데이터베이스관한 글을 쓰려 했을때, 바로 sql부터 포스팅할 예정이었다.
하지만, sql의 이론적 기초가되는 RDBMS나 관계대수의 개념 또한 매우 중요하다고 생각되어 RDBMS란 무엇인지, 그리고 관계대수는 무엇인지부터 정리하기로 했다.
RDBMS?
우선 DBMS는 Database Management System의 약자이다.
말그대로 데이터베이스를 관리해주는 시스템인데, Mysql, MongoDB, Redis등등 수많은 우리가 DB라고 부르는 친구들이다.
그럼 RDBMS는? 관계형 데이터베이스 시스템이다. 테이블이 서로 관계를 맺고 있기때문에 붙은 이름이고, RDBMS의 표준 질의어가 SQL이다.
SQL vs NoSQL
1. SQL
SQL과 NoSQL도 짚고 넘어갈 예정이다.
먼저 SQL은 구조적 쿼리언어로, 관계형 DBMS가 시장에서 압도적인 우위를 차지하게한 장본인으로, RDBMS에서 데이터를 추가하고 처리하며 상호작용하는 '언어'인 것이다.
그렇다면 '구조적'이라는건 뭘까? 우선 데이터베이스의 구조를 스키마라고한다.
대학생DB에 이름, 학번, 학과라는 애트리뷰트(속성)이 있으면 그것이 대학생DB의 스키마인것이다. 그리고,
SQL은 이 스키마의 구조를 엄격하게 지키며 데이터를 관리한다.
2. NoSQL
SQL과 반대이다. 스키마구조를 엄격하게 지키는 SQL과 달리 그 형태가 자유롭다.
애초에 빅데이터와 같은, 여러형태의 데이터를 저장해야하는 니즈에서 나왔기 때문이다.
따라서 데이터끼리 밀접한 관계를 맺지 않는다.
++
만약 프로젝트라던가 무언가를 시작할때, DB는 SQL로 하는걸 추천한다.
왜냐면 나중에 SQL에서 NoSQL로의 전환은 쉽지만, 반대는 그렇지 않기 때문이다.
RDBMS의 구조
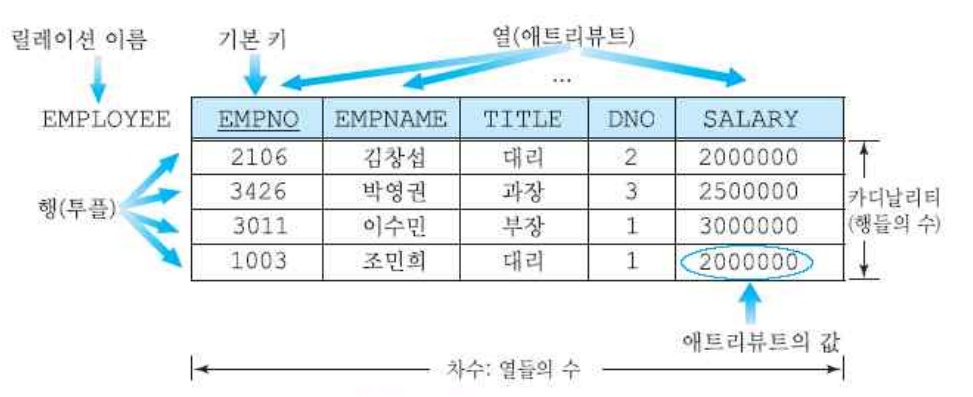
어렵지않다. 그냥 엑셀시트같이 생겼다. 앞으로 사용할 용어만 정리하겠다.
- 릴레이션 : 2차원 테이블구조의 sheet
- 레코드 : (혹은 튜플)릴레이션의 행
- 애트리뷰트 : 릴레이션의 열
- 도메인 : 애트리뷰트값의 집합. 프로그래밍할때 데이터 타입이라고 생각하자. 한 애트리뷰트는 모두 타입이 같아야하고, 원자값을 가진다.
ex) 위에서 EMPNAME 애트리뷰트는 모두 string이고 하나의 값이다. - 차수 : 애트리뷰트(열)의 수
- 카디날리트 : 튜플(행)의 수
key?
