✅ 핵심 내용
- list 와 array에 대한 이해
- Numpy, Pandas

List 와 Array
List 는 파이썬에서 별도의 import 없이 사용 가능한 임의의 데이터 타입을 담을 수 있는 가변적 시퀀스(sequence)형이다. 또한 리스트안의 요소 사이에 다른 타입의 자료형이 허용된다.
반면, Array 를 사용하기 위해서는 import 를 해주어야한다. 또한 처음부터 요소의 유형을 지정해서 생성하며, 지정되지 않은 다른 타입의 요소 추가가 허용되지 않는다.
Numpy
Numpy 는 numerical python 의 줄임말으로 과학계산용 고성능 컴퓨팅과 데이터 분석에 필요한 파이썬 패지키이다.
Numpy는 빠르고 메모리를 효율적으로 사용하여 벡터의 산술연신과 브로드캐스팅 연산 을 지원하는 다차원 배열 ndarray 데이터 타입을 지원한다. 또한 다양한 표준 수학 함수를 제공하여 전체 데이터에 대한 빠른 연산을 가능하다.
브로드캐스트(broadcast) 연산
ndarray 와 상수, 또는 서로 크기가 다른 ndarray 간의 산술연산을 브로드캐스트 연산이라고 한다.

ndarray 객체는 arange() 또는 array([}) 를 통해 만들 수 있다.
import numpy as np
array1 = np.arange(5)
array2 = np.array([5,6,7,8,9]) # 파이썬 리스트를 numpy ndarray로 변환
print(array1) # [0 1 2 3 4]
print(array2) # [5 6 7 8 9]
print(type(array1)) # <class 'numpy.ndarray'>
print(type(array2)) # <class 'numpy.ndarray'>ndarray 객체에 size, shape, ndim 을 통해 행렬 내 원소의 갯수, 행렬의 모양, 행렬의 축(axis) 를 알 수 있다.
Numpy 에서도 random 패키지의 다양한 기능을 지원한다.
- np.random.randint() : 실수형의 난수 생성
- np.random.choice() : 리스트 내의 요소 중에서 하나를 랜덤하게 뽑음
- np.random.permutation() : 정수 혹은 리스트를 받은 후, 원소 순서를 임의로 바꿈
- np.random.normal() : 정규분표(0~9) 중 임의의 표본 추출
- np.random.uniform() : 균등분포(-1~1) 중 임의의 표본 추출
또한 .T 또는 np.transpose 를 이용해 전치행렬을 만들 수 있다.
또한 Numpy 에서는 다양한 표준 수학 함수를 제공한다.
sum(): 총 합mean(): 평균std(): 표준편차median(): 중앙값
이미지를 행렬 데이터로 변환
이렇게 배열 형태의 데이터를 numpy 를 통해 편리하고 다양하게 활용 할 수 있다. 따라서 다양한 종류의 데이터를 행렬 형태로 변환하여 표현한다.
소리 데이터는 1차원 array 로 표현 가능하고, 흑백이미지는 각 픽셀별로 명도를 0-255의 숫자로 환산하여 2차원 array 로 표현 가능하다.
색상이 있는 이미지의 경우는 각 픽셀별로 RGB 값을 통해 3차원의 array 로 표현가능하다.
이미지 데이터를 처리하기 위해서는 matplotlib, PIL 라이브러리를 사용한다. open, size, filename, crop, resize, save 등 의 다양한 메소드를 사용 할 수 있다.
이미지를 행렬 데이터로 변환하는 간단한 예시로 해운대를 찍은 한 사진을 행렬 데이터로 변환해보자.
