ec2 intance(linux) 를 사용하면서 elasticsearch 혹은, prometheus 등 APM(Application Performance Management) 를 위한 서비스를 이용하게 되면 인스턴스 내부에 자체적으로 로그가 쌓이길 마련이다.
회사에서도 elasticsearch 와 prometheus 를 사용하면서 엄청나게 로그가 많이 쌓여서 kibana 가 정상적으로 기능을 못하는 바람에
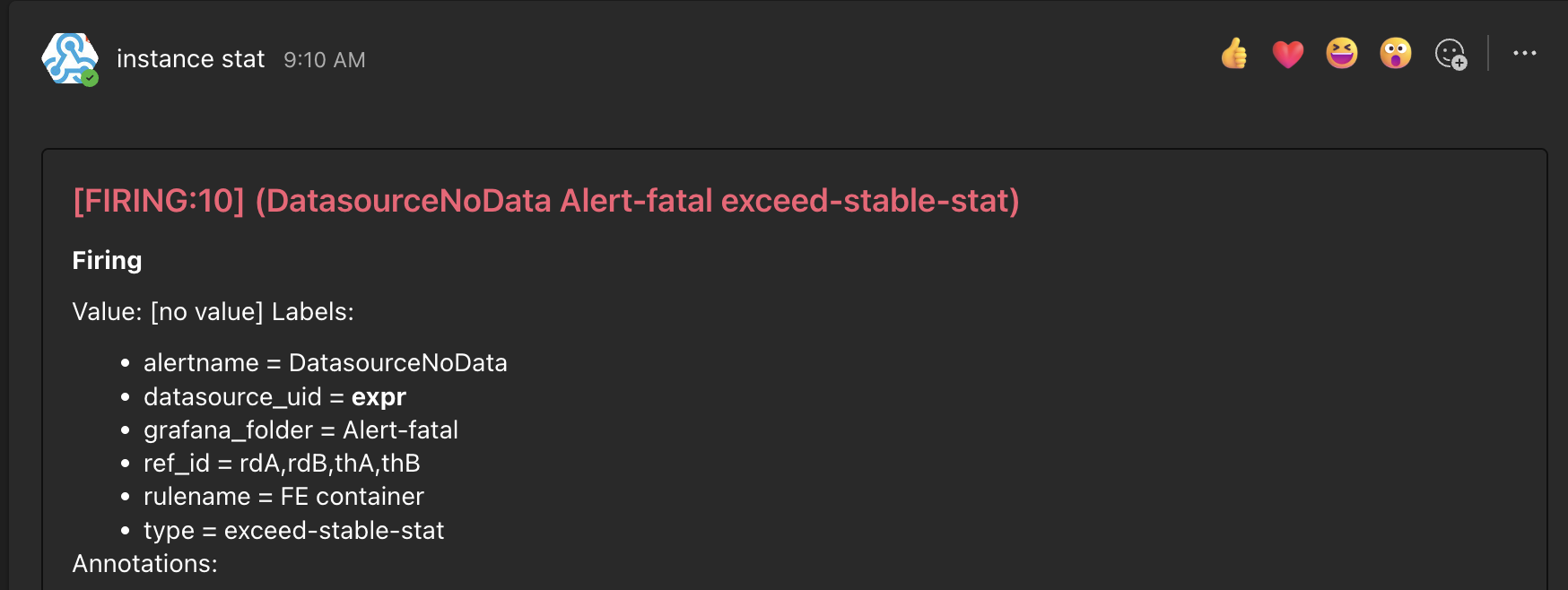
다음과 같은 알람이 계속 울리고 있었다.