그렇다면 RDBMS, 즉 관계형 DBMS에서 데이터끼리 관계를 정의하는건 뭘까?
바로 키다. 키는 특정 튜플을 식별하는 하나 이상의 애트리뷰트 집합을 뜻한다.
키에도 여러 종류가 있다.
수퍼키
=> 한 릴레이션 내의 특정 튜플을 고유하게 식별하는 하나의 애트리뷰트 or 애트리뷰트의 집합
ex) 대학생 릴레이션에서 학번은 고유하므로 수퍼키가 될수있다.
또한 학번+이름, 학번+학과등 고유하지 않은 애트리뷰트를 포함할 수 있다.
후보키
=> 튜플을 고유하게 식별하는 최소한의 애트리뷰트들의 모임.
모든 릴레이션에는 한 개 이상의 후보키가 있고, 후보키가 두 개 이상의 애트리뷰트의 집합일때 복합키라고한다.
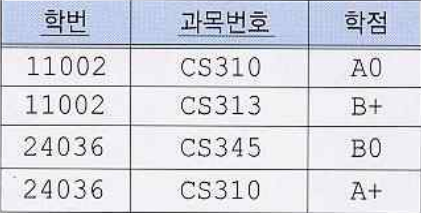 ex) 위 릴레이션에서 '학번+과목번호'는 후보키가 될 수 있다.
ex) 위 릴레이션에서 '학번+과목번호'는 후보키가 될 수 있다.
기본키(★★★)
=> 후보키가 여러개이면, 그 중 하나를 기본키로 고른다. 만약 서로 다른 릴레이션끼리 참조할때, 기본키를 바탕으로 참조한다.
(기본키가 되지못한 후보키를 대체키라고 한다.)
외래키(★★)
=>특정 릴레이션의 기본키를 참조하는 애트리뷰트이다. 이때 다른 릴레이션은 물론 자기 자신도 참조할 수 있다. 따라서, 외래키와 참조되는 릴레이션의 기본키는 같은 도메인을 가져야 한다.
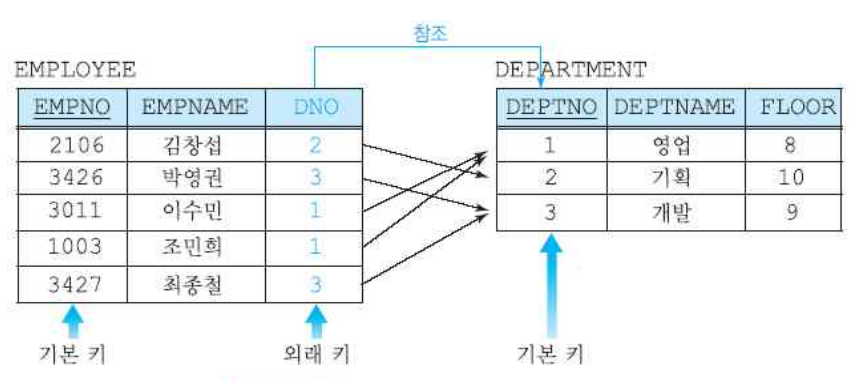 그림으로 보면 훨씬 이해가 쉽다.
그림으로 보면 훨씬 이해가 쉽다.
EMPLOYEE 릴레이션의 DNO 외래키로 DEPARTMENT 릴레이션의 DEPTNO 기본키를 참조한 모습이다. RDBMS는 이렇게 key를 통해 관계가 정의된다.
무결성 제약조건
관계형 데이터베이스에는 여러 제약 조건들이있고, 이 제약조건들을 통해 데이터베이스의 정확성과 안정성이 보장된다. 그리고 우리 똑똑한 DBMS는 데이터가 갱신될때 조건을 만족하는지 자동으로 검사해준다.
하지만, 본인도 제약 조건들을 알고있는것이 DB의 어디에 문제가 있는지 알기 수월할 것이다.
1. 도메인 제약조건
- 각 애트리뷰트의 값은 원자값이어야 함.(리스트와 같은형식 안됨)
- 애트리뷰트들의 디폴트값, 값의 범위를 제한할 수 있음.