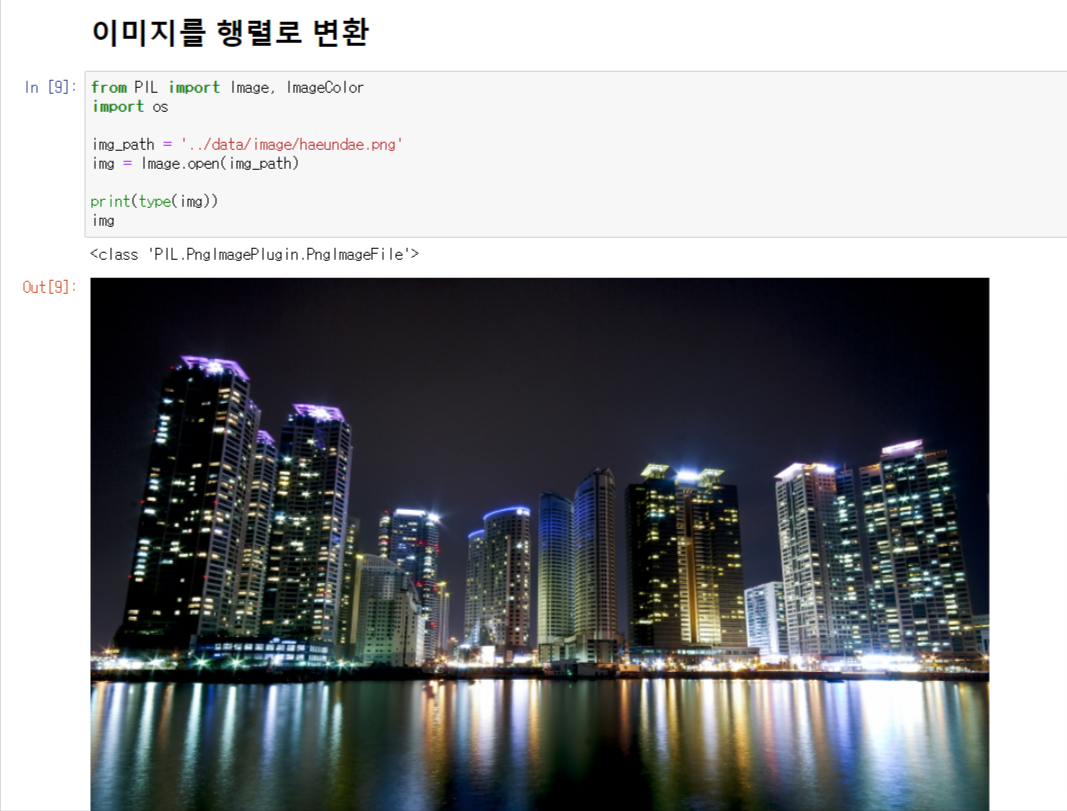
PIL 라이브러리로 불러온 이미지는 <class 'PIL.PngImagePlugin.PngImageFile'> 라는 타입을 가지고있어 이미지를 numpy array 로 변환이 가능하다.
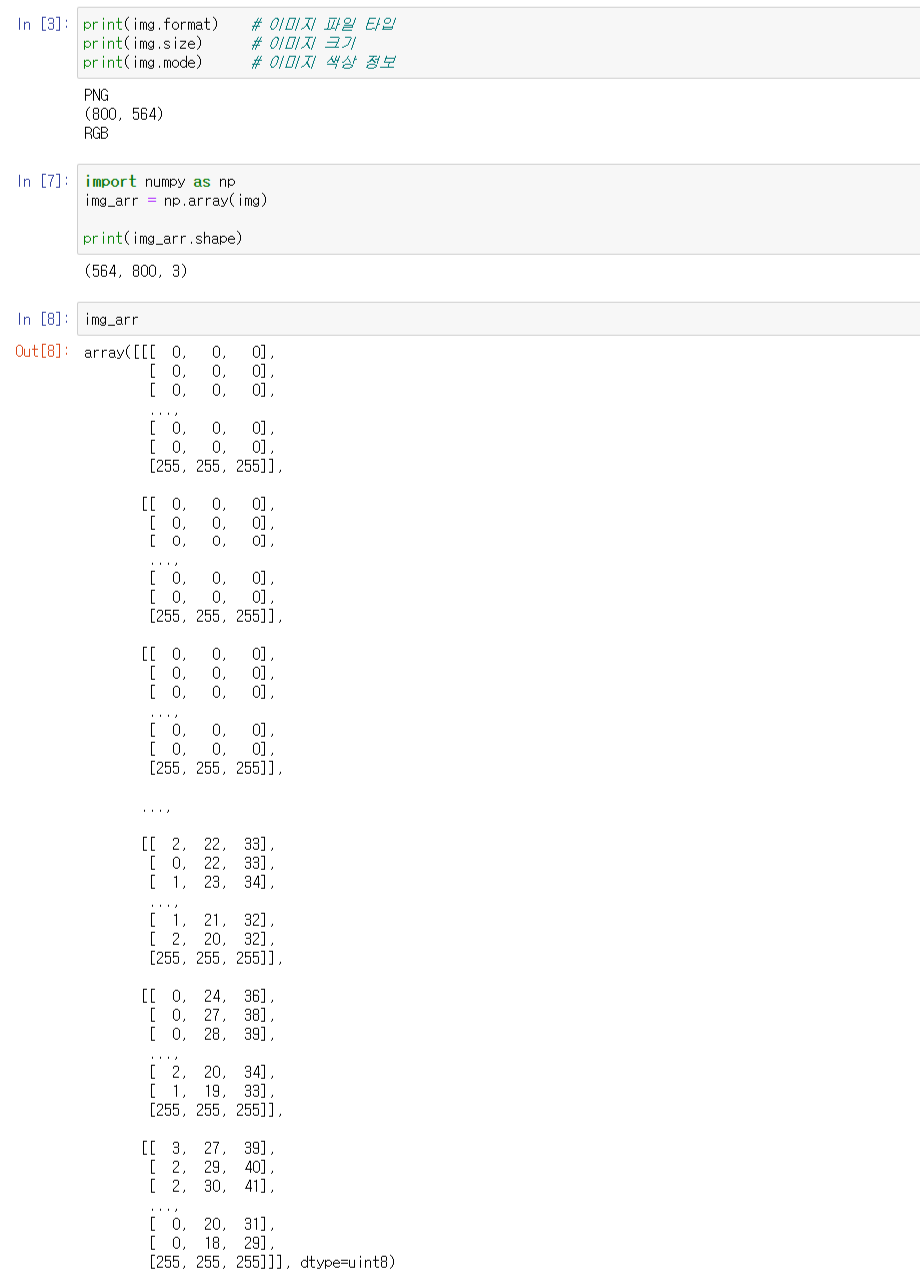
다음과 같이 불러온 이미지의 크기를 확인할 수 있고, 픽셀 별로 RGB값으로 저장되어 3차원의 array 로 저장되는 모습을 볼 수 있다.
Pandas
데이터를 다루다보면 데이터 내에 자체적인 서브 구조를 가지느 데이터를 볼 수 있고, 그것을 구조화된 데이터 라고 부른다. 특정 칼럼안에 행들이 존재하고, 행들 안에 데이터가 있는 형태이다. 이러한 구조화된 데이터를 편리하게 다루기위한 라이브러리가 Pandas 이다.

Series 는 구조화된 데이터를 표현하는데 중요한 개념 중 하나로, 일련의 객체를 담을 수 있는 1차원 배열과 비슷한 자료 구조이다. 리스트, 튜플, numpy 자료형들으로도 만들 수 있다.
Series 에는 index 와 value 가 있다. index 는 순서를 나타낸 숫자이고, value 는 실제 데이터의 값이다.
DataFrame 은 표(table)와 같은 자료 구조이다. 즉, Series의 연속된 구조이며, 여러 개의 칼럼을 나타낼 수 있다. 따라서 csv 파일이나 excel 파일을 DataFrame 으로 변환하여 편리하게 데이터를 다룰 수 있다.
