
무한 스크롤
무한 스크롤이라고 말하면 뭔가 어려워 보인다. 하지만 무한 스크롤도 결국 페이지네이션과 비슷한 느낌이다. 페이지 네이션이 특정 페이지를 클릭하면, 그 페이지의 정보를 불러온다면 무한 스크롤은 말그대로 스크롤이 가장 하단에 위치하면 새로운 데이터를 불러오는 것이다.
구현할 기능 두 가지
여기서 가장 먼저 생각해볼 수 있는 것은 '어떻게 스크롤을 끝까지 내렸는지 판달할까' 이다. 그 다음이 '어떻게 데이터를 불러오고, 이 데이터를 UI에 출력할까' 가 된다. 이 두개만 한다면 무한 스크롤은 끝이다.

하지만 우리는 누구인가. 바로 효율을 생각하는 개발자이다. 설마 "그냥 구현만 해야지!" 라고 생각한 사람은 없을 것 같다.(사실 나도 onScroll 이벤트 부터 생각했다.)
무한 스크롤을 구현했는데, 최적화가 최악이여서 이미지가 너무 늦게 불러와진다던가 버벅 거림이 심하다면 없으니만 못한 기능이 되는 것이다.
구현하는 다양한 방법
무한 스크롤을 구현하는데 사용할 수 있는 방법에는 onScroll, IntersectionObserver 등을 사용하는 방법이 있다.
맨 아래의 Element가 감지 되면 특정 함수를 호출해서 데이터를 요청하기만 하면 무한 스크롤은 구현되므로, 일단은 스크롤 감지에 집중하자.
onScroll
기본적인 스크롤 이벤트를 이용해서 무한 스크롤을 구현할 경우 scrollHeight, scrollTop, clientHeight 이 3가지의 속성을 사용하게 될 것이다. 각각 무슨 역할을 하는지 알아보자.
scrollHeight

첫 번째 속성은 scrollHeight 이다. document.documentElement.scrollHeight;와 같이 사용하면 해당 페이지의 전체 높이가 스크롤 높으로 측정이 된다. 컴포넌트의 높이를 사용하고 싶다면 useRef를 이용하면 된다. 변수.current.scrollHeight 와 같은 모양이 될 것이다.
scrollTop

두 번째 속성은 scrollTop 이다. 현재 스크롤에서 가장 상단의 위치를 알려준다. 스크롤을 끝까지 내린다면, scrollTop값은 scrollHeight가 될 것 같지만 자신의 높이만큼 빼줘야한다. 왜냐하면 아무리 가장 아래로 스크롤이 내려갔더라도 현재 스크롤의 위치는 바닥에서 해당 컴포넌트 UI의 높이만큼 위에있기 때문이다.
clientHeight
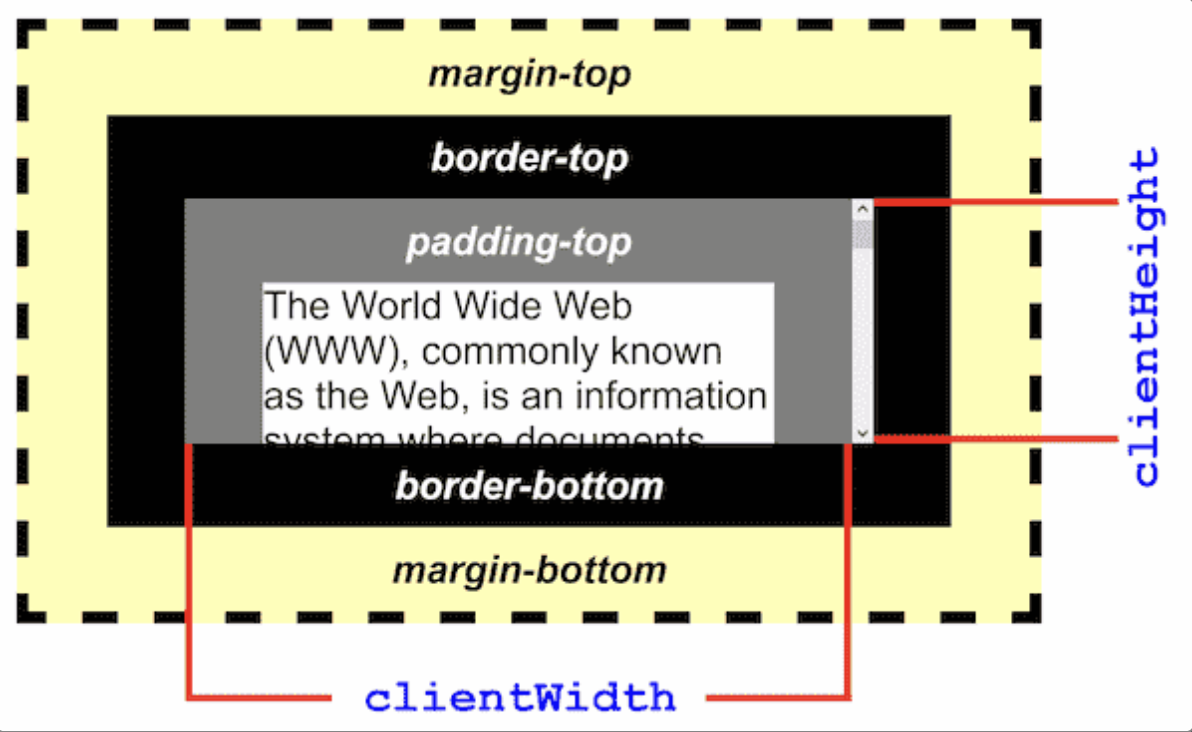
clientHeight는 클라이언트의 뷰 높이이다. 스크롤을 가장 아래로 내렸을 때, scrollHeight - scrollTop을 하면 클라이언트가 현재 보고있는 웹 사이트의 크기값이다.
예를 들어, 내가 누군가의 벨로그의 글을 중간 정도 까지 읽는중이라고 가정하자. 이 경우 스크롤은 당연히 중간에 있다. 그러면 scrollHeight - scrollTop의 값은 내가 보고있는 벨로그 화면의 크기보다 훨씬 클 것이다. 하지만 끝까지 내린다면 이 값은 같아지게 되는 것이다.
