
이번에는 processor가 어떻게 병렬처리를 하는지 알아볼 것이다.
병렬처리란 프로그램을 프로세서들에게 분산시켜, 여러 작업을 동시에 수행하여 효율을 높이는 것이다. 병렬처리하는 방식을 Pipelining이라고 한다.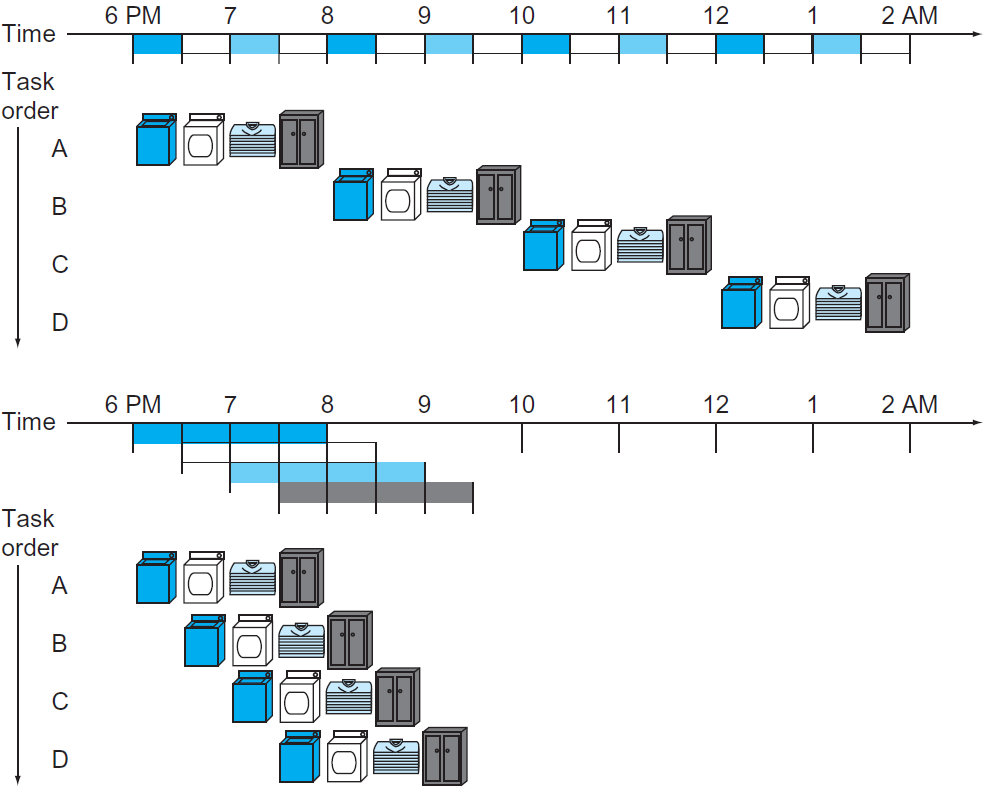
세탁 과정을 예로 들어보자. 아래 그림처럼, 세탁기가 할 일이 끝나면 건조기나 옷 개는 것을 기다리지 않고 바로 다음 옷을 세탁하는 것이 훨씬 효율적일 것이다.
