0. 글 쓰기에 앞서
(1) 자연어처리 발전과정
<기본적인 자연어 처리 발전과정부터 개략적으로 다루고자 한다.>
자연어처리란, 컴퓨터가 자연어를 이해하거나 생성하는 일련의 처리과정을 의미한다. 즉 "컴퓨터"가 자연어라는 "고급언어"를 이해하고 생성하는 과정 모두를 말하는 것이다.
2013년 전에는 통계기반방법으로 번역을 하였는데, 이는 의사결정나무 또는 확률모형과 같은 통계모형을 대규모 말뭉치 분석에 적용한 것이었다. 하지만 이는 번역문서의 양에 따라서 성과가 제각각이었다.
1. Word2Vec
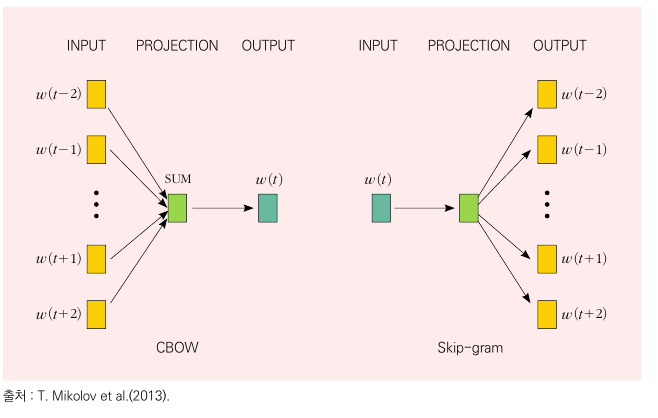
정의: 자연어를 학습하여 단어를 숫자 벡터들로 분산 표현하는 방법이다. 즉, 원-핫 인코딩으로 희소하게 표현된 고차원 단어군을 신경망을 통해 주성분분석(PCA)와 같이 저차원의 의미가 포함된 밀집 벡터로 다시 표현하는 것이다. ->이를 통해 단어들 간 얼마나 유사한지를 Consine 유사도를 통해 표현가능하다.
학습방법:
-
CBOW(Continuous Bag-of-Words) : 주변 단어로부터 중심단어 예측
-> 학습을 통해 FC 가중치를 구하는데 이 가중치 행렬의 각 행이 단어의 분산표현이다. -
Skip-Gram : 중앙단어로부터 주변단어 예측(https://ronxin.github.io/wevi/ <- 여기서 시뮬레이션가능)
2. Seq2Seq 모형
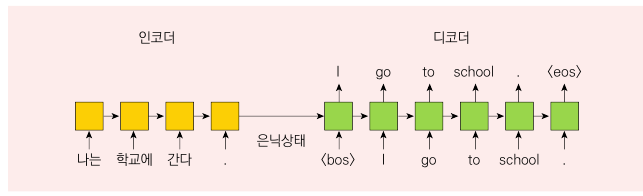
정의: 인코더와 디코더라는 2개의 순환신경망을 이어 붙인 신경망이다.
학습방법:입력문장을 순환신경망(RNN)의 은닉상태를 통해 문장의 내용을 압축한 맥락벡터(context vector) 로 인코딩(encoding)한 후, 맥락 벡터를 디코더(decoder) 의 입력으로 사용해서 순차적으로 출력 문장을 생성한다. => 즉, Seq2Seq모형에서는 인코더에서 순차적으로 읽은 중간 단계의 은닉상태 값은 사용되지 않고, 맥락 벡터인 최종 은닉상태만 디코더에 전달한다.
제약
① 최종 은닉상태만으로 입력데이터 전체 문장을 대표하기 어렵다.
② Seq2Seq 모형은 순환신경망으로 만들어지므로 문장의 길이가 길어질수록 경사손실 또는 경사폭발의 문제가 생긴다.
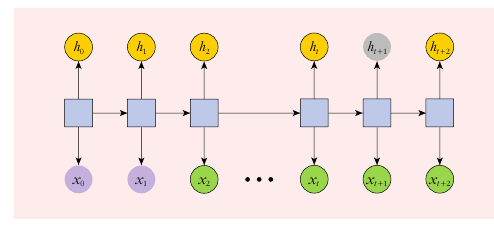
③ Seq2Seq 모형은 같은 단어라도 위치와 상황에 따라서 의미가 달라지는 언어의 특성을 반영하기 어렵다.