if (scrollHeight - scrollTop >= clientHeight) {
moreDataFetch()
}이제 우리는 하나의 공식을 유추할 수 있다. 스크롤을 가장 아래까지 내렸을 경우를 생각하면 ===만 있으면 될 것 같지만, >를 굳이 넣은 이유는 특정 브라우저에서 스크롤이 바운스 되는 경우가 있기 때문이다.(사파리)
이제 if문을 통과한다는 것은 무한 스크롤에서 데이터를 더 가져와야 하는 상황이므로 데이터를 더 가져오는 함수를 넣어주면 되는 것이다.
구현
우리는 어떤식으로 스크롤의 바닥을 감지하는지 알아보았다. 그냥 스크롤의 가장 하단을 위한 이벤트를 사용하면 안될까? 나도 그러고 싶지만 그런 속성은 없다. 이제 무한 스크롤을 구현해보자.
export const Component = ()=> {
const [data, setData] = useState([]);
const [page, setPage] = useState(1);
const handleScroll = () => {
const scrollHeight = document.documentElement.scrollHeight;
const scrollTop = document.documentElement.scrollTop;
const clientHeight = document.documentElement.clientHeight;
if (scrollHeight - scrollTop >= clientHeight) {
setPage((prev) => prev + 1);
}
};
const {isLoading, data, refetch} = useMoreData(page)
useEffect(() => {
refetch();
}, [page]);
useEffect(() => {
window.addEventListener('scroll', handleScroll);
return () => {
window.removeEventListener('scroll', handleScroll);
};
}, []);
if(isLoading) return <div>loading...</div>
return (
<>
{data?.map((title) => (<div key={title}>{title}</div>))}
</>
);
}React Query의 useQuery에서는 refetch라는 것이 있다. 쉽게 말해서 refetch를 호출하면 데이터를 요청하는 것이다. (궁금하면 이 글을 참고하자.) 스크롤이 바닥에 닿을때마다 page는 증가하고, 이 page가 증가하면 refetch를 호출하여 데이터를 요청하게 된다.
`엔드포인트/page=${page}`데이터를 요청할 때, 우리는 다음 페이지의 정보를 가져오는 것이므로 BackEnd에서 엔드포인트가 잘 되어있다면 이런식으로 쉽게 요청할 수 있을 것이다.
