서비스의 전체적인 상황들을 한눈에 파악하고 문제가 발생한 경우, 즉각적으로 트래킹 및 처리할 수 있도록 하는 것을 모니터링 한다 라고 한다.
모니터링 툴에는 여러가지가 있다.
- sentry
- datadog
- grafana
- etc...
이번에는 grafana 에 대해서 얘기를 해보려고 한다.
회사에서 아직 모니터링 대시보드 역할을 할 수 있는 것이 없었기 때문에,
이를 구축하기 위해서 prometheus + grafana stack 으로 대시보드를 구성한 경험에 대해서 기록하자.
어떤 것이 필요할까?
일단 모니터링이 필요한 경우 어떻게 해야할지에 대해서 생각을 해보자.
모니터링을 한다는 것은, 모니터링 대상에 대한 정보를 실시간으로 긁어오거나, 모니터링 대상이 본인의 정보를 실시간으로 제공을 해주거나 하는 방법으로 지속적으로 데이터를 긁어와야 한다.
그렇다면, 그 긁어오거나 제공을 해주는 툴이 있어야 한다.
긁어오는 툴을 찾아보니, prometheus 라는 툴이 있었다.
또한, 그런 데이터들을 수집하는 collector 중에 우리가 사용하는 것은 node_exporter, postgres_exporter, cadvisor, nestjs-prometheus 가 있다.
✅ collector 1 - node exporter
node exporter 는 하드웨어의 상태 및 정보와 커널관련 메트릭을 수집하는 collector 이다.
node exporter 를 통해 현재 하드웨어의 cpu 및 메모리 등 하드웨어의 정보를 수집할 수 있다.
how to install node exporter
-
download archive file
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.15.2/node_exporter-0.15.2.linux-amd64.tar.gz -
extract archive file
$ tar -xf node_exporter-0.15.2.linux-amd64.tar.gz -
move binary file to
/usr/local/bin
$ sudo mv node_exporter-0.15.2.linux-amd64/node_exporter /usr/local/bin -
create user only for node exporter
$ sudo useradd -rs /bin/false node_exporter -
make file that node exporter can be started at boot
$ sudo vim /etc/systemd/system/node_exporter.service[Unit] Description=Node Exporter After=network.target [Service] User=node_exporter Group=node_exporter Type=simple ExecStart=/usr/local/bin/node_exporter [Install] WantedBy=multi-user.target
how to start node exporter
$ sudo systemctl daemon-reload
$ sudo systemctl enable node_exporter
$ sudo systemctl start node_exporter
✅ collector 2 - postgres exporter
how to install postgres exporter
- make directory for postgres exporter
$ mkdir /opt/postgres_exporter && cd /opt/postgres_exporter - download archive file
% wget https://github.com/wrouesnel/postgres_exporter/releases/download/v0.5.1/postgres_exporter_v0.5.1_linux-amd64.tar.gz - extract archive file
tar -xzvf postgres_exporter_v0.5.1_linux-amd64.tar.gz - copy to
/usr/local/bin
$ cd postgres_exporter_v0.5.1_linux-amd64
$ sudo cp postgres_exporter /usr/local/bin
env file for postgres exporter
$ cd /opt/postgres_exporter
$ sudo vim postgres_exporter.env
특정 데이터베이스만 원하는 경우. database-name 치환
DATA_SOURCE_NAME="postgresql://username:password@localhost:5432/database-name?sslmode=disable"모든 데이터베이스
DATA_SOURCE_NAME="postgresql://postgres:postgres@localhost:5432/?sslmode=disable"setup postgres exporter user
- create user
$ sudo useradd -rs /bin/false postgres - make service file
$ sudo vim /etc/systemd/system/postgres_exporter.service[Unit] Description=Prometheus exporter for Postgresql Wants=network-online.target After=network-online.target [Service] User=postgres Group=postgres WorkingDirectory=/opt/postgres_exporter EnvironmentFile=/opt/postgres_exporter/postgres_exporter.env ExecStart=/usr/local/bin/postgres_exporter --web.listen-address=:9187 --web.telemetry-path=/metrics Restart=always [Install] WantedBy=multi-user.target
how to start prometheus exporter
$ sudo systemctl daemon-reload
$ sudo systemctl start postgres_exporter
$ sudo systemctl enable postgres_exporter
$ sudo systemctl status postgres_exporter
✅ collector 3 - cadvisor
cadvisor 는 docker, kubernetes 의 시계열 데이터를 수집하는 collector 이다. 각 container 들의 cpu, memory, network 사용량 등 리소스의 사용량 및 잔여량을 알 수 있다.
