
✅ 핵심내용
- Scikit-learn Toy Dataset 분류
- 여러가지 분류 모델
- 모델의 성능을 평가하는 지표의 종류

Scikit-learn 라이브러리에서는 Toy Datasts(연습용 데이터셋) 와 Real World Datasets(실제 데이터셋) 을 제공한다.
Toy datasets 를 분류하는 모델을 만들어보자.
⭐ 다양한 분류 모델
Toy datasets 을 분류할때 다양한 분류 모델을 사용할 수 있다. 각 분류 모델에 대한 기본적인 개념에 대해 알아보고 datasets 들 마다 어떤 모델이 가장 적합한지 알아보자.
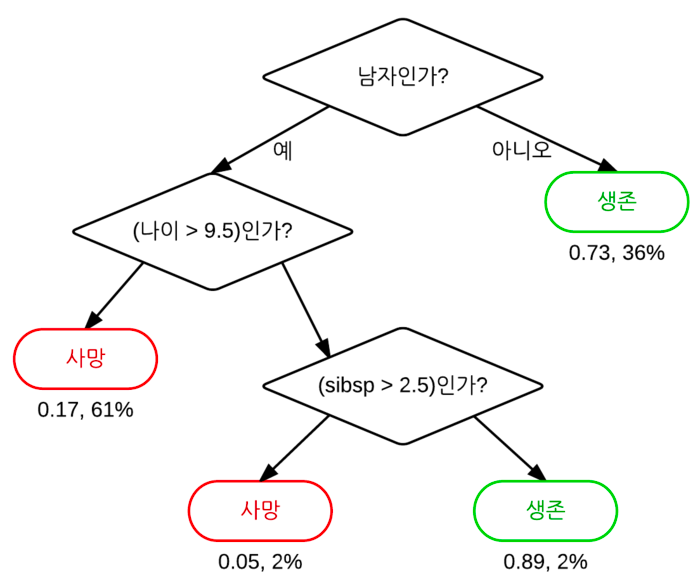
결정 트리 Decision Tree
결정 트리 (Decision Tree, 의사결정트리, 의사결정나무) 는 분류(Classification)와 회귀(Regression) 모두 가능한 지도 학습 모델 중 하나이다.
특정 기준(질문)에 따라 데이터를 구분하는 모델이다.
Random Forest
결정 트리(Decision Tree)는 훈련 데이터에 overfitting 되는 단점이 있다. 이러한 단점을 해결하기 위해 여러 개의 결정 트리를 통해 숲 (Random Forest)를 만든다.
즉, Random Forest 는 훈련을 통해 구성해놓은 많은 Decision Tree 로 부터 결과를 취합해서 얻은 결론이다. 물론 몇몇의 Decision Tree들이 overfitting을 보일 순 있지만 다수의 Decision Tree를 기반으로 예측하기 때문에 그 영향력이 줄어들게 된어 좋은 일반화 성능을 보인다.
이렇게 좋은 성능을 얻기 위해 다수의 학습 알고리즘을 사용하는 걸 앙상블(ensemble) 학습법 이라고 부른다.
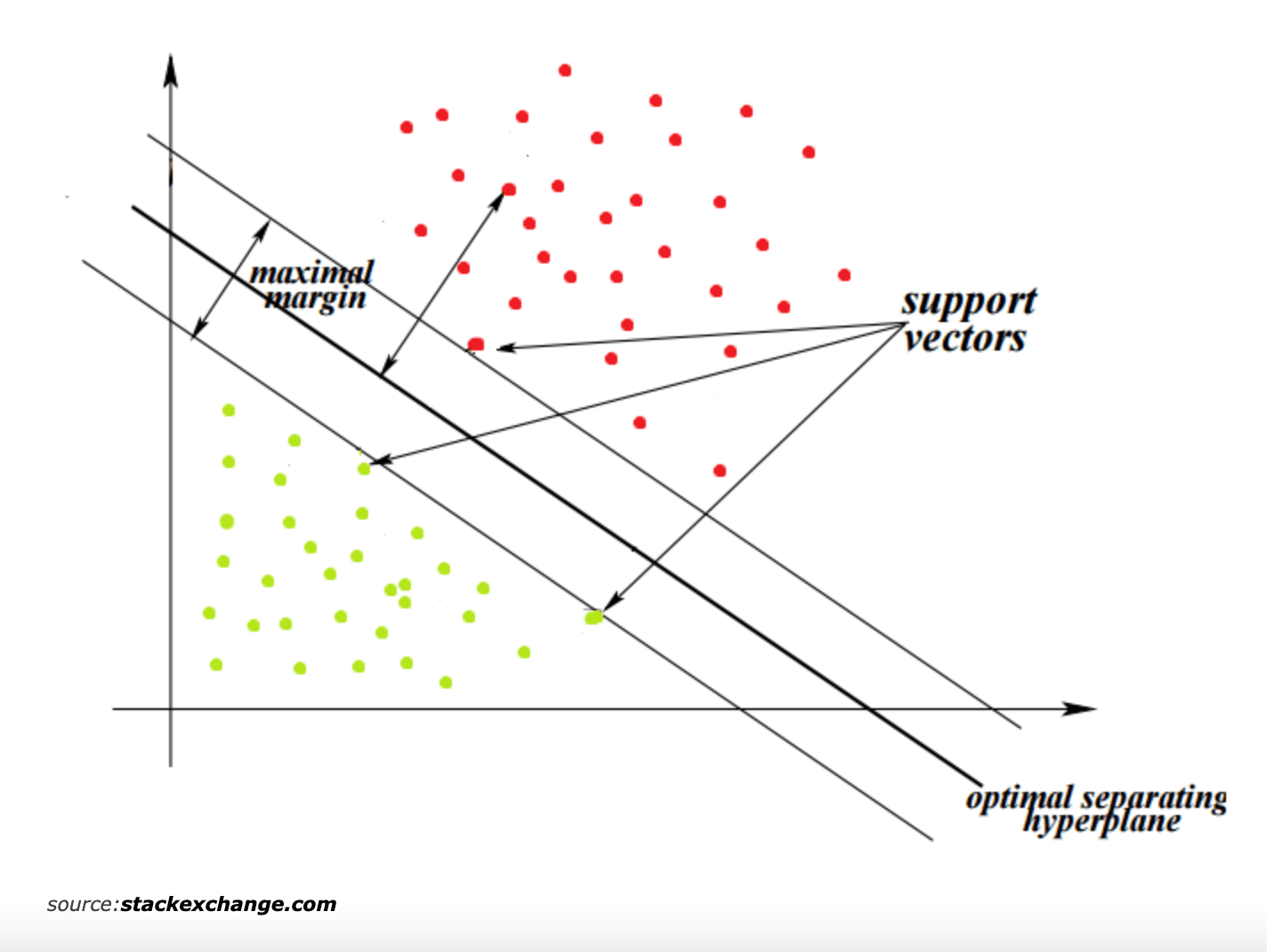