문제점
이것도 나름 성능을 고려한다고 useEffect를 사용하고, 이벤트 사용 후에는 메모리 누수가 일어나지 않도록 clean up 한다.(useEffect에서 return부분)
하지만 이렇게 구현해도 이 무한 스크롤에는 문제가 있다. 스크롤을 움직이면, 계속 동기적으로 함수를 호출한다는 것이다. 메인 스레드에 계속 영향을 미치기 때문에 성능 저하가 발생한다. 그리고 애초에 clientHeight와 같은 속성은 해당 Element의 최신값을 계산하기 위해 리플로우를 계속 발생시킨다.
그래도 무한 스크롤이 아니면 여러 방면에 사용할 수 있는 개념이므로 알고는 있자.
Intersection Observer API
Intersection Observer는 Web API중 하나로 지연 로딩(lazy-loading), 광고 수익을 위한 광고 가시성 참고, 특정 위치에서 애니메이션 동작 등 여러 기능을 구현할 때 사용된다. 또한, 무한 스크롤에서도 많이 사용한다.
비동기적으로 실행되기 때문에 메인 스레드에 영향을 미치지 않아 onScroll의 문제점을 해결한다. 그리고 웹에서 성능 저하를 시키는 주범인 리플로우를 발생시키지 않는다는 장점도 있다. 관찰할 컴포넌트를 선택하고 감지하는 역할을 해서 스크롤을 해도 계속 이벤트를 호출하지 않는 것이다.
tip) npm이나 yarn 으로 따로 설치할 필요가 없다.
IntersectionObserver과 options
const observer = new IntersectionObserver(callback[, options])IntersectionObserver는 target Element가 교차되었을 경우 실행할 callback 함수와 options을 인자로 받는다. 보통 옵션 중 threshold를 가장 흔하게 사용한다. 0.5로 설정하면 관찰 대상이 50% 이상 들어오면 콜백 함수를 호출하게 되는 옵션이다. 이 외에도 교차 영역의 기준이 될 root Element를 결정하는 root, 교차 영역의 확장 또는 축소를 위한 rootMargin 옵션도 있다.
callback
const callback = (entries, observer) => {};콜백 함수는 entries 객체의 리스트와 자기 자신인 observer를 받는다. entries을 forEach로 반복문을 돌리며 사용하게 된다. 자세한 동작은 전체 코드에서 알아보자.
observe
observer.observe(targetElement)observer는 위에서 생성했었다. 여기서 observe 메소드를 사용할 수 있는데, target Element에 대한 IntersectionObserver를 등록할 때 사용한다. 즉, 이제 이 요소를 관찰하겠다고 선언하는 것이다.
unobserve
observer.unobserve(targetElement)더 이상 관찰하지 않겠다는 메소드로 unobserve를 사용할 수 있다. 무한 스크롤에서는 바닥을 한번 감지하고 데이터를 불러온 후 원래 관찰하던 부분은 그만 관찰해도 된다. 새로운 바닥이 생기기 때문이다.
구현
export const useInfiniteScroll = () => {
const [page, setPage] = useState(1);
const [lastIntersecting, setLastIntersecting] = useState<HTMLElement | null>(null);
const {refetch} = useMoreData(page)
const onIntersect: IntersectionObserverCallback = (entries, observer) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
setPage(prev => prev + 1);
observer.unobserve(entry.target);
}
});
};
useEffect(() => {
refetch();
}, [page]);
useEffect(() => {
let observer: IntersectionObserver;
if (lastIntersecting) {
observer = new IntersectionObserver(onIntersect, { threshold: 0.5 });
observer.observe(lastIntersecting);
}
return () => observer && observer.disconnect();
}, [lastIntersecting]);
return {
setLastIntersecting,
};
};이번에는 무한 스크롤 부분은 관심사의 분리를 하기 위해서 Custom Hooks로 만들어 두었다. 이것도 마찬가지로
page가 변경되면refetch를 수행하는 것은 같고, 바닥을 감지하는 방법만 다르다.
먼저 onIntersect를 보면, entries에서 반복문을 돌며 if문으로 문언가 해주고있다. 이 부분이 화면 안에 요소가 들어왔는지 체크하는 부분이다. 만약에 화면에서 감지하기로 시작한 요소가 나타나면 page를 증가시키고 원래 감지하던 요소를 unobserve로 해제한다. 참고로 page가 증가하면 refetch 함수가 호출되므로 데이터를 더 요청할 것이다.
