
🍎 iOS 메모리 구조 (Code, Data, Stack, Heap)
1. 🍏 메모리 구조
- 운영체제(OS)는 메모리(RAM)에 이 프로그램을 위한 공간을 할당
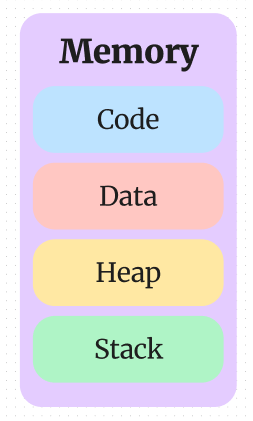
◻️ 1-1. 코드(Code) 영역

- 우리가 작성한 소스 코드가 기계어 형태로 저장됨
- 컴파일 타임에 결정, 중간에 코드가 변경되지 않도록 Read - Only 형태로 저장
- 컴퓨터가 읽을 수 있는 가장 밑단의 언어
◻️ 1-2. 데이터(Data) 영역

- 전역변수, static 변수가 저장됨
- 프로그램 시작과 동시에 할당, 프로그램 종료가 되어야 메모리 해제
- 실행도중 변수값이 변경 될 수 있으니 Read-Write로 지정
student Korean {
static let country = "Korea" //스태틱 변수(상수)로 데티어 영역에 할당
}
var name: String? //전역 변수로 데이터 영역에 할당
var age: Int? //전역 변수로 데이터 영역에 할당
func fetchData() {
}name과 age는 전역 변수, country는 static 상수로 데이터 영역에 할당 됨!
◻️ 1-3. 힙(Heap) 영역

- 프로그래머가 할당/해제 하는 메모리 영역
- 프로그래머는 malloc, calloc으로 힙에 메모리를 할당할 수 있으며, 이를 '동적 할당' 이라고 함
- 사용하고 난 후에는 반드시 메모리 해제를 해줘야 함
그렇지 않으면 memory leak이 발생 - Code, Data, Stack중 유일하게 런타임시에 결정되기 때문에 데이터 크기가 확실하지 않을 때 사용
- 클래스 인스턴스(Class Instance), 클로저 같은 참조 타입의 값들은 힙에 자동 할당 됨!!!!!
- 스위프트는 ARC를 통해 힙에 할당된 메모리가 더 이상 쓸모 없어지면(참조되지 않으면) 자동으로 해제해주기 때문에 우리가 free, release등으로 해제한적이 없는것 !
🌈 장점
- 메모리 크기에 대한 제한 없음
- 본질적인 범위가 전역이기 때문에, 프로그램의 모든 함수에서 액세스 할 수 있음
🌈 단점
- 할당작업, 해제 작업으로 인한 속도 저하
- 힙 손상(이중 해제, 해제 후 사용 등) 작업으로 인한 속도 저하
- 힙 경합(두 개 이상 쓰레드가 동시에 접근하려 할 때 Lock이 걸림)으로 인한 속도 저하
- 메모리를 직접 관리해야 함(해제해주지 않을 시 메모리 누수 발생)
◻️ 1-4. 스택(Stack) 영역

- 함수 호출 시 함수의 지역변수, 매개변수, 리턴 값 등이 저장
- 함수가 종료되면 저장된 메모리도 해제
- 컴파일 타임에 결정되기 때문에 무한히 할당 할 수 없다
- "LIFO"(last in, first out) 데이터 구조
먼저 생성된 변수가 가장 나중에 해제됨
🌈 장점
- CPU가 스택 메모리를 효율적으로 구성하기 때문에 속도가 매우 빠름
- 메모리를 직접 해제를 해주지 않아도 됨
🌈 단점
- 메모리 크기에 대한 제한 있음
- 지역 변수만 액세스 가능
2. 🍏 힙(Heap) vs 스택(Stack)
◻️ 2-1. 언제 힙을 쓰고, 언제 스택을 쓰나요?
