논문:https://arxiv.org/pdf/2503.14476
preliminary

📌 수식:
📘 등장하는 기호들 정리
| 기호 | 의미 |
|---|---|
| 현재 policy (학습 중) | |
| 이전 policy (고정됨, 학습 전) | |
| t번째 출력 토큰 | |
| t 이전까지의 토큰 시퀀스 | |
| 확률비 (importance ratio): | |
| Advantage (GAE로 계산된 이득) | |
| 클리핑 범위 제어 파라미터 |
🔍 수식의 의미 단계별 해설
🧮 1. 확률 비율 ( r_t(\theta) )
→ 현재 policy와 예전 policy가 동일한 이전 입력에 대해 t번째 토큰을 얼마나 다르게 예측하는지 측정
🛡️ 2. 클리핑:
→ 가 너무 크거나 작으면 1±ε 범위로 잘라서 정책 변화폭을 제한
→ 너무 급격한 업데이트 방지
⚖️ 3. min 함수:
→ 두 값 중 작은 쪽을 사용
→ 클리핑 후 이득이 줄어들면 그대로 사용, 아니면 클립된 쪽으로 강제
즉, 너무 큰 업데이트를 방지하면서도 좋은 방향의 업데이트는 유지하려는 구조
🔁 4. 전체 기대값:
→ 예전 policy로 생성한 데이터를 기반으로 현재 policy를 안정적으로 개선함
✨ 한 줄 요약:
PPO는 이전 policy로 만든 데이터를 기반으로, 현재 policy가 "지나치게 변화하지 않으면서도 advantage를 잘 살릴 수 있도록" 안정적으로 업데이트되게끔 만든 목적 함수

특히 핵심은:
"Value Function 없이, 그룹 내 정규화를 통해 Advantage를 추정" 한다는 점
📌 핵심 아이디어 요약
| 항목 | PPO | GRPO |
|---|---|---|
| Advantage 계산 | Value Function + GAE로 추정 | 그룹 평균 대비 상대적인 보상으로 정규화 |
| Policy 업데이트 방식 | clipped objective | clipped + KL penalty |
| Value function 필요 | ✅ 필요 | ❌ 불필요 |
✅ 1. GRPO의 Advantage 계산 (식 4)
- : 하나의 질문 에 대해 생성된 복수 개의 응답 개수
- : i번째 응답의 보상
- / : 그룹 전체 보상의 평균과 표준편차
🎯 의미:
- 개별 응답 가 그룹 평균 대비 얼마나 더 좋은지/나쁜지를 표준편차 기준으로 정규화
- → 즉, 그룹 안에서 상대적으로 좋은 응답을 강조하고 나쁜 응답은 억제
✅ 2. GRPO의 목적 함수 (식 5)
구성요소 해석:
| 구성 | 의미 |
|---|---|
| 예전 정책 대비 현재 정책이 를 얼마나 더 선호하는지 | |
| 그룹 정규화된 advantage (그룹 내 보상 비교) | |
| clip, min | PPO처럼 policy update를 안정화 |
| $D{KL}(\pi\theta | \pi_{\text{ref}})$ | 현재 정책과 기준 정책의 KL 거리 → divergence penalty |
✅ 3. GRPO는 결국 뭐가 다르냐?