Pipelining
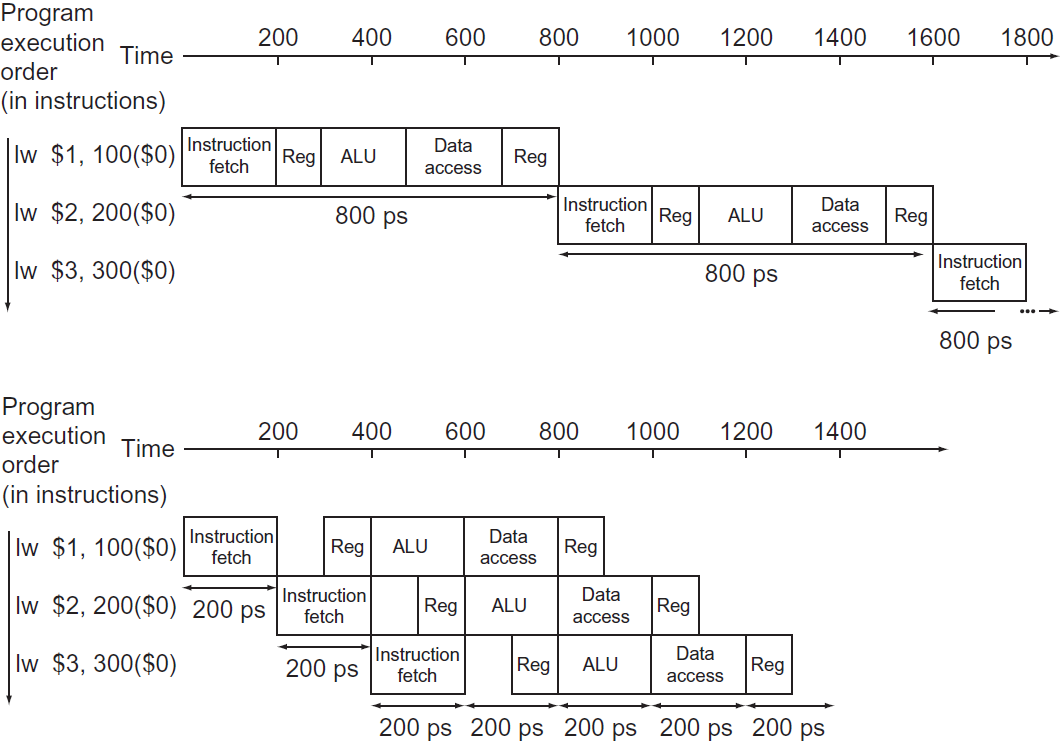
위 그림의 세탁과정이 총 4단계라고하면, MIPS에서 instruction을 수행하는 과정은 5단계로 나뉜다. 하나씩 알아보자.
- IF : memory로부터 instruction을 fetch하는 작업
- ID : instruction을 decoding하는동안 레지스터들을 읽는 작업
- EX : operation 수행/address 계산
- MEM : data memory의 opreand에 접근
- WB : 레지스터에 결과 입력
이 과정들을 병렬적으로 수행함으로써 프로그램의 속도를 향상 시킨다.
자 이제, 이전에 배웠던 datapath control과 pipelining을 한 그림에서 생각해보자!
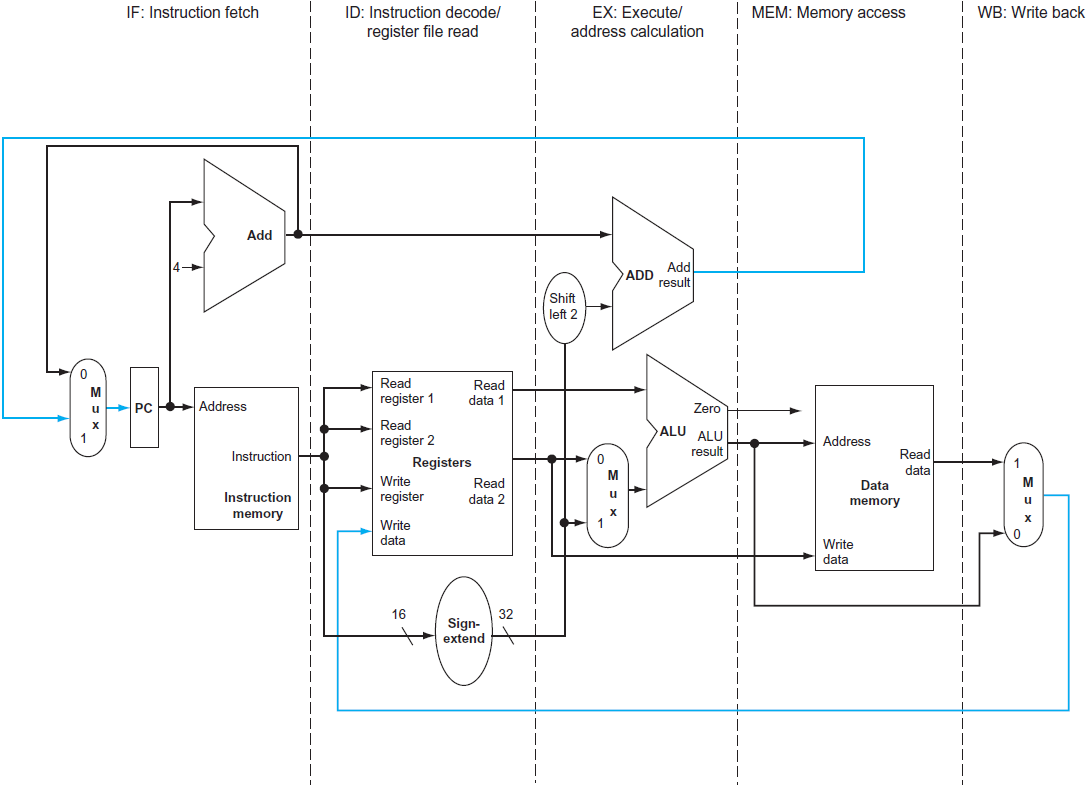
단순히 datapath control부분을 IF, ID, EX, MEM, WB부분으로 나눈 것이다. 이제 과정들을 두개씩 묶어, pipline을 세워보도록 하자.

