Multimodal RAG 프로젝트를 하면서, ColPali 모델을 다루게 되었는데 이 모델에서 LoRA 기법이 사용되었다고 하여, 공부하게 되었다. 원 논문과 게시물 하단에 기재한 블로그를 참고하여 공부하였습니다.
- paper : LoRA: Low-Rank Adaptation of Large Language Models
- github : https://github.com/microsoft/LoRA
- huggingface : https://huggingface.co/docs/peft/v0.14.0/package_reference/lora
🌟 LoRA
✅ 요약
📌 정의
Low-Rank Adaption의 약어로 Parameter-Efficiet Finetuning(PEFT) 방식 중 하나
📌 장점
- 사전 학습 모델의 weight를 update 하지 않고도 fully fine-tuning한 결과와 비슷하거나 더 좋은 성능을 보였다.
- weight update에 필요한 weight가 오직 LoRA_A, LoRA_B에 있는 weight 뿐이기 때문에 VRAM을 상당히 save할 수 있다.
- 학습된 모델로 inference해도 pre-trained model로 inference 할 때와 동일한 연산량이다. (추론 시간이 거의 동일)
- pre-trained model weight를 freeze한 상태로 (LoRA_B x LoRA_A) 행렬을 단순히 더해주기 때문에 Pre-trained model weight로 다시 원복하기 쉽다. (더해준 만큼 빼면 되기 때문)
📌 Introduction
NLP의 많은 애플리케이션은 하나의 대규모 사전 학습된 언어모델을 여러 다운스트림 애플리케이션에 적용하는 데에 의존한다. 이러한 adaptation은 일반적으로 사전 학습된 모델의 모든 파라미터를 업데이트하는 fine-tuning을 통해 수행된다. Fine-tuning의 주요 단점은 새 모델에 원래 모델만큼 많은 파라미터가 포함된다는 것. 특히 더 큰 모델이 주기적으로 학습됨에 따라, 배포하는 데에 중요한 문제가 된다.
많은 사람들이 일부 파라미터만 조정하거나 새로운 task를 위한 외부 모듈을 학습하여 이를 완화하려고 했다.이렇게 하면 각 task에 대해 사전학습된 모델 외에 소수의 task별 파라미터만 저장하고 로드하면 되므로 배포 시 운영 효율성이 크게 향상된다.
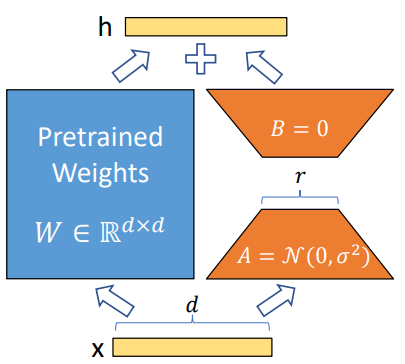
📌 Method (작성중)
- attention layers 내의 large matrix를 two smaller low-rank matrices로 decompose하는 방식이다.
- 매개변수 가중치 중 일부만 미세조정하고, 나머지는 원래대로 유지
(1) Low-Rank-Parametrized Update Matrices
A Generalization of Full Fine-tuning
No Additional Inference Latency
(2) Applying LoRA to Transformer
📌 장점
- 훈련비용과 컴퓨터 리소스를 절약하면서도 성능을 향상시킬 수 있다.
- 전체 매개변수를 사용하는 큰 체크포인트 파일 대신 작은 체크포인트 파일을 얻어 메모리를 적게 사용하면서 대규모 모델의 학습을 가속화한다.
참고