- 데이터의 크기를 모르거나, 스택에 저장하기엔 큰 데이터의 경우엔 힙에 할당 하고 그 외엔 스택에 할당하면 됨
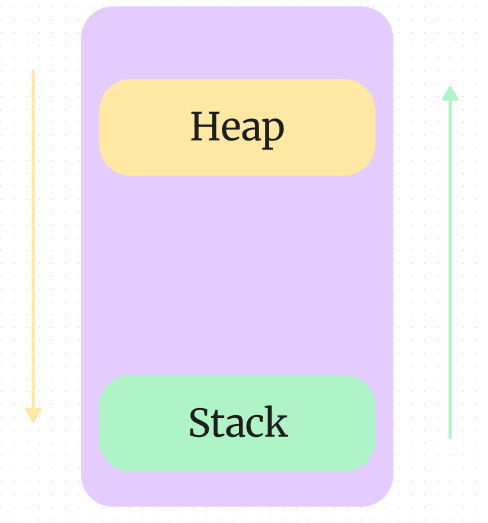
◻️ 2-2. 힙과 스택의 메모리 관계
-
힙과 스택은 같은 메모리 영역을 공유
- 힙 영역은 낮은 메모리 주소부터 할당
- 스택 영역은 높은 메모리 주소부터 할당
3.🍏 자료구조 스택(Stack)과 큐(Queue)
◻️ 스택(Stack)
-Stack 은 ‘쌓다’라는 단어로, 데이터를 저장할 때는 가장 위에 새로운 데이터를 추가하고, 데이터를 꺼낼 때는 가장 위에 있는 데이터부터 꺼내는 방식입니다.
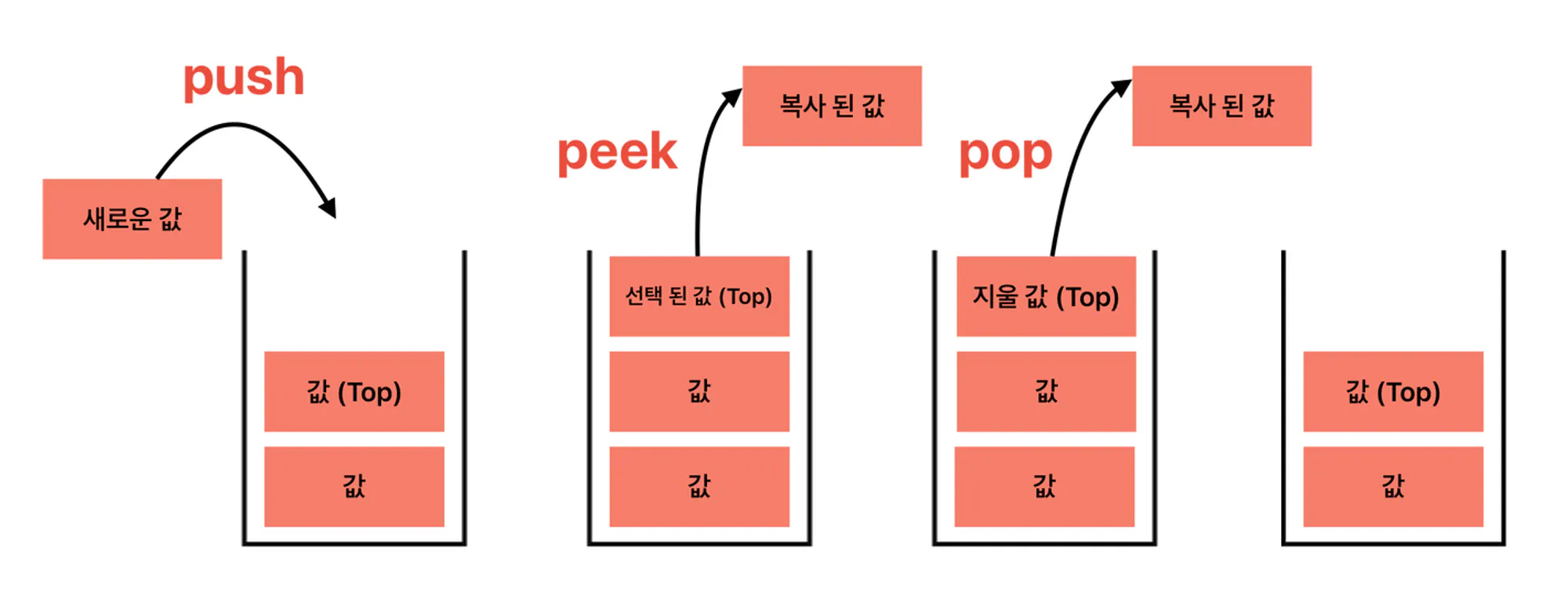
🌈스택에서 쓰이는 용어
- Top: 삽입과 삭제가 일어나는 위치
- Push: 새로운 데이터를 Stack에 쌓는 연산
- Peek: Top 이 가리키는 데이터를 단순 확인하는 연산
- Pop: Top 이 가리키는 데이터를 삭제하고 확인하는 연산
🌈 1) 후입선출(LIFO - Last In First Out) 구조
- 가장 마지막에 삽입된 데이터가 가장 먼저 삭제됩니다.