how to install cadvisor
$ sudo apt-get update
$ sudo apt-get -y install cadvisor
$ systemctl status cadvisor
✅ collector 4 - nestjs prometheus
node_exporter 에서는 실제 어플리케이션의 http request 및 response time 등을 핸들링하거나 추적하기에 적합하지 않은 데이터를 주고 있다보니, 실제 http request 및 response 를 다루기 위해 새로운 라이브러리가 필요했다.
이를 해결하기 위해서 node 라이브러리인, nestjs-prometheus 를 이용했다.
https://github.com/willsoto/nestjs-prometheus
위 링크를 타고 들어가면 어떻게 설치하고 어떻게 사용하는지 나와있는데...
이게 생각보다 어려웠다. 기본적으로 제공하는 metric 들에 대한 개념도 있어야 하고, 이를 우리가 운영하고 있는 코드에 녹이는 것도 어느정도 시행착오가 있었다. 그냥 단순하게 연동하는 것 보다 최대한 현재 운영되고 있는 서비스에 영향을 가지 않도록 개발하는것이 포인트다.
구현방법
우리는 모든 요청에 대해서 기존 request flow 를 방해하지 않기 위해, interceptor 를 이용해서 데이터를 가져오도록 구현했다.
-
우선 metric 모듈을 만들어주고, 모든 요청에 대해서 데이터를 수집하기 위해 gateway 모듈에 주입을 해준다.
// metrics.module.ts import { Global, Module } from '@nestjs/common'; import { makeCounterProvider, makeHistogramProvider, PrometheusModule as Prometheus, } from '@willsoto/nestjs-prometheus'; @Module({ imports: [ Prometheus.register({ path: '/metrics', defaultMetrics: { enabled: true, }, }), ], }) export class MetricsModule {}// gateway.module.ts @Module({ imports: [ MetricsModule, ], controllers: [GatewayController], providers: [GatewayService], }) export class GatewayModule { ... 이하 생략 } -
그 다음에 interceptor를 구현한다.
import { CallHandler, ExecutionContext, Injectable, NestInterceptor, OnModuleInit, } from '@nestjs/common'; import { Counter, Gauge, Histogram } from 'prom-client'; import { Observable, tap } from 'rxjs'; @Injectable() export class PrometheusInterceptor implements NestInterceptor, OnModuleInit { onModuleInit() { this.requestSuccessHistogram.reset(); this.requestFailHistogram.reset(); this.failureCounter.reset(); } // status code 2XX private readonly requestSuccessHistogram = new Histogram({ name: 'nestjs_success_requests', help: 'NestJs success requests - duration in seconds', labelNames: ['handler', 'controller', 'method'], buckets: [ 0.0001, 0.001, 0.005, 0.01, 0.025, 0.05, 0.075, 0.09, 0.1, 0.25, 0.5, 1, 2.5, 5, 10, ], }); // status code != 2XX private readonly requestFailHistogram = new Histogram({ name: 'nestjs_fail_requests', help: 'NestJs fail requests - duration in seconds', labelNames: ['handler', 'controller', 'method'], buckets: [ 0.0001, 0.001, 0.005, 0.01, 0.025, 0.05, 0.075, 0.09, 0.1, 0.25, 0.5, 1, 2.5, 5, 10, ], }); private readonly failureCounter = new Counter({ name: 'nestjs_requests_failed_count', help: 'NestJs requests that failed', labelNames: ['handler', 'controller', 'error', 'method'], }); static registerServiceInfo(serviceInfo: { domain: string; name: string; version: string; }): PrometheusInterceptor { new Gauge({ name: 'nestjs_info', help: 'NestJs service version info', labelNames: ['domain', 'name', 'version'], }).set( { domain: serviceInfo.domain, name: `${serviceInfo.domain}.