SVM (Support Vector Machine)
서포트 벡터 머신(SVM: Support Vector Machine)은 분류 과제에 사용할 수 있는 강력한 머신러닝 지도학습 모델이다.
SVM 은 결정 경계(Decision Boundary), 즉 분류를 위한 기준 선을 정의하는 모델 이다. 그래서 분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행할 수 있게 된다.
SGDClassifier
SGDClassifier 는 "확률적 경사 하강법" 으로 큰 데이터셋을 가지고 있을 때 장점을 가지고 있다. 훈련 데이터를 하나씩 독립적으로 처리하기 때문이다.
scikit-learn 의 perceptron(), LogisticRegression(), SVM() 대신 SGDClassifier() 의 loss 파라미터값을 달리해서 확률적 경사하강법 알고리즘을 적용한 것으로 대체 할 수 있다.
model = SGDClssifier(loss='perceptron') # 확률적 경사하강법 적용 퍼셉트론
model = SGDClssifier(loss='log') # 확률적 경사하강법 적용 로지스틱회귀
model = SGDClssifier(loss='hinge') # 확률적 경사하강법 적용 SVM4⭐ 모델 성능을 평가하는 다양한 지표
얼마나 많은 양성 데이터를 맞았느냐도 중요하겠지만, 음성 데이터를 얼마나 안 틀렸느냐도 중요한 경우가 있다. 이러한 경우를 위해 다양한 지표들로 모델의 성능을 평가 할 수 있다.
정답과 오답을 구분하여 표현하는 방법을 오차행렬(confusion matrix) 이라고 한다.
오차행렬에서 나타나는 성능 지표는 Precision, Negative Predictive Value, Sensitivity, Specificity, Accuracy 로 다섯 가지가 있다.