- 스택에 새로운 데이터를 삽입하면, 해당 데이터는 스택의 가장 위에 위치하게 됩니다.
- 스택에서 데이터를 삭제할 때는 가장 위에 있는 데이터부터 삭제됩니다.
🌈 2) 삽입과 삭제가 한 쪽에서만 이루어짐
- 스택의 한 쪽 끝에서만 데이터의 삽입과 삭제가 이루어집니다.
- 이 한 쪽 끝을 스택의 top이라고 부릅니다.
- 새로운 데이터를 삽입할 때는 top을 통해 삽입되고, 데이터를 삭제할 때도 top에서 삭제됩니다.
🌈 3) top 포인터의 이동
- 스택에 새로운 데이터가 삽입되면, top 포인터는 새로 삽입된 데이터를 가리키도록 이동합니다.
- 스택에서 데이터가 삭제되면, top 포인터는 그 아래에 있는 데이터를 가리키도록 이동합니다.
🌈 4) 데이터의 접근 제한
- 스택에서는 top 포인터가 가리키는 데이터에만 직접적으로 접근할 수 있습니다.
- 스택 내부의 다른 데이터에 접근하기 위해서는 top부터 시작하여 차례대로 데이터를 삭제해야 합니다.
🌈 5) 재귀 알고리즘과의 유사성
- 스택의 동작 원리는 재귀 함수의 동작 원리와 유사합니다.
- 재귀 함수에서는 함수가 자기 자신을 호출하면서 호출 정보를 스택에 저장하고, 함수가 종료되면 스택에서 이전 호출 정보를 꺼내 실행을 이어갑니다.
🌈 6) 깊이 우선 탐색(DFS)과의 관련성
- 스택은 깊이 우선 탐색(DFS) 알고리즘에서 유용하게 사용됩니다.
- DFS에서는 한 방향으로 깊이 탐색을 진행하다가 더 이상 탐색할 수 없을 때 이전 상태로 돌아가는데, 이때 스택을 활용하여 탐색 경로를 저장하고 관리합니다.
◻️ 큐(Queue)
- 큐(Queue)란 ‘대기줄’ 이라는 단어로, 데이터를 저장할 때는 큐의 뒤쪽(rear)에 새로운 데이터를 추가하고, 데이터를 꺼낼 때는 큐의 앞쪽(front)에서 데이터를 꺼내는 방식을 의미합니다.
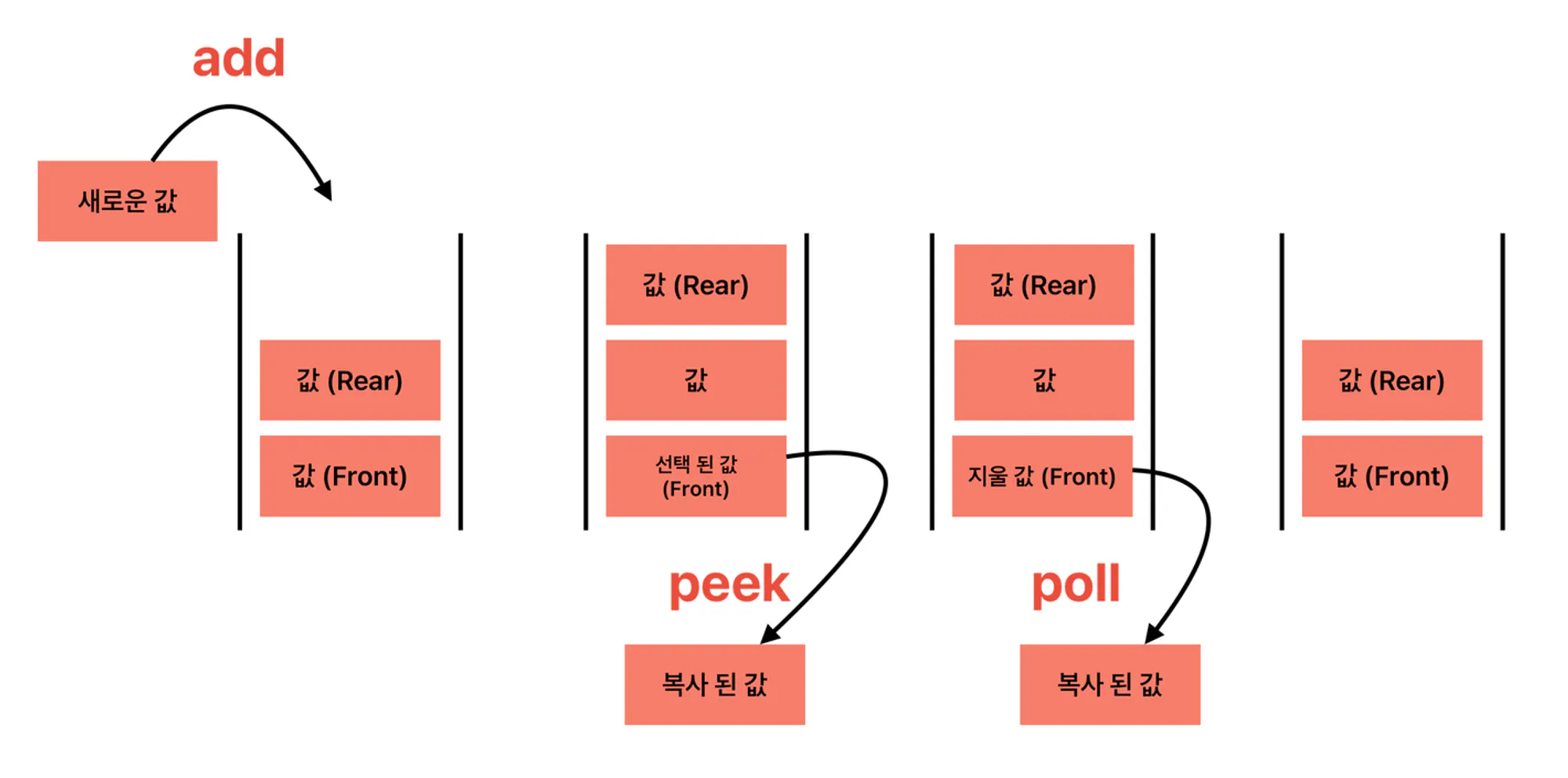
