saveAll이 N개 쿼리를 보내는 이유 (save와 GenerationType.IDENTITY의 관계)
날씨 알리미 : "오늘 오후 8시에 비가 오니 우산을 챙겨요!"

요약
saveAll 메서드를 사용하니 N개의 Insert문이 발생했습니다. 이는 Id가 Auto Increment인 엔티티의 Insert를 수행할 때 발생하는 문제임을 인지했고, Id가 Auto Increment가 아닌 엔티티에서라도 Batch Insert가 나가도록 설정했습니다. 이렇게 실행되는 쿼리문을 직접 보면서 이유를 알아가고 내부 작동방식을 알아보고 하나씩 수정해나가는 게 재미있었습니다.
saveAll이 N개 쿼리를 보내네?
saveAll 메서드를 사용할 때 Iterable의 모든 원소에 대해 Insert문이 1개씩 나가는 문제가 있었습니다. DB 통신이 잦아지면 시간도 오래걸리고 병목이 될 가능성이 있기 때문에, 이걸 배치 인서트로 바꿔야 했습니다.
GenerationTye.IDENTITY가 원인
Hibernate에선 AutoIncrement(GenerationType.IDENTITY)이고 Update가 아닌 Insert할 경우엔 각각 인서트된다고 합니다. 왜냐하면 Persistence Context 내부에서 엔티티를 식별할때는 엔티티 타입과 엔티티의 id 값으로 엔티티를 식별하지만 IDENTITY 의 경우 DB에 insert 문을 실행해야만 id 값을 확인 가능하기 때문에 batch insert 를 비활성화한다고 합니다.
해결
AutoIncrement가 아닌 키를 가진 엔티티에라도 배치 인서트를 적용하기 위해 구글링해봤는데, 아래와 같은 설정으로 간단하게 설정될 수 있었습니다.
일단 order_inserts와 order_updates는 insert와 update문을 번갈아가면서 보내지 않고 같은 구조의 insert 혹은 update문끼리 묶어서 보내겠다는 뜻입니다.
그리고 batch_size는 같은 구조의 쿼리일 때 최대 n개씩 묶어서 보내겠다는 뜻입니다.
spring:
jpa:
properties:
hibernate:
order_inserts: true
order_updates: true
jdbc:
batch_size: 500
datasource:
url: jdbc:mysql:://DB주소:포트/스키마?rewriteBatchedStatements=true
주의해야할 점은 중간에 다른 연산이 끼어있으면 batch size에 상관없이 나누어서 보내져야한다는 것입니다.
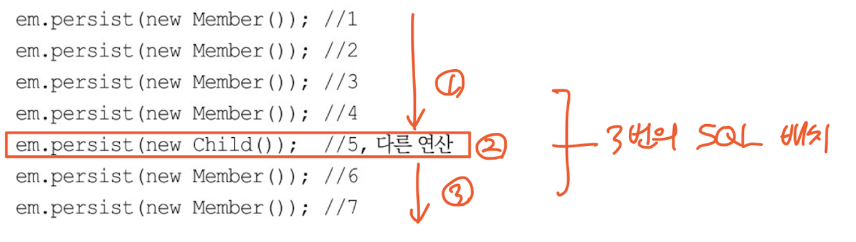
결과
스프링에서 나오는 로그에는 배치인서트가 표현되지 않았지만, MySQL에서 실제로 실행되는 쿼리 로그를 보니 배치인서트가 잘 실행됨을 볼 수 있었습니다.
MySQL의 로그를 보기 위해선 db source url에 아래를 추가하면 됩니다.
jdbc:mysql://[유알엘]&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999다른 것도 알아보자
위 문제에 대해 조사하다가 우아한 형제들의 테크 블로그의 글을 보고 해당 내용을 간략하게 정리해보도록하겠습니다. 자세한 설명을 원하시면 링크 속의 글을 참조해주세요.
ID가 자동증가일 때
Insert
하나씩 Insert함 원인은 id를 알 수 없어서입니다.
