
MongoDB는 평소 많이 사용했던 RDBMS가 아니고 NoSQL(Not Only SQL) 데이터베이스 중 하나이다.
1. 설치
https://www.mongodb.com/try/download/community

해당 url에 들어가서 msi 파일로 다운을 받고 환경변수 Path에 mongoDB 다운받은 경로 중 bin폴더 경로를 추가한다. ex)C:\Program Files\MongoDB\Server\4.2\bin
cmd창을 열고 mongo명령어를 치고 들어간다.
2. 메소드 정리
2-1)기본 메소드
use db명 - DB 생성
db - 현재 들어와있는 DB 확인
show dbs - DB 리스트 확인
db.dropDatabase() - DB 제거. 제거하기 전 use로 제거할 DB 선택해서 혹시 모를 실수 방지
db.createCollection("collection명", {
... capped: true, //사이즈 제한두기, 꽉차면 오래된 데이터를 덮어쓰기
... autoIndexId: true, //index 자동 생성
... size: 6142800, // capped을 위한 최대사이즈
... max: 10000 // 최대 갯수
... })
- collection 생성.
추가는 save()로 해도 된다. 차이점은 같은 id가 있는 경우 insert는 에러나고 save는 걍 덮어쓴다.
db.collection명.remove({"name": "Book1"},true) - document 제거.book1인거 제거. 두번째 변수는 조건에 맞는 document 한 개만 제거할 것인지 해당되는 document 다 제거 할 것인지 (true or false)
2-2)조회 메소드
db.collection명.find() - document 전체 조회. .pretty()붙이면 결과가 깔끔해진다.
db.colelction명.find({"likes":{$lte:30}}) - likes 항목이 30이하인 document조회
db.collection명.find({"likes":{$gt:10,$lt:30}}) - likes가 10보다 크고 30보다 작은 것 조회
db.collection명.find({"writer":{$in:["Alpha","Bravo"]}}) - writer 항목이 ["Alpha","Bravo"] 배열안의 값들과 맞는 것들 조회
db.collection명.find({$and :[{"writer":"writer1"},{"likes":{$lt:10}}]}) - AND 조건 조회.
= db.collection명.find("writer":"writer1","likes":{$lt:10})
db.collection명.find({"title":/article0[1-2]/}) - 정규식으로 조건 표현 가능. title이 article01, article02인 것들 조회
db.collection명.find({$where:"this.comments.length == 0"}) - where절을 써서 표현 가능. comments배열이 비어있는 document 조회
db.collection명.find({"comments":{$elemMatch:{"name":"writer1"}}}) - $elemMatch. embedded documents배열 쿼리 시 사용.
ex)comments:[{"title":"aaa","name":"writer1"},{"title":"bbb","name":"writer2"}] 형태에서 comments name이 writer1인 것 조회
db.collection명.find({"name.first":"abc"}) - 데이터 형태가 ex)name:[]
db.collection명.find({},{_id:false, title:true, content:true}) - 두번째 파라미터 이용. _id는 조회 안되고 title과 content만 조회된다.
db.collection명.find({"title":"title1"},{comments:{$slice:1}}) - $slice는 embeded 배열 읽을 때 limit 설정. title값이 title1이인 document를 조회하지만 comments배열의 값은 하나만 조회.
db.collection명.find({"comments":{$elemMatch:{"name":"name1"}}}
,{"title":true,"comments:"{$elemMatch:{"name":"name1"}},"comments.name":true,"comments.message":true}) - comments중 name1이 작성한 덧글이 있는 document 중 제목 , 그리고 name1의 댓글만 조회
db.collection명.find().sort({"_id":1}) - id기준 오름차순 정렬 조회
db.collection명.find().sort({"amount":1,"_id":-1}) - amount 오름차순 하고 _id 내림차순 정렬
db.collection명.find().limit(3) - 3개 까지만 조회
db.collection명.find().skip(2) - 2개 데이터 생략하고 그 다음부터 조회
var showPage = function(page){
return db.collection명.find().sort({"_id":-1}).skip((page-1)*2).limit(2)
} - 최신순으로 한 페이지당 2개씩 나타내기
2-3)UPDATE 메소드
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)=> query : 조건
update: 변동사항
upsert : true면 해당 건이 없으면 새로 추가
multi : true면 여러개 수정 (기본은 false하나만 수정)
db.collection명.update( { name: "Aladdin" }, { $set: { age: 20 } } ) - 특정 필드 값을 수정할 때 $set 사용. 이름이 Abet인 사람의 나이를 20으로 수정.
db.collection명.update({name:"Aladdin"},{"name":"Ala","age":1}) - 이름이 Aladdin인 데이터를 아예 replace하기.
db.collection명.update({name:"Ati"},{$unset : {score : 1}}) - $unset을 쓰면 해당 필드 제거.