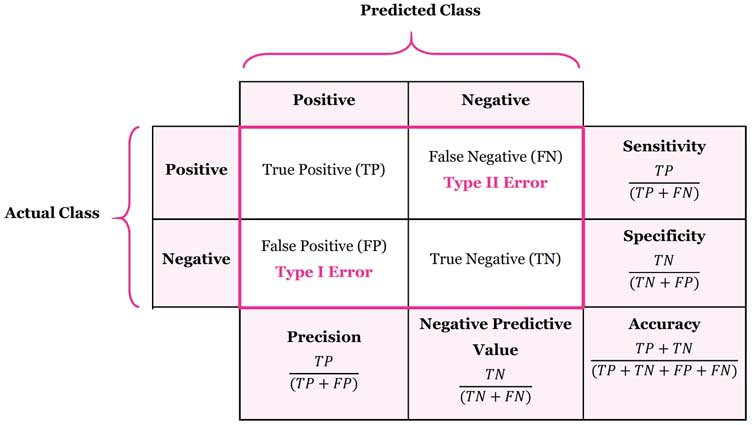
이러한 TP, FN, FP, TN의 수치로 계산되는 성능 지표 중 대표적으로 쓰이는 것은 다음과 같다.
- 정밀도(Precision) : 분모에 있는 가 낮을수록 커짐
- 재현율(Recall, Sensitivity) : 분모에 있는 이 낮을수록 커짐
- F1 스코어(f1 score) : Recall과 Precision의 조화평균
- 정확도(Accuracy) : 전체 데이터 중 올바르게 판단한 데이터 개수의 비율
이제 위의 scikit-learn 을 통해 다양한 모델로 데이터를 학습시키고 여러 지표들로 모델의 성능을 평가해보자.
💐 붓꽃 데이터 분류 (Iris Classification)
Toy datasets 중 한가지인 Iris dataset 를 이용하여 프랑스의 국화인 Iris(붓꽃)을 분류해보자.
iris dataset 의 sepal(꽃받침)과 petal(꽃잎)의 길이와 폭을 가지고 세 개의 품종(setosa, versicolor, virginica) 으로 다양한 모델을 통해 분류했다.

전체적인 과정은 다음의 순서로 진행되었다.
- 1. 데이터 정보 확인
- 데이터셋을 본격적으로 다루기 전에 먼저 데이터셋에 대한 기본적인 정보를 확인한다.
- 2. 데이터 불러오기
sklearn.datasets.load_iris()를 통해 데이터를 불러올 수 있다.- 불러온 iris 객체는 다음과 같은 다양한 메소드를 가지고 있다.
data: 데이터셋의 속성 데이터
target: 데이터셋의 타겟 데이터
DESCR: 데이터셋에 대한 설명
target_names: 라벨 이름
feature_names: 각 feature 이름
filename: 데이터셋 파일이 저장된 경로
- 3. 데이터 다루기(training set, test set 나누기)
- iris 데이터를 DataFrame 자료형으로 변환
sklearn.model_selection.train_test_split을 통해 training set, test set 으로 나눔
- 4. 다양한 모델을 사용해 학습
- Decision Tree, Random Forest, SVM, SGDClassifier 을 사용하여 각각 모델을 학습
- 5. 다양한 지표로 모델 성능 평가
- precision, recall, f1-score, accuracy 등 다양한 지표로 각각의 모델의 성능을 평가
위 과정에 대한 자세한 과정은 아래의 GitHub 링크를 참조하기 바란다.
GitHub Link -> EP02_Iris_Classification
Toy Dataset 분류
이번에는 Toy datasets 중 다음의 세가지 데이터 셋을 이용하여 여러 분류모델을 사용 해보고, 해당 데이터 마다 어떤 분류모델이 가장 높은 성능 을 보이는지 확인해보겠다.
- Optical recognition of handwritten digits dataset : 손글씨 이미지 데이터
- Wine recognition dataset: 와인 데이터
- Breast cancer wisconsin (diagnostic) dataset : 유방암 데이터
위와 같은 과정으로 진행되었고, 자세한 내용은 아래의 GitHub 링크를 참조하기 바란다.
GitHub Link -> EP02_Toy_Dataset_Classification
🎬 프로젝트 정리
여러 데이터들을 관찰하고 다루면서 해당 데이터에 맞는 분류 모델을 알아보았다. 데이터 마다, 모델 마다 약간의 성능 차이가 있었고 전체적으로는 Random Forest 모델의 성능이 높은 것을 확인했다.
하지만 Random Forest 의 느린 속도와 많은 메모리 차지와 같은 단점이 존재해 상황에 맞는 모델을 고르는 것이 중요하다.
또한 데이터의 종류나 성질에 따라 여러가지 모델들로 학습시켜보고 최적의 모델을 선택하는 것이 중요하다.
마지막으로 모델의 성능을 평가 할때에도 해당 데이터의 이해도를 바탕으로 최적의 척도로 모델 성능을 평가해야한다.