Hazard
이제 왜 Pipelining을 하는지는 알겠다. 그런데 눈치챘을 수 있지만, 이렇게 되면 문제가 발생할 수 있다. 예를 들어
add $s0, $t0, #t1
sub $t2, $s0, $t3
라는 프로그램이 있다고 하자. Pipelining을 하게 되면, $s0의 값이 add연산이 끝나지 않은 채로 sub연산에 들어가 버릴것이다. 그렇다면 결과값이 예상한 값과 다르게 나올것이다! 이렇게 Pipelining의 성능을 하락시키는 상황을 Hazard라고 한다. Hazard에는 크게 3가지가 있다.
1. Pipeline(Structural) Hazard
pipelining의 구조적 hazard. 제한된 Hardware에 여러 resource들이 충돌할 때 발생한다.
※ solution : 단순히 hardware을 더 확보 하거나, stall, bubble(지연)을 통해 사용할 수 있을 때까지 기다린다.
하지만!! stall이나 bubble은 말 그대로 한 cycle을 쉬는 것이기 때문에 성능을 저하시킨다.
2. Data Hazard
- 위 add sub 예시와 같이, instruction이 이전의 연산에 dependency가 있는 상황.
※ solution : forwarding(bypassing)
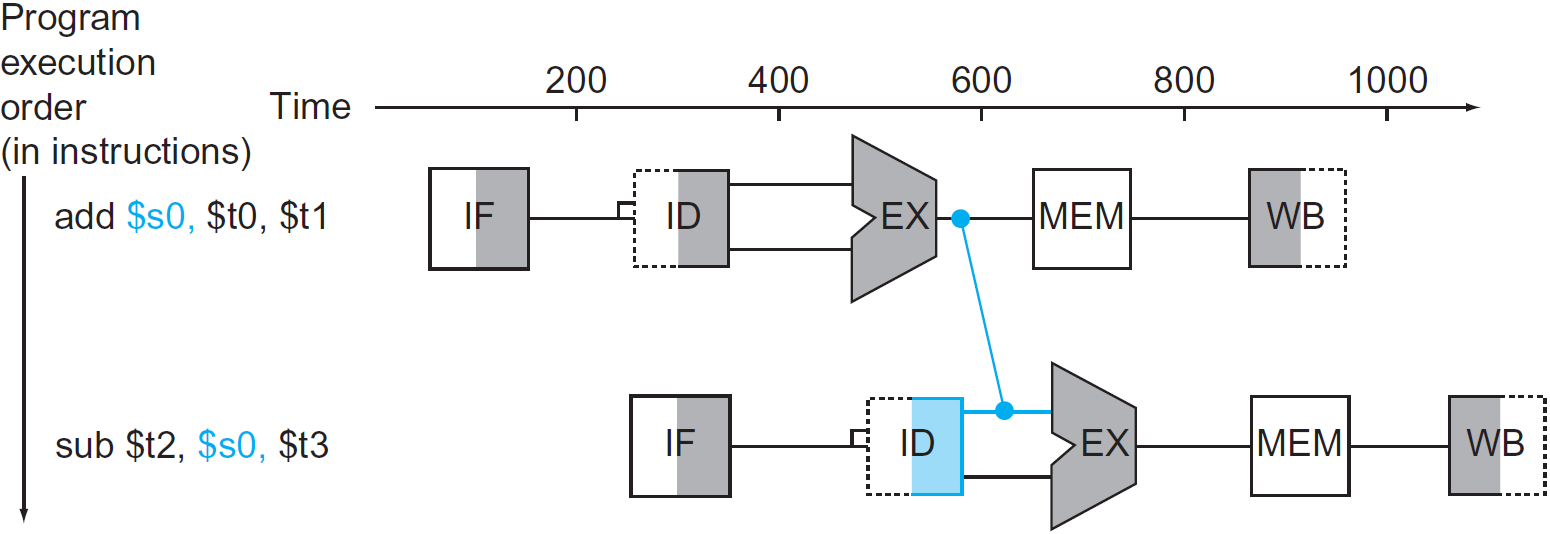
미리 값을 넘기는 것이다. 그림처럼 EX연산이 끝난 값을 바로 ID/EX로 넘겨 주면서, stall을 사용하지 않고 해결 할 수 있다.
그리고 아래 그림과 같이 연산에 필요한 register에 data가 아직 load 되지 않은 상황을 Load-use data hazard라고 한다.
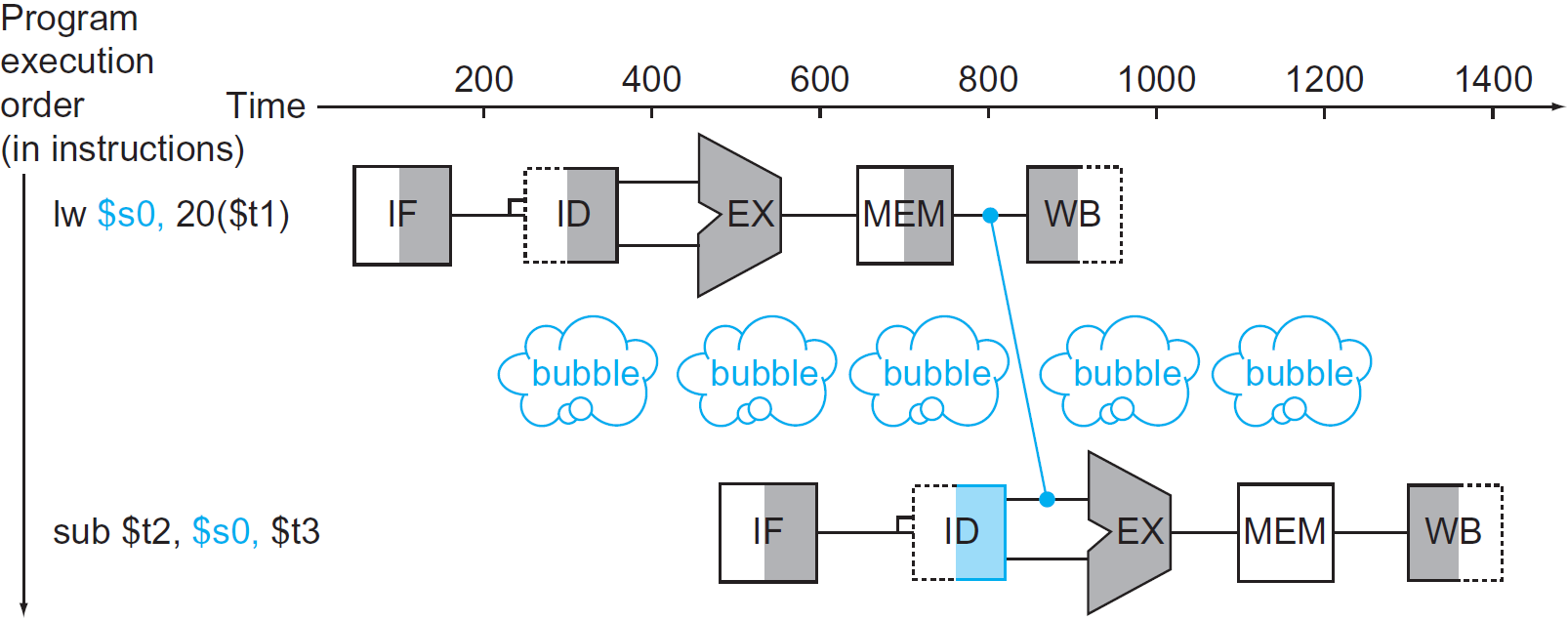
※ solution : 그림처럼 한 cycle에 bubble을 넣어줌으로써 해결 할 수 있다.