--위 제약을 극보하기 위해 Transformer 모형이 탄생했따!!--
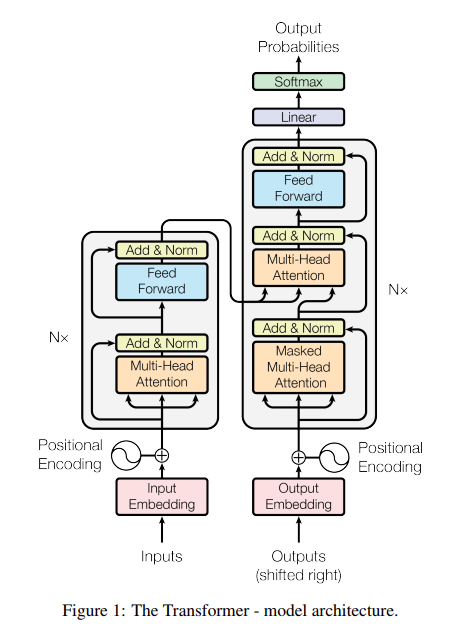
3. Attention 모형을 이제 Transformer 라는 논문을 통해서 알아보잣! (참고로, 이렇게 네모에 있는 것은 논문에 있는 내용을 그대로 차용한 것이다)
1. Introduction
(1-0). Seq2Seq 한계
This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples
=> 논문에서는 병렬학습을 막는 본질적인 문제점이 Seq2Seq에 있다고 봤음.
(1-1).Transformer 제안
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in
translation quality after being trained for as little as twelve hours on eight P100 GPUs.
=> Transformer의 핵심은 2가지다.
① 순환(Recurrence)를 피하고
② Attention 매커니즘에만 의존하여 입력과 출력 간의 전역적 종속성을 도출하는 모델 아키텍쳐.
2. BackGround
(2-0). 문제상황
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU, ByteNet and ConvS2S , all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions
=> Sequntial 의 컴퓨테이션을 줄일려는 노력을 CNN,RNN등을 이용해서 할려고 노력했음.
(2-1). Trasnformer 를 사용하는 이유
In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
-> 트랜스포머가 연산을 줄이게 하지만 해상도가 감소하는 대가를 치름. 하지만 이는 멀티헤드어텐션 으로 보완됨.
이제 Model Architecture에서 어떻게 감소하는지 살펴보자.
3. Model Architecture
3.0 Encoder and Decoder Stacks
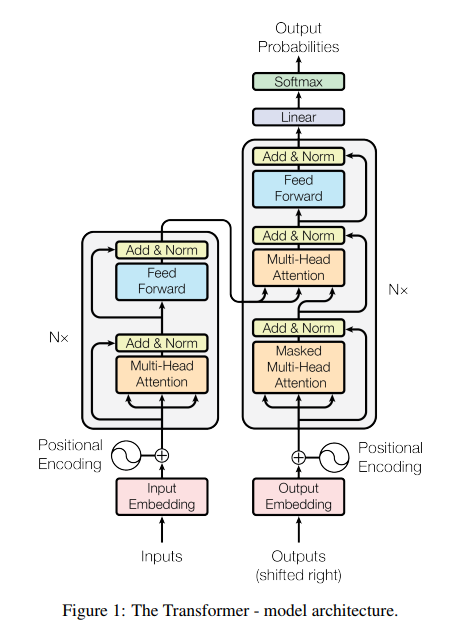
the encoder maps an input sequence of symbol representations (x1, ..., xn) to a sequence of continuous representations z = (z1, ..., zn).
Given z, the decoder then generates an output sequence (y1, ..., ym) of symbols one element at a time. At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next
여기서 무조건 알아야 할 개념은 3가지임
① 인코더는, represetation -> z-continuous vector 로 변환
② 디코더는, z-continuous -> output y vector 을 반환
③ 모델은 자기회귀(AutoRegressive)적이라고 Xt번째가 X(t-1)번째의 생성물을 참조함.