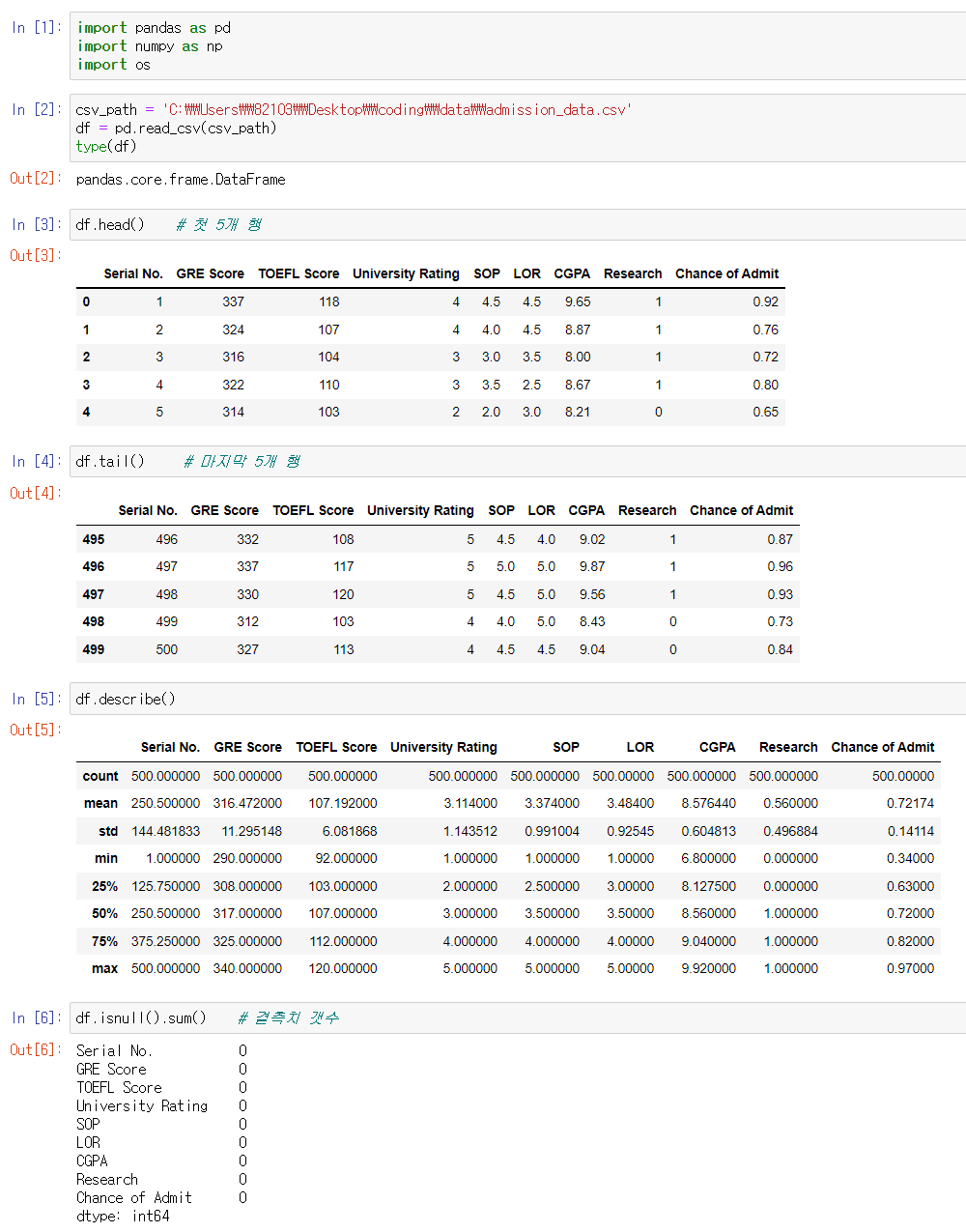
csv 파일 출처 : [https://www.kaggle.com/mohansacharya/graduate-admissions]
csv 파일을 DataFrame 객체로 읽고 pandas 메소드를 통해 다양한 방법으로 데이터 분석을 할 수 있다.
DataFrame 인덱싱
추가 예정