| 특징 | PPO | GRPO |
|---|---|---|
| Advantage | GAE 사용 (value function 필요) | 그룹 내 상대적 보상 정규화 (value function 없음) |
| Update 단위 | 시퀀스 내 모든 토큰 | 각 응답 단위에서 평균 |
| KL Penalty | 선택적으로 사용 | KL을 명시적으로 포함시킴 |
| 장점 | Value-based learning 가능 | Value 없이도 작동 가능, 상대 평가 기반 |
🔍 정리 한 줄
GRPO는 Value Function 없이 하나의 질문에 대한 여러 응답 간 상대적 비교로 Advantage를 추정하고, PPO 스타일의 클립 + KL penalty를 결합한 정책 최적화 방법
본격적으로 DAPO

하지만 ✅ DAPO는 단순히 GRPO - KL 이 아니라, 구조적으로 두 가지 차별점
✅ DAPO vs GRPO — 정확한 차이점 요약
| 항목 | GRPO | DAPO |
|---|---|---|
| ✅ KL Term | 있음 | ❌ 없음 |
| ✅ Clipping 범위 | 대칭: | 비대칭: |
| ✅ Equivalent filtering | ❌ 없음 | ✅ 정답과 유사한 응답 제외 |
| ✅ 목적 | 기준 정책과 가까운 fine-tuning | 다양한 답변 학습 가능 (alignment보다는 general reward-maximization) |
📌 수식 기반 차이 분석
✅ (1) 목적 함수 구조 유사
→ GRPO와 거의 똑같지만:
✅ (2) 클리핑 범위가 비대칭
GRPO는:
DAPO는:
왜?
- 모델이 좋은 응답을 더 과감히 강화하고, 나쁜 응답은 더 부드럽게 억제하도록 설계
- reward-maximization 관점에서 더 유연한 정책 업데이트 가능
✅ (3) Filtering 조건 추가됨
조건:
→ 즉, 정답 와 거의 똑같은 응답 들은 학습에서 제외시킴
왜?
- 모델이 정답과 거의 똑같은 응답만 반복해서 학습하는 걸 방지
- 다양한 표현의 응답을 학습시키기 위함 (diversity 학습)
✨ DAPO는 결국 뭘 위한 거냐?
RLHF에서 모델이 너무 정답에만 수렴하는 문제를 피하고,
더 자유롭고 다양한 정답 표현을 생성하도록 하기 위해 설계된 방식이야.
🔁 정리 한 줄 요약
DAPO는 GRPO에서 KL을 제거하고,
비대칭 클리핑 + 정답 유사 응답 필터링을 추가해서
모델이 정답에만 고정되지 않고 더 다양한 high-reward 응답을 생성하도록 유도하는 구조야.

🔁 전체 알고리즘 설명 (너가 말한 흐름 기준으로 정리)
🧮 알고리즘 개요: DAPO - Decoupled Clip and Dynamic sAmpling Policy Optimization
✅ 1. M번 반복 (큰 학습 루프)
for step = 1 to M:✅ 2. 샘플링 수행
-라는 프롬프트 배치(batch)를 샘플링
- 각 프롬프트 에 대해 이전 정책 로 개의 응답 생성
Sample G outputs {o_i} from π_old(·|q)✅ 3. 각 응답 ( o_i )에 대해 reward 계산 (R로 평가)
Compute rewards {r_i}✅ 4. Dynamic Sampling
- 정답률이 0 (전부 틀림) 또는 1 (전부 맞음) 인 응답은 제외
- 나머지만 buffer에 저장
Filter out o_i with acc=0 or acc=1 → buffer에 저장✅ 5. 만약 buffer 크기 ( n_b )가 N보다 작으면 → 학습 skip, 다음 step으로
if buffer size < N: continue✅ 6. buffer가 충분히 찼으면 → Advantage ( \hat{A}_{i,t} ) 계산
- 각 응답 ( oi )의 각 토큰 ( t ) 에 대해
group-normalized advantage ( \hat{A}{i,t} ) 계산 (Equation 9)
For each o_i in buffer, compute A_i,t✅ 7. ( \mu )번 반복하면서 policy 모델 업데이트
- token-level policy gradient 기반 DAPO objective (Equation 8) 사용
for iteration = 1 to μ:
Update π_θ using DAPO objective✅ 최종 출력: 업데이트된 policy ( \pi_\theta )
🧠 요약 구조 (네가 말한 표현 정제해서 다시)
- 학습은 M번 반복됩니다.
- 각 반복에서 프롬프트를 샘플링하고, 그에 대한 응답 ( oi )를 ( \pi{\text{old}} )로 생성합니다.