모든 기능이 정상적으로 돌아가고 있는 가운데,
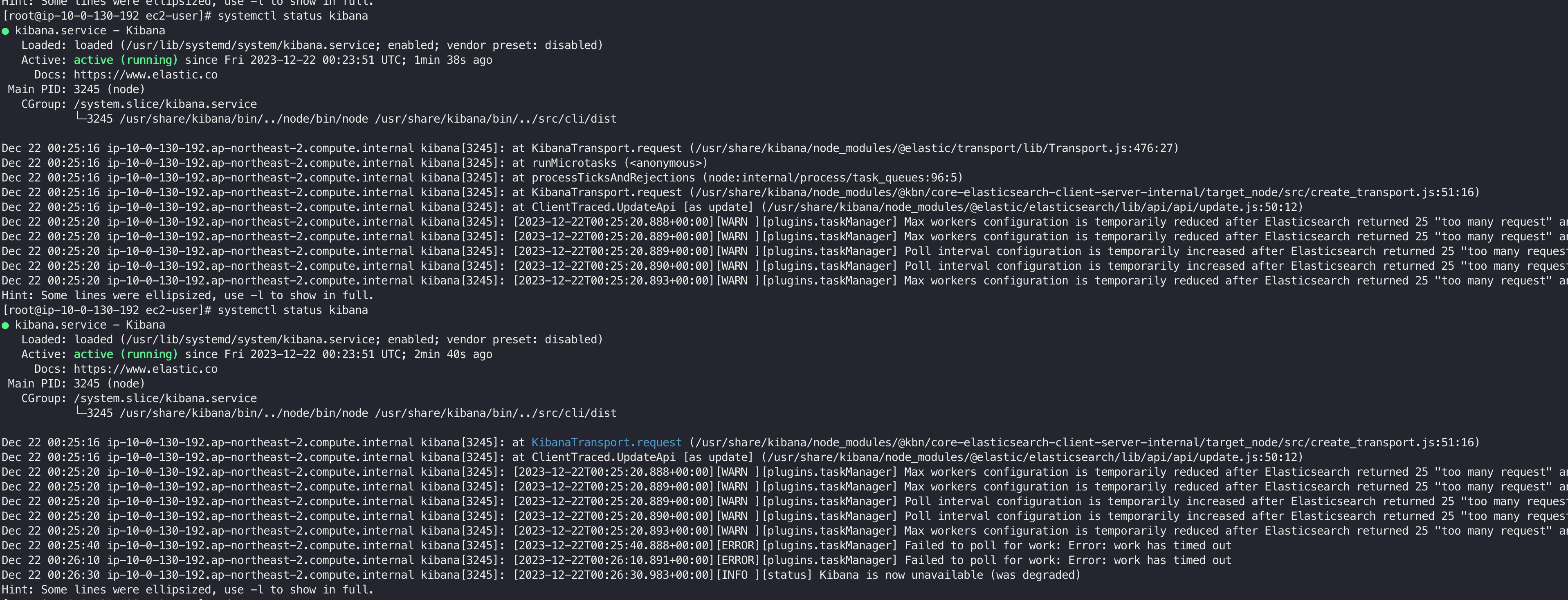
다음과 같은 에러가 발생했다. 의역하면, 요청이 너무 많아서 가용가능한 worker 가 정상적으로 일을 할 수 없다. 라는 뜻 인 것 같았다.
요청은 기존 그대로 보낼것 같은데, 혹시 디스크가 부족한건가 싶어서 디스크를 확인해봤다.
디스크 용량 확인하기
$ df -h
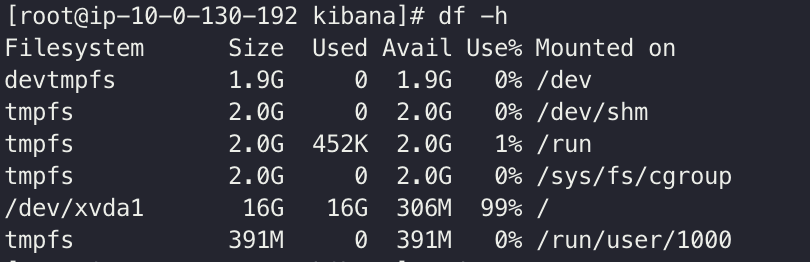
/dev/xvda1 용량을 보면 거의 다 사용한것을 알 수 있다.