이제는 어떤 것을 감지할 것인지 결정하는 부분을 보자. 위에서 lastIntersecting라는 state를 null로 초기화 하며 선언했다. 이 값이 존재 할 때, observer에 new IntersectionObserver를 할당 해준다. 이 요소를 observe로 관찰하기 시작하는 것이다.
useEffect를 최적화 하기 위해 observer에 대해서 disconnect(useEffect clean up)를 해주고 있다. 또한, lastIntersecting에 변화가 생길때마다 이 과정이 수행된다.
우리는 lastIntersecting이 존재해야 관찰을 시작하고, 마지막 요소가 감지되면 page를 증가시켜 데이터를 요청한다는 과정은 알았다. 이제 생각할 부분은 "데이터가 증가했을 경우 lastIntersecting에 변화가 생기게 해서 위의 useEffect를 실행하게 할까?"와 "애초에 lastIntersecting를 어떻게 존재하게 하지?" 이다. 이 부분은 Custom Hook이 아닌 컴포넌트에서 수행되므로 여기서는 setLastIntersecting를 리턴해주고 있다.
const { setLastIntersecting } = useInfiniteScroll();
//...
{datas.map((data: Data) => {
const { id } = data;
return (
<p key={id} ref={setLastIntersecting}>
{id}
</p>
);
})}컴포넌트에서 ref로 setLastIntersecting를 주고, UI는 데이터 배열을 map을 돌려 출력한다. 이렇게 하면 첫 Get요청을 데이터를 반환 받으면, setLastIntersecting로 인해 lastIntersecting 가 null에서 해당 요소의 값을 얻는다. 이로 인해, 관찰 대상이 지정될 것이다. 여기서 스크롤을 끝까지 내려 바닥을 감지하면 어떻게 될까?
위에서 언급했다 싶이 page 가 증가하고, 새로운 Get요청을 해서 datas에 합쳐진다.(물론 이 과정은 위의 코드에서는 없다. useMoreData가 이 역할을 해준다고 생각하자.) 데이터가 증가했을 경우 UI에 변화가 생길 것이고, 그러면 setLastIntersecting으로 인해 lastIntersecting값이 다시 변경된다.
이렇게 다시 관찰하고 감지하고 데이터 요청하고 무한 반복이다. 무한 스크롤이다!!
Intersection Observer API에 대해 더 궁금하다면 내가 참고한 블로그를 보면 도움이 될 것이다.
무한 스크롤 고려해야할 부분
이제 무한 스크롤 구현하는 방법은 간단하는것을 느꼈다. 하지만 한 가지 더 고려해야할 부분이 있다. 한 500개를 무한 스크롤로 데이터를 가져와 UI에 출력했다고 가정하자. 점점 더 가져오면 가져올 수록 reflow로 인해 렌더링 속도는 느려지게 된다.
CSS 속성 (display: none)
유저가 보고 있는 UI외의 아이템들은 css의 display: none을 해주면 어떨까? React에서 보면, 이 속성은 우리 눈에만 안보이게 해주는 것이 아니라 실제로 렌더링되지 않는다.
조금 더 자세하게 들어가보면, React의 함수형 컴포넌트는 display속성이 무엇인지 상관 없이 React Element를 반환한다. 이 Element를 이용하여 브라우저는 DOM tree와 CSSOM tree를 생성하는데, 이 두개의 tree를 이용하여 Render tree를 생성할 때는 display:none인 Element는 제외가 된다. 즉, 렌더링 속도가 개선된다는 것이다.
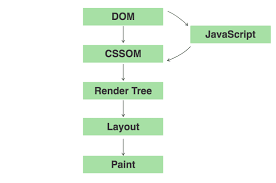
하지만 DOM tree에는 이 Element가 존재한다는 문제점이 있다. 데이터의 수가 많아질 경우 해당 문제점을 개선시키는 것이지 해결하지는 않는다.
그리고 display 속성이 block인 Element에 none을 부여하여 무한 스크롤의 문제점을 해결할텐데, 속성이 부여된 Element의 영역이 사라지면 그 밑에 있던 요소가 그 자리를 차지하게 된다. 이러면 또 reflow(layout이라고 부르기도 한다.)와 repaint를 발생시키는 것이다.
react-virtualized
Element를 DOM에서도 삭제할 수 있는 react-virtualized라는 라이브러리가 있다. 직접 구현할 수도 있지만 이 라이브러리를 사용해보는 것도 좋아 보인다. (여기서는 알아보지 않겠다.)


좋은 글 감사합니다~~ ㅎㅎ