원제: Alessandro Segala - When "Zoë" !== "Zoë". Or why you need to normalize Unicode strings
원본 게시물 링크: https://withblue.ink/2019/03/11/why-you-need-to-normalize-unicode-strings.html
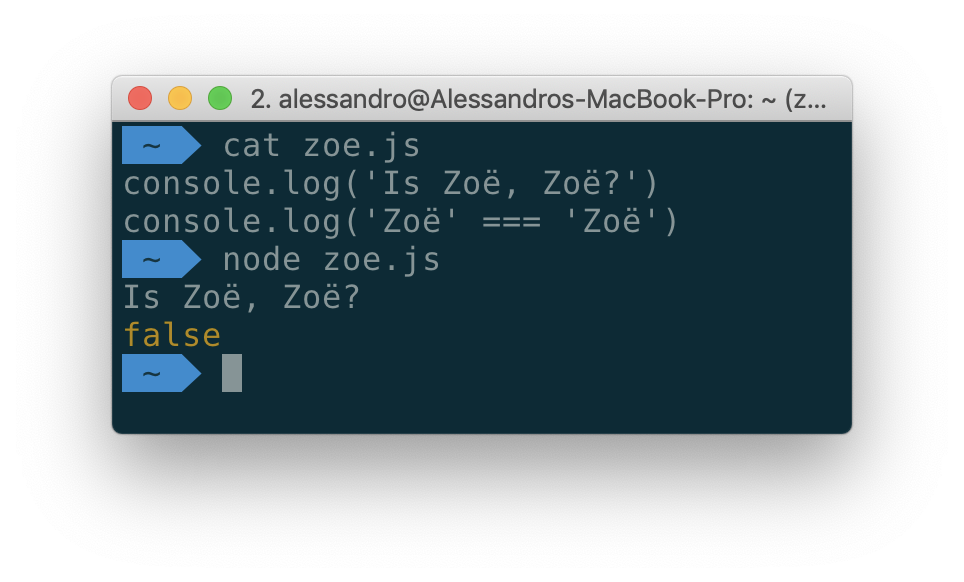
개발을 하다보면 언젠가 한 번은 이런 일을 겪을 것이다.
이런 현상은 비단 자바스크립트의 문제만은 아니다. Python, Go 혹은 shell 스크립트 등 거의 모든 프로그래밍 언어에서 비슷한 일이 벌어지기 때문이다.
이런 현상을 처음 발견한 것은 몇 년전 Objective-C 앱을 개발하고 있을 때였다. 앱에는 주소록과 SNS에서 연락처를 가져와서 중복된 연락처를 제거하는 기능이 포함되어 있었는데, 가끔 같은 이름이 동일한 스트링으로 비교되지 않아서 두 번 들어가는 일이 발생했다.
사실 두 개의 스트링이 화면 상에 동일하게 보여도, 파일로 저장될 때는 다른 바이트로 저장될 수 있다. 첫 번째 “Zoë”의 ë (움라우트 e) 는 유니코드 하나로 표현됐지만 두 번째 스트링은 분해된 형태(decomposed form)으로 표현됐다. 만약 당신이 유니코드 스트링을 처리해야될 일이 생긴다면 같은 글자가 실제로는 두 가지 방법으로 표현될 수 있다는 점을 염두에 두어야한다.
이모티콘과 글자 인코딩
컴퓨터는 데이터를 바이트 혹은 간단히 숫자로 처리한다. 그러므로 글자를 나타내려면 각 글자를 특정 숫자에 대응시켜야 한다. 그리고 어떤 식으로 이를 처리할지를 정리한 것을 글자 인코딩 규약이라고 한다.
글자 인코딩에 대한 첫 번째 규약은 ASCII다. ASCII는 알파벳 대소문자와 숫자 그리고 간단한 문장부호를 포함하는 128개의 글자를 나타내기 위해 각 글자에 7 비트를 부여한다. 여기에는 "프린트할 수 없는(non-printable)" 글자들도 포함됐는데, newline, tab, carriage return 등이 해당 된다. ASCII 체제에서 M은 77 (혹은 16진법 형식으로는 4D)로 나타낼 수 있다.
문제는 128개의 글자가 영어화자에게는 충분할지 몰라도 이모티콘을 포함하는 전세계의 언어를 모두 표현하기에는 너무 작다는 점이다.
그래서 인쇄 가능한 현재와 과거의 모든 언어와 다양한 심볼을 포함하는 체계를 만들기 위해 Unicode로 불리는 새로운 체계를 도입됐다. Unicode는 현재 며칠전에 12.0 버전이 공개되었으며 무려 137,000개의 글자를 지원한다.