${serviceInfo.name}`, version: serviceInfo.version, }, 1, ); return new PrometheusInterceptor(); } // metrics url 요청은 트래킹 필요 x private isAvailableMetricsUrl(url: string): boolean { const excludePaths = 'metrics'; if (url.includes(excludePaths)) { return false; } return true; } intercept(context: ExecutionContext, next: CallHandler): Observable<any> { const originUrl = context.switchToHttp().getRequest().url.toString(); const method = context.switchToHttp().getRequest().method.toString(); const labels = { controller: context.getClass().name, handler: context.getHandler().name, method: method, }; try { const requestSuccessTimer = this.requestSuccessHistogram.startTimer(labels); const requestFailTimer = this.requestFailHistogram.startTimer(labels); return next.handle().pipe( tap({ next: () => { if (this.isAvailableMetricsUrl(originUrl)) { requestSuccessTimer(); } // Handle the next event here }, error: () => { if (this.isAvailableMetricsUrl(originUrl)) { requestFailTimer(); this.failureCounter.labels({ ...labels }).inc(1); } // Handle the error event here }, }), ); } catch (error) {} } }위 코드에서 보듯이,
우선적으로 요청데이터를 저장할 histogram을 선언한다.Histogram class에서 제공하는startTimer()함수가 모든 요청에 있어서 정보를 긁어올 수 있다.
- 요청의 response 가 성공하면
requestSuccessTimer()를 통해requestSuccessHistogram Histogram에 정보를 저장하고, - 요청의 response 가 실패하면
requestFailTimer()를 통해
requestFailHistogram Histogram에 정보를 저장한다.
또한,failureCounter.labels({ ...labels }).inc(1);를 통해 실패 횟수를 1씩 증가시킬 수 있다. - 해당 모듈이 실행될 때 마다 histogram 을 리셋해줌으로서(
onModuleInit()), 메모리 용량을 관리해준다.
-
main.ts 에 interceptor 를 등록해준다.
// main.ts async function bootstrap(): Promise<void> { const app = await NestFactory.create(GatewayModule); app.enableCors({ origin: '*', methods: '*', allowedHeaders: '*', }); app.useGlobalInterceptors(new ResponseInterceptor()); app.useGlobalInterceptors(new PrometheusInterceptor()); await app.listen(3000); } bootstrap(); -
response interceptor 에서 메트릭 정보를 가공하지 않고 그대로 반환해주기 위해 조건을 추가한다.
서비스내에서 클라이언트와 약속한 표준 응답으로 메트릭을 제공하면 데이터를 바인딩하는데 있어서 에러가 났다. 그래서 이를 약속한 response format 이 아닌 메트릭을 수집할 수 있도록raw 형태 그대로반환을 해줘야 한다.
