✅ 핵심 내용
- 전체 데이터 분석 순서 이해
- 결측치, 이상치 처리
- 데이터 정규화
- 원-핫 인코딩 (One-Hot Encoding)
- 구간화
" 데이터 분석의 80퍼센트는 데이터 전처리이다. "
라는 말이 있듯이 데이터 분석에 있어 데이터 전처리 과정은 아주 중요하다. 전처리에 따라서 데이터 분석의 질이 달라진다. 그러한 이유는 무엇일까?
데이터 전처리의 중요성과 역할을 알아보기 위해 본격적인 데이터 전처리 과정을 알아보기에 앞서 전체적인 데이터 분석 순서에 대해 공부하였다.
👨💻 데이터 분석 순서
데이터 분석의 80퍼센트는 데이터 전처리이다.
라는 말이 있듯이 데이터 분석에 있어 데이터 전처리 과정은 아주 중요하다. 전처리에 따라서 데이터 분석의 질이 달라진다. 그러한 이유는 무엇일까?
데이터 전처리의 중요성과 역할을 알아보기 위해 본격적인 데이터 전처리 과정을 알아보기에 앞서 전체적인 데이터 분석 순서에 대해 공부하였다.
1. 문제 정의 (Problem identification)
- Business 목적 파악
- 현재 솔루션의 구성 파악
2. 데이터 수집 (Collecting data sets)
- Database, file(csv, xml, json) 등을 이용
- 웹 크롤링을 이용 (파이썬 패키지 BeautifulSoup 등을 이용)
3. 데이터 전처리 (Preprocessing)
- 결측치 처리 : 데이터 삭제 또는 다른 값(평균값, 중앙값, 예측모델 활용값)으로 대체
- 이상치 처리 : 이상치 값 설정 및 해당 값 삭제,대체
- Feature Engineering : scaling, binning, transform, encoding
4. 탐색적 데이터 분석 (Exploratory Data Analysis, EDA)
- 구체적인 분석을 통한 데이터 이해도 향상
- 최댓값, 최솟값, 평균값, 중앙값, 분산, 표준편차, 사분위수 등의 통계적 정보 파악
- 범주형 or 수치형 데이터 파악
- 변수간 상관 관계, 독립 관계 파악
- Feature Selection : 사용할 특성 선택
5. 모델(Model) 선택 및 하이퍼 파라미터(Hyper parameter) 조정
- 해당 데이터에 알맞는 모델 선택
- 모델의 성능을 개선,최적화 할 수 있는 hyper parameter 조정
- 파이썬 패키지 Scikit learn, Tensorflow, Keras, Pytorch 등 사용
6. 모델 학습
- model.fit 및 model.predict
7. 모델 평가
- 정확도 (accuracy), 재현율 (recall), 정밀도 (precision) 등으로 모델 평가
8. 데이터 시각화 및 서비스화
- 시각화 : 다양한 그래프 (scatter plot, bar chart, box plot, histogram, heatmap)를 사용
- 서비스화 : 웹서비스, 모바일 어플리케이션, 데스크탑 어플리케이션
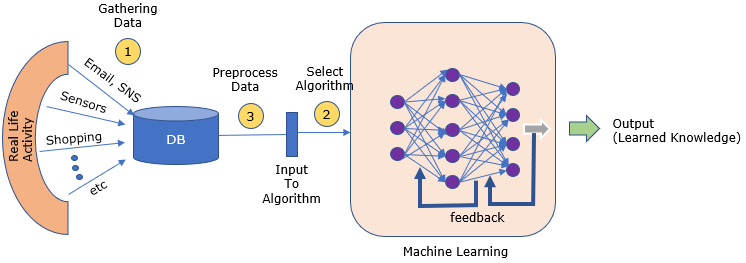
출처 : http://www.sharetechnote.com/html/NN/NN_HowToLearn.html
위의 전체적인 데이터 분석 과정을 보면 데이터 전처리 부분이 해당 데이터를 본격적으로 다루는 첫 단추의 역할을 한다. 따라서 데이터 전처리가 잘 된 경우, 전체적인 데이터 분석의 품질이 높아지고 예측 모델의 성능을 높일 수 있다.
📑 데이터 전처리 (Preprocessing)
결측치 Missing Data
현실의 데이터는 완벽히 완성되어있지 않아 데이터 분석 과정에서 문제가 되곤한다. 그 중 첫번째 문제는 데이터 수집하는 과정에서 누락된 데이터인 결측치이다.
결측치는 데이터의 특성을 반영하여 두 가지 방법 중의 한 방법으로 처리해야한다.
- 결측치가 있는 데이터 삭제
- 결측치를 다른 값으로 대체
그럼 결측치를 다른 값으로 대체해야할때는 어떤 값을 사용해야할까?
수치형 데이터의 경우, 다음과 같은 방법들이 있다.
-
특정 값을 지정 (결측치가 많은 경우, 모두 같은 값으로 대체하면 데이터의 분산이 실제보다 작아지는 문제 발생 가능)
-
평균 또는 중앙값으로 대체 (결측치가 많은 경우, 모두 같은 값으로 대체하면 데이터의 분산이 실제보다 작아지는 문제 발생 가능)
-
다른 데이터를 이용한 예측값으로 대체
-
시계열 특성을 가진 데이터의 경우, 앞뒤 데이터를 통해 결측치 대체
범주형 데이터의 경우, 다음과 같은 방법들이 있다.