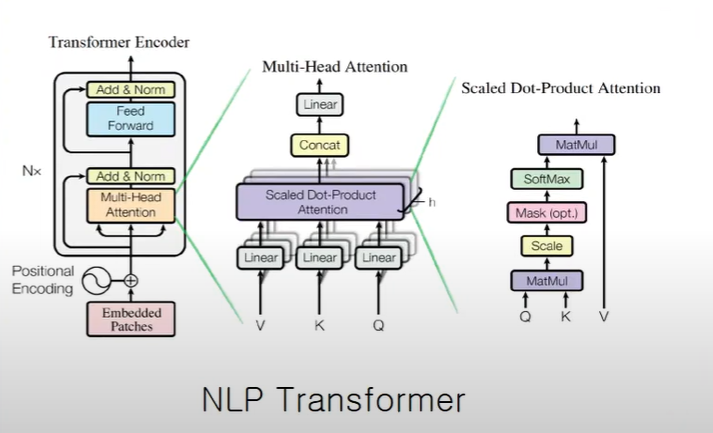
3.1 Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output,where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
- 어텐션은 query 와 {key,value} 값의 output 으로 설명할 수 있음.
output은 가중치들의 합으로 결정되는데 이 가중치들은 query와 key의 호환성 함수에 의해서 결정됨!!
=> 즉, 쿼리(query)는 검색할 질문 또는 요청, 키(key)는 검색할 항목의 식별자, 값(value)는 각 키와 관련된 실제 데이터임.
==> 비유로 하자면,쿼리로 "어떤 영화 추천?" 했을때 키는 데이터베이스의 영화 목록이고 값은 각 영화의 실제 정보임.즉 키는 인덱스 역할을 하는 것!
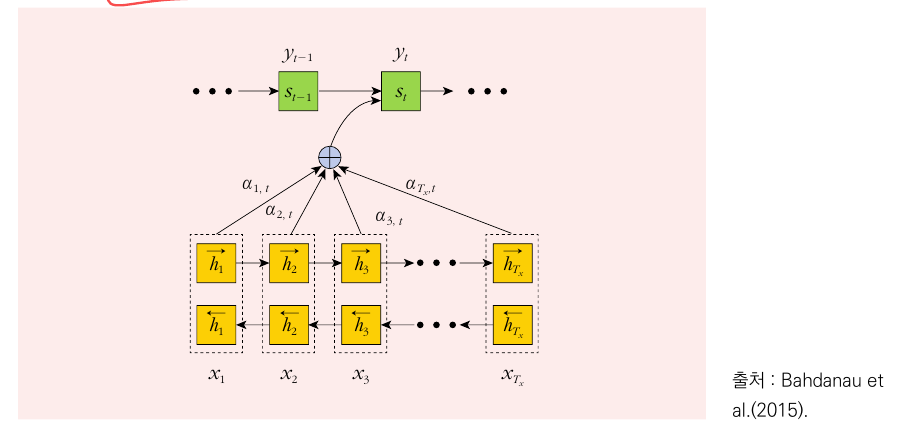
논문에는 없는 Attention에 관한 내용 추가
어텐션은 로 출력문장의 번째 토큰 를 생성할 때 입력 시퀀스의 모든 토큰이 만들어내는 은닉상태를 결합하여 만든다. 즉, 를 가중치로 한 은닉상태의 가중합(혹은 평균)으로 번째 토큰을 위한 맥락 벡터를 만든다.
여기서 는 입력 어텐션() 시점 에서의 은닉층 값이다.
는 소프트맥스 함수를 적용하며 구하며, 번째 토근이 출력 어텐션의 번째 토큰에 미치는 기여도를 의미한다.
어텐션의 구조
3.1.0 Scaled Dot-Product Attention
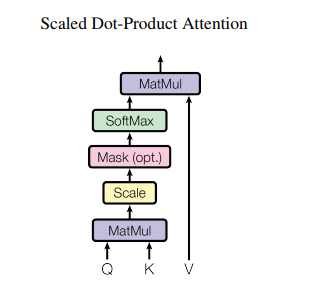
We compute the dot products of the query with all keys, divide each by √dk, and apply a softmax function to obtain the weights on the values.
