
저번에 관계대수를 포스팅했었는데, SQL은 관계대수를 선언적으로 사용하면 된다
예를들어 π[dno,empname](σ dno=3)(employees)를 SQL로 표현하면
SELECT dno, empname
FROM employees
WEHRE dno=3;
이다. 마지막으로 집단 함수와 GROUP BY, 정렬까지 알아보고 SQL을 연습해보자.
집단함수
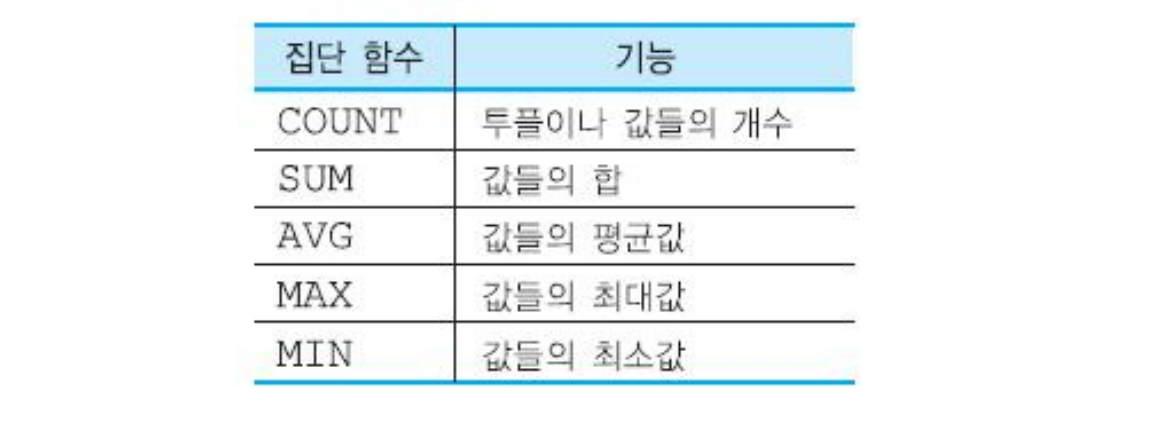 위와 같은 집단함수들이 있고, 아래와 같이 사용한다. (as A=> 출력을 A로 하겠다.)
위와 같은 집단함수들이 있고, 아래와 같이 사용한다. (as A=> 출력을 A로 하겠다.)
SELECT avg(salary) as AVGSAL, max(salary) as MAXSAL
FROM employees;
Result

※ 주의
- SELECT, HAVING절에만 나타날 수 있음.
- 집단함수앞에 DISTINCT 키워드를 사용하면 중복을 제거 후 집단함수 적용.
- count(*)을 제외하고는 null값을 제외 후 계산.
(count(*)는 결과 릴레이션에 모든 행의 갯수 출력)
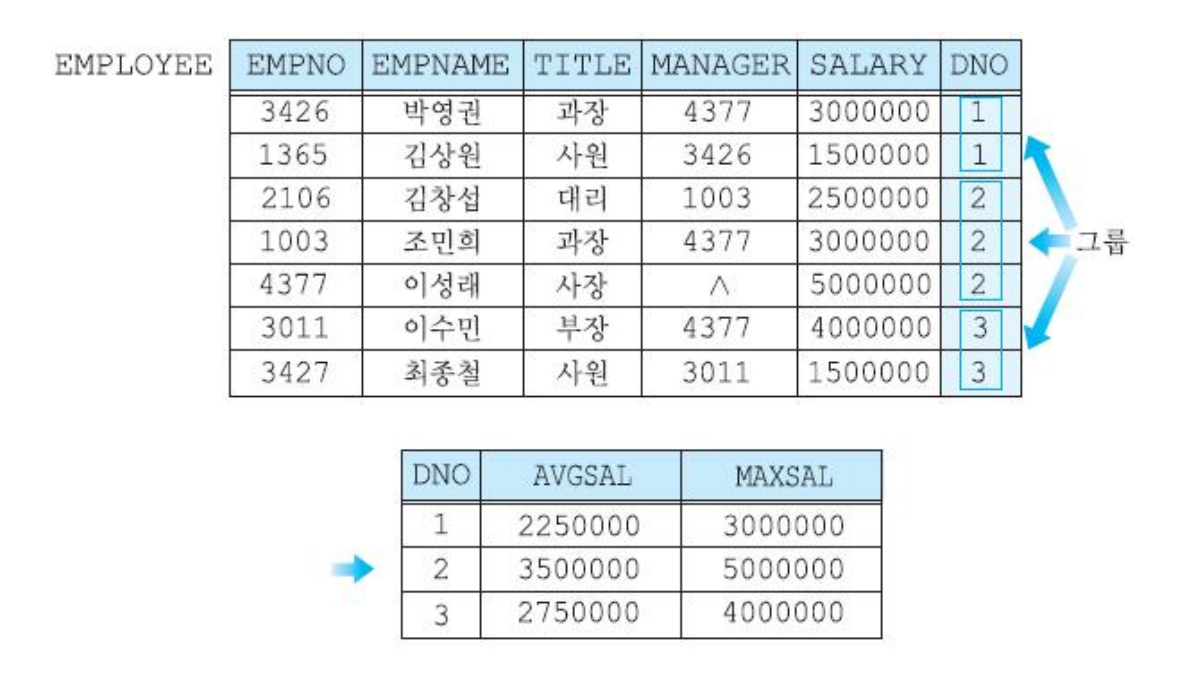
GROUP BY
역시 직접 해보는게 이해가 가장 빠르다. 그룹화는 아래와같이 사용한다.