혹시 response format 을 사용하고 있다면 메트릭 수집을 위해서는 꼭 약속된 format 을 이용하지 않고, 반환할 수 있도록!!!// response.interceptor.ts @Injectable() export class ResponseInterceptor implements NestInterceptor { intercept(_context: ExecutionContext, next: CallHandler) { const req: Request = _context.switchToHttp().getRequest(); const excludePaths = ['/api/capa-metrics', '/capa-metrics']; return next .handle() .pipe(defaultIfEmpty(null)) .pipe( map((result) => { if (excludePaths.includes(req.url)) { return result; } // CAPA4.0 표준 응답으로 변환하여 반환 return new ResponseObj(true, result); }), ); } }
결과 확인
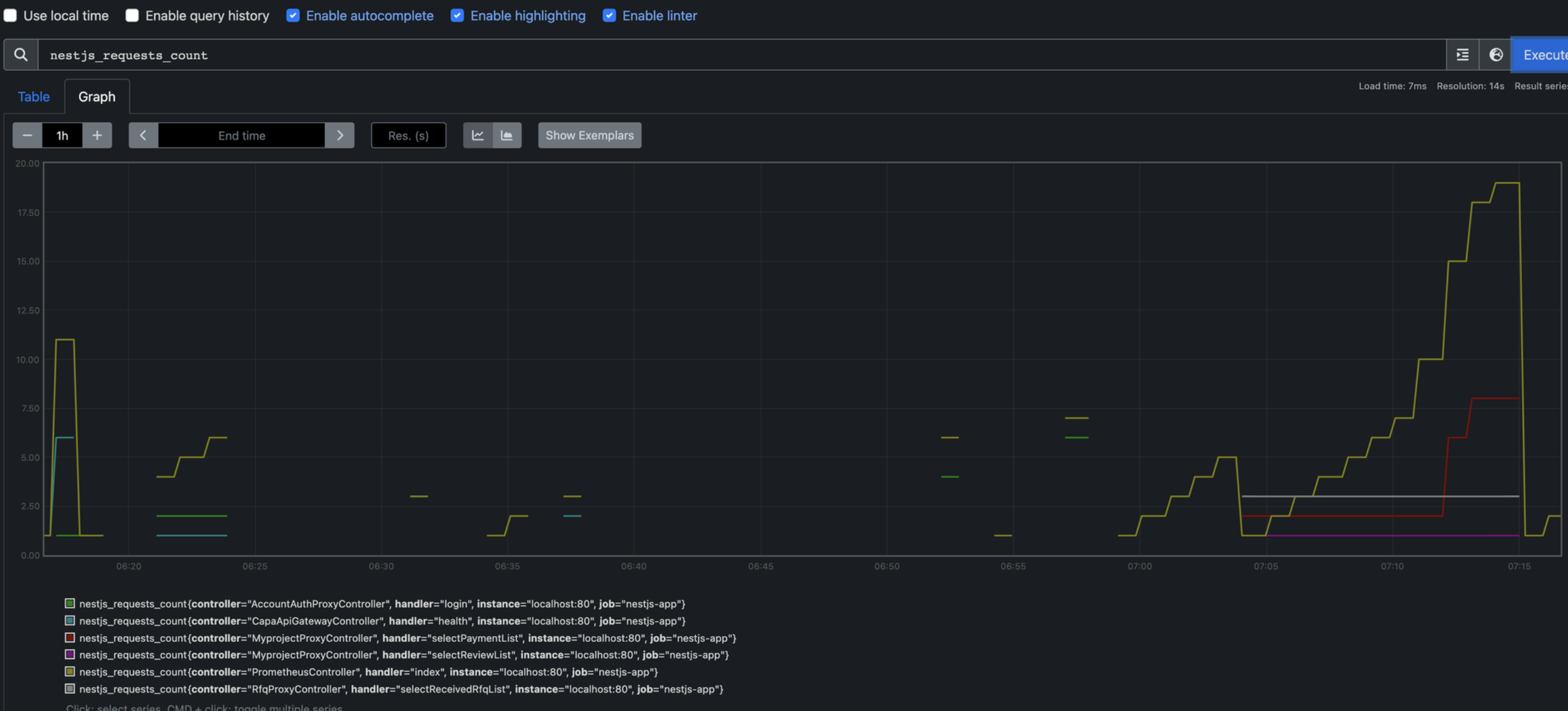
다음과 같이 어떤 요청이 어떻게 들어오고 있는지 확인할 수 있다.
자 이제 이 collector 들을 한군데 모으기 위해 prometheus 를 이용해보자.
✅ prometheus
prometheus 는 SoundCloud 에서 만든 오픈소스 모니터링 툴이다.
prometheus 의 구조는 다음과 같다.