- 생성된 응답 중 정답률이 0 또는 1인 것은 제외하고, 나머지를 buffer에 저장합니다.
- buffer에 유효한 샘플이 N개 이상 쌓이면 학습을 시작합니다.
- 각 응답의 각 토큰에 대해 advantage ( \hat{A}_{i,t} )를 계산하고,
- ( \mu )번 반복하면서 DAPO objective를 사용해 policy ( \pi_\theta )를 업데이트합니다.
- 이 과정을 총 M번 반복합니다.
연구자들 재현 노하우
여기서 저자들은 RL학습은 매우 민감한 것이므로 metric을 꾸준히 살펴보는게 중요하다고 충고함. 여기 4가지 지표있음
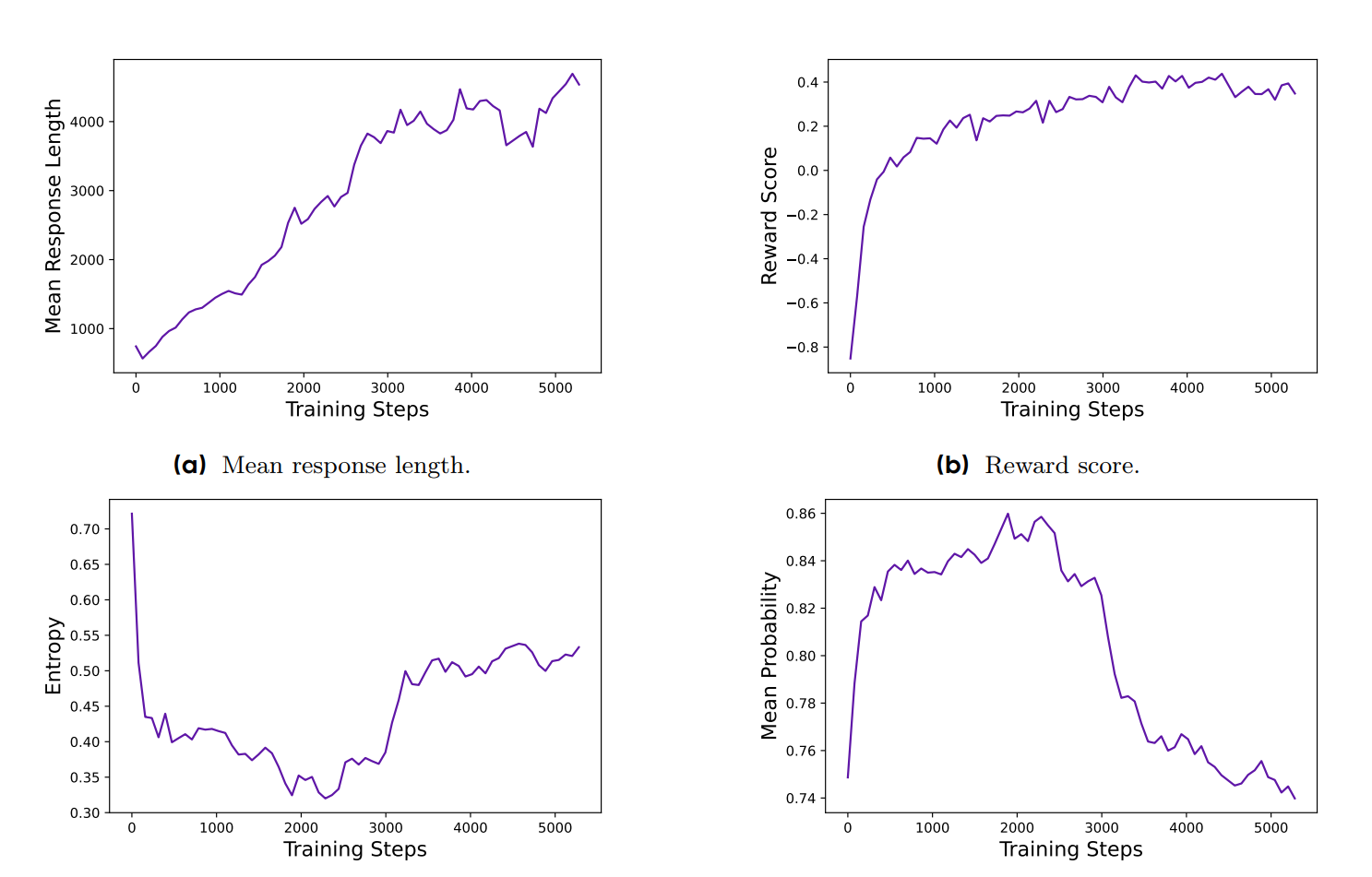
🧠 전체적인 메시지 요약
Reinforcement Learning with LLM은 단순한 알고리즘 문제가 아니라,
매우 복잡한 시스템 엔지니어링 문제다.