Update
MySQL 드라이버는 3개 이하의 업데이트인 경우엔 한건씩 쿼리를 실행하도록 되어있습니다. 대신 인서트는 3개 이하여도 배치 인서트합니다.
ID가 자동증가가 아닐 때
Insert & Update
order_insert/update, batch_size 등 값을 조정해 Batch Insert를 할 수 있습니다.
하나의 트랜잭션 내에서 동일한 종류의 엔티티를 Select 후 Update하는 것을 반복
flush할 때 한번에 업데이트하지 않고, 두번째 select 전에 update가 실행됩니다. 쿼리에 명시된 엔티티가 쓰기지연 SQL 저장소에 있다면 flush를 한다고 합니다.
하나의 트랜잭션 내에서 다른 종류의 엔티티를 Select 후 Update
동일한 엔티티를 조회했을 때와는 달리 조회가 끝나고 flush() 를 호출했을때 update 쿼리가 실행됩니다.
복합적일 때
하나의 트랜잭션에서 IDENTITY 엔티티와 NON-IDENTITY 엔티티를 번갈아가며 SAVE
IDENTITY 저장 시도 → 쓰기지연 SQL 저장소 flush → IDENTITY 저장 (쓰기지연 SQL 저장소에 넣지 않고 바로 DB 반영)
IDENTITY가 적용된 엔티티를 저장할때는 항상ActionQueue(쓰기지연 SQL 저장소) 내부에 이미 저장되어 있는 insert 작업들을 먼저 실행 후IDENTITY를 저장하기 때문에IdentityEntity와NonIdentityEntity가 번갈아가며 insert 문이 실행되었습니다.
그리고 IDENTITY 가 적용된 엔티티를 insert 할 경우에는 예외적으로 ActionQueue 에 insert 작업을 넣지 않고 바로 insert 작업을 실행합니다.
Save할 때 실행되는 select
select하는 이유
Non-identity entity에 id를 직접지정해서 객체를 생성해서 DB에 저장하려고하면 select문이 나가게 됩니다. 원인이 뭘까요?
id ≠ null일때, 영속성컨텍스트에선 이게 new가 아니라 생각해서 merge(update)를 수행하려 합니다. update를 위해 DB에 존재하는지 확인하기 위해 select를 보내는 것입니다. 이 때 DB에 없는 레코드니 update도 수행되지도 않습니다.
이 내용은 CrudRepository의 save 메소드의 내부 구현을 보면 알 수 있습니다.
@Transactional
public <S extends T> S save(S entity) {
if (this.entityInformation.isNew(entity)) {
this.em.persist(entity);
return entity;
} else {
return this.em.merge(entity);
}
}확인해보면 entity의 상태가 isNew면 persist하고 다른 경우엔 merge를 합니다. 즉 isNew가 false이기 때문에 계속 merge가 실행되었던 것입니다.
한 트랜잭션에서 가져온 id는 영속성 컨텍스트에 포함되어 있어서, save에서 isNew 판단이 되지 않아 update 여부를 확인하기 위해 계속 select를 해왔던 것입니다.
즉 결과적으로는 트랜잭션 단위를 잘 관리해야 합니다.
entity.isNew() 강제정의
아래와 같이 엔티티의 isNew()를 강제적으로 true로 정의해주면 이 문제를 해소할 수 있습니다.
@Entity
@Table(name = "some_table")
@AllArgsConstructor @NoArgsConstructor
@Getter @Builder @ToString
public class SomeEntity implements Persistable<String> { // id의 타입을 제네릭에 넣어준다.
...
@Override
public boolean isNew() {
return true;
}
@Override
public String getId() {
return this.id;
}
}그 외에도 리스너를 활용한 방법, createdDate을 활용한 방법도 있습니다.
느낀 점
이렇게 실행되는 쿼리문을 직접 보면서 이유를 알아가고 내부 작동방식을 알아보고 하나씩 수정해나가는 게 재미있었습니다.
참조