Unicode는 다양한 방식으로 구현이 가능하며, 가장 보편적인 방식은 UTF-8과 UTF-16이고 웹 상에서는 UTF-8이 좀더 보편적이다.
두 방식의 차이는 UTF-8은 1에서 4바이트까지 사용하고, ASCII의 상위호환이기 때문에 첫 128개의 글자를 공유하는 반면 UTF-16은 2에서 4바이트를 사용한다.
왜 한 가지 체계에 두 가지 방식을 사용할까? 이는 서구권 언어가 보통 UTF-8을 사용할 때 가장 효율적으로 인코딩할 수 있는 반면 (대부분의 글자를 1바이트만으로 나타낼 수 있으므로), 아시아권 언어는 UTF-16을 사용할 때 가장 효율적이기 때문이다.
글자 인코딩과 Unicode 값
Unicode 체계에서 각 글자는 구별 가능한 숫자 혹은 값 (code point)를 부여받는다. 예를 들어 강아지 이모티콘 (🐶)은 U+1F436의 값을 가지고 있다.
인코딩 되었을 때 강아지 이모티콘은 아래 두 가지 방식으로 나타난다:
UTF-8: 4 bytes, 0xF0 0x9F 0x90 0xB6
UTF-16: 4 bytes, 0xD83D 0xDC36그리고 자바스크립트에서는 아래 코드가 모두 같은 값을 리턴한다:
// 파일 내부의 바이트 시퀀스를 그대로 사용
console.log('🐶') // => 🐶
// Unicode 값을 사용 (ES2015 and newer)
console.log('\u{1F436}') // => 🐶
// UTF-16 방식
console.log('\uD83D\uDC36') // => 🐶Node.js와 모던 브라우저를 포함하는 다수의 자바스크립트 인터프리터가 내부적으로 UTF-16 방식을 사용한다. 그러므로 강아지 이모티콘은 각각 16 비트를 가지는 두 개의 UTF-16 값으로 저장된다. 그러므로 아래 코드는 전혀 이상하지 않다.
console.log('🐶'.length) // => 2글자 합치기
이제 다시 동일하게 보이지만 다른 방식으로 나타나는 글자들을 살펴보자.
Unicode 글자 중 일부는 합자(combining characters)인데, 예를 들어:
n + ˜ = ñ
u + ¨ = ü
e + ´ = é물론 모든 합자가 발음 구별 기호를 사용하는 것은 아니다. 걔 중에는 æ이나 ffi처럼 발음 구별 기호 없이 합쳐진 경우도 있다.
예를 들어 é는:
- 단일 Unicode 값: U+00E9
- 글자 e와 양음 부호의 Unicode 값의 결합: U+0065 과 U+0301
두 글자는 동일하게 보이지만 동일한 값으로 비교되지는 않으며 서로 다른 길이를 가지고 있다.
자바스크립트에서는:
console.log('\u00e9') // => é
console.log('\u0065\u0301') // => é
console.log('\u00e9' == '\u0065\u0301') // => false
console.log('\u00e9'.length) // => 1
console.log('\u0065\u0301'.length) // => 2이런 현상은 데이터베이스에서 해당 레코드를 조회하지 못한다거나 유저의 비밀번호가 일치하지 않는다거나 하는 등 예기치 못한 버그를 불러올 수 있다.
유니코드 정규화
다행히 아주 간단한 해결책이 있다. 문자열을 정규화된 형태(canonical form)로 나타내는 것이다.
아래는 네 가지 표준 정규화 방식이다:
- NFC: Normalization Form Canonical Composition
- NFD: Normalization Form Canonical Decomposition
- NFKC: Normalization Form Compatibility Composition
- NFKD: Normalization Form Compatibility Decomposition
가장 보편적인 방식은 NFC이며, 이 방식은 먼저 모든 글자를 분해한 다음 합자를 표준에 명시된 순서에 따라 다시 합치는 방식이다. 물론 어떤 방식을 사용하든 일관되게 한 방식만 사용한다면 전혀 문제될 것이 없다.
자바스크립트는 문자열 내장 함수의 형태로 정규화를 지원한다. ES2015에 추가된 String.prototype.normalize([form]) 함수가 그것인데, form 인자는 'NFC'와 같은 정규화 방식을 의미한다.
이제 이전 예시를 정규화를 사용해서 나타내보자.
const str = '\u0065\u0301'
console.log(str == '\u00e9') // => false
const normalized = str.normalize('NFC')
console.log(normalized == '\u00e9') // => true
console.log(normalized.length) // => 1요약
간단히 말해서 유저로부터 입력값을 받을 때는 항상 Unicode 정규화를 사용해야 한다.
그리고 자바스크립트에서는 ES2015부터 내장된 String.prototype.normalize() 함수를 사용할 수 있다.