사소한 설정 하나(데이터, 하이퍼파라미터)가 전체 흐름을 바꿔버릴 수 있다.
그래서 학습 중 중간 지표들을 꾸준히 모니터링하지 않으면,
“왜 잘 안 되는지” 절대 파악 못 한다.
📌 그래서 어떤 걸 모니터링하라고?
DAPO 논문은 다음 4가지 핵심 지표를 추천해:
1️⃣ 📏 Mean Response Length
응답 길이는 학습 안정성 + 복잡한 reasoning 가능성과 관련됨.
- 길이가 점점 길어진다 → 모델이 더 복잡한 생각을 표현할 수 있게 된다는 신호
- 하지만 일정 구간에선 정체되거나 감소할 수도 있음 → 학습 문제 가능성
- 👉 길이 + 정확도(accuracy)를 함께 보면 실험이 “망해가는 중”인지 판단 가능
2️⃣ 💰 Reward Score
훈련 보상의 평균도 중요한 지표지만…
검증 정확도(val acc)와 상관이 별로 없다 → 오버피팅 가능성!
- reward가 잘 오르면 학습은 잘 되는 듯 보이지만,
- 실제로는 train set에만 맞춰져 있을 수도 있음
- 👉 reward ↑ 이라고 해서 항상 성능 ↑ 는 아님
3️⃣ 🎲 Generation Entropy
탐색 능력과 관련된 대표 지표
- 너무 낮다 (entropy ↓) → 확률 분포가 너무 뾰족함, 탐색 못하고 같은 말 반복
- 너무 높다 (entropy ↑) → 헛소리(gibberish), 반복, 품질 저하
- 👉 적절한 수준의 entropy 유지 필요 (너무 낮지도 높지도 않게)
4️⃣ 📊 Mean Probability (of generation)
entropy와 반대되는 관점에서 보는 확률 분포의 평균
- 높다 → 자주 나오는 토큰에 확신이 강해짐
- 낮다 → 분산되어 있음
- Clip-Higher 전략 덕분에 entropy 붕괴 문제 해결함
- 실험적으로, entropy가 천천히 오르는 게 좋다고 확인됨
✅ 실전에서 재현하려면?
| 지표 | 목적 | 주의점 |
|---|---|---|
| 응답 길이 | reasoning 가능성 | 정체되면 문제 발생 신호 |
| reward | 학습 진척 확인 | 검증 성능과는 별개 (오버피팅 주의) |
| entropy | 탐색-수렴 밸런스 | 너무 낮으면 반복, 너무 높으면 헛소리 |
| mean prob | 확률 sharpness | Clip-Higher로 안정적 조절 가능 |
🔁 한 줄 요약
이 섹션은 "DAPO 실험 재현하려면 뭐부터 보고 감지해야 하는지 알려주는 연구자용 가이드"다.
LLM RL 학습은 아주 민감하므로, 길이·보상·엔트로피·확률 분포 같은 중간지표를 지속적으로 모니터링해야
어디서 꼬였는지를 빠르게 감지하고 수정할 수 있다.