- 특정 값을 지정 ('기타','결측' 과 같은 새로운 범주를 만들어 결측치를 채울 수도 있음)
- 최빈값 등으로 대체 (결측치가 많은 경우, 최빈값이 지나치게 많아질 수 있음)
- 다른 데이터를 이용한 예측값으로 대체
- 시계열 특성을 가진 데이터의 경우, 앞뒤 데이터를 통해 결측치 대체
관세청 수출입 무역 통계에서 가공한 데이터인 trade.csv 을 이용해 결측치 처리 예시를 실행하였다.
➡ 깃허브 링크 (추가예정)
중복된 데이터
데이터를 수집하는 과정에서 중복된 데이터가 생길 수 있다. 이러한 데이터를 처리해보자.
duplicated 함수를 통해 중복된 데이터 여부를 True, False 값으로 반환하여 중복된 데이터를 찾아낼 수 있다.
이후 중복된 데이터를 drop_duplicates 의 subset, keep 옵션을 통해 손쉽게 중복을 제거할 수 있습니다.
관세청 수출입 무역 통계에서 가공한 데이터인 trade.csv 을 이용해 중복된 데이터 처리 예시를 실행하였다.
➡ 깃허브 링크 (추가예정)
이상치 Outlier
이상치란 데이터의 대부분 값의 범위에서 벗어나 극단적으로 크거나 작은 값을 의미한다. 이후에 나올 Min-Max Scaling 시 몇 개의 이상치 때문에 대부분의 데이터의 의미가 없어지게 되는 문제가 발생한다.
따라서 이러한 이상치를 분석하고 제거해야할 필요성이 있다.
그렇다면 어떤 기준으로 이상치를 찾아낼까? 앞으로 이상치를 찾는 방법 2가지를 알아보겠다.
첫번째 방법은 z score 방법이다.
평균을 빼주고 표준편차로 나눠 z score () 을 계산한다. 그리고 z score가 특정 기준을 넘어서는 데이터는 이상치라고 판단 하는 방법이다.
이상치를 판단한 후에 이상치 데이터들을 다음과 같은 방법으로 처리한다.
- 이상치 삭제
- 다른 값으로 대체
- 다른 데이터를 이용해 예측
- 구간화(binning)을 통해 수치형 데이터를 범주형으로 변환
이상치를 찾는 두 번째 방법은 IQR method 이다.
여기서 은 제 3사분위수에서 제 1사분위 값을 뺀 값으로 데이터의 중간 50%의 범위이다.
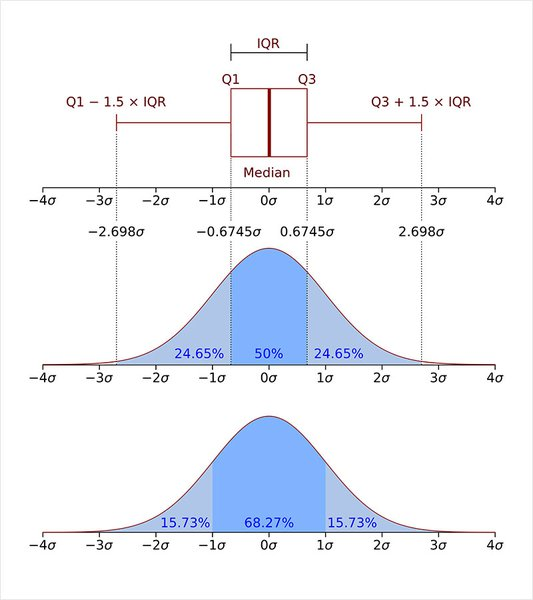
출처 : https://en.wikipedia.org/wiki/Interquartile_range
보다 작거나 보다 큰 값을 이상치라고 판단한다.
관세청 수출입 무역 통계에서 가공한 데이터인 trade.csv 을 이용해 이상치 처리 예시를 실행하였다.
➡ 깃허브 링크 (추가예정)
정규화 Normalization
데이터는 각 단위가 각각 다른 단위의 데이터들로 이루어져있다. 컬럼마다 스케일이 크게 차이가 나면 범위가 큰 칼럼에 영향을 크게 받는 문제가 발생한다.
일반적으로 컬럼간에 범위가 크게 다를 경우 전처리 과정에서 데이터를 정규화한다.
그중에서 Min-Max Scaling 과 Standardization 에 대해 알아보겠다.
Min-Max Scaling 은 데이터의 최솟값은0, 최댓값은 1로 전체 데이터를 변환하는것이다.


scikit-learn 에서도 sklearn.preprocessing.MinMaxScaler() 을 사용하여 Min-Max Scaling 을 구현하였다.
여기서 자세한 코드를 확인 할 수 있다. ➡ Github_Normalization
다음으로 Standardization 은 데이터의 평균을 0, 분산을 1로 변환하는 것이다.
Standardization 또한 scikit-learn 을 통해 preprocessing.StandardScaler()를 사용하여 간단히 구현하였다.
여기서 자세한 코드를 확인 할 수 있다. ➡ Github_Standardization
마지막으로 앞에서 다룬 관세청 수출입 무역 통계에서 가공한 데이터인 trade.csv 를 Min-Max Scaling 방법으로 정규화했다.
➡ 깃허브 링크 (추가예정)
One-Hot Encoding
one-hot encoding 이란 카테고리별 이진 특성을 만들어 해당하는 특성만 1, 나머지는 0으로 만드는 방법이다.

one-hot encoding 은 pandas의 get_dummies 함수를 통해 구현할 수 있다.
get_dummies를 통해 trade 데이터셋에 '국가명' 칼럼을 one-hot encoding 하였다.
➡ 깃허브 링크 (추가예정)
구간화 Binning
구간화는 연속적인 데이터를 구간별로 나누어 범주형 카테고리로 만드는것이다.
pandas 의 cut, qcut 메소드를 이용하여 구현할 수 있다.
➡ 깃허브 링크 (추가예정)