forwarding??
forwarding은 좀더 깊게 알아볼 필요가 있다.
먼저, Data hazard는 EX부분에서 발생할 수도, MEM부분에서 발생할 수도 있는데, 이를 각각 EX hazard, MEM hazard라고 한다. 발생 조건은 다음과 같다.
 복잡해 보이지만 그렇지 않다!
복잡해 보이지만 그렇지 않다!
처음 예시로 보여준 hazard(add후 sub)의 예시가 바로 1a에 해당한다.
(EX/MEM.RegisterRd = ID/EX.RegisterRs = $s0)
나머지도 같은 원리로, 앞서 수행한 instruction의 rd와 다음 명령어의 rs, rt 레지스터와 겹치는 상황이다.
이제 forwarding 신호를 어떻게 보내는지 알아보자.
- forwarding이 필요 없을 경우 00을 보낸다.
- EX/MEM부분에서 forwarding이 필요하면 10을, MEM/WB에서 forwarding이 필요하면 01을 보낸다.
- rd와 rs가 겹치느냐, rt가 겹치느냐에 따라 forwardA 와 forwarB로 나눈다.
아래는 이를 정리해 놓은 표이다.

이제 이 forwarding상황들을, 조건문을 통해 표현해보자.

EX/MEM.RegWrite상황이고,
EX/MEM.RegisterRd가 0이 아니며,
그 값이 ID/EX.RegisterRs와 같으면=>forwardA=10
그 값이 ID/EX.RegisterRt와 같으면=> forwardB=10

MEM/WB.RegWrite상황이고,
MEM/WB.RegisterRd가 0이 아니며,
그 값이 ID/EX.RegisterRs와 같으면=>forwardA=01
그 값이 ID/EX.RegisterRt와 같으면=> forwardB=01
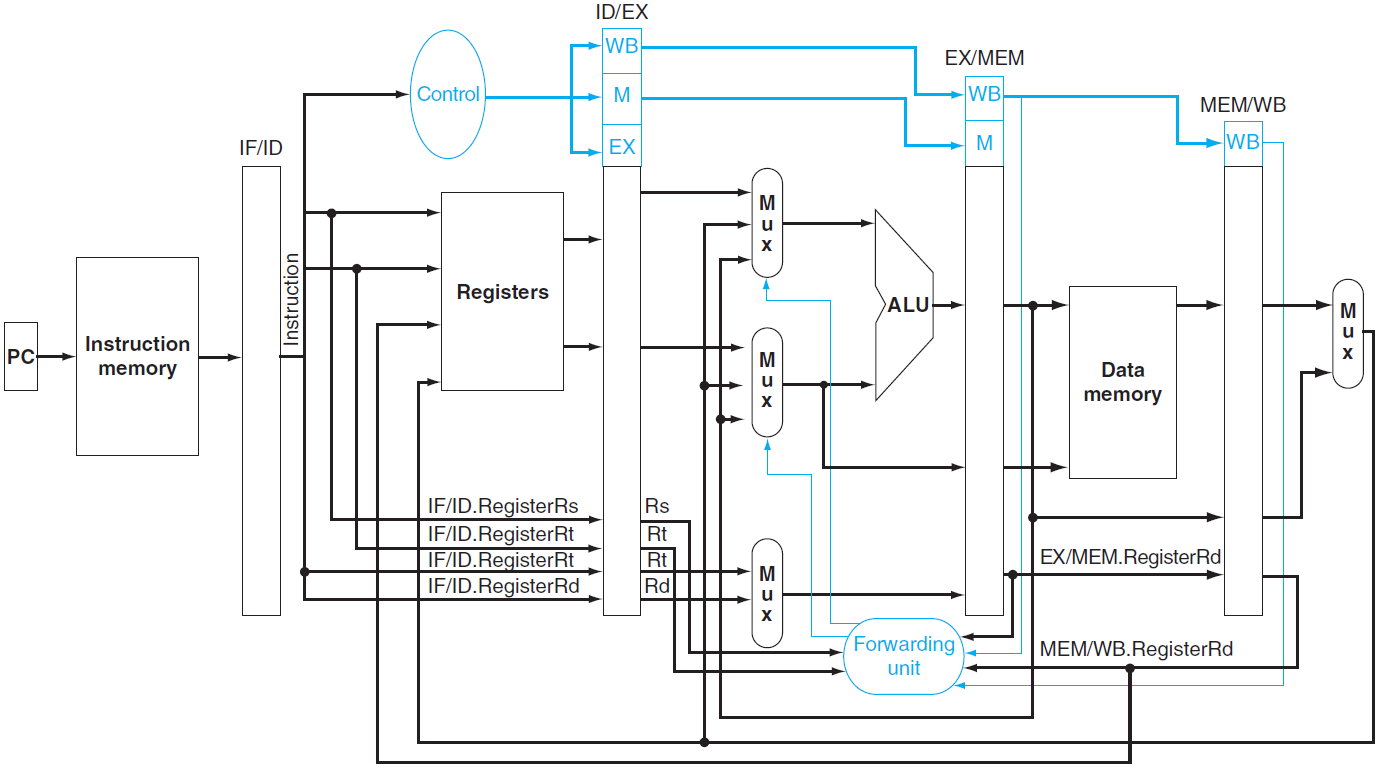
마지막으로 그림으로 살펴보자. forwarding의 판단을 위해
Forwarding unit으로 Rs, Rt, EX/MEM.RegisterRd, MEM/WB.RegisterRd 값이 들어가는걸 볼 수 있다.
Load-use data hazard의 조건은 다음과 같다.
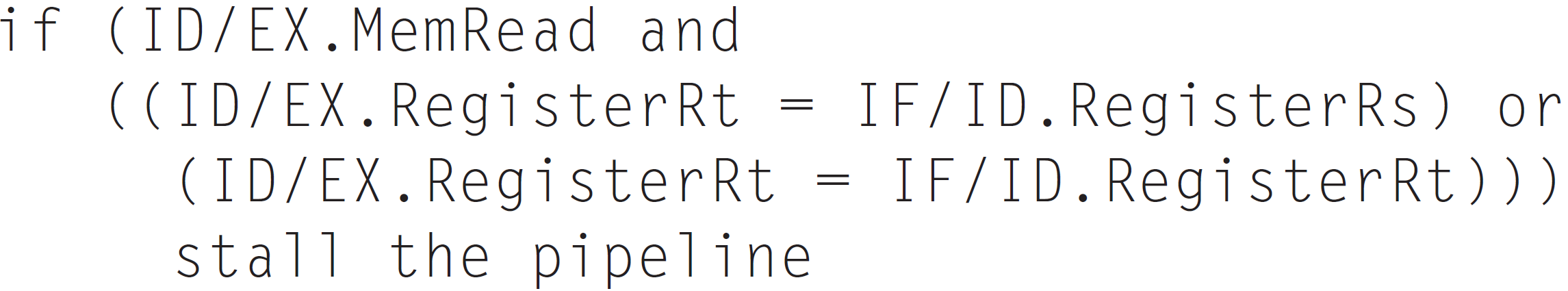
ID/EX.MemRead 상황이고, ID/EX.RegisterRt가 IF/ID.Register의 rs나 rt와 같다면?