- 데이터 타입을 제한하고, CHECK 제약조건을 통해 범위도 제한할 수 있음.
2. 키 제약조건
- 키 애트리뷰트에는 중복된 값이 존재해서는 안됨.
3. 기본키, 엔티티 무결성 제약조건
- 기본키를 구성하는 애트리뷰트는 null값을 가질 수 없음.
=>외래키로 기본키를 참조해야 하는데 기본키가 null이면 참조할 수 없다.
4. 외래키와 참조 무결성 제약조건
이 제약조건은 특정 릴레이션을 참조할때의 조건을 정의한다.
R1의 외래키가 R2의 기본키를 참조할 때, 아래 둘중 하나를 만족해야한다.
- 외래키의 값은 R1의 어떤 튜플의 기본키값과 같다.
- null값을 가진다. (단, 외래키인 동시에 본인 릴레이션의 기본키인 경우는 불가)
DBMS의 무결성 제약조건 유지방법
그렇다면 DBMS는 이 무결성 제약조건들을 어떻게 유지시켜줄까?
먼저 데이터 갱신은
1. 삽입
2. 삭제
3. 수정
연산으로 나눌 수 있다. 여기선 참조 무결성 제약조건 유지법만 살펴볼 것이다.
(다른 제약조건들은 값 자체의 문제이기 때문이다.)
우선 삽입의 경우를 먼저 생각해보자. 문제되는 경우는 참조하는 릴레이션으로의 데이터 삽입이다. 참조되는 릴레이션의 기본키를 참조할 수 없을수 있기 때문이다.
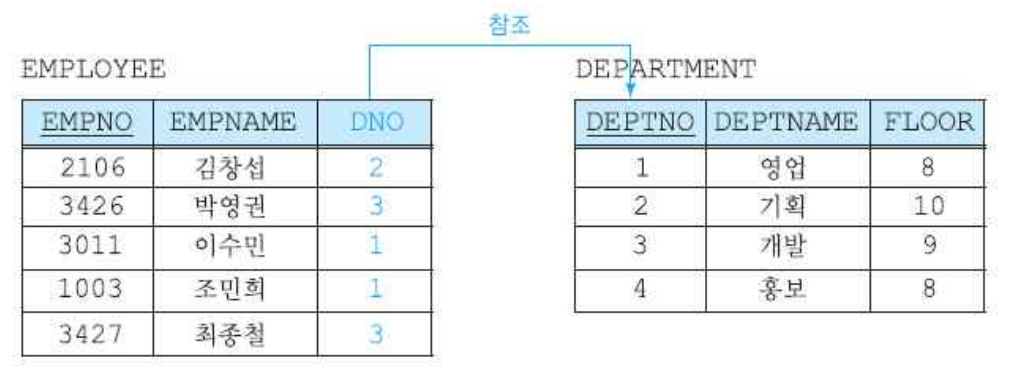 ex) EMPLOYEE 릴레이션에 (4265,제임스,6) 레코드를 삽입하면 참조 할 수 없음.
ex) EMPLOYEE 릴레이션에 (4265,제임스,6) 레코드를 삽입하면 참조 할 수 없음.
다음은 삭제의 경우를 보자. 삭제의 경우는 반대로, 참조하는 릴레이션의 튜플의 삭제는 문제가 되지 않지만 참조되는 튜플의 삭제가 문제가 될 수 있다. 마찬가지로 참조할 수 없는 경우가 생기기 때문이다.
이제 이런상황에서 DBMS가 어떻게 작동하는지 보자.
- 제한(Restricted) : 말그대로 삽입/삭제를 거부한다.
- 연쇄(Cascade) : 참조할 수 없게된 튜플을 같이 삭제해버린다.
ex) 위 그림에서 (2,기획,10)을 삭제하면 왼쪽의 김창섭씨도 삭제해버림 - 널값(nullify) : 참조되는 튜플을 삭제할 때, 참조하는 튜플의 외래키 값을 null로 변경
- 기본값(Default) : nullify와 동일한 매커니즘으로, null대신 default값으로 변경