가장 많이 사용된 용량 확인하기
$ cd /
$ sudo du -ckx | sort -n > /tmp/duck-root
$ sudo tail /tmp/duck-root
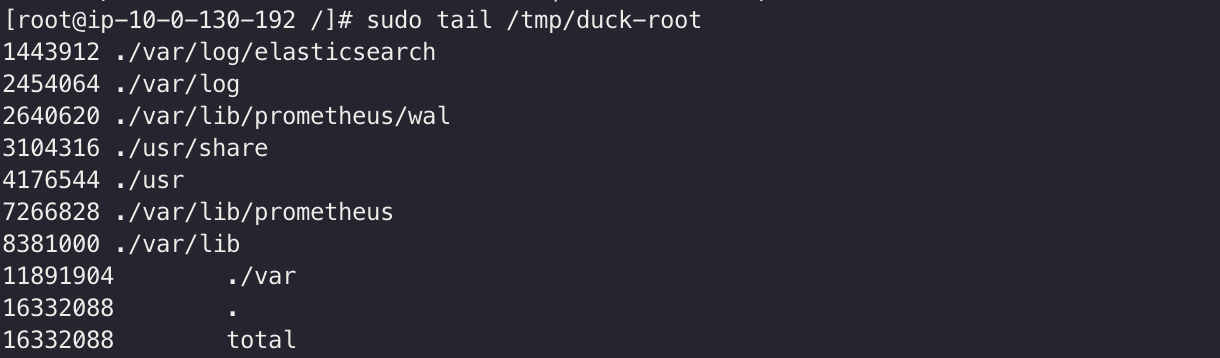
/var/log 와 /var/lib 에서 엄청나게 사용하는 것을 확인할 수 있다.
/var/log/elasticsearch 와 /var/lib/promethus 에 가서 필요없는 파일들을 삭제하여 용량을 늘려줄 수 있다.
특정 디렉토리에서 많이 쓰이는 용량 확인하기
$ du -ah | sort -n -r | head -n 10
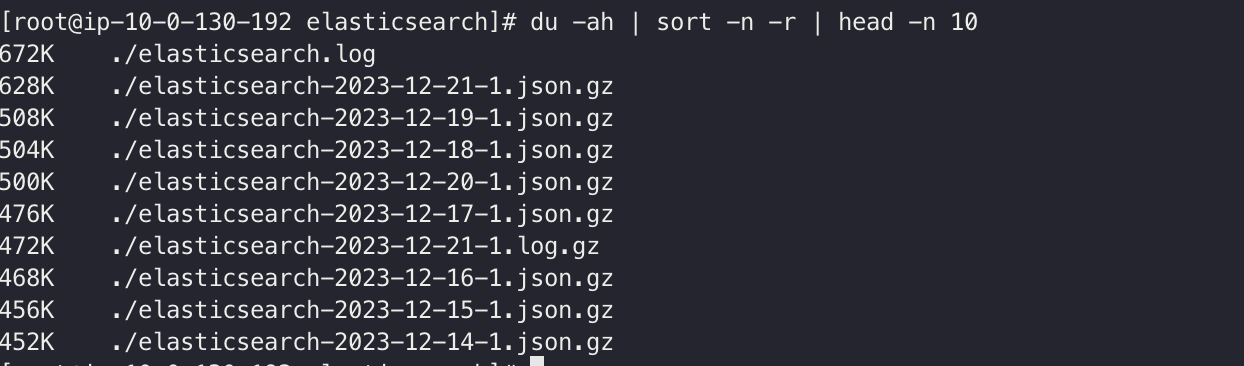
용량을 꽤나 차지 하고 있는 /var/log/elasticsearch 에 들어가서 어떤 파일이 실제로 용량을 차지하고 있는지 확인하려면, 위 명령어를 통해서 확인할 수 있다.