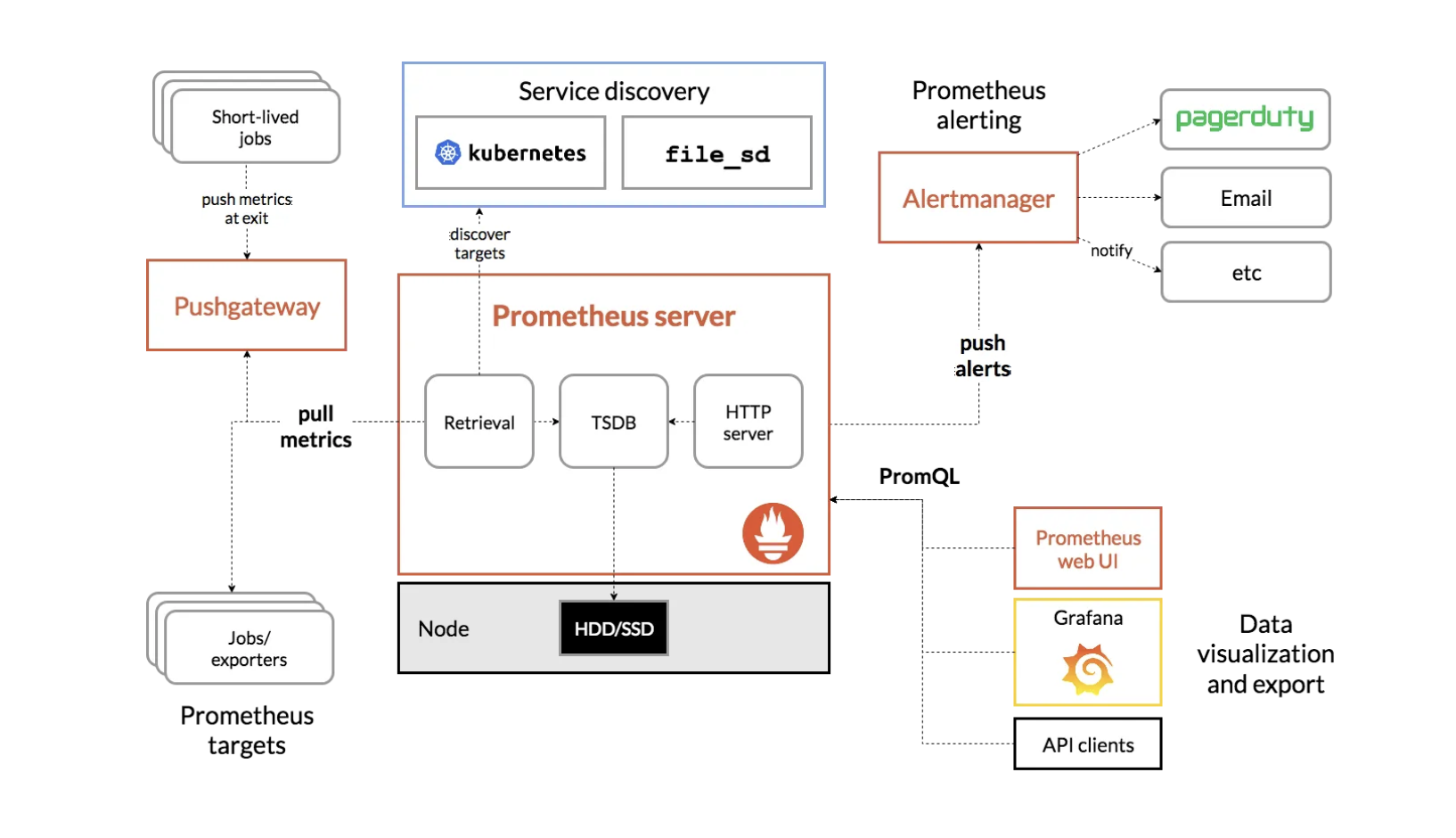
jobs/exporter 가 실제로 메트릭을 수집하고 이를 prometheus server 가 해당 메트릭 정보를 pull 을 통해서 가져온다.