SELECT dno, avg(salary) as AVGSAL, max(salary) as maxsal
FROM employee
GROUP BY dno;
HAVING
그룹핑을 한 후, 특정 조건을 만족하는 그룹에만 집단함수를 적용할 수 있고,
그 조건을 HAVING절에 명시한다.
위 예제에 HAVING조건을 추가해보면,
SELECT dno, avg(salary) as AVGSAL, max(salary) as maxsal
FROM employee
GROUP BY dno
HAVING avg(salary) >= 2500000;
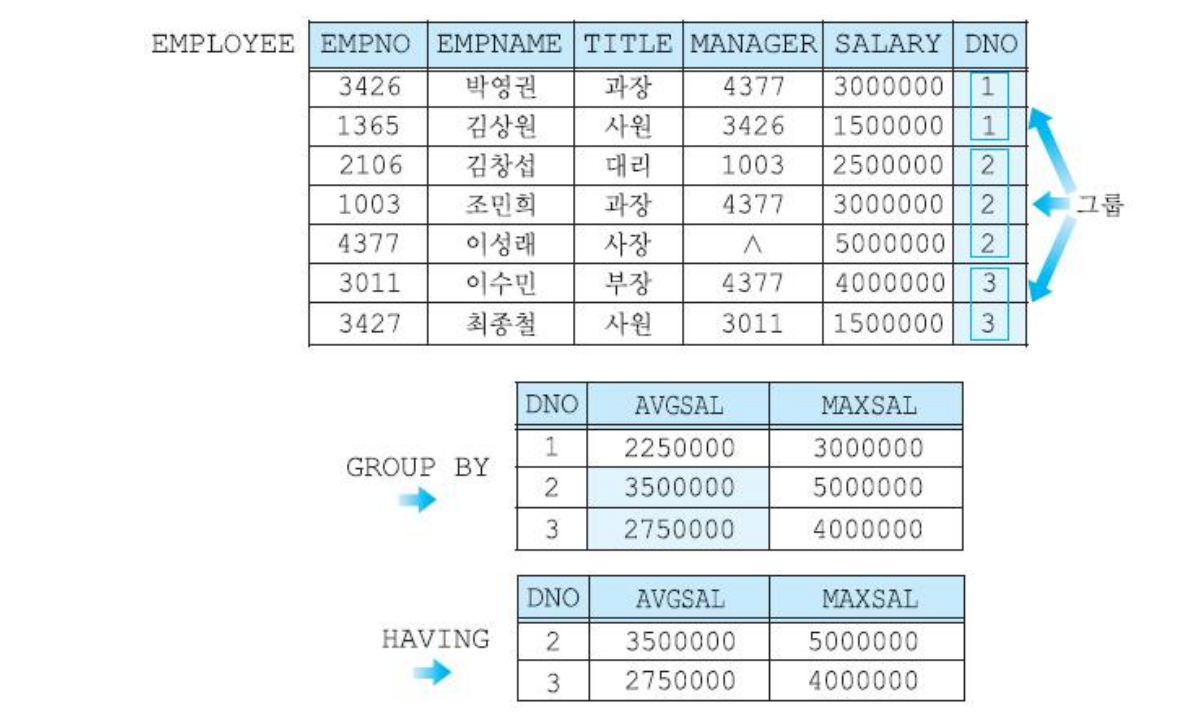 이렇게 평균 월급이 250만원 이상인 조건을 만족하는 그룹만 출력된다.
이렇게 평균 월급이 250만원 이상인 조건을 만족하는 그룹만 출력된다.
※ 주의
- HAVING절에 나타나는 애트리뷰트는 반드시 GROUP BY절에 나타나거나
집단 함수에 포함되어야 함
ORDER BY
결과 릴레이션을 ORDER BY의 조건에 따라 오름차순, 또는 내림차순으로 정렬한다.
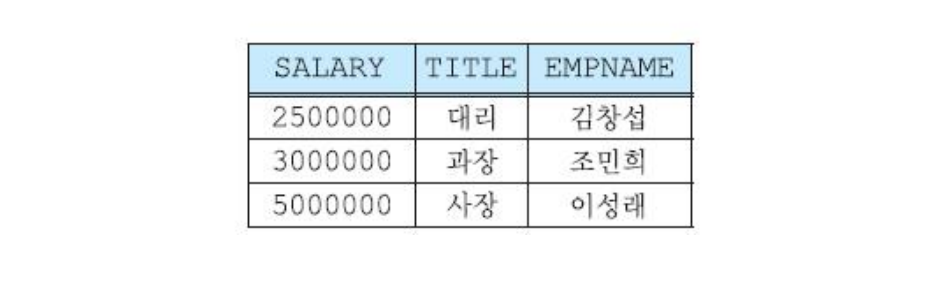
SELECT salary, title, empname
FROM employee
WHERE dno=2
ORDER BY salary asc; // salary를 기준으로 오름차순 정렬. (내림차순 => desc)
※ 주의
-
SELECT문 가장 마지막에 사용
-
디폴트 값은 ASC
-
널값은 오름차순에서는 가장 마지막에 나타나고, 내림차순에서는 가장 앞에 나타남
-
SELECT절에 명시한 애트리뷰트들을 사용해서 정렬해야 했으나,
최근 SQL에서는 SELECT 절에 나오지 않은 애트리뷰트도 허용함
