핵심 조회쿼리에 복합인덱스를 설정해 조회성능 900% 개선(쿼리 실행계획 확인, 인덱스를 안타는 이유) 🔥
날씨 알리미 : "오늘 오후 8시에 비가 오니 우산을 챙겨요!"
요약
자주 쓰이는 요청의 Full-table 스캔을 막기 위해 where절에 쓰이는 칼럼에 복합인덱스를 적용하고, 실행계획을 보며 인덱스를 타는지 확인하며 시행착오를 거쳤습니다. 10만건의 더미데이터를 만들어 테스트 한 결과, 수행시간이 0.04초에서 0.00041초로 줄었습니다. (🌱 900% 개선)
성능이 많이 올라서 인덱스의 중요성을 느끼게 되었고, 복합 인덱스와 인덱스 스캔 기준, 실행 계획에 대해 이해할 수 있는 좋은 실습이었습니다. 무엇보다, 직접 어떻게 개선할지 고민하고 실제 수치상으로 드러낸 게 뿌듯합니다.
복합인덱스를 적용하기위해 아래의 과정을 거쳤습니다.
1. 처음엔 PK를 복합키로 만들었습니다. 성능 최적화를 위해 카디널리티와 조회 조건을 고려해 순서를 지정했습니다.
2. 테이블 변형이나 다른 테이블의 참조에 어려움을 주는 안티패턴이라 생각해, PK는 그냥 단일키로 만들고 별도의 복합키를 만들었습니다.
3. explain 명령어로 조회 쿼리를 분석해봤는데, 기대했던 대로 인덱스를 타지는 않았었습니다.
4. 알고보니 칼럼과 where 조건의 타입이 달라서 생기는 문제임을 알게되고, 두 타입을 일치시켜주고 실행계획을 보니 인덱스를 탔고 조회성능이 900% 개선되었습니다.
문제 : Full Table Scan 안돼~
이 서비스는 오늘 특정 지역의 날씨를 기반으로 알림을 주기 때문에, 지역(동등)과 시간(범위)을 기반으로 조회하는 쿼리가 자주 쓰입니다. 그런데 오직 날씨 정보의 PK인 id에만 인덱스가 적용되어 있어서, 지역, 시간을 기반으로하는 조회가 Full Table Scan이 되는 문제가 있었습니다. 그래서 인덱스를 적용해 인덱스를 타게 하면 조회 성능이 향상될 것이라 기대했습니다.
explain select * from
weather_info
where
weather_region="2600000000" -- 인덱스 X
and (
fcst_time between "202305150500" and "202305150600" -- 인덱스 X
); -- -> Full Table Scan시도 : 복합키 PK
다른 조회 조건은 없으니, 기존에 있던 id PK를 지우고 저 조합으로 복합키를 생성하면 클러스터 인덱스를 타서 조회 성능이 크게 증가할 수 있는 좋은 방법이라 생각했습니다.