해당 메트릭 정보는 각 모니터링 대상의 수집기로 부터 긁어오는데, 그 때 이제 http endpoint port 를 통해서 데이터를 가져온다.
모니터링 수집기의 예로는 node_exporter, cadvisor, postgres_exporter 이 있다.
또한, prometheus 에서 취급하는 메트릭 데이터는 전부 time series data 들로, 이러한 시계열 매트릭 데이터를 수집하고 저장하는 데이터베이스 역할도 한다.
그리고 오른쪽에 보면 Alertmanager 와 Grafana 가 있다.
Alertmanager 는 수집한 메트릭 정보가 어떠한 alert rule 에 위배가 되는 경우, email, teams, slack 으로 알림을 보낼 수 있는 기능이다.
Grafana 는 수집한 메트릭 정보를 시각화 해줄 수 있는 visual dashboard 역할을 한다.
우리는 prometheus 에서 수집한 메트릭 정보를 grafana 에서 시각화하는 방법으로 모니터링을 구축했다. 약간 elasticSearch & Kibana 같은 관계로 생각하면 된다.
prometheus install
-
download prometheus archive file
$ wget https://github.com/prometheus/prometheus/releases/download/v2.1.0/prometheus-2.1.0.linux-amd64.tar.gz -
extract from archieve file
$ tar -xf prometheus-2.1.0.linux-amd64.tar.gz -
move binary file to
/usr/local/bin
$ sudo mv prometheus-2.1.0.linux-amd64/prometheus prometheus-2.1.0.linux-amd64/promtool /usr/local/bin -
make configuration file
$ sudo mkdir /etc/prometheus /var/lib/prometheus
$ sudo mv prometheus-2.1.0.linux-amd64/consoles prometheus-2.1.0.linux-amd64/console_libraries /etc/prometheus -
delete useless file
$ rm -r prometheus-2.1.0.linux-amd64*
prometheus configuration file
global:
scrape_interval: 10s
scrape_configs:
- job_name: 'prometheus_metrics'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter_B/E'
scrape_interval: 5s
static_configs:
- targets: ['xx:9100', 'xx:9100', 'xx:9100']
- job_name: 'node_exporter_F/E'
scrape_interval: 5s
static_configs:
- targets: ['xx:9100', 'xx:9100']
- job_name: 'postgres_exporter'
static_configs:
- targets: ['localhost:9187']
- job_name: 'container_B/E'
scrape_interval: 10s
static_configs:
- targets: ['xx:8080', 'xx:8080', 'xx:8080']
- job_name: 'container_F/E'
scrape_interval: 10s
static_configs:
- targets: ['xx:8080', 'xx:8080']
- job_name: 'nestjs-app'
scrape_interval: 10s
metrics_path: /api/capa-metrics
static_configs:
- targets: ['xx:3000', 'xx:3000']prometheus 설정파일을 보면, 각 collector 들의 할당된 port를 통해 긁어오게 세팅을 해줘야 한다.
* XX 로 되어 있는 host 는 실제 Frontend, Backend ec2 instance IP 이다
✅ grafana dashboard
grafana의 대시보드 datasource 를 prometheus 혹은 postgresql 와 연결하면 수집한 메트익 정보를 다음과 같이 시각화하여 대시보드를 구성할 수 있다.