Stall the pipeline(지연) 해라!
※stall은 nop(no-operation)을 삽입함으로써 수행된다.
3. Control Hazard
- branch instruction이 있을 경우 발생. 예를 들어 beq 명령어 뒤에 add, sub와 같은 instruction들을 병렬처리로 마구마구 수행하고 있는데, beq 조건을 만족해서 다른 address로 가버린다면...?
손해도 이런 손해가 없다!
프로그램에 수많은 분기문이 있을텐데, 필요없는 연산을 너무 하게된다.
※ solution : 첫번째로는 안전하게 branch 연산이 끝날때까지 stall을 해주는 것이지만... 말했듯이 수많은 분기문이있을텐데, 그때마다 stall을 해주는건 너무 손해이다.
그래서 두번째 solution으로 prediction이있다. 분기문의 결과를 예측하고, 그 예측이 틀렸을 때만 stall을 해주면 훨씬 효율적일 것!
prediction
prediction에 대해 알아보자. 먼저 Branch prediction Buffer라는걸 두어서, 그 table에 taken/not taken의 값을 저장해 놓는다. 그리고 이를 바탕으로 예측하는 것이다. 예측이 틀리면? 예측결과를 바꿀것이다.
predictor엔 1-bit predictor, 2-bits predictor가 있다.
1bit predictor는 예측이 틀리면 즉시 예측값을 바꾸기 때문에 성능이 좋지않다. 그래서 등장한 것이 2bits predictor이다.
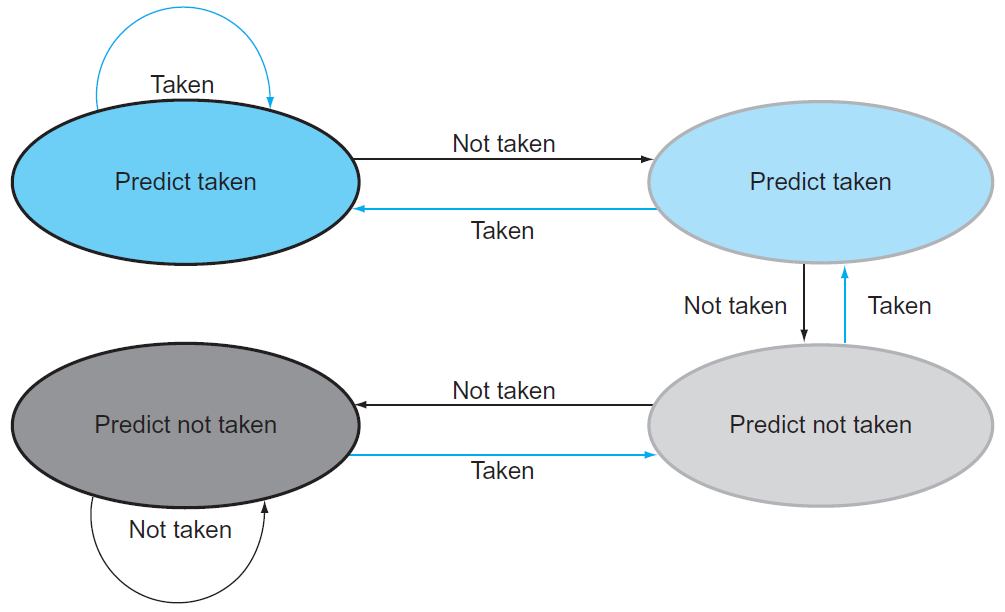
↑2-bits predictor의 의사결정도
2-bits predictor는 예측이 두번 빗나가야, 그 state를 바꾼다.