We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients . To counteract this effect, we scale the dot products by √dk.(스케일조정)
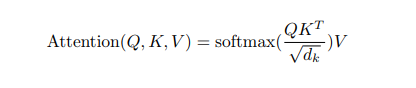
3.1.1 Multi-Head Attention
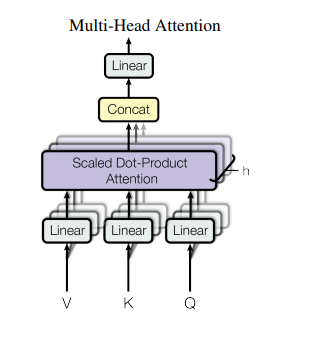
Instead of performing a single attention function with dimensional keys, values and queries,
we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to , and dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding dv-dimensional output values. These are concatenated and once again projected, resulting in the final values
✍
① 멀티헤드란, 어테션 메커니즘을 여러 번 적용시키는 것을 의미
② 멀티-헤드 어텐션은, ,, 라는 입력을 완전연결된 밀집층을 통과시키고 난 후의 결과물을 노드의 입력으로 사용
③ =512인 상황에서 = 8개의 헤드를 사용하면 어텐션을 적용한다면, 512 의 행렬을 64 개의 행렬로 쪼갠 후에 각각 어텐션을 적용함.
④이후 8개의 어텐션 헤드를 통과한 결과물을 이어붙이면 512 의 행렬을 얻으면 이 행렬에 다시 512 512 차원의 완전연결된 밀집신경망을 적용시켜서 멀티-헤드 어텐션의 출력이 완성된다.
3.1.2 Application of Attention in our Model
①In "encoder-decoder attention" layers, the queries come from the previous decoder layer,and the memory keys and values come from the output of the encoder
②The encoder contains self-attention layers
③self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position
이렇게 3가지 경우가 기존의 모델과 다르다고 한다.(별로 중요하지 않으니 넘어가자)
3.2 Position-wise Feed-Forward Networks
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between
각 위치별 피드포워드 네트워크는 인코더와 디코더의 각 레이어에 포함된 요소로, 각 위치에 대해 동일한 방식으로 처리된다. 이 네트워크는 두 번의 선형 변환(즉, 매트릭스 곱)과 그 사이에 ReLU라는 활성화 함수를 사용한다.
3.3 Embeddings and Softmax
3.3.0) Embedding
we use learned embeddings to convert the input
tokens and output tokens to vectors of dimension .
3.3.1) Softmax
We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities
3.4 Positional Encoding
3.4.0) Positional Encoding 이란?
:= 문장에 각 토큰의 위치를 ㅏ나타내주는 정보를 임베딩에 더하는 것.
3.4.1) 필요한 이유
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence
👉 Transformer 는 recurrence, cnn을 전혀 쓰지 않기 때문에 시퀀스의 토큰에 상대적인(relative) 또는 절대적인(absolute) 토큰의 위치를 삽입해주어야 함!
3.4.2) 구체적 수식
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset , can be represented as a linear function of
왜 model 이 더 쉽게 배우는지 솔직히 이해 안감.
4. Why Self-Attention?
(4.0) Self-Attention이란?
Self-Attention은 같은 문장의 다른 표현인 ,,를 스케일드 닷-프로덕트 어텐션을 통해 결합하여, 문장 내 토큰 간 문법 및 의미적 관계를 찾는것. 따라서 Self-Attention을 통해서 출력 시퀀스의 특정 토큰이 입력 시퀀스 중에 어떤 부분과 연관성이 높은가를 자체 문장 속에서 파악할 수 있다.
(4.1) 왜 쓰는가?(Self-Attention이점)
One is the total computational complexity per layer.
Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
The third is the path length between long-range dependencies in the network
_
As side benefit, self-attention could yield more interpretable models
5. Model Variation
-생략-
6. Concolusion
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with
multi-headed self-attention
_
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers
👉 결론: 우리가 Attention 만을 이용한 모델을 만들었는데 이걸 Transformer 라고 명명할 것이고 그전의 CNN,RNN 같은 모델보다 더 잘났다!
: ㅇㅈ.