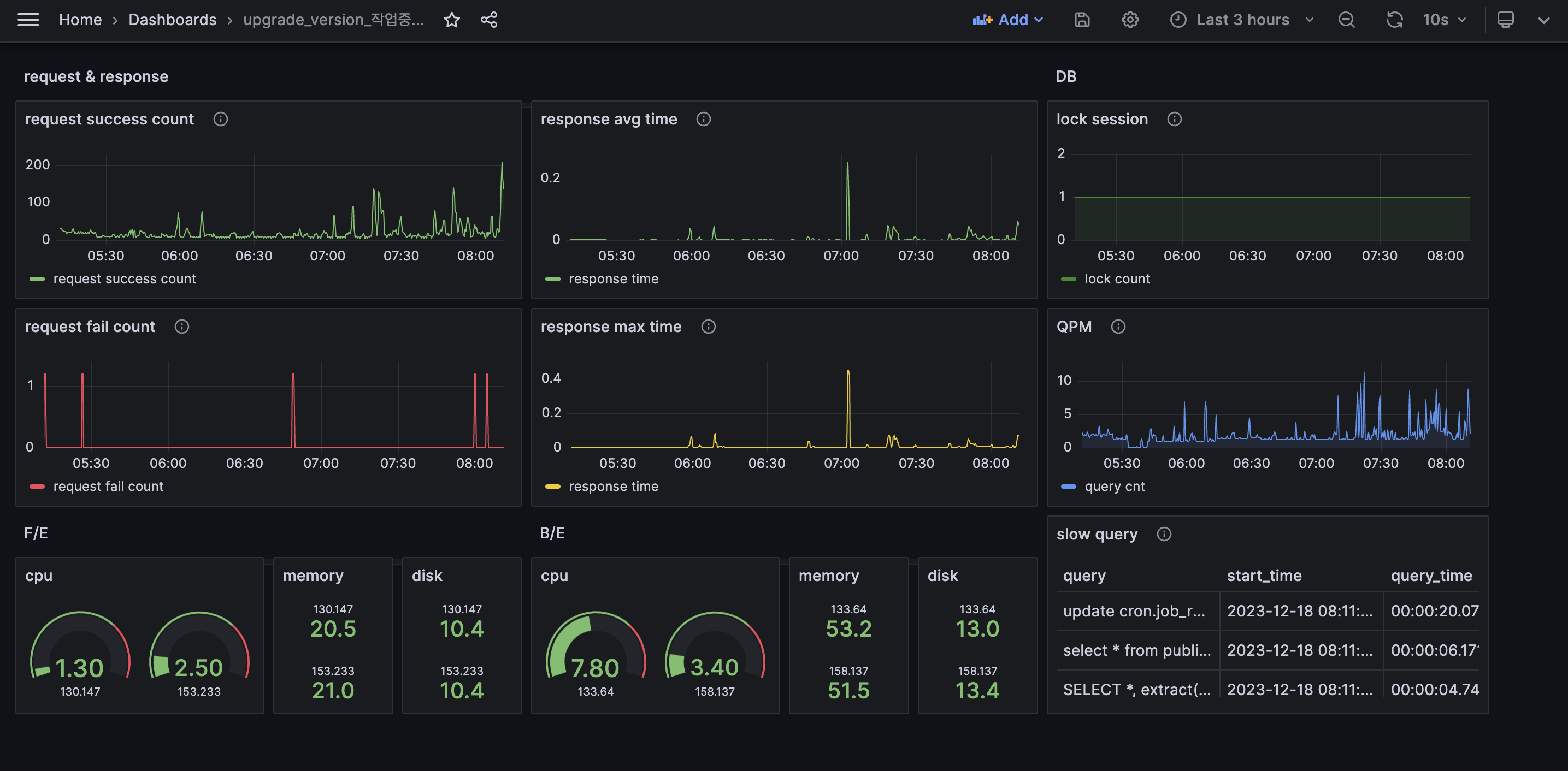
collector 들로 수집한 메트릭 데이터를 prometheus 를 이용해서 grafana 에서 시각화 하려면 promql(prometheus query) 를 알아야 한다.
일반적으로 rdbms 혹은 nosql 에서 사용하는 언어와는 결이 다르기 때문에 따로 공부를 해야한다.
promql 공식 문서
대시보드를 구성하는 방법은 여기서는 따로 언급하지는 않겠다.