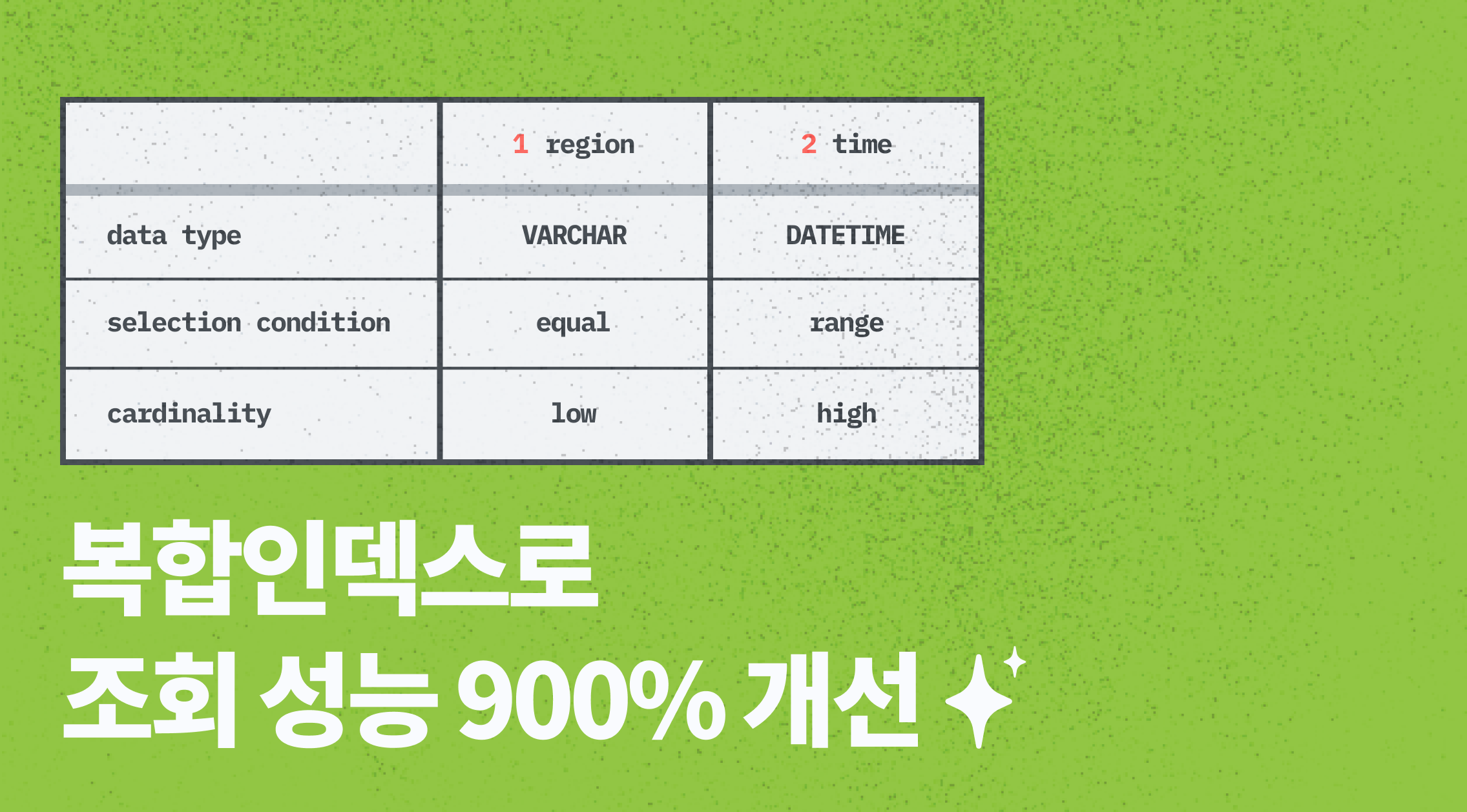
| ⛰️ ️지역 | 🕰️ 시간 | |
|---|---|---|
| 데이터 타입 | 문자열 | 문자열 |
| 조회 조건 | 동일 | 범위 |
| 카디널리티 | 낮음 | 높음 |
날씨 정보 중 [지역, 시간] 순서로 복합인덱스로 만들었습니다.
둘 조건 모두 동일 조건이라면 카디널리티가 높은 순서대로 하는 게 좋겠지만, 한 조건이 범위 조건이 때문에, 일반적으로 [값, 범위]보다 [범위, 값] 순서의 인덱스가 인덱스를 탈 확률이 높다고 해서 이렇게 지정했습니다.
그리고 Jpa에서 복합키를 인식할 수 있도록 @EmbbededId를 사용해서 복합키를 WeatherInfoPk라는 객체에 맵핑했습니다. 그런데 과연 복합키를 PK로 쓰는 게 맞을까 싶었습니다. 그래서 검색을 해보니, 이동욱님의 의견으로는 PK는 단일키가 좋다고 한다는 걸 알게되었습니다. 그 이유는 아래와 같았습니다.