db.collection명.update({name:"Eden"},{name:"Eden",age:17},{upsert:true}) - 해당 건이 없으면 새로 추가한다.
db.collection명.update({name:"Eden"},{$push:{skills:"java"}}) - skills라는 배열에 값 추가 할 땐 $push사용.
db.collection명.update({name:"Eden"},{$push:{skills:{$each:["js","c++"],$sort:1}}}) - $each를 사용하여 배열에 여러개 값 추가하고, 오름차순 정렬하기.
db.collection명.update({name:"Eden"},{$pull:{skills:"java"}}) - $pull사용해 배열에 값 제거
db.collection명.update({name:"Eden"},{$pull:{skills:{$in:["js","c++"]}}}) - $in사용하여 배열에 값 여러개 제거
save()로도 update할 수 있지만 save는 그냥 덮어쓰는거라 위험부담이 크다.
2-4)Index 관련 메소드
db.collection명.createIndex({score:1}) - score필드에 인덱스 걸기. ensureIndex()라는 메소드가 별칭으로 있지만 deprecated.
db.collection명.createIndex({age:1, score:-1}) - 복합 필드 인덱스 생성. age 오름차순, score 내림차순
db.collection명.createIndex({firstName:1 , lastName:1}, {unique:true}) - unique를 true로 주어서 유일함 속성 추가.
db.collection명.createIndex({name:1}, {partialFilterExpression : {visitors: {$gt: 1000}}}) - visitors값이 1000보다 높은 document에만 name필드에 인덱스 적용.
db.collection명.createIndex({"notifiedDate : 1"}, {expireAfterSeconds:3600}) - notifiedDate가 현재시간과 1시간 이상 차이나면 제거
db.collection명.getIndexes() - 인덱스 조회
db.collection명.dropIndex({KEY: 1}) - 인덱스 제거.
db.collection명.dropIndexes() - _id 인덱스를 제외한 모든 인덱스 제거.
3. 쿼리 튜닝
MongoDB는 쿼리 수행하기 전 Query Planner를 통해 최적의 쿼리 플랜을 설정할 수 있다. 쿼리 플랜이란 어떤 적절한 인덱스를 사용해 쿼리를 수행할 지 정하는 것이다. 결국 최적의 쿼리 플랜은 사용했을 때 최고의 성능을 보여주는 인덱스를 뜻한다.
쿼리.explain()
을 사용하여 쿼리 수행 정보를 확인 할 수 있다.
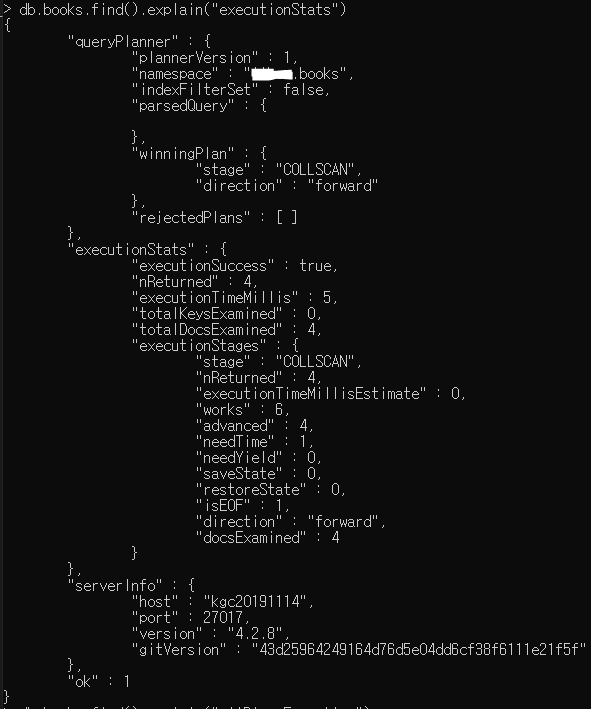
전달되는 인자를 통해 queryPlanner, executionStats, allPlansExecution 3단계 레벨의 수행 정보를 확인 할 수 있다. 상위 레벨은 하위 레벨의 내용을 포함한다.
queryPlanner : 어떤 쿼리 플랜이 사용되었는지 표시
executionStats : 선정된 쿼리 플랜에 대한 자세한 수행 정보
allPlansExecution : 선정되지 못한 쿼리 플랜에 대한 부분 수행 정보
- queryPlanner안에 winningPlan 안에 state : 인덱스가 설정되었으면 IXSCAN이고, 인덱스 없으면 컬렉션 전체 순회하는 COLLSCAN이 나온다.
- totalKeysExamined : 몇 개의 인덱스 요소를 검사했는지. 적을 수록 효율적이다.
출처&참조 : https://velopert.com/mongodb-tutorial-list,
https://m.blog.naver.com/PostView.nhn?blogId=suresofttech&logNo=221096609752&proxyReferer=https:%2F%2Fwww.google.com%2F
