacheKey(CacheType cacheType, K key){
return cacheType.getCacheName() + "::" + key;
}
}DB 로직은 함수형 인자로 전달
look-aside는 캐시를 먼저 조회한 뒤, 캐시가 없을 시 DB를 조회하는 로직인데, DB를 조회하는 로직을 어떻게 짜야할 지 고민이 있었습니다.
getCacheOrLoad(CacheType cacheType, K key, JpaRepository repository);처음엔 위와 같이 JpaRepository를 인자로 넣어서 내부적으로 findById 메서드를 호출하도록하면 될까 싶었는데, 꼭 findById가 아닌 다른 방식으로 데이터를 가져올 수도 있겠다 싶었습니다. 아니면 cacheKey가 entityId가 아닐 수도있고, 조회로직 앞뒤로 다른 로직이 추가적으로 들어갈 수도 있겠다 싶었습니다. 그래서 DB 관련 로직은 아래와 같이 람다식으로 전달함으로써, 사용자 측에서 유연하게 사용할 수 있도록 했습니다.
아래는 캐시 모듈 중 제일 자주 쓰는 getCacheOrLoad 메서드입니다. 캐시를 먼저 조회하고, 없을 경우에만 DB 조회 함수를 사용해서 값을 가져오고, 캐시에 반영합니다.
// 캐시모듈을 사용하는 쪽. DB 로직을 람다식으로 전달한다.
Cigarette cigarette = cacheModule.getCacheOrLoad(CacheType.CIGARETTE, id, id ->
cigaretteRepository.findById().OrElseThrow(EntityNotFoundException::new)); // 캐시 모듈. look-aside 조회 메서드
// cacheName, key에 해당하는 캐시들을 먼저 조회한 뒤, 캐시에 없으면 다른 저장소 조회(loadFunction 수행)
public <K, V> V getCacheOrLoad(CacheType cacheType, K key, Function<K, V> dbLoadFunction) {
String cacheKey = getCacheKey(cacheType, key);
V cached = (V) ops.get(cacheKey);
// 캐시에 값 있을 때 바로 리턴
if (cached != null)
return cached;
// 캐시에 값 없을 땐 다른 저장소 조회, 캐시에 저장
V loaded = dbLoadFunction.apply(key);
ops.set(cacheKey, loaded, cacheType.getTtlSecond(), TimeUnit.SECONDS);
return loaded;
}캐시모듈을 한 번 더 감싸 간결하게 사용하는 CacheableRepository
CacheKey가 꼭 Entity id로 되는 건 아니지만, Entity id를 CacheKey로 하는 Look-aside 조회, write-through 삭제 등 단순한 로직들은 여러 도메인에 걸쳐서 동일하게 사용되었고, 매번 DB 처리 함수과 캐시타입 등의 인자를 넣어줘야 했습니다. 이런 중복되는 부분은 좀 더 간결해질 수 있겠다 싶어서, 이런 로직은 한 번 더 CacheableRepository라는 클래스 안에 넣고, CacheType, Repository, KeyExtractor 등의 특정 도메인의 정보를 주입 받아 빈으로 등록해서 해당 도메인의 서비스 레이어에서 더 간결하게 호출할 수 있게도 했습니다.
🔗 도메인 공통 인자를 받아 도메인 특화 캐시 모듈 Bean(CacheableRepository) 생성
@RequiredArgsConstructor
public class CacheableRepository<K, V, REPO extends JpaRepository<V, K>> {
// 도메인 공통 인자들
final private CacheType cacheType;
final private REPO repository;
final private Function<V, K> keyExtractor;
final private CacheModule cacheModule;
// 모든 도메인에 쓰일 수 있을만한 공통 로직. 인자가 훨씬 줄어든다.
public List<V> getAllCacheOrLoadByKeys(List<K> keys){
return cacheModule.getAllCacheOrLoadByKeys(cacheType, keys, repository::findAllById);
}
...@Bean
public CacheableRepository<Long, Cigarette, CigaretteRepository> cigaretteCacheableRepository(){
return new CacheableRepository<>(CacheType.CIGARETTE, cigaretteRepository, Cigarette::getId, cacheModule);
}사용 시 훨씬 적어진 파라미터 (기존 3~5개 -> 1~2개)
// 적용 전
Cigarette cigarette = cacheModule.getCacheOrLoad(CacheType.CIGARETTE, id, id -> cigaretteRepository.findById().OrElseThrow(EntityNotFoundException::new));
// 적용 후
Cigarette cigarette = cigaretteCacheableRepository.getCacheOrLoad(id);
필요에 따라 유연함과 간결함을 선택할 수 있는 구조입니다.
그 외
- 맨 윗부부에서 CacheType이라는 enum 객체 안에 해당 캐시타입을 저장할 Redis Server가 적혀있다고 했는데, 이를 통해서 Redis Server와 통신하는 방법은 아래 글에 설명되어있습니다.
🔗 캐시와 세션별로 Redis 서버 분리 - 사용하다보니 캐시에 저장할 때 Entity를 DTO로, 꺼낼 땐 DTO를 Entity로 변환하는 로직도 필요해졌는데, 그 내용은 아래 글에 설명되어있습니다.
🔗 캐시에 저장 로드할 때 리플렉션으로 DTO‐Entity 변환
마무리
캐시모듈은 제가 만든 Util클래스 중 제일 규모가 있고 활용도도 높은 작업물이었습니다. 만들고나니, 여기저기 쉽게 적용이 되어 잘 작동하는 걸 보니 굉장히 뿌듯했습니다.