1. FK를 맺을 때 다른 테이블에서 복합키를 모두 갖고있거나, 중간 테이블을 둬야하는 상황이 발생
2. 인덱스에 좋은 영향을 끼치지 못함
3. 유니크한 조건이 변경될 경우, PK전체를 수정해야 하는 일이 발생생각해보니, 미래에는 Unique하지 않게 저장하게 될 수도 있겠다고 생각되었고, 특정 비지니스 목적을 위한 복합키를 PK로 만드는 건 좋지 않겠다고 동의하게 되었습니다.
시도 2 : 복합 인덱스
Long 타입의 Auto Increment한 단일컬럼 PK를 두고, 따로 복합 인덱스를 만들어주기로 결정했습니다.
ALTER TABLE weather_info ADD UNIQUE region_fcst(weather_region, fcst_time) ;
실행 계획 결과 : 왜 안되지?
explain select * from
weather_info
where
weather_region=2600000000
and (
fcst_time between "202305150500" and "202305150600"
);인덱스를 설정했으니 그런데 기대와는 달리 인덱스를 타지 않는 모습이었습니다. 인덱스 컬럼 순서를 바꿔보기도하고, 문자열 range 검색이 index를 잘 안타는 건가 싶었지만 이유를 알 수 없었습니다. 계속 찾아보고 생각해보고 위 쿼리문을 들여다보니 머릿속에 한가지 생각이 스쳤습니다.
'weather_region은 문자열 컬럼인데 숫자로 비교하고 있네?'
생각해보니 이런 경우 형변환이 진행되어 인덱스를 타지 않는다고 읽은 적이 있었습니다.
실행 계획 결과 : 이제 된다 !
weather_region 조건을 숫자가 아닌 문자열로 만들어주니, 이번엔 Full Table Scan이 아닌 Index Range Scan함을 확인할 수 있었습니다.
explain select * from
weather_info
where
weather_region="2600000000" --weather_region=2600000000가 아니라
and (
fcst_time between "202305150500" and "202305150600"
);10만건의 더미데이터를 만들어 테스트 한 결과, 수행시간이 0.04초에서 0.00041초로 줄었습니다. (🌱 900% 개선)
인덱스를 안 타는 이유
타입 불일치 말고 다른 이유들로 인덱스를 타지 않을수도 있습니다.
- WHERE에 컬럼에 변형을 가했을 때
WHERE id * 2 = 6
- <, > NOT-XX로 비교된 경우
<,>,NOT IN,NOT BETWEEN,IS NOT NULL
- 보조인덱스에서 조회 내용이 전체의 15% 이상일 때 (클러스터는 X)
- 클러스터인덱스에선 그래도 인덱스를 사용하기 때문에 직접 인덱스 사용을 비활성화해줘야할 때도 있음
- (A,B,C) 순서로 복합 인덱스를 구성했는데, 서로 다른 정렬방향으로 조회하는 경우
- MySQL 5.7 이하의 복합 인덱스는 모든 칼럼이 한 방향으로만 정렬이 가능해서, 정렬을 섞어서 조회하면 인덱스를 타지 않는다.
- NOT-DETERMINISTIC 속성의 스토어드 함수가 비교조건에 사용된 경우
- NOT-DETERMINISTIC 속성의 스토어드 함수란, 매번 스토어드 함수를 실행했을 때 결과가 달라지는 함수다.
WEHRE id = my-procedure()
- LIKE 뒷부분 일치로 비교된 경우
WHERE nickname LIKE "%tail"
- 데이터 타입이 서로 다른 비교
- 인덱스 컬럼의 타입을 변환해야 비교가 가능한 경우.
- 값을 변경해야하는 경우는 상관 없다.
- 문자열 데이터 타입의 콜레이션(utf-8 같은)이 다른 경우
느낀 점
성능이 많이 올라서 인덱스의 중요성을 느끼게 되었고, 복합 인덱스와 인덱스 스캔 기준, 실행 계획에 대해 이해할 수 있는 좋은 실습이었습니다. 무엇보다, 직접 어떻게 개선할지 고민하고 실제 수치상으로 드러낸 게 뿌듯합니다.
출처
