업무를 하다보면, 갑자기 서버에 이상이 생기는 경우가 있다. 모니터링 하는 프로세스 덕에 서버에 이상이 생기면 문자가 온다.
SYSTEM_CPU 93.XXXXXX % exceed. CPU 사용량이 높아서 발생한 문제인데, 간혹가다가 이것 때문에 서버가 먹통이 되는 경우가 있다 (잦진 않지만) 그럴때마다 PID를 Kill 한 후 컨테이너별로 재기동을 해주면 또 잘 작동한다..
개발자로써 서버 부하에 관한 지식을 알고 있어야 이러한 상황에 해결할 수 있을 것 같아 공부 후 정리해보려한다.
우선 일반적으로 서버에 걸리는 부하는 네트워크 부하, 서버 부하 총 두 가지로 나눌 수 있는데,
네트워크 부하란 서버에 접속하려는 사람이 일시적으로 증가하여 트래픽이 급증한 경우를 말한다.
그렇다면 이제 서버 부하를 알아보자
두 가지로 분류할 수 있는데,
CPU 부하는 서버에서 실행되고 있는 프로그램 자체의 연산량이 많은 경우나 프로그램에 오류등이 발생한 경우이고,
I/O 부하는 서버에서 실행되고 있는 프로그램의 입출력이 많거나, DB나 하드디스크 등의 저장 장치로의 접근이 많아 스왑이 발생하는 경우이다.
CPU사용률이 높은 경우는 서버를 얼마나 끄지 않았나(가비지가 안 없어짐), 특정 프로세스가 길을 막고 있지 않는가(Load average) 등등이 있고 I/O는 많이 일어날 수록 메모리 사용량이 올라간다.
Load average
CPU를 사용하기 위해 기다리고 있는 프로세스가 많으면 많을수록 CPU가 바빠지게 되고 결국 시스템에 부하가 생기게 된다.
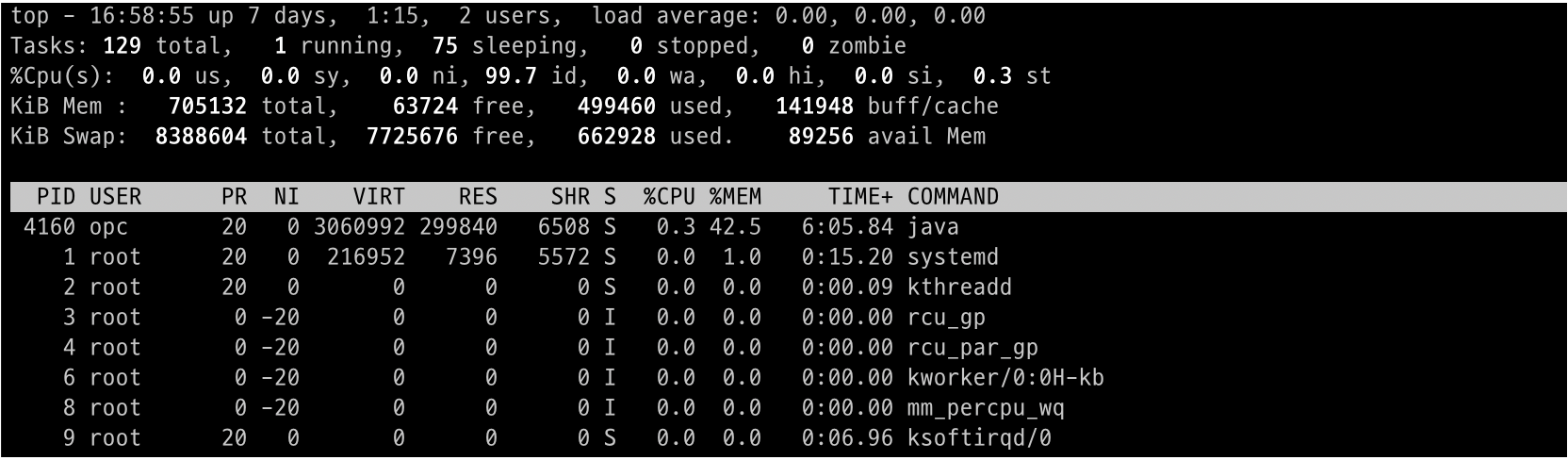
이런 경우 서버에서 top 으로 확인할 수 있는데 단순히 CPU 부하가 높은지 I/O 부하가 높은지는 알 수 없다.
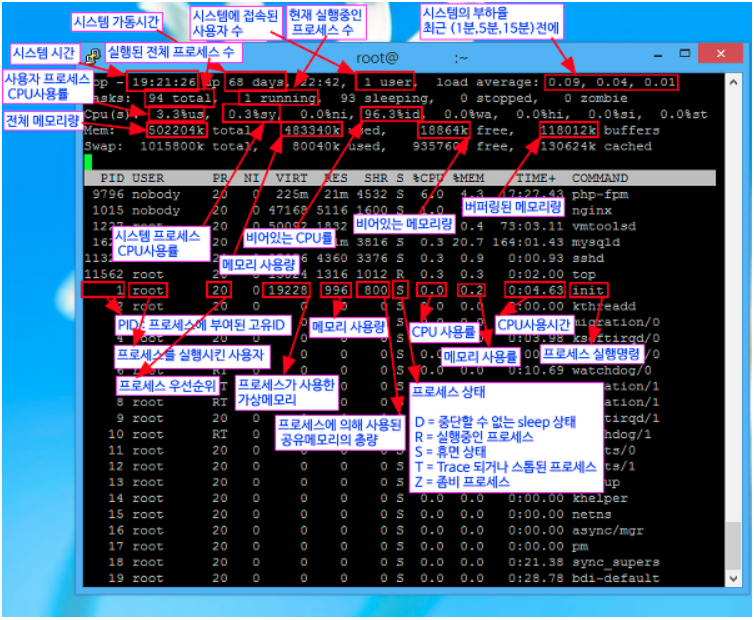
CPU 부하가 큰 경우는 CPU 바운드한 시스템이라고 하고, I/O 부하가 큰 경우는 I/O 바운드한 시스템이라고 한다.
CPU 바운드는 프로세스가 진행될 때, CPU 사용 기간이 I/O Wating 보다 많은 경우
반면 I/O 바운드는 프로세스가 진행될 때, I/O Wating 시간이 많은 경우다.
그렇다면 CPU 사용률이 높을 때 어떻게 해야하는가?
우선적으로 서버 전체를 재기동한다.
/app/jeus/bin 경로들어가서 jdown, jboot 순서대로 실행예상되는 원인 중 서버에 컨테이너별로 재기동은 했을지언정, 서버(JEUS) 전체 재기동은 자주 안 하는 듯 싶다..
이후 top 명령어로 모니터링을 해본다.
CPU 사용량과 MEMORY 사용량을 많이 먹는 프로세스를 확인 후 조치해야 한다.
원인을 분석하기 어렵다면 해당 프로세스의 GC Log를 확인해봐야한다.(개발자가 하는 일은 아니라고 하시긴 했다..)
프로세스 확인하는 명령어 (ps -ef |grep)을 사용하여 gc부분 확인
-XX:+PrintHeapAtGC -Xloggc:/logs/jeus/system/gclog/test_gc.log_20250218163414 gc로그 자체를 분석하기에 어려움이 있다면,, 툴을 사용해보자
gceasy.io