🌈큐에서 쓰이는 용어
- Rear: 큐의 가장 끝 데이터 영역
- Front: 큐의 가장 앞 데이터 영역
- Add: Rear 부분에 새로운 데이터를 삽입하는 연산
- Peek: Front 부분에 있는 데이터를 확인하는 연산
- Poll: Front 부분에 있는 데이터를 삭제하고 확인하는 연산
🌈 1) 큐에서 쓰이는 용어
- Rear: 큐의 가장 끝 데이터 영역
- Front: 큐의 가장 앞 데이터 영역
- Add: Rear 부분에 새로운 데이터를 삽입하는 연산
- Peek: Front 부분에 있는 데이터를 확인하는 연산
- Poll: Front 부분에 있는 데이터를 삭제하고 확인하는 연산
🌈2) 삽입과 삭제가 양방향에서 이루어짐
- Queue의 한 쪽 끝(Rear)에서는 데이터의 삽입이 이루어지고, 다른 쪽 끝(Front)에서는 데이터의 삭제가 이루어집니다.
- 새로운 데이터는 항상 Rear에 추가되며, 삭제는 Front에서부터 이루어집니다.
🌈3) Front와 Rear 포인터의 이동
- Queue에 새로운 데이터가 삽입되면, Rear 포인터는 새로 삽입된 데이터를 가리키도록 이동합니다.
- Queue에서 데이터가 삭제되면, Front 포인터는 그 다음 데이터를 가리키도록 이동합니다.
🌈4) 데이터의 접근 제한
- Queue에서는 Front 포인터가 가리키는 데이터와 Rear 포인터가 가리키는 데이터에만 직접적으로 접근할 수 있습니다.
- Queue 내부의 다른 데이터에 접근하기 위해서는 Front부터 시작하여 차례대로 데이터를 삭제해야 합니다.
🌈 5) 너비 우선 탐색(BFS)과의 관련성
- Queue는 너비 우선 탐색(BFS) 알고리즘에서 유용하게 사용됩니다.
- BFS에서는 시작 노드부터 인접한 노드를 먼저 탐색하고, 이후 다음 레벨의 노드들을 순차적으로 탐색하는데, 이때 Queue를 활용하여 탐색 순서를 관리합니다.

개발이 어려운 나를 위한... 개발노트