대시보드 구성방법
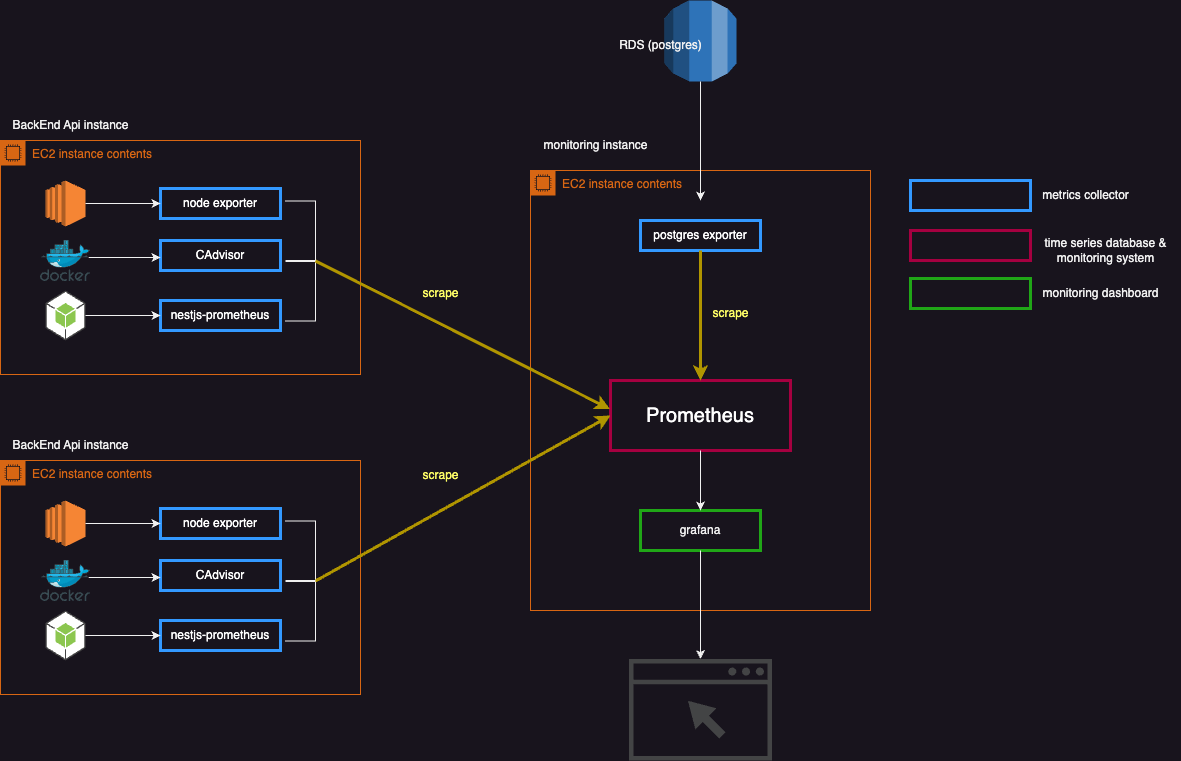
Architecture
대시보드 파이프라인을 구축한 전체적인 아키텍처이다.
Ref
https://medium.com/devops-dudes/install-prometheus-on-ubuntu-18-04-a51602c6256b
https://schh.medium.com/monitoring-postgresql-databases-using-postgres-exporter-along-with-prometheus-and-grafana-1d68209ca687
https://github.com/willsoto/nestjs-prometheus
https://github.com/raphaabreu/nestjs-prometheus-requests/blob/main/src/prometheus.interceptor.ts

안녕하세요, 질문이 있어서 댓글 남깁니다.
OnModuleInit을 통해 메모리를 관리하신다고 했는데, OnModuleInit은 부트스트래핑 단계에서 최최 실행되는 것으로 알고있습니다. 애플리케이션이 재시작될 경우 메모리 영역은 초기화되어 사용하신 히스토그램이나 카운트들이 전부 초기화될 것 같은데, reset()을 명시적으로 호출하신 이유가 있을까요?